
一文看得 Linux 性能分析|perf原理
最近线上运行的程序出现性能问题,但通过分析程序源代码(Code Review),并找不到导致问题的根本原因。所以,只能借助强大的性能分析工具 perf 来找出问题所在。
perf 工具的功能非常强大,但本文并不是介绍 perf 工具的使用,而是介绍 perf 的实现原理。介绍 perf 使用的文章多如牛毛,但介绍 perf 原理和实现的却凤毛麟角。
但正因为 perf 功能非常强大,所以其实现也是非常复杂的。本文只介绍其中的一个功能:分析进程中的函数调用频率。
接下来,我们先介绍怎么使用 perf 来分析进程中的函数调用频率。
使用 perf 分析程序性能瓶颈
在介绍 perf 的实现之前,我们先使用 perf 分析一个简单的程序,此程序代码如下:
// sample.c
void workload1()
{
int i, c = 0;
for (i = 0; i < 100000000; i++) {
c += i * i;
c -= i * 100;
c += i * i * i / 100;
}
}
void workload2()
{
int i, c = 0;
for (i = 0; i < 200000000; i++) {
c += i * i;
c -= i * 100;
c += i * i * i / 100;
}
}
int main(int argc, char *argv[])
{
workload1();
workload2();
return 0;
}
上面的程序很简单,我们创建两个函数:workload1 和 workload2。从代码可以看出,workload2 的负载是 workload1 的2倍。
现在我们使用 perf 来分析这个程序的性能瓶颈在哪里。
首先我们将程序编译成可执行文件,编译时记得加上 -g参数,这样 perf 才能获取到函数名。
$ gcc sample.c -g -o sample
使用 perf 的 record命令来记录程序的运行情况。
$ sudo perf record -g ./sample sleep 10
运行上面的命令后,将会生成一个 perf.data 的文件,此文件记录了 sample 程序运行时的采样数据。
使用 perf 的 report命令分析程序的运行情况。
$ perf report -g
结果如下图所示:
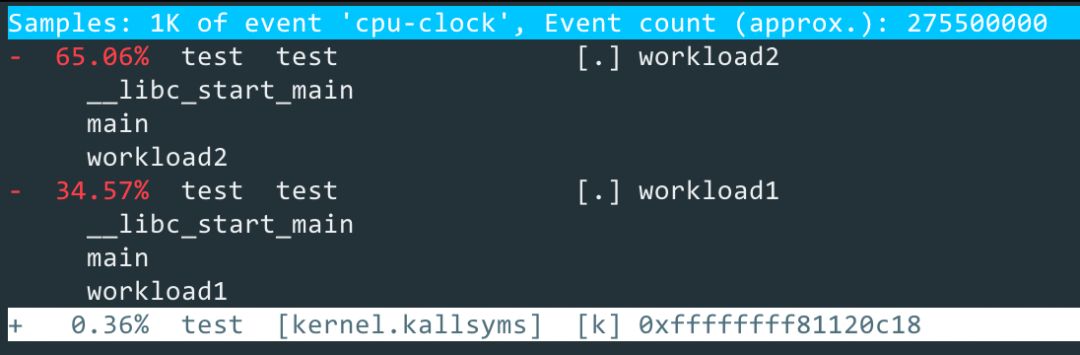
从上图可以看出,函数 workload2(65%)的负载大概是函数 workload1(35%)的 2 倍,与我们的代码基本一致。
perf 实现原理
通过上面的例子,我们大概知道怎么使用 perf 来分析程序的性能瓶颈。接下来,我们将会介绍 perf 的内部实现原理。
来思考一下,如果让我们来设计一个统计程序中各个函数占用 CPU 时间的方案,应该如何设计?最简单的方案就是:在各个函数的开始记录当前时间,然后在函数执行结束后,使用当前时间减去函数开始执行时的时间,得到函数的执行时间总时长。如下伪代码:
void func1()
{
...
}
void func2()
{
...
}
int main(int argc, char *argv[])
{
int start_time, total_time;
start_time = now();
func1();
total_time = now() - start_time;
printf("func1() spent %d\n", total_time);
start_time = now();
func2();
total_time = now() - start_time;
printf("func2() spent %d\n", total_time);
}
虽然上述方式可以统计程序中各个函数的耗时情况,但却存在很多问题:
代码入侵度高。由于要对每个函数进行耗时记录,所以必须在调用函数前和调用函数后加入统计代码。 统计函数耗时,并不能反映该函数的真实 CPU 使用率。比如函数内部调用了导致进程休眠的系统调用(如sleep),这时函数实际上是不使用CPU的,但函数的耗时却统计了休眠的时间。 对性能影响较大。由于程序中所有函数都加入统计代码,所以对性能的影响是非常大的。
所以我们需要一个系统,它能够避免上述问题:
零代码入侵。 能够真实反映函数的 CPU 使用率。 对性能影响较小。
perf 就是为了解决上述问题而生的,我们先来介绍一下 perf 的原理。
采样
为了减小对程序性能的影响,perf 并不会在每个函数加入统计代码,取而代之的统计方式是:采样。
采样的原理是:设置一个定时器,当定时器触发时,查看当前进程正在执行的函数,然后记录下来。如下图所示:
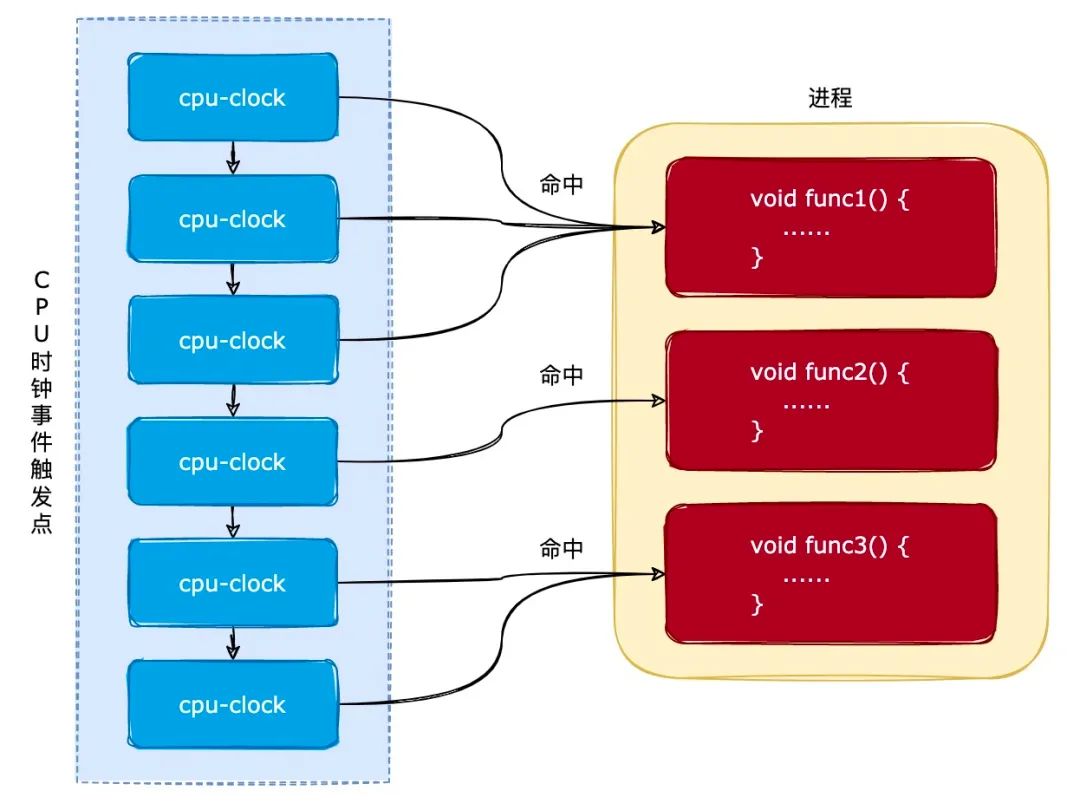
如上图所示,每个 cpu-clock 是一个定时器的触发点。在 6 次定时器触发点中,函数 func1 被命中了 3 次,函数 func2 被命中了 1 次,函数 func3 被命中了 2 次。所以,我们可以推测出,函数 func1 的 CPU 使用率最高。
排序
如果程序有成千上万的函数,那么采样出来的数据可能非常多,这个时候就需要对采样的数据进行排序。
为了对采样数据进行排序,perf 使用红黑树这种数据结构,如下图所示:
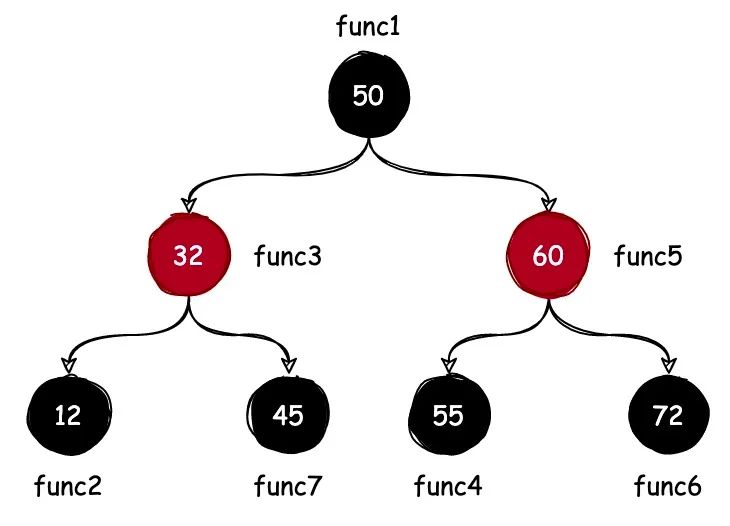
如上图所示,在 perf 采样的数据中,有 7 个函数被统计了命中次数,perf 使用采样到的数据构建一棵红黑树。
根据红黑树的特性,最右边的节点就是被命中最多的函数,这样就能把程序中 CPU 使用率最高的函数找出来。
总结
由于 perf 的功能非常强大,所以本文也只介绍了 perf 其中一种功能:统计函数的 CPU 使用率。
在下一篇文章中,我们将会介绍 perf 的代码实现。Linux 的创始人 Linus 曾经说过:Read the f**king source code,要真正理解一个系统,只能通过阅读其源码。