
全新Backbone | 超越PvT,TWins等方法,ECOFormer使用哈希注意力成就高峰!
共 5664字,需浏览 12分钟
· 2022-10-25


Transformer 是一种用于深度学习的变革性框架,它对序列数据进行建模,并在广泛的任务中取得了显着的性能,但计算和能源成本很高。为了提高效率,一种流行的选择是通过二值化压缩模型,将浮点值限制为二进制值,以显着节省资源消耗,因为按位运算便宜。然而,现有的二值化方法仅旨在统计上最小化输入分布的信息损失,而忽略了注意力机制核心的成对相似性建模。为此,我们提出了一种新的二值化范式,通过核散列(称为 EcoFormer)为高维 softmax 注意力定制,将原始查询和键映射到汉明空间中的低维二进制代码。学习核化散列函数以以自我监督的方式匹配从注意力图中提取的真实相似性关系。基于二进制码的内积与汉明距离的等价性以及矩阵乘法的关联性,我们可以将注意力近似的线性复杂度表示为二进制码的点积。此外,EcoFormer 中查询和键的紧凑二进制表示使我们能够用简单的累加来替换注意力中大多数昂贵的乘法累加操作,从而在边缘设备上节省大量的片上能源足迹。对视觉和语言任务的广泛实验表明,EcoFormer 始终如一地实现与标准注意力相当的性能,同时消耗更少的资源。例如,基于 PVTv2-B0 和 ImageNet-1K,EcoFormer 实现了 73% 的能源足迹减少,与标准注意力相比,性能仅略有下降 0.33%。
1、简介
最近,Transformers 凭借其非凡的表现力,在自然语言处理 (NLP) 和计算机视觉 (CV) 方面取得了快速而令人兴奋的进展。与卷积神经网络 (CNN) 相比,Transformer 模型通常更适合海量数据,并且更擅长以更少的归纳偏差捕获长依赖的全局信息,从而在许多任务中实现更好的性能。然而,效率瓶颈,特别是高能耗,极大地阻碍了 Transformer 模型大规模部署到资源受限的边缘设备,如手机和无人机,以解决各种现实世界的应用。
为了减少能量消耗,已经积极研究量化以降低网络权重和/或激活的位宽表示。凭借最激进的位宽,二进制量化引起了很多关注,因为它通过用单个位(例如 +1 或 -1)表示值来实现高效的按位运算。当我们只对权重进行类似于 BinaryConnect 的二值化时,如表 1 所示,它通过用简单的高能效累加代替大量耗能的乘法累加操作为专用硬件带来了巨大的好处,从而节省了大量的片上面积和使用 Transformer 进行推理所需的能量,使其能够部署在资源有限的移动平台上。然而,传统的二值化过程通常以最小化原始全精度数据分布和量化的伯努利分布之间的量化误差为目标。换句话说,每个标记都被单独二值化,其中二进制表示可能无法很好地保留标记之间的原始相似性关系。这促使我们将二值化过程定制为 softmax attention,这是 Transformer 中编码标记之间成对相似性的核心机制。为此,我们可以采用成熟的散列方法,将高维查询和键映射为能够保留汉明空间中相似关系的紧凑二进制代码(例如,16 位)。一个简单的解决方案是使用局部敏感散列(LSH)来替代二进制量化对应物。
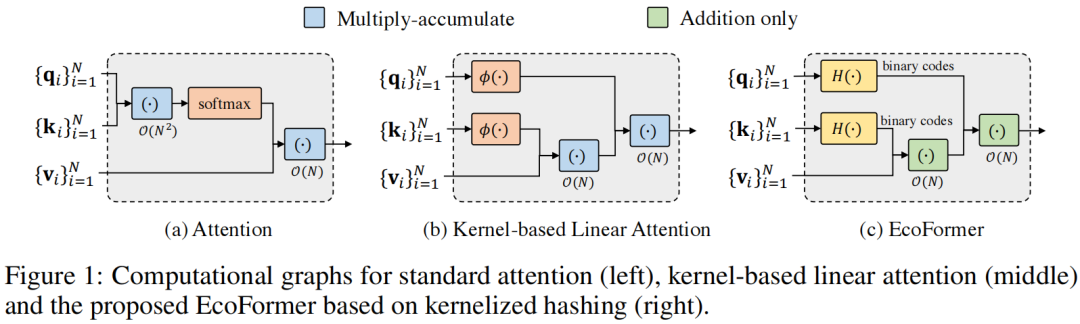
然而,变形金刚还存在另一个能源瓶颈。特别地,给定一个标记序列,softmax attention 通过计算查询之间的内积来获得注意力权重令牌和所有关键令牌,导致关于令牌数量N的二次时间复杂度O(N2),如图1(a)所示。对于长序列长度 N,这个问题甚至更糟,尤其是对于密集预测任务中的高分辨率图像。为了降低 softmax 注意力的复杂性,一些先前的工作建议将注意力表示为核化特征嵌入的线性点积。借助矩阵乘法的关联性,注意力操作可以近似为线性复杂度 O(N),如图 1 (b) 所示。
基于哈希机制和基于内核的注意力公式,我们设计了一种简单而有效的节能注意力,称为 EcoFormer,如图 1(c) 所示。特别是,我们建议使用带有 RBF 内核的核化散列来将查询和键映射到紧凑的二进制代码。基于代码的内积(即汉明亲和力)和汉明距离具有一一对应的良好特性,得到的代码对于保持相似性是有效的。由于二进制代码之间线性点积的关联特性,核化散列注意力具有线性复杂性,具有显着的节能效果。此外,注意力中的成对相似度矩阵可以直接用于获得哈希函数学习的监督标签,从而提供了一种新颖的自监督哈希范式。通过最大化相似标记对的汉明亲和力并同时最小化不同标记对,可以保留标记之间的成对相似关系。使用低维二进制查询和键,我们可以用简单的加法代替注意力中大部分耗能的浮点乘法,这大大节省了片上的能量足迹。
总而言之,我们做出了三个主要贡献:
我们提出了一种新的二值化范式,以更好地保持softmax注意力中的成对相似性。特别是,我们提出了 EcoFormer,这是一种具有线性复杂性的节能注意力,由内核散列驱动,可将查询和键映射为紧凑的二进制代码。
我们基于从注意力分数中提取的groundtruth Hamming亲和力以自我监督的方式学习核化哈希函数。
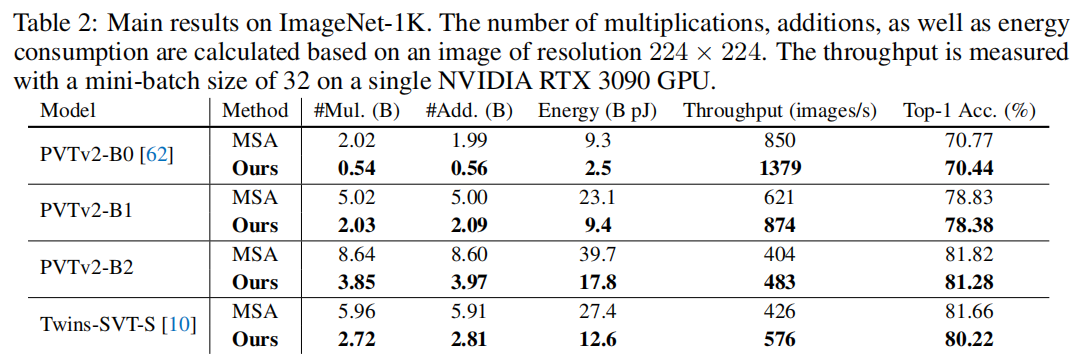
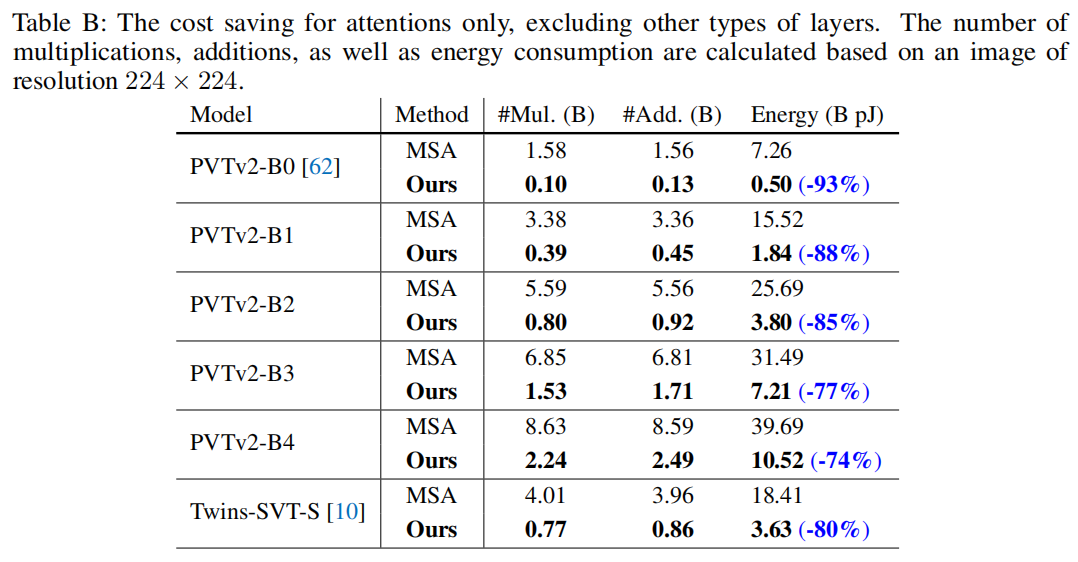
在 CIFAR-100、ImageNet-1K 和 Long Range Arena 上的大量实验表明,EcoFormer 能够在保持准确性的同时显着降低能源成本。例如,基于 PVTv2-B0 和 ImageNet-1K,EcoFormer 实现了 73% 的能源足迹减少,与标准注意力相比,性能仅下降了 0.33%。
2、背景知识
2.1、Attention Mechanism
令 X ∈ RN×D 是标准多头自注意力 (MSA) 层的输入序列,其中 N 是输入序列的长度,D 是隐藏维数。一个标准的 MSA 层使用三个可学习的投影矩阵 Wq,Wk,Wv ∈ RD×Dp 计算一系列查询、键和值向量,可以表示为:
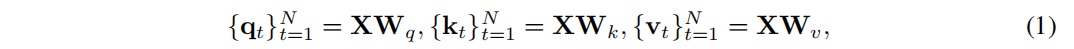
其中 Dp 是指每个头部的维数。对于每个查询向量,注意力输出是所有值向量的加权和,如
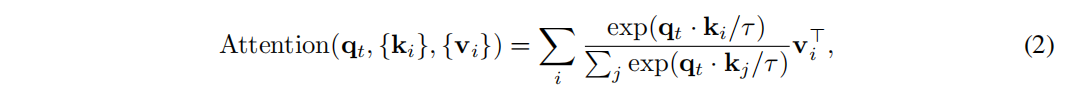
其中τ是控制softmax平坦度的温度,exp(h·,·i)是指数函数。Eq.(2) 的计算在空间和时间上都具有 O(N2) 的二次复杂度,这在处理长序列时导致了巨大的计算成本。
2.2、Kernel-based Linear Attention
基于内核的线性注意背后的想法是将方程(2)中的相似性度量表示为内核嵌入的线性点积,例如多项式内核、指数或 RBF 内核。一个特定的选择是使用有限随机映射 φ(·) 来逼近无限维 RBF 内核。然后,根据 Rahimi 的定理,一对变换向量 x 和 y 与 φ(·) 的内积可以逼近一个高斯 RBF 核。这导致对等式(2)中的 exp(h·,·i) 的无偏估计,可以表示为:
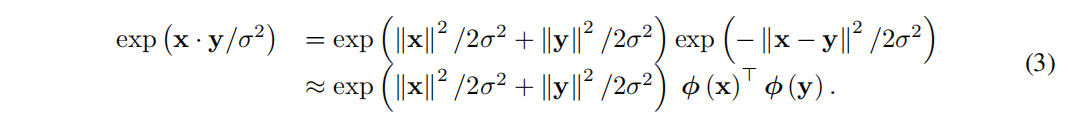
假设查询和键是单位向量,则等式(2)中的注意力计算可以近似为
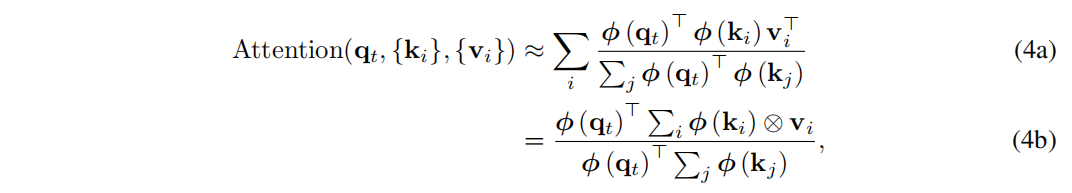
其中⊗是指外积。最近的工作表明,基于内核的线性注意力在机器翻译和蛋白质序列建模方面优于原始的 softmax 注意力。然而,虽然复杂度降低为线性,但等式(4b)中密集的浮点乘法仍然消耗大量能量,这会很快耗尽移动/边缘平台上的电池。
2.3、Binary Quantization
在 Xnor-net 之后,二进制量化通常使用二进制 ˆu ∈ {+1, -1}n 和比例因子 α ∈ R+ 来估计全精度 u ∈ Rn,使得 u ≈ αˆu 成立。为了找到准确的估计,现有方法将量化误差最小化为
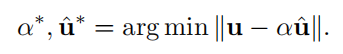
通过解决问题 (5),我们有 ^u = sign(u) 和 α = 1n k uk 1,其中如果 u ≥ 0,sign(u) 返回 1,如果 u < 0,则返回 -1。可微分时,应用直通估计器 (STE) 来近似梯度,例如使用硬 tanh 或分段多项式函数的梯度。
3、本文方法
为了减少self-attention的能量消耗,可以对查询{qt}Nt=1和键{kt}Nt=1执行二进制量化。在这种情况下,我们可以用高能效的逐位运算代替大部分高能耗的乘法运算。然而,现有的二进制量化方法只关注于最小化原始全精度值与等式(5)中的二进制值之间的量化误差,无法保持注意力中不同标记之间的成对语义相似性,导致性能下降.
请注意,注意力可以看作是对成对的令牌应用内核平滑器,其中内核分数表示令牌对的相似性,如 3.2 节所述。受此启发,我们提出了一种新的二值化方法,该方法应用带有高斯 RBF 的核散列,将原始高维查询/键映射到汉明空间中的低维相似性保持二进制码。我们称之为 EcoFormer 的提议框架如图 1 (c) 所示。为了保持注意力的语义相似性,我们以自我监督的方式学习哈希函数。通过利用二进制代码之间线性点积的关联特性以及代码内积(即汉明亲和度)与汉明距离之间的等价性,我们能够以较低的能量成本在线性时间内逼近自注意力。下面,我们首先在 4.1 节介绍核化哈希注意力,然后在 4.2 节展示如何以自监督的方式学习哈希函数。
3.1、Kernelized Hashing Attention
在应用哈希函数之前,我们让查询 {qt}Nt=1 和键 {kt}Nt=1 相同。这样,我们就可以应用核化散列函数 H : RDp 7→ {1, -1}b 而无需显式应用 3.2 节中提到的变换 φ(·) 将 qi 和 kj 映射为 b 位二进制码 H(qi) 和 H(kj ),分别(见第 4.2 节)。在这种情况下,它们之间的汉明距离可以定义为
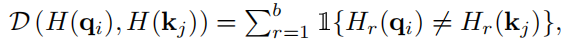
其中 Hr(·) 是二进制码的第 r 位;1{A} 是一个指示函数,如果满足 A,则返回 1,否则返回 0。使用 D (H(qi), H(kj )),H(qi) 和 H(kj ) 之间的代码内积可以是 制定为
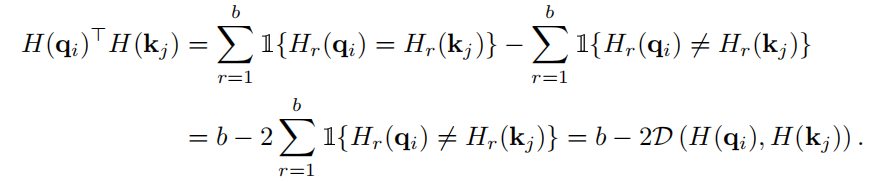
重要的是,等式(7)显示了汉明距离和代码内积之间的等价性,因为存在一一对应关系。通过用等式(4a)中的散列查询和键替换,我们可以将自注意力近似为
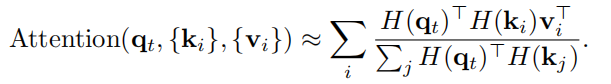
注意 H(qt)> H(kj ) ∈ [−b, b]。为了避免分母为零,我们在每个内积中引入一个偏置项 2c,使得 H(qt)> H(kj ) + 2c > 0,对相似性度量没有影响。在这里,我们可以简单地将 c 设置为 d log2(b + 1)e,其中 due 返回大于或等于 u 的最小整数。利用矩阵乘法的关联属性,我们将自注意力近似为
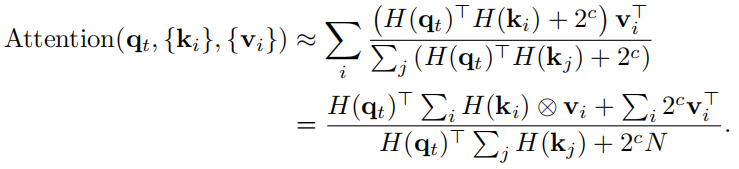
在实践中,等式(9)中的二进制代码和全精度值之间的乘法可以用简单的加法和减法代替,这大大减少了片上能量足迹方面的计算开销。此外,与 2c 的二次幂的乘法也可以通过有效的位移操作来实现。结果,唯一的乘法来自分子和分母之间的元素除法。
3.2、Self-supervised Hash Function Learning
给定查询 Q = {q1, ... , qN } ⊂ RDp ,我们寻求学习一组哈希函数 h : RDp 7→ {1, -1}。我们没有显式应用第 3.2 节中提到的变换函数 φ(·),而是使用核函数 κ(qi, qj ) 计算散列函数:RDp × RDp 7→ R。给定 Q = [q1,..., qN ]> ∈ RN×Dp ,我们从 Q 中随机抽取 m 个查询 q(1), ..., q(m) 作为支持样本,遵循基于内核的监督散列 (KSH) [36] 并定义一个散列函数 h 为
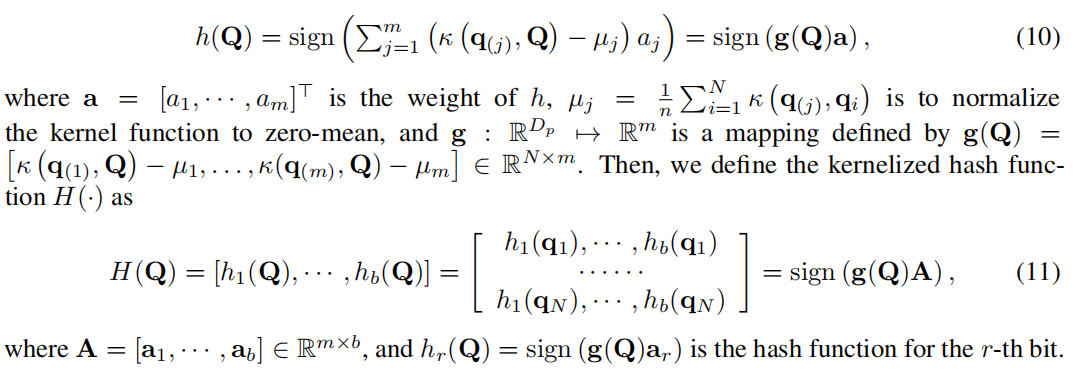
为了指导二进制代码的学习,我们希望相似的标记对具有最小的汉明距离,而不同的标记对具有最大的距离。然而,由于方程(6)中的非凸和非光滑公式,直接优化汉明距离是困难的。利用等式(7)中代码内积和汉明距离之间的等价性,我们改为基于汉明亲和力进行优化以最小化重构误差为
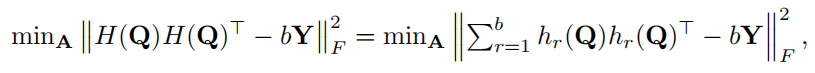
其中 k·kF 是 Frobenius 范数,Y ∈ RN×N 是目标汉明亲和矩阵。为了保持查询和键之间的相似关系,我们使用注意力分数作为自监督信息来构造 Y。让 S 和 U 是相似和不相似的标记对。我们通过选择具有 Top-l 最大和最小注意力分数的标记对来获得 S 和 U。然后我们构造成对标签 Y 为
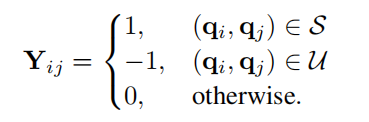
然而,问题 (12) 是 NP 难的。为了有效地解决它,我们采用离散循环坐标下降来顺序学习二进制代码。具体来说,我们只在之前的 a1,...,ar−1 优化后才求解 ar。令 ˆYr−1 = bY − P r−1 t=1 ht(Q)ht(Q)> 为残差矩阵,其中 ˆY0 = bY。然后,我们可以最小化以下目标以获得 ar
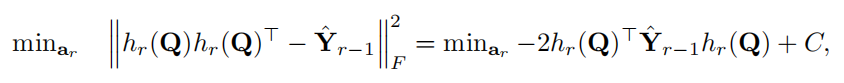
其中 C 是一个常数。注意 ^Yr−1 是一个对称矩阵。因此,问题 (14) 是一个标准的二元二次规划问题,可以通过许多现有的方法有效地解决,例如 LBFGS-B 求解器和块图切割。为了结合网络参数学习 ar,我们建议使用基于梯度的方法来解决问题 (14)。对于不可微分的符号函数,我们使用 STE 来近似梯度,使用硬 tanh,如 3.3 节所述。请注意,为每个 epoch 学习散列函数在计算上是昂贵的,但却是不必要的。我们只学习每个 τ epoch 的哈希函数。
4、实验
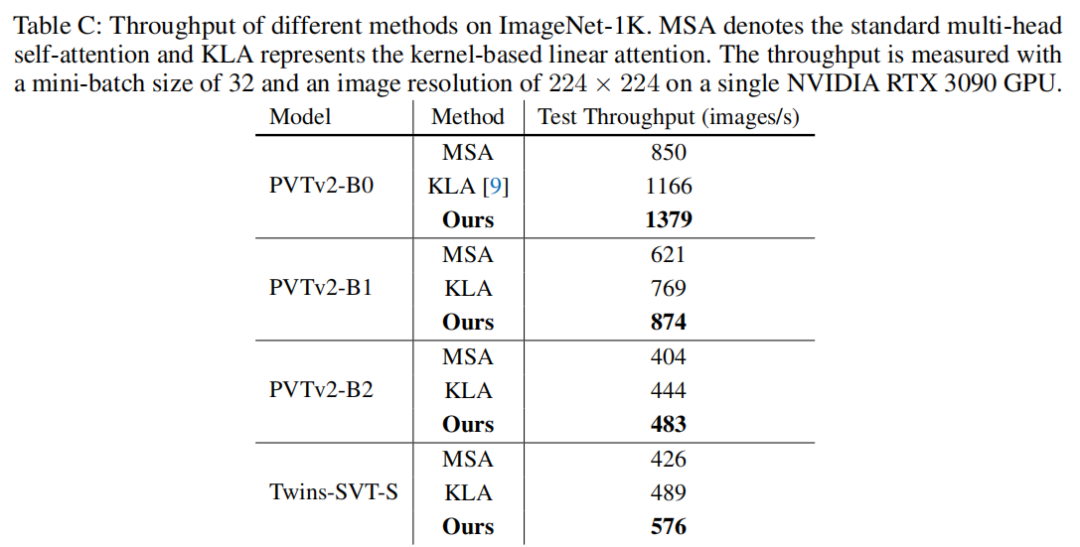
5、参考
[1].EcoFormer: Energy-Saving Attention with Linear Complexity.
6、推荐阅读
NeurIPS 2022 | 百度提出超快Transformer分割模型RTFormer,180FPS+81mIOU
重参系列 | 以伤换杀,RMNet带你一键将ResNet重参为VGG(附代码及ONNX对比)
即插即用 | CNN与Transformer都通用的Trick,即插即涨点即提速!
扫描上方二维码可联系小书童加入交流群~
想要了解更多前沿AI视觉感知全栈知识【分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF】、行业技术方案【AI安防、AI医疗、AI自动驾驶以及AI元宇宙】、AI模型部署落地实战【CUDA、TensorRT、NCNN、OpenVINO、MNN、ONNXRuntime以及地平线框架等】,欢迎扫描下方二维码,加入集智书童知识星球,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!