
用最朴素的ViT,拿最新的SOTA!沈春华团队:搬来「ATM」打造语义分割的新范式!(NeurIPS 2022)

极市导读
本文提出了一种新的语义分割范式SegViT。不同于已有基于ViT语义分割方案的像素级表达方式,本文采用ViT最基本的成分(注意力机制)直接生成掩码(Mask)。在COCO-Stuff-10K(50.3%%mIoU)与PASCAL-Context(65.3%mIoU)数据集上取得了新的SOTA指标。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2210.05844
本文对朴素ViT在语义分割中的应用进行了探索,提出了一种新的语义分割范式SegViT。不同于已有基于ViT语义分割方案的像素级表达方式,本文采用ViT最基本的成分(注意力机制)直接生成掩码(Mask)。具体来说,本文提出ATM(Attention-to-Mask)模块,它将所学习类别token与特征之间的相似性直接转换为分割Mask。实验结果表明:在ADE20K数据集上,所提SegViT(55.2%mIoU)取得了明显优于其他ViT方案的性能,在COCO-Stuff-10K(50.3%%mIoU)与PASCAL-Context(65.3%mIoU)数据集上取得了新的SOTA指标。
此外,为更进一步降低ViT骨干的计算复杂度,本文还提出了QD(query-based 下采样)与QU(query-based 上采样)用于构建Shrunk结构,搭配上该结构所得SegViT可以在保持相当性能(55.1%mIoU)同时节省40%的计算量(373.5GFLOPs vs 637.9GFLOPs)。
本文出发点
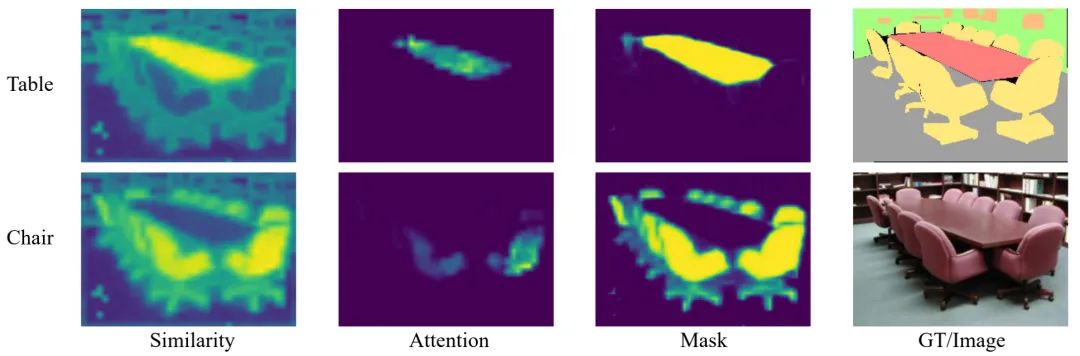
注意力机制中的Q与K的点乘操作用于计算两者之间的相似性,而在语义分割中同类区域特征应与其对应类别具有更大的相似性,上图则很好的说明了特征与类别之间的相似性。在Attention的基础上,简单的添加Sigmoid操作即可将相似性图转换为Mask。受此启发,作者设计了一种用于语义分割的ATM模块,并将其与朴素ViT的组合称之为SegViT。
众所周知,ViT骨干具有极高的计算复杂度,为进一步降低计算复杂度,作者提出了QD与QU以构建Shrunk结构,其中QD用于降低特征分辨率,而QU则用于辅助骨干进行分辨率重建。但搭配上Shrunk结构后,所提SegViT能够在保持相当性能的同时节省40%的计算量。
本文方案
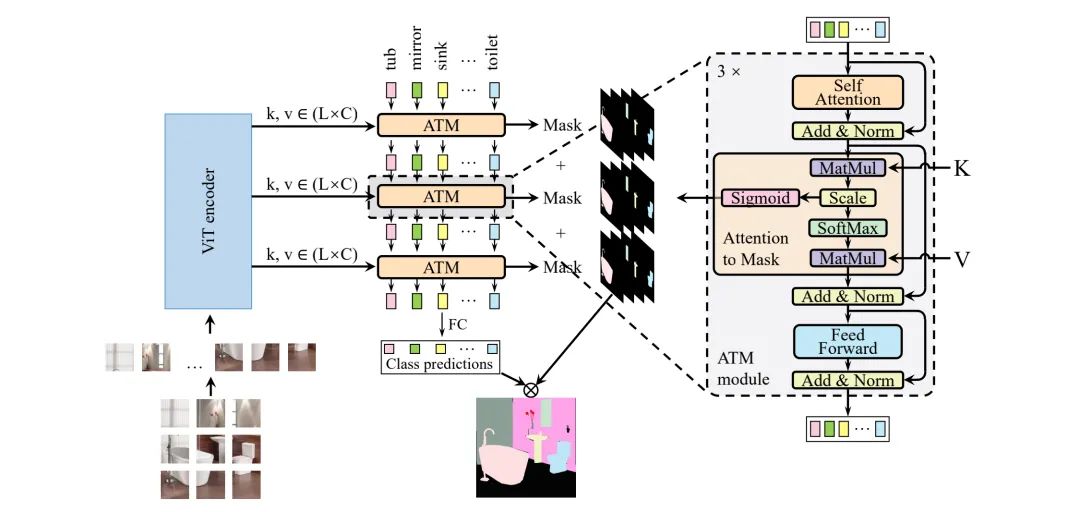
上图给出了本文所提方案架构示意图,它由基于ViT骨干的Encoder与基于ATM的Decoder构成。接下来,我们对Encoder部分进行简要介绍,重点针对Decoder部分进行介绍。
Encoder
给定输入图像,朴素ViT将其reshape为token序列,此外可学习位置嵌入信息将与相加以捕获位置信息。然后,采用m个Transformer层对进行处理以得到输出,将每一层的输出定义为。需要注意的是,本文采用了的是最基本的ViT,并非采用后来衍生出来的改进版。
Decoder
跨注意力可以描述为两个token序列之间的映射建模。我们首先定义两个token序列(N表示类别数)与。首先,我们对其进行线性变换构建Q、K以及V:
Q与K之间的相似性通过如下点乘操作计算得到:
在这里,本文采用Attention对进行逐步更新。需要注意的是:Attention通过Softmax函数聚焦于具有高相似性的token聚合。然而,作者认为:具有最大相似性的token同样非常有意义。基于该假设,作者构建了一个轻量模块直接生成语义预测。具体来说,作者将视作类分割任务的类嵌入信息,则表示ViT骨干不同层的输出。对类嵌入中的每个token搭配一个语义Mask以表征每个类别的语义预测,该计算表示如下:
Mask为跨注意力的中间输出,ATM模块的最后输出将被用于分类。作者对其添加一个线性变换+Softmax激活以输出得到类别概率预测。在推理阶段,类别概率与Mask的点乘输出作为最终的语义输出。
由于朴素ViT并不具备多阶段多尺度特征,FPN这种多尺度特征聚合方式就不再适用。那么,如何进行底层与高层特征聚合呢?作者基于ATM将ViT骨干不同位置的特征进行聚合并作为SegViT的Decoder模块。基于此,作者进一步引入了QD与QU构建了Shrunk版本的SegViT,在大幅降低计算量的同时保持同等性能。
Shrunk Decoder
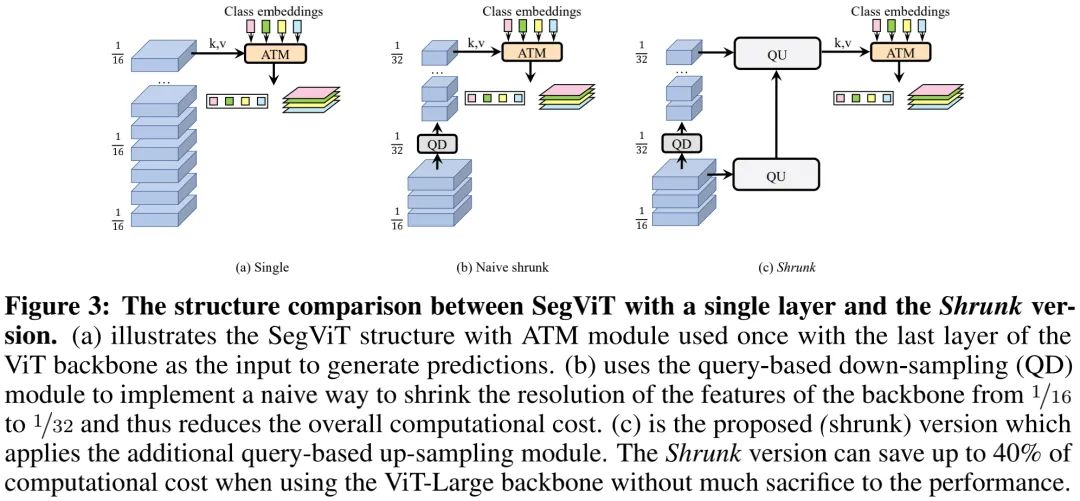
众所周知,同等性能前提下,朴素ViT具有更高的计算量复杂。为降低所提方案的计算复杂度,作者提出了一种基于QD与QU的Shrunk结构,可参考上图。由于注意力模块的输出尺寸受Q的尺寸决定,最简单的方式就是对齐进行下采样(如最近邻下采样,见上图b),然后送入后续Transformer层处理,但这种方式会导致信息损失,进而导致性能的退化。
为补充朴素Shrunk处理导致的信息损失,作者进一步添加了两个并行QU模块进行高分辨率特征重建。通过该方式的加持,SegViT-Shrunk可以大幅降低计算量(约40%),同时保持相当的性能。
Loss
在损失函数方面,作者对类别预测概率部分采用分类损失进行监督,对Mask部分采用Mask Loss(它有Focal Loss与Dice Loss组成)进行监督,定义如下:
本文实验
为验证所提方案的有效性,作者在ADE20K、COCO-Stuff-10K以及PASCAL-Context三个数据集上进行了验证。需要注意的是,ViT预训练模型并非官方预训练,而是参考Segmenter与Structtoken中选用了更强的预训练模型。这是因为:两个版本的预训练模型在最终模型上的性能差距竟然可以达到2.9%mIoU(51.7% vs 54.6%)。


上表与图给出了ADE20K数据集上的指标与可视化效果,从中可以看到:
所提SegViT-ViT-Large取得了55.2%mIoU指标,比StructToken高出1.0%;
SegViT-Shrunk取得了55.1%mIoU,计算量相比SegViT-ViT节省40%。
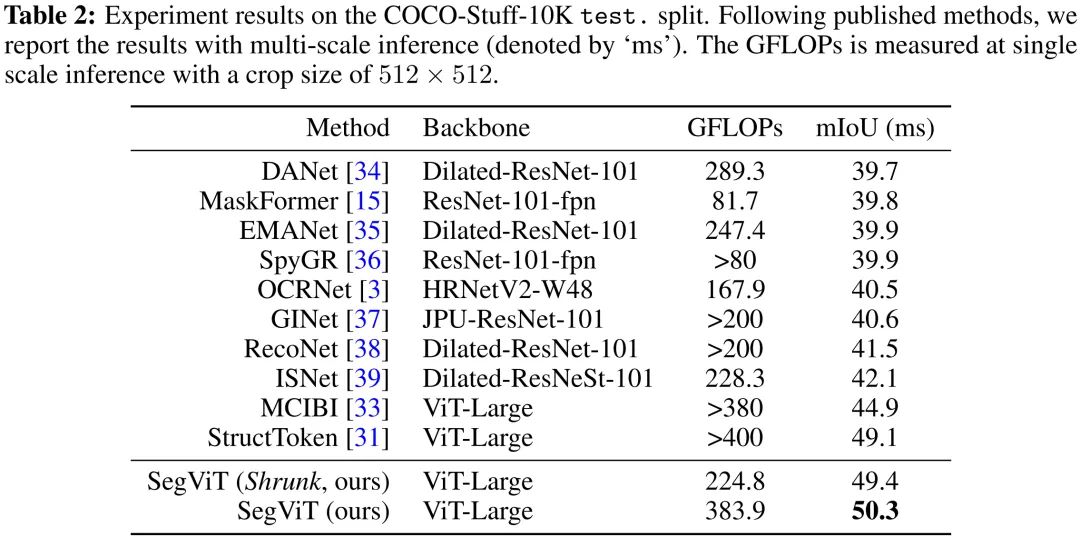

上表与图给出了COCO-Stuff-10K数据集上的指标与可视化效果,从中可以看到:
所提方案取得了50.3%mIoU指标,比SturcToken高出1.2%,同时具有更少的计算量;
SegViT-Shrunk取得了49.4%mIoU指标,参数量仅为224.8GFLOPs。
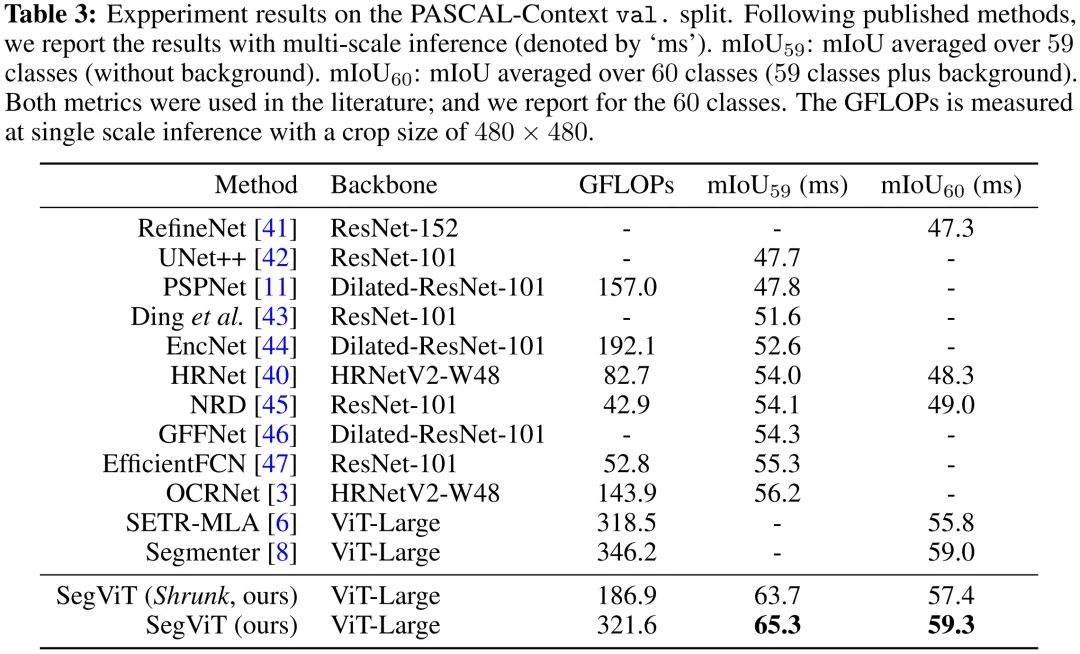

上表与图给出了PASCAL-Context数据集上的指标与可视化效果,从中可以看到:所提方案取得了65.3%mIoU指标(带背景类别)、59.3%mIoU指标(不带背景类别),达成了新的SOTA指标。
公众号后台回复“开学”获取CVPR、ICCV、VALSE等论文资源下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV技术深度Follower、爱造各种轮子
研究领域:专注low-level,对CNN、Transformer、MLP等前沿网络架构
保持学习心态,倾心于AI技术产品化。
公众号:AIWalker
作品精选
