AI大佬是如何从头开始写一篇顶级论文的?
作者:重剑无锋,宾夕法尼亚大学机器学习Ph.D
最近完成了一篇很满意的论文,不仅整个过程愉快、回味无穷,而且真正做到了「学术有影响,工业有产出」。我相信这篇文章会改变差分隐私(differential privacy;DP)深度学习的范式。
因为这次经历实在太过「巧」了 (过程充满巧合、结论极其巧妙),在此和同学们分享一下自己从观察 -->构思 -->实证 -->理论 -->大规模实验的完整流程。本文我会尽量保持 lightweight,不涉及过多技术细节。

论文地址:arxiv.org/abs/2206.07136
与 paper 展现的顺序不同,paper 有时会刻意将结论放在开头吸引读者,或者先介绍简化后的定理而将完整的定理放附录;而本文我想将我的经历按时间顺序写下(也就是流水账), 比如把走过的弯路和研究中突发的状况写出来,以供刚踏上科研之路的同学参考。
一、 文献阅读
事情的起源是斯坦福的一篇论文,现在已经录了 ICLR:

论文地址:https://arxiv.org/abs/2110.05679
文章写的非常好,总结起来有三个主要贡献:
1. 在 NLP 任务中,DP 模型的 accuracy 非常高,鼓励了 privacy 在语言模型的应用。(与之相对的是 CV 中 DP 会产生非常大的 accuracy 恶化,比如 CIFAR10 目前 DP 限制下不用预训练只有 80% accuracy,而不考虑 DP 可以轻松达到 95%;ImageNet 当时最好的 DP accuracy 不到 50%。)
2. 在语言模型上,模型越大,性能会越好。比如 GPT2 从 4 亿参数到 8 亿参数性能提升很明显,也取得了很多 SOTA。(但是在 CV 和推荐系统中,很多时候更大的模型性能会很差,甚至接近 random guess。比如 CIFAR10 的 DP best accuracy 此前是由四层 CNN 得到的,而非 ResNet。)
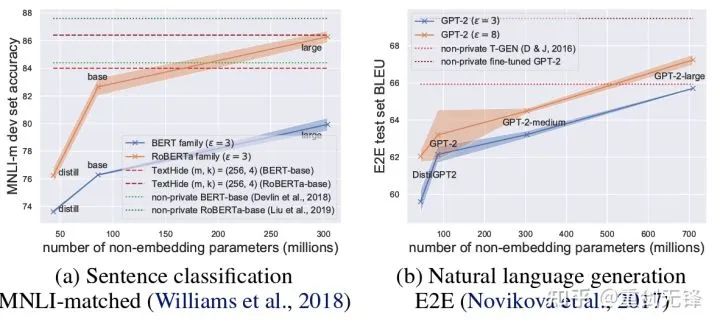
NLP 任务中 DP 模型越大性能越好 [Xuechen et al. 2021]
3. 在多个任务上取得 SOTA 的超参数是一致的:都是 clipping threshold 要设置的足够小,并且 learning rate 需要大一些。(此前所有文章都是一个任务调一个 clipping threshold,费时费力,并没有出现过像这篇这样一个 clipping threshold=0.1 贯穿所有任务,表现还这么好。)
以上总结是我读完 paper 瞬间理解的,其中括号内的内容并非来自这篇 paper,而是以往诸多阅读产生的印象。这有赖于长期的阅读积累和高度的概括能力,才能快速联想和对比出来。
事实上,很多同学做文章起步难恰恰就在于看一篇文章只能看到一篇文章的内容,无法和整个领域的知识点形成网络、产生联想。这一方面由于刚入门的同学阅读量不够,尚未掌握足够的知识点。尤其是长期从老师手中拿课题,不自己独立 propose 的同学,容易有这个问题。另一方面则是阅读量虽然够,但没有时时归纳总结,导致信息没有凝聚成知识或者知识没有串联。
这里补充下 DP deep learning 的背景知识,暂且略过 DP 的定义,不影响阅读。
所谓 DP deep learning 从算法的角度来说其实就是多做两个额外的步骤:per-sample gradient clipping 和 Gaussian noise addition;换句话说,只要你把 gradient 按照这两步处理完了(处理后的 gradient 叫做 private gradient),之后该怎么用优化器就怎么用,SGD/Adam 都可以。
至于最后算法到底多 private,就是另一个子领域的问题了,称为 privacy accounting theory。此领域相对成熟而且需要极强的理论功底,由于本文专注于 optimization,按下不表。
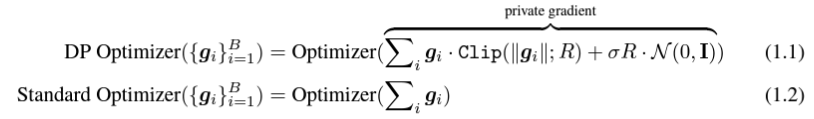
g_i 是 一个数据点的梯度(per-sample gradient),R 是 clipping threshold, sigma 是 noise multiplier。
其中 Clip 叫做 clipping function,就跟常规的 gradient clipping 一样,梯度长于 R 就剪到 R,小于 R 就不动。
比如 DP 版本的 SGD 就是目前所有 paper 都用的是隐私深度学习开山之作(Abadi, Martin, et al. "Deep learning with differential privacy.")中的 clipping function,也称为 Abadi's clipping: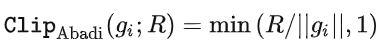 。
。
但这是完全不必要的,遵循第一性原理,从 privacy accounting theory 出发,其实 clipping function 只需要满足 Clip(g_i)*g_i 的模小于等于 R 就可以了。也就是说,Abadi's clipping 只是一种满足这个条件的函数,但绝非唯一。
二、切入点
一篇文章的闪光点很多,但是并非都能为我所用,要结合自身的需求和擅长去判断最大的贡献是什么。
这篇文章前两个贡献其实非常 empirical,也很难深挖。而最后一个贡献很有意思 我仔细看了看超参数的 ablation study 发现一个原作者没有发现的点:在 clipping threshold 足够小的时候,其实 clipping threshold(也就是 clipping norm C,在上面的公式中和 R 是一个变量)没有作用。
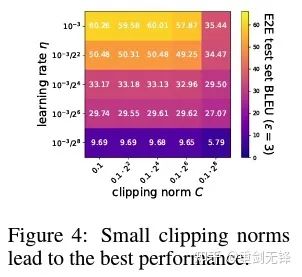
纵向来看 C=0.1,0.4,1.6 对 DP-Adam 没什么区别 [Xuechen et al. 2021]。
这引起了我的兴趣,感觉背后一定有什么原理。于是我手写了他们所用的 DP-Adam 来看看为什么,其实这很简单:
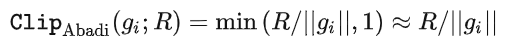
如果 R 足够小,clipping 其实等价于 normalization!简单代入 private gradient(1.1),可以将 R 从 clipping 的部分和 noising 的部分分别提出来:
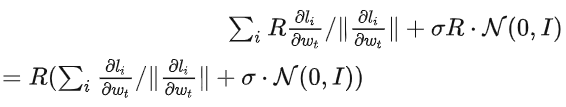
而 Adam 的形式使得 R 会同时出现在梯度和自适应的步长中,分子分母一抵消,R 就没有了,顶会 idea 就有了!
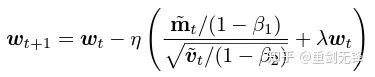
m 和 v 都依赖于梯度,同时用 private 梯度替换即得到 DP-AdamW。
就这么简单的代换,就证明了我的第一个定理:在 DP-AdamW 中,足够小的 clipping thresholds 是互相等价的,无需调参。
毫无疑问,这是一个很简明而且很有趣的观察,但这并没有足够的意义,所以我需要思考这个观察在实际中有什么用途。
其实,这意味着 DP 训练减少了一个数量级的调参工作:假设学习率和 R 各调 5 个值(如上图) ,那就要测 25 种组合才能找到最优超参数。现在只需要调学习率 5 种可能就好,调参效率提高了数倍,这是对业界来说极有价值的痛点问题。
立意足够高,数学足够简明,一个好的想法已经初具雏形。
三、简单扩展
只对 Adam/AdamW 成立的话,这个工作的局限性还是太大了,所以我很快扩展到了 AdamW 和其他 adaptive optimizers,比如 AdaGrad。事实上,对于所有的 adaptive optimizers,都可以证明 clipping threshold 会被抵消,从而不用调参,大大增加了定理的丰富程度。
这里面还有一个有趣的小细节。众所周知,Adam with weight decay 和 AdamW 不一样,后者使用的是 decoupled weight decay,就这个区别还发了篇 ICLR

Adam 有两种加 weight decay 的方式。
这个区别在 DP 优化器中也存在。同样是 Adam,用 decoupled weight decay 的话, 缩放 R 不影响 weight decay 的大小,但是用普通的 weight decay 的话,放大 R 两倍等价于缩小两倍的 weight decay。
四、另有乾坤
聪明的同学可能已经发现了 我一直再强调自适应优化器 为啥不讲讲 SGD 呢? 答案是在我写完 DP 自适应优化器的理论后 Google 紧接着就放了一篇 DP-SGD 用在 CV 的文章 也做了 ablation study 但是规律和在 Adam 上发现的完全不同 给我留下了一个对角的印象
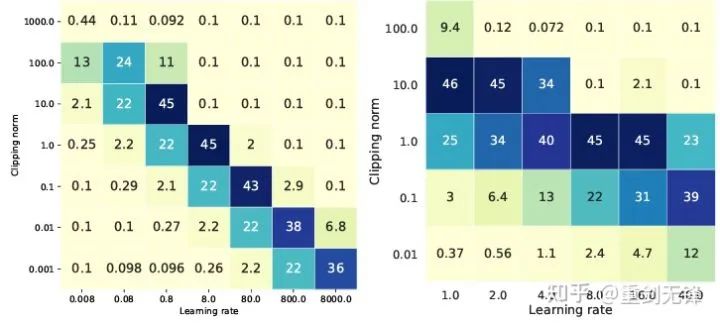
对 DP-SGD 且 R 足够小的时候,增大 10 倍 lr 等于增大 10 倍 R [https://arxiv.org/abs/2201.12328]。
当时我看到这篇文章的时候很兴奋,因为又是一个证明 small clipping threshold 效果好的论文。
在科学界,连续的巧合背后往往有着隐藏的规律。
简单地代换一下,发现 SGD 比 Adam 还好分析,(1.3)可以近似为:
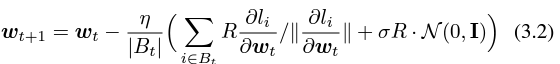
“Specifically, when the clipping norm is decreased k times, the learning rate should be increased k times to maintain similar accuracy.”
再将 SGD 的理论扩充到 momentum,所有 Pytorch 支持的优化器全都分析完毕。
五、从直觉到严谨
一个创新点是有了,但是 Abadi's clipping 严格来说只是近似 normalization,不能划等号,也就没法确凿地分析收敛性。
根据多啦 A 梦铁人兵团原理,我直接命名 normalization 为新的 per-sample gradient clipping function,替代了整个领域用了 6 年的 Abadi clipping,这是我的第二个创新点。

经过刚才的证明,新的 clipping 严格不需要 R,所以称之为 automatic clipping (AUTO-V; V for vanilla)。
既然形式上与 Abadi's clipping 有不同,那么 accuracy 就会有差异,而我的 clipping 可能有劣势。
所以我需要写代码测试我的新方法,而这只需要改动一行代码 (毕竟只是把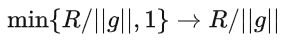 )。
)。
事实上 DP per-sample gradient clipping 这个方向主要就三种 clipping functions, 除了 Abadi's clipping 以外的两种都是我提出的,一个是 global clipping,还有一个就是这篇 automatic clipping。而在先前的工作中,我就已经知道怎么在各个流行的库中改 clipping 了,我将修改方法放在文章最后一个 appendix。
经过我的测试,我发现斯坦福的文章中 GPT2 在整个训练过程中,所有 itertation 和所有 per-sample gradient 都是 clip 过的。也就是说,至少在这一个实验上,Abadi's clipping 完全等价于 automatic clipping。虽然后来的实验的确有输于 SOTA 的情况, 但这已经说明了我的新方法有足够的价值:一个不需要调整 clipping threshold 的 clipping function,而且有时 accuracy 也不会牺牲。
六、 回归抽象思考
斯坦福的文章有两大类语言模型的实验,一类是 GPT2 为模型的生成型任务,另一类是 RoBERTa 为模型的分类型任务。虽然在生成任务上 automatic clipping 和 Abadi's clipping 等价,但是分类型任务却总是差几个点的准确率。
出于我自己的学术习惯,这个时候我不会去换数据集然后专门挑我们占优的实验发表,更不会增加 trick(比如做数据增强和魔改模型之类的)。我希望在完全公平的比较中, 只比较 per-sample gradient clipping 的前提下,尽可能做出最好的不含水分的效果。
事实上,在和合作者讨论中我们发现:纯粹的 normalization 和 Abadi's clipping 比 梯度大小的信息是完全抛弃的,也就是说对于 automatic clipping,无论原始的梯度多大,clip 后都是 R 这么大,而 Abadi 对于比 R 小的梯度是保留了大小的信息的。
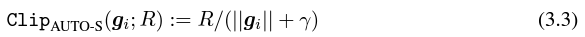
将 R 和学习率融合后变成
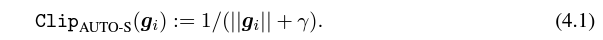
简单一画可以发现这个小小的 (一般设为 0.01,其实设成别的正数都行,很稳健)就能保留梯度大小的信息:
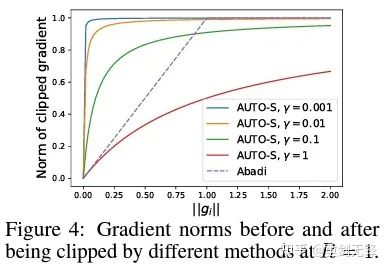
基于这个算法,还是只改动一行,把斯坦福的代码重跑一遍,六个 NLP 数据集的 SOTA 就到手了。
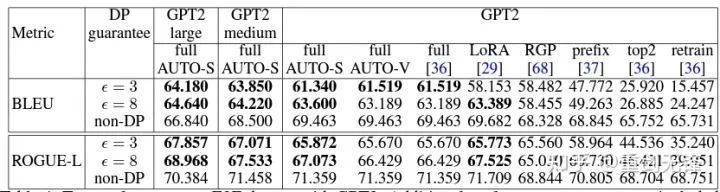
在 E2E 生成任务上,AUTO-S 超越了所有其他 clipping function,在 SST2/MNLI/QNLI/QQP 分类任务上也是。
七、要做通用算法
斯坦福文章的一个局限性是只专注于 NLP,又很巧合的是:紧接着 Google 刷了 ImageNet 的 DP SOTA 两个月后,Google 子公司 DeepMind 放出了一篇 DP 在 CV 中大放异彩的文章,直接将 ImageNet 准确率从 48% 提升到 84%!

论文地址:https://arxiv.org/abs/2204.13650
在这篇文章中,我第一时间去看优化器和 clipping threshold 的选择,直到我在附录翻到这张图:
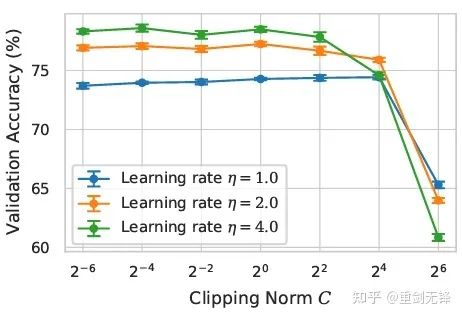
DP-SGD 在 ImageNet 上的 SOTA 也是需要 clipping threshold 足够小。
依然是 small clipping threshold 效果最好!有了三篇高质量的文章支撑 automatic clipping,已经有了很强的动机了,我越发肯定自己的工作会是非常杰出的。
巧合的是 DeepMind 这篇文章也是纯实验没有理论,这也导致他们差点就领悟出了他们可以从理论上不需要 R,事实上他们真的非常接近我的想法了,他们甚至已经发现了 R 是可以提取出来和学习率融合的(感兴趣的同学可以看看他们的公式(2)和(3))。但是 Abadi's clipping 的惯性太大了... 即使他们总结出了规律却没有更进一步。

DeepMind 也发现了 small clipping threshold 效果最好,但是没有理解为什么。
受这篇新工作的启发,我开始着手做 CV 的实验,让我的算法能被所有 DP 研究者使用,而不是 NLP 搞一套方法,CV 搞另一套。
好的算法就是应该通用好用,事实也证明 automatic clipping 在 CV 数据集上同样能取得 SOTA。
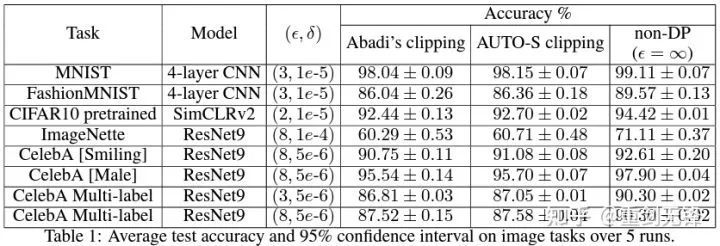
八、理论为骨 实验为翼
纵观以上所有的论文,都是 SOTA 提升显著、工程效果拔满,但是理论完全空白。
当我做完所有实验的时候,这份工作的贡献已经超过了一篇顶会的要求:我将经验上 small clipping threshold 所产生的 DP-SGD 和 DP-Adam 的参数影响大大简化;提出了新的 clipping function 而不牺牲运算效率、隐私性,还不用调参;小小的 γ 修复了 Abadi's clipping 和 normalization 对梯度大小信息的破坏;充足的 NLP 和 CV 实验都取得了 SOTA 的准确率。
我还没有满意。一个没有理论支撑的优化器,还是无法为深度学习做出实质贡献。每年顶会提出的新优化器有几十个,第二年全都扫进故纸堆。Pytorch 官方支持的、业界真正在用的,还是那么几个。
为此我和合作者们额外花了两个月做了 automatic DP-SGD 收敛性分析,过程艰难但最后的证明简化到极致。结论也很简单:将 batch size、learning rate、model size、sample size 等变量对收敛的影响都定量地表达出来,并且符合所有已知的 DP 训练行为。
特别的,我们证明了 DP-SGD 虽然收敛的比标准的 SGD 慢,但是 iteration 趋于无穷的话,收敛的速度都是一个数量级的。这为隐私计算提供了信心:DP 模型收敛,虽迟但到。
九、撞车了...
终于,写了 7 个月的文章完稿了,没想到巧合还没停。5 月份 NeurIPS 投稿,6 月 14 日内部修改完放 arXiv,结果 6 月 27 日看到微软亚州研究院(MSRA)发表了一篇和我们撞车的文章,提出的 clipping 和我们的 automatic clipping 一模一样:

和我们的 AUTO-S 分毫不差。
仔细看了看,连收敛性的证明都差不多。而我们两组人又没有交集,可以说隔着太平洋的巧合诞生了。
这里稍微讲一下两篇文章的不同:对方文章更偏理论,比如额外分析了 Abadi DP-SGD 的收敛(我只证了 automatic clipping,也就是他们文中的 DP-NSGD,可能我也不知道咋整 DP-SGD);用的假设也有一些不同;而我们实验做的多一些大一些(十几个数据集),更显式地建立了 Abadi's clipping 和 normalization 的等价关系,比如 Theorem 1 和 2 解释为什么 R 可以不用调参。
既然是同时期的工作,我很开心能有人不谋而合,互相能补充共同推动这个算法,让整个社群尽快相信这个结果并从中受益。当然,私心来说,也提醒自己下一篇要加速了!
十、总结
回顾这篇文章的创作历程,从起点来看,基本功一定是前提,而另一个重要的前提是自己心中一直念念不忘调参这个痛点问题。正是久旱,所以读到合适的文章才能逢甘露。至于过程,核心在于将观察数学化理论化的习惯,在这个工作中代码实现能力反倒不是最重要的。我会再写一篇专栏着重讲讲另一个硬核代码工作;最后的收敛性分析,也是靠合作者和自己的不将就。所幸好饭不怕晚,继续前进!

推荐阅读
分享
收藏
点赞
在看