 数据派THU
数据派THU





本文约5200字,建议阅读10分钟 本文主要介绍了小红书数据流团队基于Apache Iceberg在实时数仓领域的探索与实践。

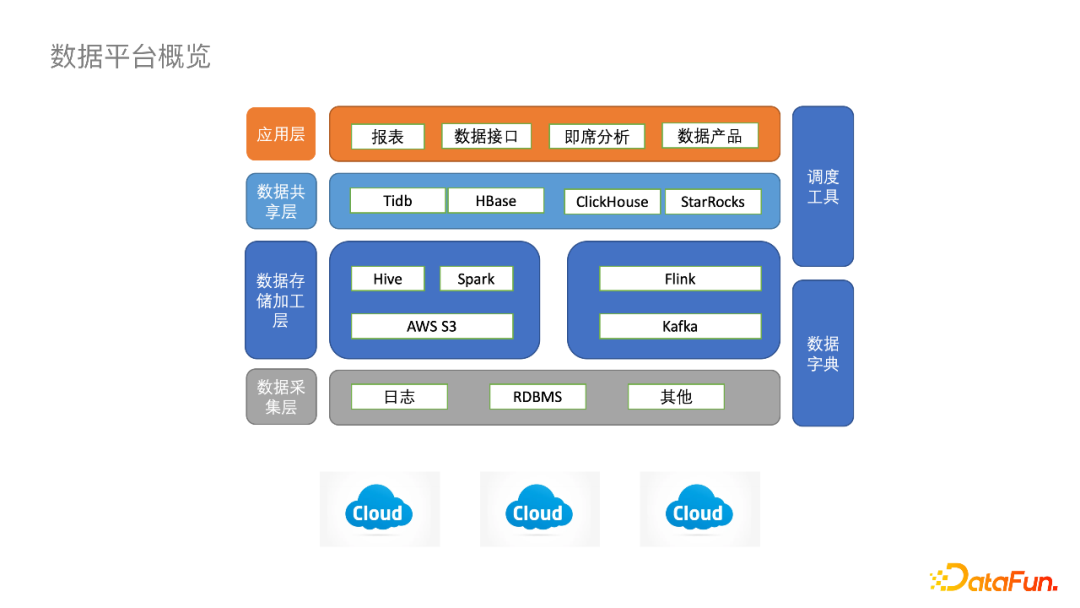
日志数据入湖 CDC实时入湖 实时湖分析探索 未来规划
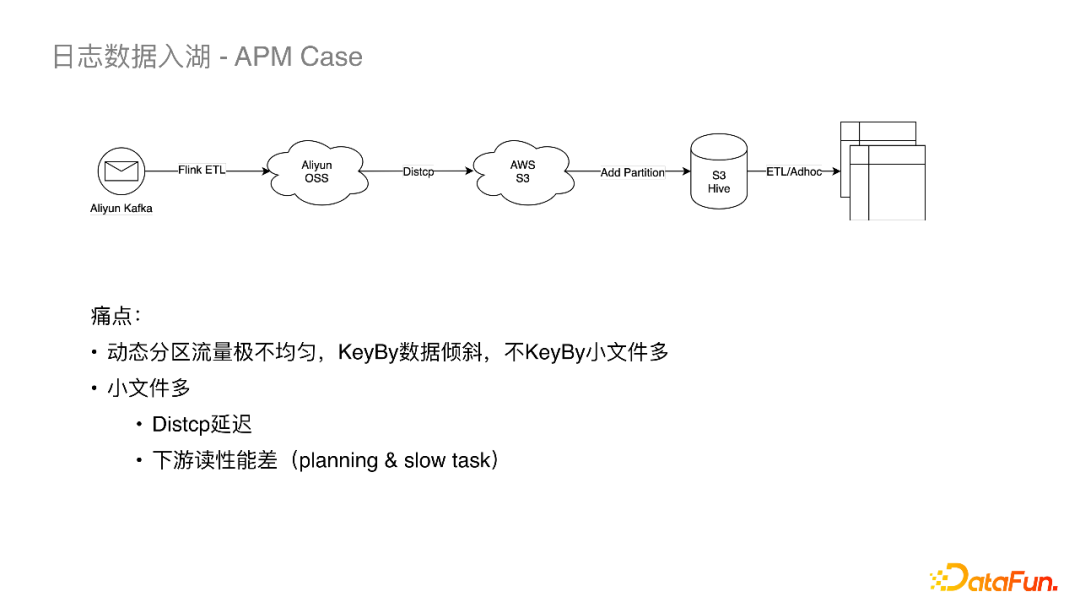
Distcp会变得非常慢,导致数据延迟在小时级以上。 流量小的很多文件集中在一个Task,导致查询性能差。
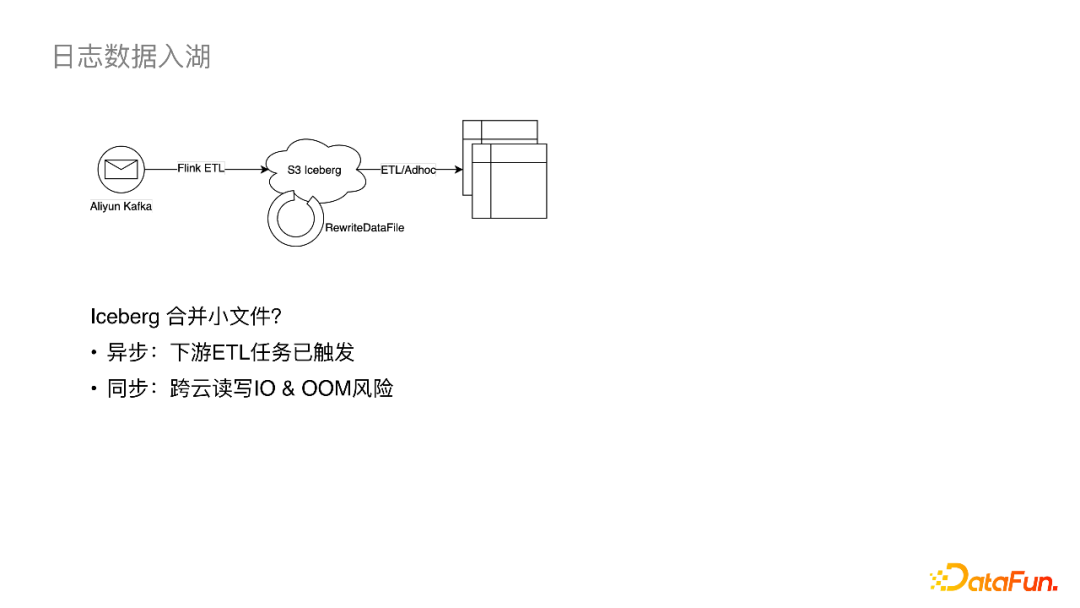
异步的小文件合并为周期调度,但是Iceberg在commit之后,下游ETL读文件作业会立即执行,在这之后再挂异步合并作业的意义就不大了。 如果同步合并小文件,即在Flink入湖作业中挂一个合并算子,这样会引入跨云IO,并增加Flink作业的OOM风险。

Fanout:下游Subtask的分区个数。 Residual:下游Subtask的分配流量和与目标流量差距。

小文件的问题得到了解决。 Writer算子内存占用减少。
引入了Shuffle。 流量动态变化。暂时还不能根据流量变化动态调整分区分布,因为当前是在Flink 作业启动的时候读取Iceberg的元数据。
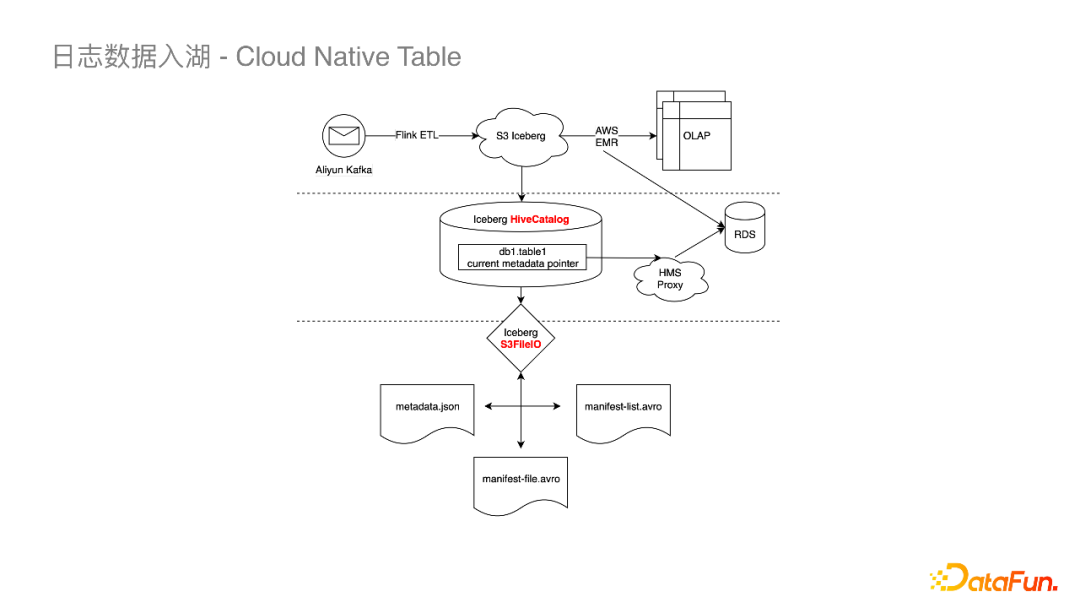
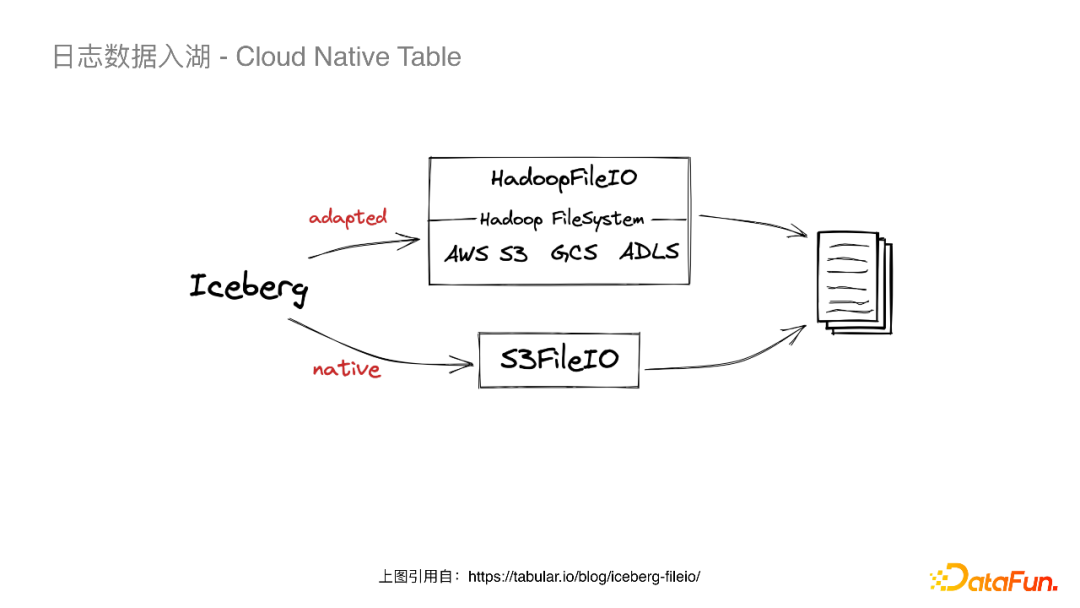
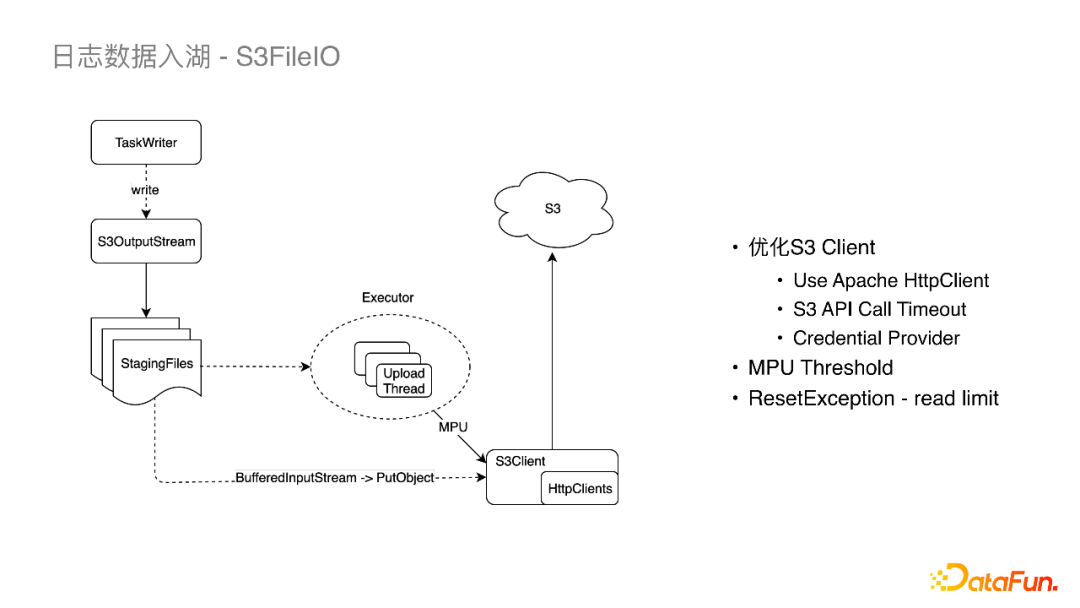
HttpsClients,我们将S3原生的HttpsClients(Java8自带的HTTP URL Connection)更换为了Apache HttpClient,其在Socket链接以及易用性上有一些提升。在写的过程中我们也遇到了一些问题,多云机器带来的问题是每个厂商机器的内核是不太一样的,例如在某云上发现有写S3超时的问题,我们与厂商一起抓包发现是内核参数的问题。 API Call Timeout,将S3的Timeout配置项暴露给Iceberg。 Credential Provider,S3 SDK从FlinkConf中读取密钥。
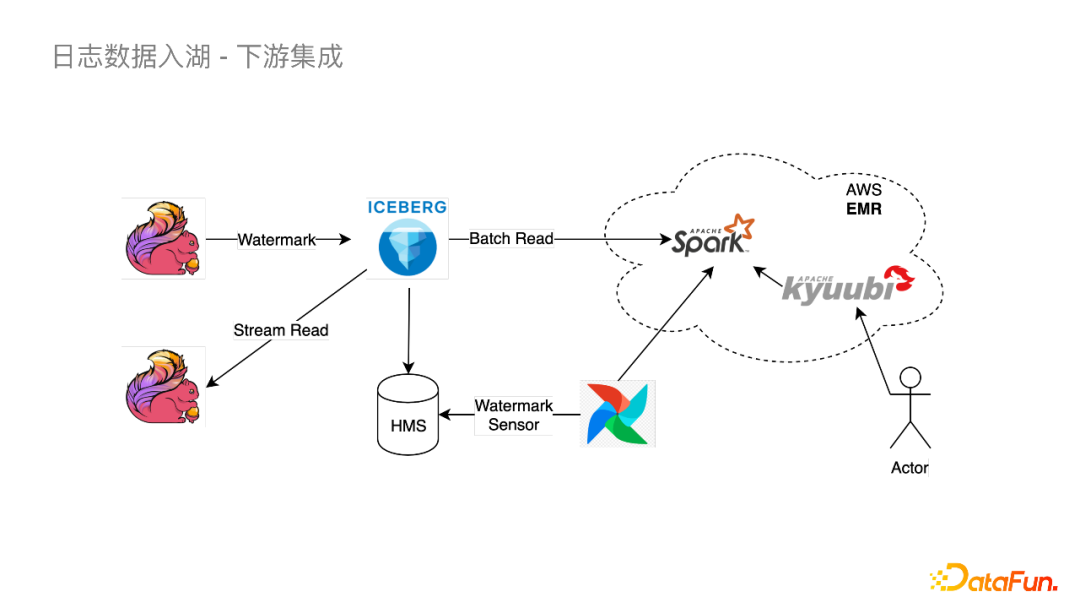
第一个问题是Batch Read
第二个问题是Adhoc查询
hive_prod.Iceberg_test.table
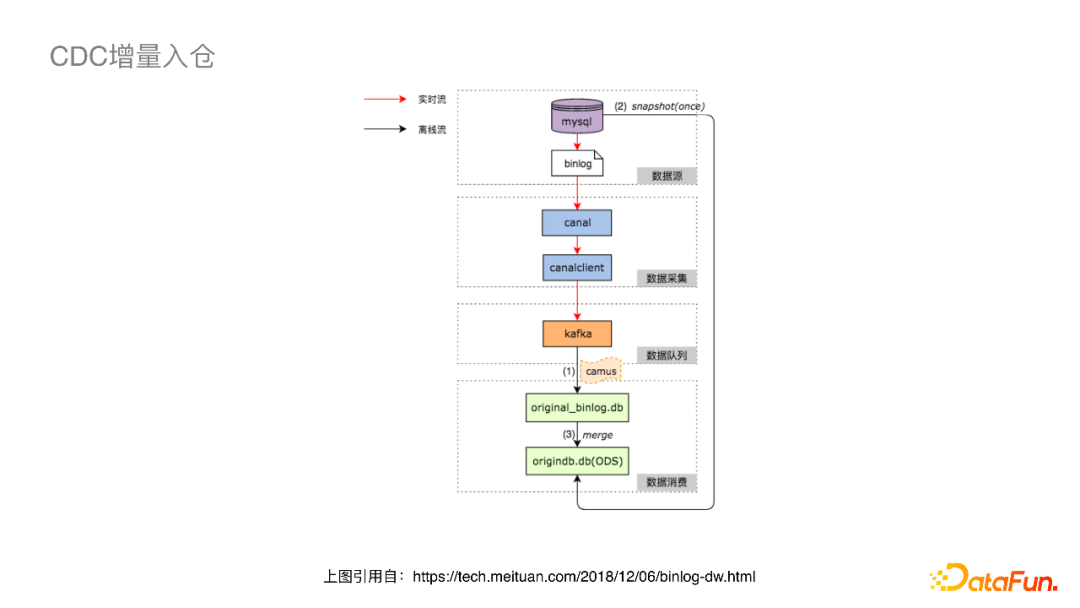
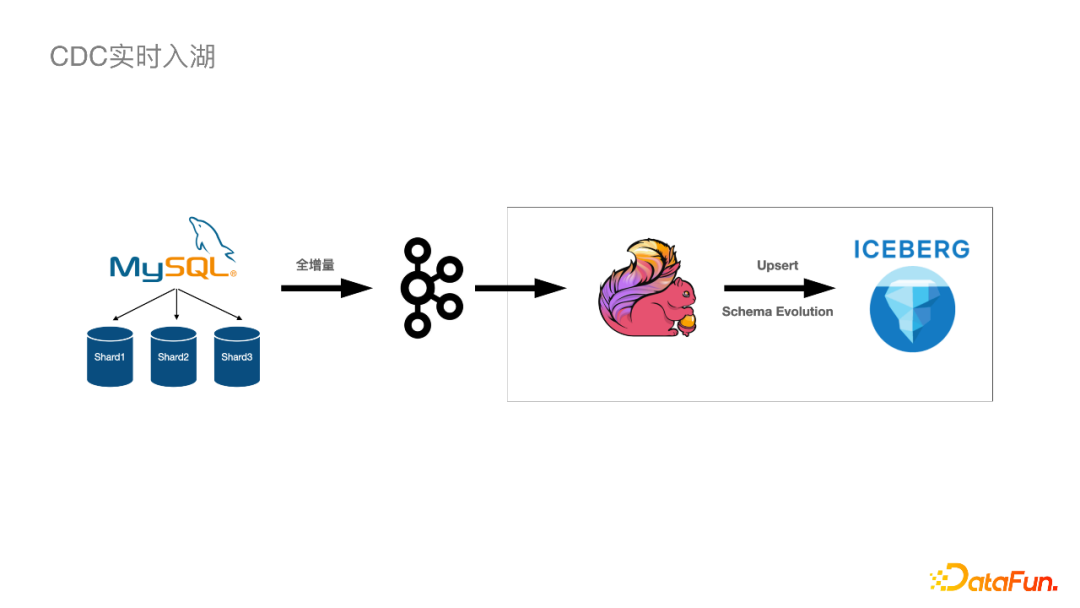
全增量,先发全量再发增量。 At-Least-Once,保证重复发送时保证有序(最终⼀致性)。 MQ Producer根据主键Hash(且分桶数固定,不受扩容影响)。
Shuffle Key 只能是主键的⼦集 + Immutable Columns。
Upsert Mode。
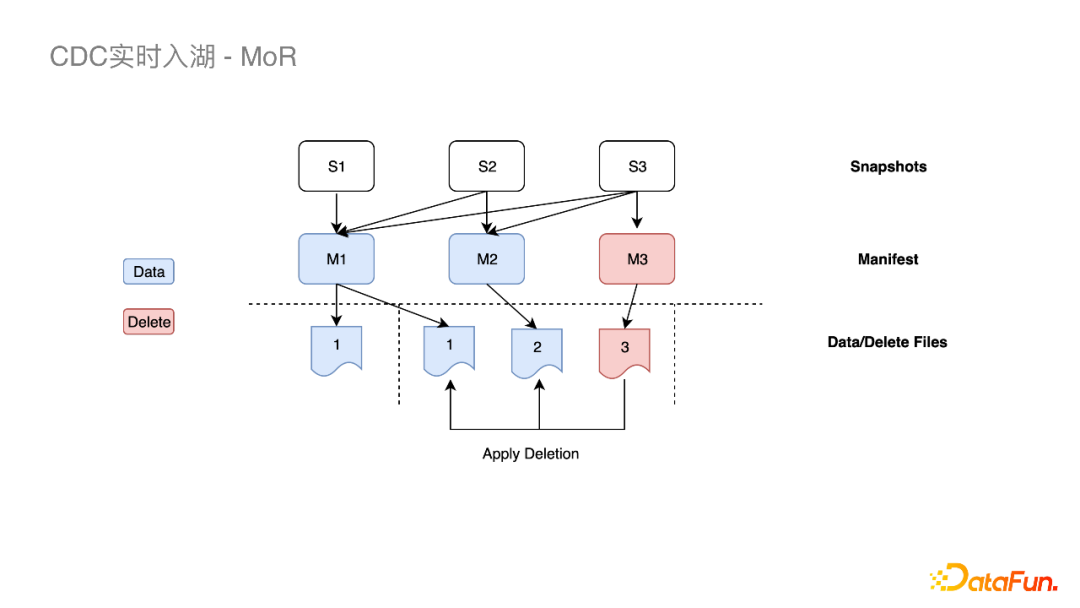
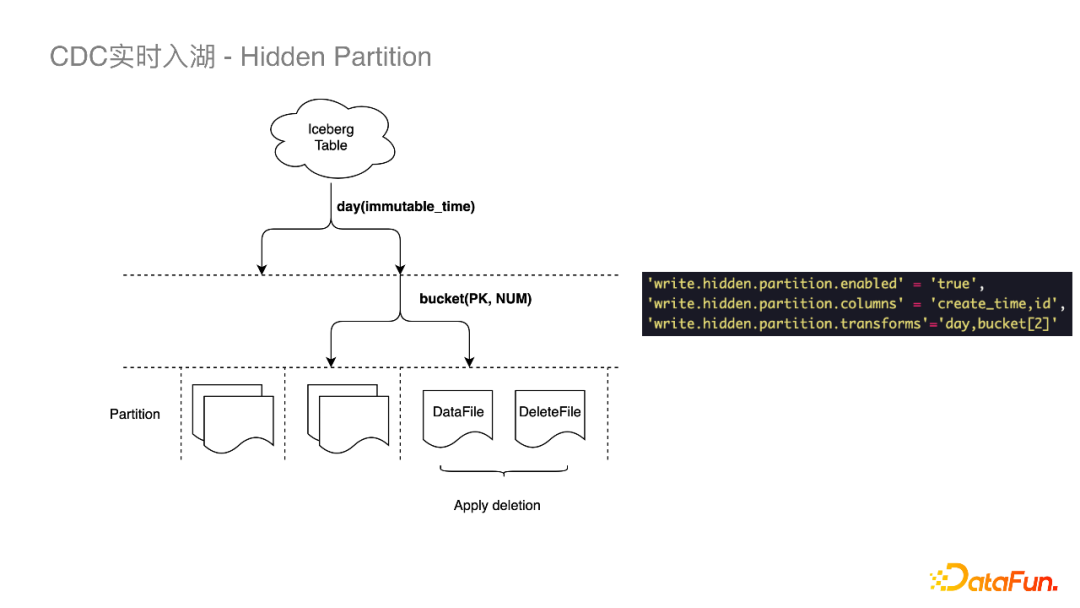
在读数据时可以只查询关联分区,忽略其他分区。 错峰做File Compaction,减少冲突。例如在写当前小时分区时我们可以对之前的分区做File Compaction。
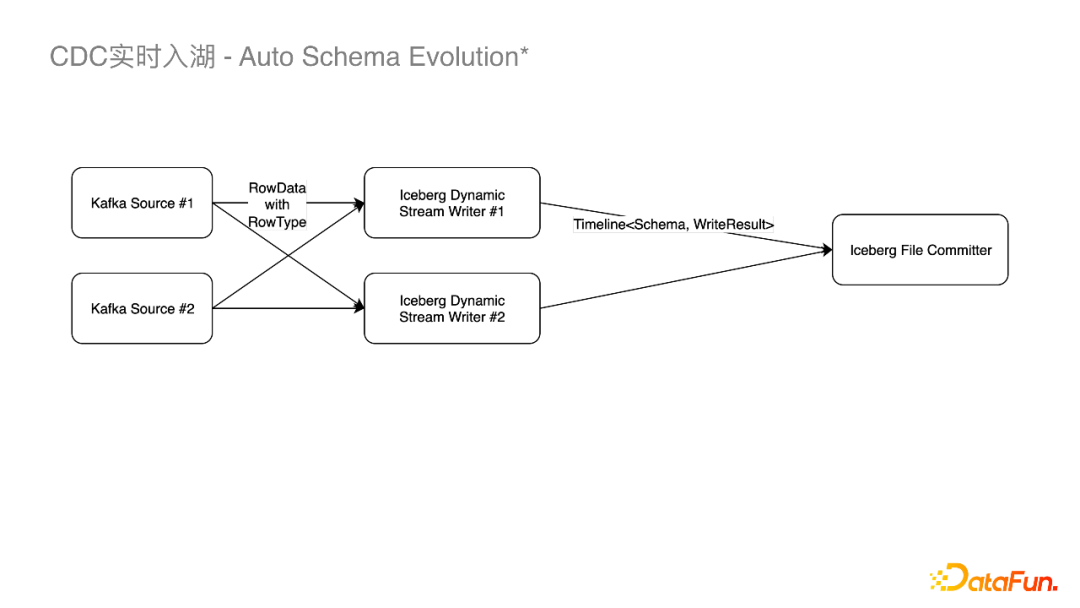
关掉当前的Writer,以新的Schema去建立新的Writer写数据。 以Schema变更的时间点为分割,对Schema变更前的数据先提交,再对Schema 进行Update,之后再提交 Schema变更后的文件。

Binlog Format。支持解析Canal PB格式。 Progressive Compaction。Compaction是我们接下来工作的重点,尤其在MySQL的量比较小的时候,如果想维持五分钟级别的CheckPoint,小文件问题就会非常突出。如何避开流式任务正在写的Partition去做Compaction 也是目前在做的事情。
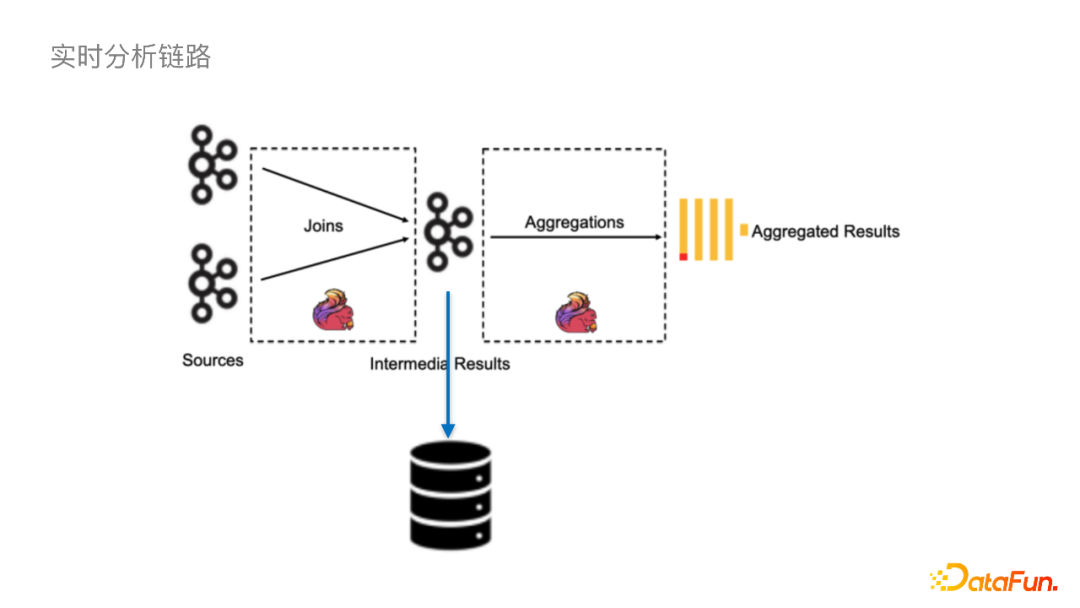
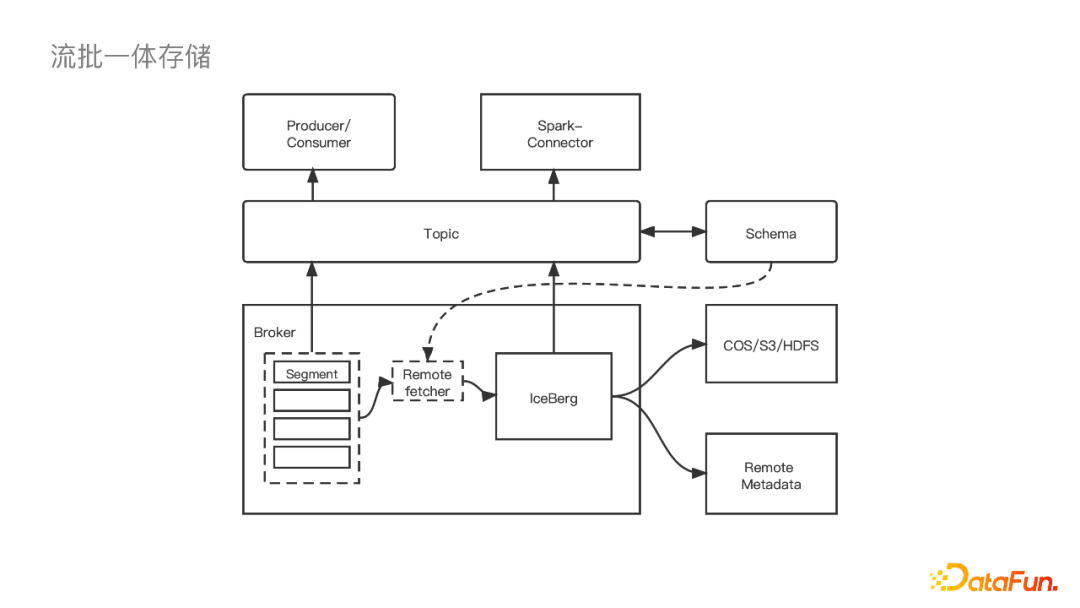
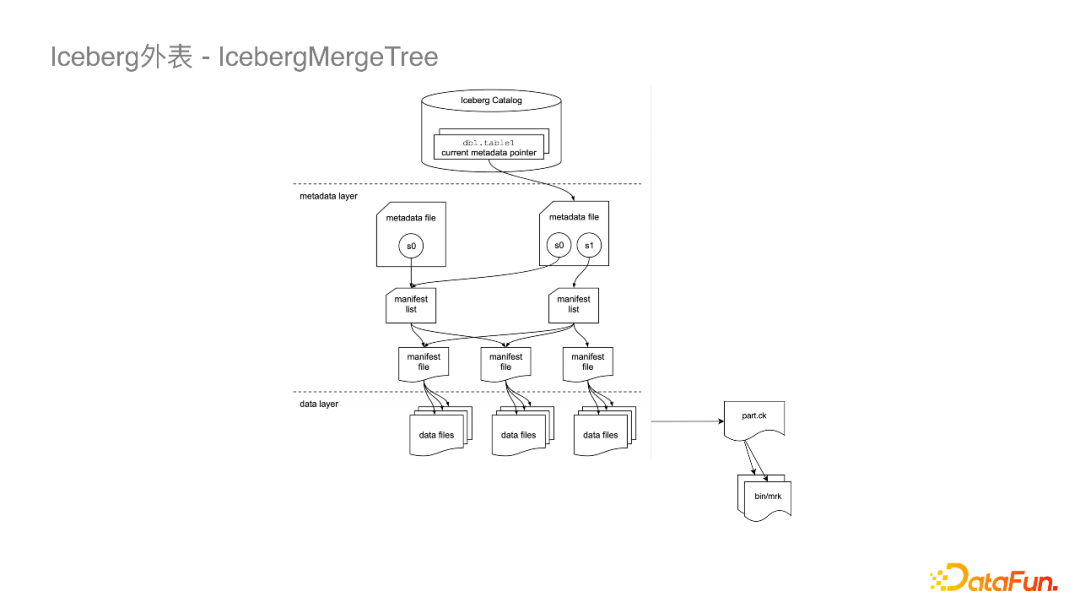
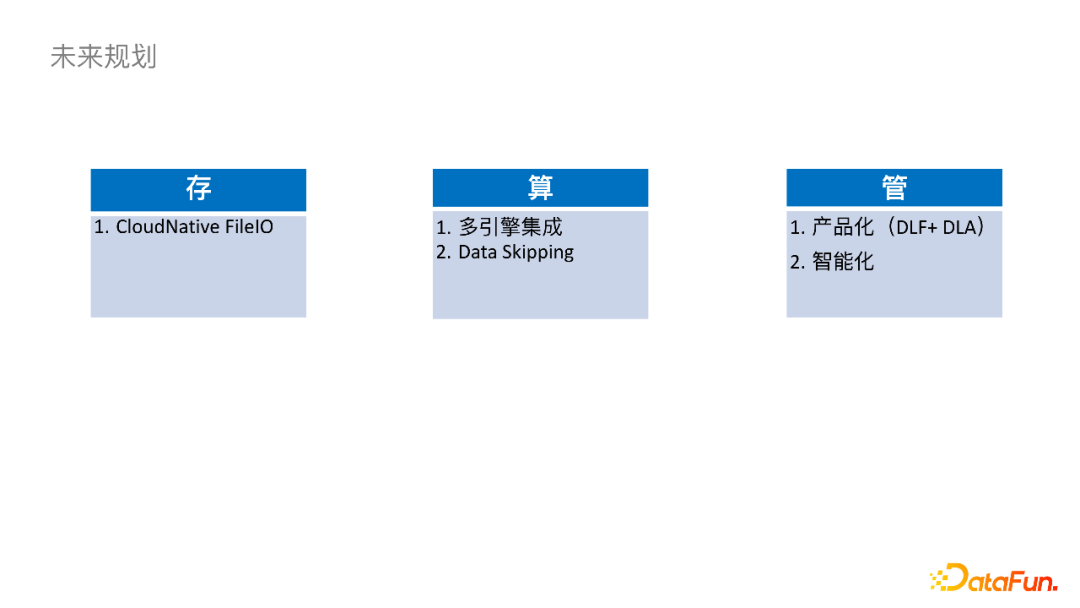
首先在存储方面,我们需要对CloudNative FileIO持续优化,比如进一步减少Checkpoint的毛刺、进一步提高吞吐、提高跨云读写的稳定性。 关于计算,我们会跟更多引擎去集成,目前已经集成了Spark引擎,同时正在集成ClickHouse。另外StarRocks社区已经集成了Iceberg外表的Connector,我们以后也会在上面做一些应用。在查询方面,计划通过改变数据的组织形式,或者添加一些二级索引来做Data Skipping去加速查询。 管理方面,让Iceberg持续稳定的运行下去还是需要外挂表维护作业的,这对下游数仓同学来说还是引入了运维压力。我们接下来会将其服务化,思考如何智能地拉起一些作业,以及运用什么策略可以减少冲突的概率。
编辑:王菁



