
盘点一个Python网络爬虫+正则表达式处理案例
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
一、前言
前几天在Python白银交流群【鑫】问了一个Python网络爬虫的问题,提问截图如下:

下面是他的代码:
import requests
import re
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
pageSource = resp.text
print(pageSource) #re.S可以让正则的。匹配换行符
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</sp'
r'an>.*? <p class="">.*?导演:(?P<dao>.*?) <br>'
r'(?P<year>.*?) ', re.S)
result = obj.finditer(pageSource)
for item in result:
print(item.group("name"))
print(item.group("dao"))
print(item.group("year"))
二、实现过程
这里【瑜亮老师】指出问题,如下所示:
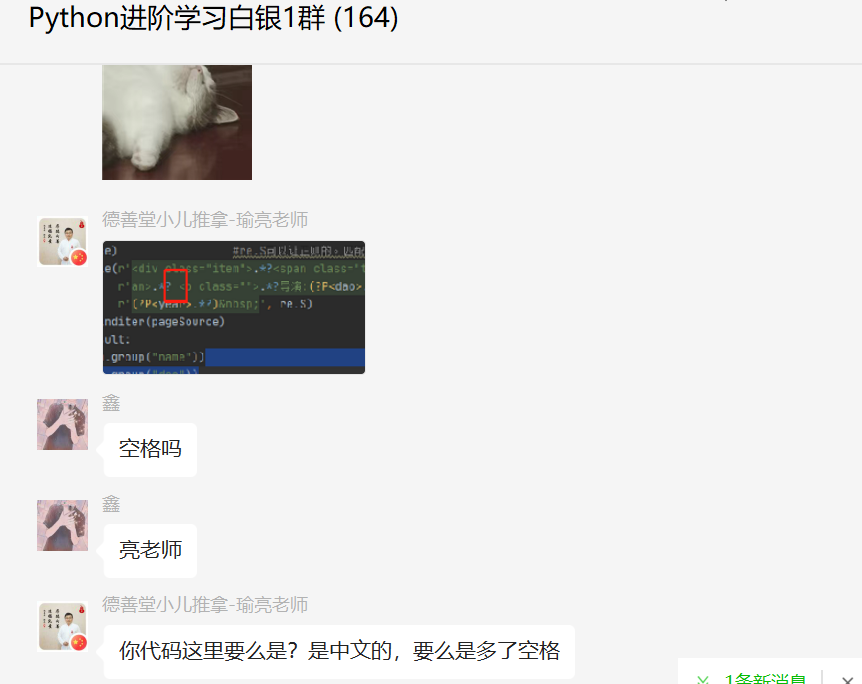
事实上还是那个正则表达式写的有问题。

跟着视频来敲,有时候视频太老了,或者对应的网页结构改版了,导致原有的代码并不能够适配,导致出错。
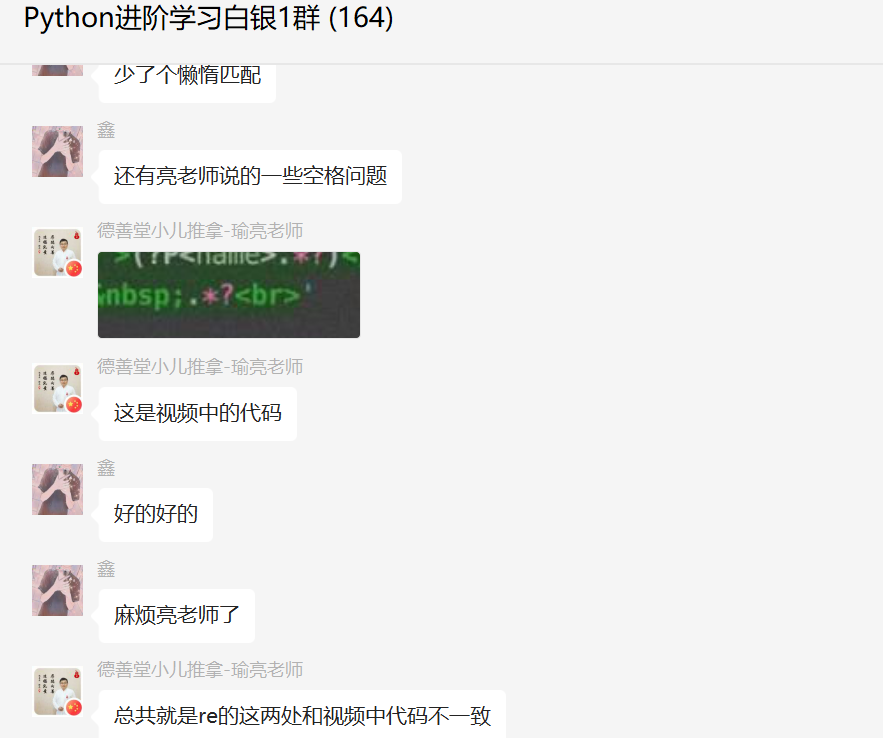
修改之后可以得到正确的结果了。
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python网络爬虫+正则表达式处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【鑫】提问,感谢【瑜亮老师】给出的思路和代码解析,感谢【dcpeng】、【ᯤ⁶ᴳ】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群,欢迎大家加入我的Python学习交流群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
评论