
还没吃透 K8S 调度器?看这篇文章就够了
共 38631字,需浏览 78分钟
· 2022-08-25

1. kube-scheduler 的设计
Scheduler 在整个系统中承担了“承上启下”的重要功能。“承上”是指它负责接受 Controller Manager 创建的新 Pod,为其安排 Node;“启下”是指安置工作完成后,目标 Node 上的 kubelet 服务进程接管后续工作。Pod 是 Kubernetes 中最小的调度单元,Pod 被创建出来的工作流程如图所示:
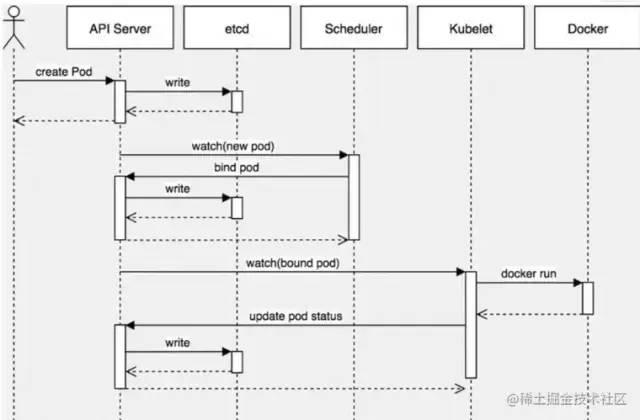
在这张图中
第一步通过 apiserver REST API 创建一个 Pod。 然后 apiserver 接收到数据后将数据写入到 etcd 中。 由于 kube-scheduler 通过 apiserver watch API 一直在监听资源的变化,这个时候发现有一个新的 Pod,但是这个时候该 Pod 还没和任何 Node 节点进行绑定,所以 kube-scheduler 就进行调度,选择出一个合适的 Node 节点,将该 Pod 和该目标 Node 进行绑定。绑定之后再更新消息到 etcd 中。 这个时候一样的目标 Node 节点上的 kubelet 通过 apiserver watch API 检测到有一个新的 Pod 被调度过来了,他就将该 Pod 的相关数据传递给后面的容器运行时(container runtime),比如 Docker,让他们去运行该 Pod。 而且 kubelet 还会通过 container runtime 获取 Pod 的状态,然后更新到 apiserver 中,当然最后也是写入到 etcd 中去的。
通过这个流程我们可以看出整个过程中最重要的就是 apiserver watch API 和kube-scheduler的调度策略。
总之,kube-scheduler 的功能是为还没有和任何 Node 节点绑定的 Pods 逐个地挑选最合适 Pod 的 Node 节点,并将绑定信息写入 etcd 中。整个调度流程分为,预选(Predicates)和优选(Priorities)两个步骤。
预选(Predicates):kube-scheduler 根据预选策略(xxx Predicates)过滤掉不满足策略的 Nodes。例如,官网中给的例子 node3 因为没有足够的资源而被剔除。 优选(Priorities):优选会根据优先策略(xxx Priority)为通过预选的 Nodes 进行打分排名,选择得分最高的 Node。例如,资源越富裕、负载越小的 Node 可能具有越高的排名。
2. kube-scheduler 源码分析
kubernetes 版本: v1.21
2.1 scheduler.New() 初始化 scheduler 结构体
在程序的入口,是通过一个 runCommand 函数来唤醒 scheduler 的操作的。首先会进入 Setup 函数,它会根据命令参数和选项创建一个完整的 config 和 scheduler。创建 scheduler 的方式就是使用 New 函数。
Scheduler 结构体:
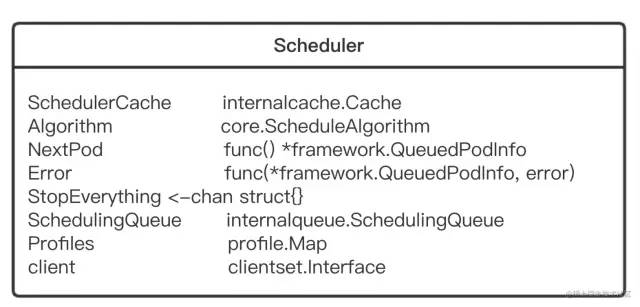
SchedulerCache:通过 SchedulerCache 做出的改变将被 NodeLister 和 Algorithm 观察到。 NextPod :应该是一个阻塞直到下一个 Pod 存在的函数。之所以不使用 channel 结构,是因为调度 pod 可能需要一些时间,k8s 不希望 pod 位于通道中变得陈旧。 Error:在出现错误的时候被调用。如果有错误,它会传递有问题的 pod 信息,和错误。 StopEverything:通过关闭它来停止 scheduler。 SchedulingQueue:保存着正在准备被调度的 pod 列表。 Profiles:调度的策略。
scheduler.New() 方法是初始化 scheduler 结构体的,该方法主要的功能是初始化默认的调度算法以及默认的调度器 GenericScheduler。
创建 scheduler 配置文件 根据默认的 DefaultProvider 初始化 schedulerAlgorithmSource然后加载默认的预选及优选算法,然后初始化GenericScheduler若启动参数提供了 policy config 则使用其覆盖默认的预选及优选算法并初始化 GenericScheduler,不过该参数现已被弃用
kubernetes/pkg/scheduler/scheduler.go:189
// New函数创建一个新的scheduler
func New(client clientset.Interface, informerFactory informers.SharedInformerFactory,recorderFactory profile.RecorderFactory, stopCh <-chan struct{},opts ...Option) (*Scheduler, error) {
//查看并设置传入的参数
……
snapshot := internalcache.NewEmptySnapshot()
// 创建scheduler的配置文件
configurator := &Configurator{……}
metrics.Register()
var sched *Scheduler
source := options.schedulerAlgorithmSource
switch {
case source.Provider != nil:
// 根据Provider创建config
sc, err := configurator.createFromProvider(*source.Provider)
……
case source.Policy != nil:
// 根据用户指定的策略(policy source)创建config
// 既然已经设置了策略,在configuation内设置extender为nil
// 如果没有,从Configuration的实例里设置extender
configurator.extenders = policy.Extenders
sc, err := configurator.createFromConfig(*policy)
……
}
// 对配置器生成的配置进行额外的调整
sched.StopEverything = stopEverything
sched.client = client
addAllEventHandlers(sched, informerFactory)
return sched, nil
}
在 New 函数里提供了两种初始化 scheduler 的方式,一种是 source.Provider,一种是 source.Policy,最后生成的 config 信息都会通过sched = sc创建新的调度器。Provider 方法对应的是createFromProvider函数,Policy 方法对应的是createFromConfig函数,最后它们都会调用 Create 函数,实例化 podQueue,返回配置好的 Scheduler 结构体。
2.2 Run() 启动主逻辑
kubernetes 中所有组件的启动流程都是类似的,首先会解析命令行参数、添加默认值,kube-scheduler 的默认参数在 k8s.io/kubernetes/pkg/scheduler/apis/config/v1alpha1/defaults.go 中定义的。然后会执行 run 方法启动主逻辑,下面直接看 kube-scheduler 的主逻辑 run 方法执行过程。
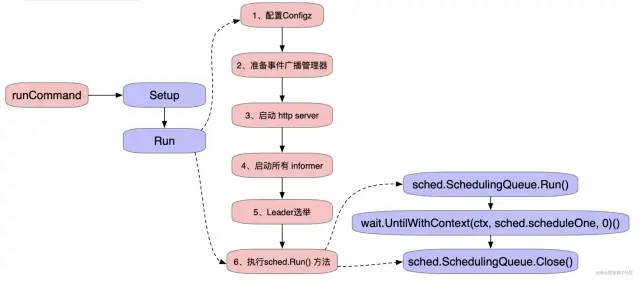
Run() 方法主要做了以下工作:
配置了 Configz 参数 启动事件广播器,健康检测服务,http server 启动所有的 informer 执行 sched.Run()方法,执行主调度逻辑
kubernetes/cmd/kube-scheduler/app/server.go:136
// Run 函数根据指定的配置执行调度程序。当出现错误或者上下文完成的时候才会返回。
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// 为了帮助debug,先记录Kubernetes的版本号
klog.V(1).Infof("Starting Kubernetes Scheduler version %+v", version.Get())
// 1、配置Configz
if cz, err := configz.New("componentconfig"); err == nil {……}
// 2、准备事件广播管理器,此处涉及到Events事件
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
// 3、启动 http server,进行健康监控服务器监听
if cc.InsecureServing != nil {……}
if cc.InsecureMetricsServing != nil {……}
if cc.SecureServing != nil {……}
// 4、启动所有 informer
cc.InformerFactory.Start(ctx.Done())
// 等待所有的缓存同步后再进行调度。
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// 5、因为Master节点可以存在多个,选举一个作为Leader。通过 LeaderElector 运行命令直到完成并退出。
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
// 6、执行 sched.Run() 方法,执行主调度逻辑
sched.Run(ctx)
},
// 钩子函数,开启Leading时运行调度,结束时打印报错
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
// 参加选举的会持续通信
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// 领导者选举失败,所以runCommand函数会一直运行直到完成
close(waitingForLeader)
// 6、执行 sched.Run() 方法,执行主调度逻辑
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
这里相比 16 版本增加了一个 waitingForLeader的 channel 用来监听信号Setup 函数中提到了 Informer。k8s 中有各种类型的资源,包括自定义的。而 Informer 的实现就将调度和资源结合了起来。pod informer 的启动逻辑是,只监听 status.phase不为 succeeded 以及 failed 状态的 pod,即非 terminating 的 pod。
2.3 sched.Run()开始监听和调度
然后继续看 Run() 方法中最后执行的 sched.Run() 调度循环逻辑,若 informer 中的 cache 同步完成后会启动一个循环逻辑执行 sched.scheduleOne 方法。
kubernetes/pkg/scheduler/scheduler.go:313
// Run函数开始监视和调度。SchedulingQueue开始运行。一直处于调度状态直到Context完成一直阻塞。
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}sched.SchedulingQueue.Run():会将 backoffQ 中的 Pods 节点和 unschedulableQ 中的节点移至 activeQ 中。即将之前运行失败的节点和已经等待了很长时间超过时间设定的节点重新进入活跃节点队列中。backoffQ 是并发编程中常见的一种机制,就是如果一个任务重复执行,但依旧失败,则会按照失败的次数提高重试等待时间,避免频繁重试浪费资源。 sched.SchedulingQueue.Close(),关闭调度之后,对队列也进行关闭。SchedulingQueue 是一个优先队列。优先作为实现 SchedulingQueue 的实现,其核心数据结构主要包含三个队列:activeQ、podBackoffQ、unschedulableQ 内部通过 cond 来实现 Pop 操作的阻塞与通知。当前队列中没有可调度的 pod 的时候,则通过 cond.Wait 来进行阻塞,然后在往 activeQ 中添加 pod 的时候通过 cond.Broadcast 来实现通知。 wait.UntilWithContext()中出现了 sched.scheduleOne 函数,它负责了为单个 Pod 执行整个调度工作流程,也是本次研究的重点,接下来将会详细地进行分析。
2.4 scheduleOne() 分配 pod 的流程
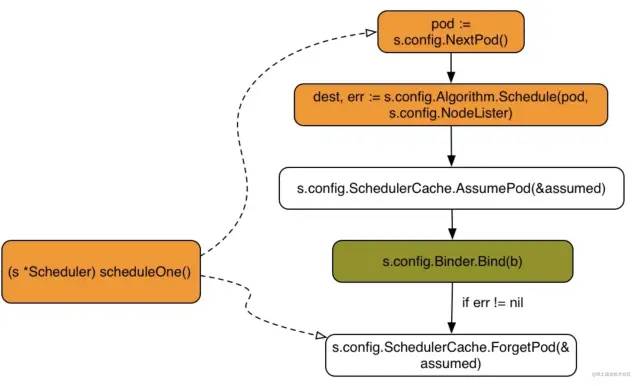
scheduleOne() 每次对一个 pod 进行调度,主要有以下步骤:
从 scheduler 调度队列中取出一个 pod,如果该 pod 处于删除状态则跳过 执行调度逻辑 sched.schedule()返回通过预算及优选算法过滤后选出的最佳 node如果过滤算法没有选出合适的 node,则返回 core.FitError 若没有合适的 node 会判断是否启用了抢占策略,若启用了则执行抢占机制 执行 reserve plugin pod 对应的 spec.NodeName 写上 scheduler 最终选择的 node,更新 scheduler cache 执行 permit plugin 执行 prebind plugin 进行绑定,请求 apiserver 异步处理最终的绑定操作,写入到 etcd 执行 postbind plugin
kubernetes/pkg/scheduler/scheduler.go:441
准备工作
// scheduleOne为单个pod做整个调度工作流程。它被序列化在调度算法的主机拟合上。
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// podInfo就是从队列中获取到的Pod对象
podInfo := sched.NextPod()
// 检查pod的有效性,当 schedulerQueue 关闭时,pod 可能为nil
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
//根据定义的pod.Spec.SchedulerName查到对应的profile
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// 这不应该发生,因为我们只接受调度指定与配置文件之一匹配的调度程序名称的pod。
klog.ErrorS(err, "Error occurred")
return
}
// 可以跳过调度的情况,一般pod进不来
if sched.skipPodSchedule(fwk, pod) {
return
}
klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))
调用调度算法,获取结果
// 执行调度策略选择node
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, fwk, state, pod)
if err != nil {
/*
出现调度失败的情况:
这个时候可能会触发抢占preempt,抢占是一套复杂的逻辑,这里略去
目前假设各类资源充足,能正常调度
*/
}
assumedPod 是假设这个 Pod 按照前面的调度算法分配后,进行验证。告诉缓存假设一个 pod 现在正在某个节点上运行,即使它还没有被绑定。这使得我们可以继续调度,而不需要等待绑定的发生。
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// 为pod设置NodeName字段,更新scheduler缓存
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {……} // 如果出现错误,重新开始调度
// 运行相关插件的代码不作展示,这里省略运行reserve插件的Reserve方法、运行 "permit" 插件、 运行 "prebind" 插件.
// 真正做绑定的动作
err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)
if err != nil {
// 错误处理,清除状态并重试
} else {
// 打印结果,调试时将log level调整到2以上
if klog.V(2).Enabled() {
klog.InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
}
// metrics中记录相关的监控指标
metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts))
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(podInfo)).Observe(metrics.SinceInSeconds(podInfo.InitialAttemptTimestamp))
// 运行 "postbind" 插件
Binder 负责将调度器的调度结果,传递给 apiserver,即将一个 pod 绑定到选择出来的 node 节点。
2.5 sched.Algorithm.Schedule() 选出 node
在上一节中scheduleOne() 通过调用 sched.Algorithm.Schedule() 来执行预选与优选算法处理:
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, fwk, state, pod)
Schedule()方法属于 ScheduleAlgorithm 接口的一个方法实现。ScheduleAlgorithm 是一个知道如何将 pods 调度到机器上的事物实现的接口。在 1.16 版本中 ScheduleAlgorithm 有四个方法——Schedule()、Preempt()、Predicates():Prioritizers(),现在则是Schedule()、Extenders() 在目前的代码中进行优化,保证了程序的安全性。代码中有一个 todo,目前的
名字已经不太符合这个接口所做的工作。
kubernetes/pkg/scheduler/core/generic_scheduler.go 61
type ScheduleAlgorithm interface {
Schedule(context.Context, framework.Framework, *framework.CycleState, *v1.Pod) (scheduleResult ScheduleResult, err error)
// 扩展器返回扩展器配置的一个片断。这是为测试而暴露的。
Extenders() []framework.Extender
}点击查看 Scheduler()的具体实现,发现它是由 genericScheduler 来进行实现的。
kubernetes/pkg/scheduler/core/generic_scheduler.go 97
func (g *genericScheduler) Schedule(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
// 1.快照 node 信息,每次调度 pod 时都会获取一次快照
if err := g.snapshot(); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if g.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
// 2.Predict阶段:找到所有满足调度条件的节点feasibleNodes,不满足的就直接过滤
feasibleNodes, diagnosis, err := g.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
// 3.预选后没有合适的 node 直接返回
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
Pod: pod,
NumAllNodes: g.nodeInfoSnapshot.NumNodes(),
Diagnosis: diagnosis,
}
}
// 4.当预选之后只剩下一个node,就使用它
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
FeasibleNodes: 1,
}, nil
}
// 5.Priority阶段:执行优选算法,获取打分之后的node列表
priorityList, err := g.prioritizeNodes(ctx, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
// 6.根据打分选择分数最高的node
host, err := g.selectHost(priorityList)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
}
流程图如图所示:
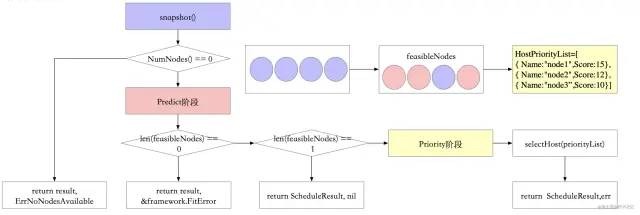
在程序运行的整个过程中会使用 trace 来记录当前的运行状态,做安全处理。 如果超过了 trace 预定的时间会进行回滚
至此整个 Scheduler 分配 node 节点给 pod 的调度策略的基本流程介绍完毕。
2.6 总结
在本章节中,首先对 Kube-scheduler 进行了介绍。它在整个 k8s 的系统里,启承上启下的中药作用,是核心组件之一。它的目的就是为每一个 pod 选择一个合适的 node,整体流程可以概括为五步:
首先是 scheduler 组件的初始化; 其次是客户端发起 command,启动调度过程中用的服务,比如事件广播管理器,启动所有的 informer 组件等等; 再次是启动整个调度器的主流程,特别需要指出的是,整个流程都会堵塞在 wait.UntilWithContext()这个函数中,一直调用ScheduleOne()进行 pod 的调度分配策略。然后客户获取未调度的 podList,通过执行调度逻辑 sched.schedule()为 pod 选择一个合适的 node,如果没有合适的 node,则触发抢占的操作,最后提进行绑定,请求 apiserver 异步处理最终的绑定操作,写入到 etcd,其核心则是一系列调度算法的设计与执行。最后对一系列的调度算法进行了解读,调度过程主要为,对当前的节点情况做快照,然后通过预选和优选两个主要步骤,为 pod 分配一个合适的 node。
3. 预选与优选算法源码细节分析
3.1 预选算法
预选顾名思义就是从当前集群中的所有的 node 中进行过滤,选出符合当前 pod 运行的 nodes。预选的核心流程是通过findNodesThatFit来完成,其返回预选结果供优选流程使用。预选算法的主要逻辑如图所示:

kubernetes/pkg/scheduler/core/generic_scheduler.go 223
// 根据prefilter插件和extender过滤节点以找到适合 pod 的节点。
func (g *genericScheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) {
// prefilter插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。
s := fwk.RunPreFilterPlugins(ctx, state, pod)
……
// 查找能够满足filter过滤插件的节点,返回结果有可能是0,1,N
feasibleNodes, err := g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, allNodes)
// 查找能够满足Extenders过滤插件的节点,返回结果有可能是0,1,N
feasibleNodes, err = g.findNodesThatPassExtenders(pod, feasibleNodes, diagnosis.NodeToStatusMap)
return feasibleNodes, diagnosis, nil
}
这个方法首先会通过前置过滤器来校验 pod 是否符合条件; 然后调用 findNodesThatPassFilters方法过滤掉不符合条件的 node。这样就能设定最多需要检查的节点数,作为预选节点数组的容量,避免总结点过多影响效率。最后是 findNodesThatPassExtenders函数,它是 kubernets 留给用户的外部扩展方式,暂且不表。
findNodesThatPassFilters查找适合过滤器插件的节点,在这个方法中首先会根据numFeasibleNodesToFind方法选择参与调度的节点的数量,调用Parallelizer().Until方法开启 16 个线程来调用checkNode方法寻找合适的节点。判别节点合适的方式函数为checkNode(),函数中会对节点进行两次检查,确保所有的节点都有相同的机会被选择。
kubernetes/pkg/scheduler/core/generic_scheduler.go 274
func (g *genericScheduler) findNodesThatPassFilters(ctx context.Context,fwk framework.Framework,state *framework.CycleState,pod *v1.Pod,diagnosis framework.Diagnosis,nodes []*framework.NodeInfo) ([]*v1.Node, error) {……}
// 根据集群节点数量选择参与调度的节点的数量
numNodesToFind := g.numFeasibleNodesToFind(int32(len(nodes)))
// 初始化一个大小和numNodesToFind一样的数组,用来存放node节点
feasibleNodes := make([]*v1.Node, numNodesToFind)
……
checkNode := func(i int) {
// 我们从上一个调度周期中停止的地方开始检查节点,这是为了确保所有节点都有相同的机会在 pod 中被检查
nodeInfo := nodes[(g.nextStartNodeIndex+i)%len(nodes)]
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.Code() == framework.Error {
errCh.SendErrorWithCancel(status.AsError(), cancel)
return
}
//如果该节点合适,那么放入到feasibleNodes列表中
if status.IsSuccess() {……}
}
……
// 开启N个线程并行寻找符合条件的node节点,数量等于feasibleNodes。一旦找到配置的可行节点数,就停止搜索更多节点。
fwk.Parallelizer().Until(ctx, len(nodes), checkNode)
processedNodes := int(feasibleNodesLen) + len(diagnosis.NodeToStatusMap)
//设置下次开始寻找node的位置
g.nextStartNodeIndex = (g.nextStartNodeIndex + processedNodes) % len(nodes)
// 合并返回结果
feasibleNodes = feasibleNodes[:feasibleNodesLen]
return feasibleNodes, nil
}
在整个函数调用的过程中,有个很重要的函数——checkNode()会被传入函数,进行每个 node 节点的判断。具体更深入的细节将会在 3.1.2 节进行介绍。现在根据这个函数的定义可以看出,RunFilterPluginsWithNominatedPods会判断当前的 node 是否符合要求。如果当前的 node 符合要求,就讲当前的 node 加入预选节点的数组中(feasibleNodes),如果不符合要求,那么就加入到失败的数组中,并且记录原因。
3.1.1 确定参与调度的节点的数量
numFeasibleNodesToFind 返回找到的可行节点的数量,调度程序停止搜索更多可行节点。算法的具体逻辑如下图所示:
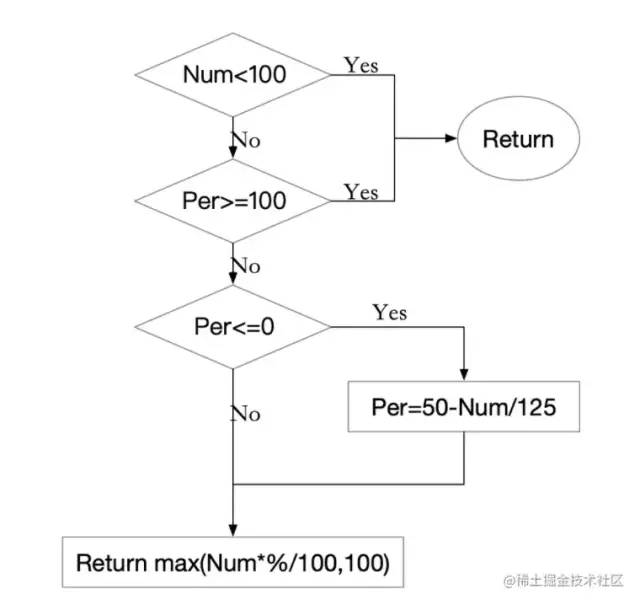
找出能够进行调度的节点,如果节点小于 minFeasibleNodesToFind(默认值为 100),那么全部节点参与调度。percentageOfNodesToScore参数值是一个集群中所有节点的百分比,范围是 1 和 100 之间,0 表示不启用。如果集群节点数大于 100,那么就会根据这个值来计算让合适的节点数参与调度。举个例子,如果一个 5000 个节点的集群, percentageOfNodesToScore会默认设置为 10%,也就是 500 个节点参与调度。因为如果一个 5000 节点的集群来进行调度的话,不进行控制时,每个 pod 调度都需要尝试 5000 次的节点预选过程时非常消耗资源的。如果百分比后的数目小于 minFeasibleNodesToFind,那么还是要返回最小节点的数目。
kubernetes/pkg/scheduler/core/generic_scheduler.go 179
func (g *genericScheduler) numFeasibleNodesToFind(numAllNodes int32) (numNodes int32) {
// 对于一个小于minFeasibleNodesToFind(100)的节点,全部节点参与调度
// percentageOfNodesToScore参数值是一个集群中所有节点的百分比,范围是1和100之间,0表示不启用,如果大于100,就是全量取样
// 这两种情况都是直接便利整个集群中的所有节点
if numAllNodes < minFeasibleNodesToFind || g.percentageOfNodesToScore >= 100 {
return numAllNodes
}
adaptivePercentage := g.percentageOfNodesToScore
//当numAllNodes大于100时,如果没有设置percentageOfNodesToScore,那么这里需要计算出一个值
if adaptivePercentage <= 0 {
basePercentageOfNodesToScore := int32(50)
adaptivePercentage = basePercentageOfNodesToScore - numAllNodes/125
if adaptivePercentage < minFeasibleNodesPercentageToFind {
adaptivePercentage = minFeasibleNodesPercentageToFind
}
}
// 正常取样计算,比如numAllNodes为5000,而adaptivePercentage为50%
// 则numNodes=50000*0.5/100=250
numNodes = numAllNodes * adaptivePercentage / 100
// 也不能太小,不能低于minFeasibleNodesToFind的值
if numNodes < minFeasibleNodesToFind {
return minFeasibleNodesToFind
}
return numNodes
}
3.1.2 并行化二次筛选节点
并行取样主要通过调用工作队列的ParallelizeUntil函数来启动 N 个 goroutine 来进行并行取样,并通过 ctx 来协调退出。选取节点的规则由函数 checkNode 来定义,checkNode里面使用RunFilterPluginsWithNominatedPods筛选出合适的节点。
在 k8s 中经过调度器调度后的 pod 结果会放入到 SchedulingQueue 中进行暂存,这些 pod 未来可能会经过后续调度流程运行在提议的 node 上,也可能因为某些原因导致最终没有运行,而预选流程为了减少后续因为调度冲突,则会在进行预选的时候,将这部分 pod 考虑进去。如果在这些 pod 存在的情况下,node 可以满足当前 pod 的筛选条件,则可以去除被提议的 pod 再进行筛选。
在抢占的情况下我们会运行两次过滤器。如果节点有大于或等于优先级的被提名的 pod,我们在这些 pod 被添加到 PreFilter 状态和 nodeInfo 时运行它们。如果所有的过滤器在这一次都成功了,我们在这些被提名的 pod 没有被添加时再运行它们。
kubernetes/pkg/scheduler/framework/runtime/framework.go 650
func (f *frameworkImpl) RunFilterPluginsWithNominatedPods(ctx context.Context, state *framework.CycleState, pod *v1.Pod, info *framework.NodeInfo) *framework.Status {
var status *framework.Status
// podsAdded主要用于标识当前是否有提议的pod如果没有提议的pod则就不需要再进行一轮筛选了。
podsAdded := false
//待检查的 Node 是一个即将被抢占的节点,调度器就会对这个Node用同样的 Predicates 算法运行两遍。
for i := 0; i < 2; i++ {
stateToUse := state
nodeInfoToUse := info
//处理优先级pod的逻辑
if i == 0 {
var err error
//查找是否有优先级大于或等于当前pod的NominatedPods,然后加入到nodeInfoToUse中
podsAdded, stateToUse, nodeInfoToUse, err = addNominatedPods(ctx, f, pod, state, info)
// 如果第一轮筛选出错,则不会进行第二轮筛选
if err != nil {
return framework.AsStatus(err)
}
} else if !podsAdded || !status.IsSuccess() {
break
}
//运行过滤器检查该pod是否能运行在该节点上
statusMap := f.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse)
status = statusMap.Merge()
if !status.IsSuccess() && !status.IsUnschedulable() {
return status
}
}
return status
}
这个方法用来检测 node 是否能通过过滤器,此方法会在调度 Schedule 和抢占 Preempt 的时被调用,如果在 Schedule 时被调用,那么会测试 node,能否可以让所有存在的 pod 以及更高优先级的 pod 在该 node 上运行。如果在抢占时被调用,那么我们首先要移除抢占失败的 pod,添加将要抢占的 pod。
RunFilterPlugins 会运行过滤器,过滤器总共有这些:nodeunschedulable, noderesources, nodename, nodeports, nodeaffinity, volumerestrictions, tainttoleration, nodevolumelimits, nodevolumelimits, nodevolumelimits, nodevolumelimits, volumebinding, volumezone, podtopologyspread, interpodaffinity。这里就不详细赘述。
至此关于预选模式的调度算法的执行过程已经分析完毕。
3.2 优选算法
优选阶段通过分离计算对象来实现多个 node 和多种算法的并行计算,并且通过基于二级索引来设计最终的存储结果,从而达到整个计算过程中的无锁设计,同时为了保证分配的随机性,针对同等优先级的采用了随机的方式来进行最终节点的分配。这个思路很值得借鉴。
在上文中,我们提到在优化过程是先通过 prioritizeNodes 获得 priorityList,然后再通过 selectHost 函数获得得分最高的 Node,返回结果。
3.2.1 prioritizeNodes
在 prioritizeNodes 函数中会将需要调度的 Pod 列表和 Node 列表传入各种优选算法进行打分排序,最终整合成结果集 priorityList。priorityList 是一个 framework.NodeScoreList 的结构体,结构如下面的代码所示:
// NodeScoreList 声明一个节点列表及节点分数
type NodeScoreList []NodeScore
// NodeScore 节点和节点分数的结构体
type NodeScore struct {
Name string
Score int64
}
prioritizeNodes 通过运行评分插件对节点进行优先排序,这些插件从 RunScorePlugins()的调用中为每个节点返回一个分数。每个插件的分数和 Extender 的分数加在一起,成为该节点的分数。整个流程如图所示:
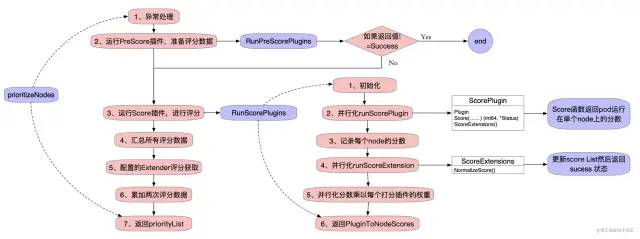
由于 prioritizeNodes 的逻辑太长,这里将他们分四个部分,如下所示:
准备阶段
func (g *genericScheduler) prioritizeNodes(ctx context.Context, fwk framework.Framework,state *framework.CycleState, pod *v1.Pod,nodes []*v1.Node,) (framework.NodeScoreList, error) {
// 如果没有提供优先级配置(即没有Extender也没有ScorePlugins),则所有节点的得分为 1。这是生成所需格式的优先级列表所必需的
if len(g.extenders) == 0 && !fwk.HasScorePlugins() {
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{
Name: nodes[i].Name,
Score: 1,
})
}
return result, nil
}
// 运行PreScore插件,准备评分数据
preScoreStatus := fwk.RunPreScorePlugins(ctx, state, pod, nodes)
if !preScoreStatus.IsSuccess() {
return nil, preScoreStatus.AsError()
}
运行 Score 插件进行评分
// 运行Score插件对Node进行评分,此处需要知道的是scoresMap的类型是map[string][]NodeScore。scoresMap的key是插件名字,value是该插件对所有Node的评分
scoresMap, scoreStatus := fwk.RunScorePlugins(ctx, state, pod, nodes)
if !scoreStatus.IsSuccess() {
return nil, scoreStatus.AsError()
}
// result用于汇总所有分数
result := make(framework.NodeScoreList, 0, len(nodes))
// 将分数按照node的维度进行汇总,循环执行len(nodes)次
for i := range nodes {
// 先在result中塞满所有node的Name,Score初始化为0;
result = append(result, framework.NodeScore{Name: nodes[i].Name, Score: 0})
// 执行了多少个scoresMap就有多少个Score,所以这里遍历len(scoresMap)次;
for j := range scoresMap {
// 每个算法对应第i个node的结果分值加权后累加;
result[i].Score += scoresMap[j][i].Score
}
}
Score 插件中获取的分数会直接记录在 result[i].Score,result 就是最终返回结果的 priorityList。
RunScorePlugins里面分别调用 parallelize.Until 方法跑三次来进行打分:
第一次会调用runScorePlugin方法,里面会调用 getDefaultConfig 里面设置的 score 的 Plugin 来进行打分;
第二次会调用runScoreExtension方法,里面会调用 Plugin 的NormalizeScore方法,用来保证分数必须是 0 到 100 之间,不是每一个 plugin 都会实现 NormalizeScore 方法。
第三次会调用遍历所有的scorePlugins,并对对应的算出的来的分数乘以一个权重。
打分的 plugin 共有:noderesources, imagelocality, interpodaffinity, noderesources, nodeaffinity, nodepreferavoidpods, podtopologyspread, tainttoleration
配置的 Extender 的评分获取
// 如果配置了Extender,还要调用Extender对Node评分并累加到result中
if len(g.extenders) != 0 && nodes != nil {
// 因为要多协程并发调用Extender并统计分数,所以需要锁来互斥写入Node分数
var mu sync.Mutex
var wg sync.WaitGroup
// combinedScores的key是Node名字,value是Node评分
combinedScores := make(map[string]int64, len(nodes))
for i := range g.extenders {
// 如果Extender不管理Pod申请的资源则跳过
if !g.extenders[i].IsInterested(pod) {
continue
}
// 启动协程调用Extender对所有Node评分。
wg.Add(1)
go func(extIndex int) {
defer func() {
wg.Done()
}()
// 调用Extender对Node进行评分
prioritizedList, weight, err := g.extenders[extIndex].Prioritize(pod, nodes)
if err != nil {
//扩展器的优先级错误可以忽略,让k8s/其他扩展器确定优先级。
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
// Extender的权重是通过Prioritize()返回的,其实该权重是人工配置的,只是通过Prioritize()返回使用上更方便。
// 合并后的评分是每个Extender对Node评分乘以权重的累加和
combinedScores[host] += score * weight
}
mu.Unlock()
}(i)
}
// 等待所有的go routines结束,调用时间取决于最慢的Extender。
wg.Wait()
Extender 这里有几个很有趣的设置
首先是扩展器中如果出现了评分的错误,可以忽略,而不是想预选阶段那样直接返回报错。 能这样做的原因是,因为评分不同于过滤,对错误不敏感。过滤如果失败是要返回错误的(如果不能忽略),因为 Node 可能无法满足 Pod 需求;而评分无非是选择最优的节点,评分错误只会对选择最优有一点影响,但是不会造成故障。 其次是使用了 combinedScores 来记录分数,考虑到 Extender 和 Score 插件返回的评分的体系会存在出入,所以这边并没有直接累加。而是后续再进行一次遍历麻将 Extender 的评分标准化之后才与原先的 Score 插件评分进行累加。 最后是关于锁的使用 在评分的设置里面,使用了多协程来并发进行评分。在最后分数进行汇总的时候会出现并发写的问题,为了避免这种现象的出现,k8s 的程序中对从 prioritizedList 里面读取节点名称和分数,然后写入 combinedScores的过程中上了互斥锁。为了记录所有并发读取 Extender 的协程,这里使用了 wait Group 这样的数据结构来保证,所有的 go routines 结束再进行最后的分数累加。这里存在一个程序性能的问题,所有的线程只要有一个没有运行完毕,程序就会卡在这一步。即便是多协程并发调用 Extender,也会存在木桶效应,即调用时间取决于最慢的 Extender。虽然 Extender 可能都很快,但是网络延时是一个比较常见的事情,更严重的是如果 Extender 异常造成调度超时,那么就拖累了整个 kube-scheduler 的调度效率。这是一个后续需要解决的问题
分数的累加,返回结果集 priorityList
for i := range result {
// 最终Node的评分是所有ScorePlugin分数总和+所有Extender分数总和
// 此处标准化了Extender的评分,使其范围与ScorePlugin一致,否则二者没法累加在一起。
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
}
}
return result, nil
}
优选算法由一系列的 PriorityConfig(也就是 PriorityConfig 数组)组成,每个 Config 代表了一个算法,Config 描述了权重 Weight、Function(一种优选算法函数类型)。需要调度的 Pod 分别对每个合适的 Node(N)执行每个优选算法(A)进行打分,最后得到一个二维数组,元素分别为 A1N1,A1N2,A1N3… ,行代表一个算法对应不同的 Node 计算得到的分值,列代表同一个 Node 对应不同算法的分值:
| N1 | N2 | N3 | |
|---|---|---|---|
| A1 | { Name:“node1”,Score:5,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:3,PriorityConfig:{…weight:1}} | { Name:“node3”,Score:1,PriorityConfig:{…weight:1}} |
| A2 | { Name:“node1”,Score:6,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:2,PriorityConfig:{…weight:1}} | { Name:“node3”,Score:3,PriorityConfig:{…weight:1}} |
| A3 | { Name:“node1”,Score:4,PriorityConfig:{…weight:1}} | { Name:“node2”,Score:7,PriorityConfig:{…weight:1.}} | { Name:“node3”,Score:2,PriorityConfig:{…weight:1}} |
最后将结果合并(Combine)成一维数组 HostPriorityList :HostPriorityList =[{ Name:"node1",Score:15},{ Name:"node2",Score:12},{ Name:"node3",Score:6}]这样就完成了对每个 Node 进行优选算法打分的流程。
Combine 的过程非常简单,只需要将 Node 名字相同的分数进行加权求和统计即可。
最终得到一维数组 HostPriorityList,也就是前面提到的 HostPriority 结构体的集合。就这样实现了为每个 Node 的打分 Priority 优选过程。
3.2.2 selectHost选出得分最高的 Node
priorityList 数组保存了每个 Node 的名字和它对应的分数,最后通过selectHost函数选出分数最高的 Node 对 Pod 进行绑定和调度。selectHost通过传入的 priorityList,然后以随机筛选的的方式从得分最高的节点们中挑选一个。
这里的随机筛选是指的当多个 host 优先级相同的时候,会有一定的概率用当前的 node 替换之前的优先级相等的 node(到目前为止的优先级最高的 node), 其主要通过`cntOfMaxScore和rand.Intn(cntOfMaxScore)来进行实现。
// selectHost()根据所有可行Node的评分找到最优的Node
func (g *genericScheduler) selectHost(nodeScoreList framework.NodeScoreList) (string, error) {
// 没有可行Node的评分,返回错误
if len(nodeScoreList) == 0 {
return "", fmt.Errorf("empty priorityList")
}
// 在nodeScoreList中找到分数最高的Node,初始化第0个Node分数最高
maxScore := nodeScoreList[0].Score
selected := nodeScoreList[0].Name
// 如果最高分数相同,先统计数量(cntOfMaxScore)
cntOfMaxScore := 1
for _, ns := range nodeScoreList[1:] {
if ns.Score > maxScore {
maxScore = ns.Score
selected = ns.Name
cntOfMaxScore = 1
} else if ns.Score == maxScore {
// 分数相同就累计数量
cntOfMaxScore++
if rand.Intn(cntOfMaxScore) == 0 {
//以1/cntOfMaxScore的概率成为最优Node
selected = ns.Name
}
}
}
return selected, nil
}
只有同时满足 FilterPlugin 和 Extender 的过滤条件的 Node 才是可行 Node,调度算法优先用 FilterPlugin 过滤,然后在用 Extender 过滤,这样可以尽量减少传给 Extender 的 Node 数量;调度算法为待调度的 Pod 对每个可行 Node(过滤通过)进行评分,评分方法是:
其中 f(x)和 g(x)是标准化分数函数,w 为权重;分数最高的 Node 为最优候选 Node,当有多个 Node 都为最高分数时,每个 Node 有 1/n 的概率成最优 Node;调度算法并不是对调度框架和调度插件再抽象和封装,只是对调度周期从 PreFilter 到 Score 的过程的一种抽象,其中 PostFilter 不在调度算法抽象范围内。因为 PostFilter 与过滤无关,是用来实现抢占的扩展点;
3.3 总结
Scheduler 调度器,在 k8s 的整个代码中处于一个承上启下的作用。了解 Scheduler 在哪个过程中发挥作用,更能够理解它的重要性。
本文第二章,主要对于 kube-scheduler v1.21 的调度流程进行了分析,但由于选择的议题实在是太大,这里这对正常流程中的调度进行源码的解析,其中有大量的细节都暂未提及,包括抢占调度、framework、extender 等实现。通过源码阅读可以发现,Pod 的调度是通过一个队列 SchedulingQueue 异步工作的,队列对 pod 时间进行监听,并且进行调度流程。单个 pod 的调度主要分为 3 个步骤:
1)根据 Predict 和 Priority 两个阶段选择最优的 Node; 2)为了提升效率,假设 Pod 已经被调度到对应的 Node,保存到 cache 中; 3)通过 extender 和各种插件进行验证,如果通过就进行绑定。
在接受到命令之后,程序会现在scheduler.New() 初始化 scheduler 结构体,然后通过 Run() 函数启动调度的主逻辑,唤醒 sched.Run()。在 sched.Run()中会一直监听和调度,通过队列的方式给 pod 分配合适的 node。scheduleOne() 里面是整个分配 pod 调度过程的主要逻辑,因为篇幅有限,这里只对 sched.Algorithm.Schedule() 进行了深入的了解。bind 和后续的操作就停留在scheduleOne()这里没有再进行深入。
因篇幅有限,以及个人的兴趣导向,在正常流程介绍完毕之后第三章对正常调度过程中的优选和预选策略再次进行深入的代码阅读。以期能够对正常调度的细节有更好的把握。如果时间可以再多些,可以更细致到对具体的调度算法进行分析,这里因为篇幅有限,预选的部分就只介绍了根据 predict 过程中的 NameNode 函数。
- END -
链接:https://juejin.cn/post/7133192540215312420
(版权归原作者所有,侵删)