 浅黑科技
浅黑科技





浅友们好~我是史中,我的日常生活是开撩五湖四海的科技大牛,我会尝试各种姿势,把他们的无边脑洞和温情故事讲给你听。如果你想和我做朋友,不妨加微信(shizhongmax)。
王者荣耀的B面:
人类在此喧闹,AI却在他们脚下悟道
文 | 史中
孙悟空在旷野上狂奔,喉咙里喊出:I'm Real!!
他把金箍棒直插入地,炫目的振波四散冲开,眨眼间,又跳到敌人近身左右开弓,一顿输出行云流水,对方血槽见半。
然而,就在下一秒,猴子却突然判若两猴,握着铁棍,失神呆立,任由对手揪住一阵爆锤,刚才的威风无影无踪。
原因很简单:我在打《王者荣耀》——刚刚我还在操纵孙悟空,现在我把手指从屏幕上挪开了。
在0和1编织的赛博世界里,哪怕贵为齐天大圣,没有玩家的“灵魂注入”,它也只是一具皮囊。
孙悟空并不 Real。

看到这儿,很多浅友可能会哭笑不得:中哥你在说啥?孙悟空不就是个游戏角色么?游戏角色不用人操纵,难道还能自己上阵杀敌不成?
诶,那可真不一定哦。
最近我就遇到一群人,他们用了6年时间在王者峡谷里铺下了千万行代码,完成了三连杀:
第一、用人工智能指挥英雄战胜了无数人类好手。
第二、他们还把《王者荣耀》改造成了AI科研的试炼场;
第三、他们甚至把小小屏幕背后的游戏变成了“多智能体协作”这个人类前沿技术命题的悟道之地。
听我细细道来。

(一)为英雄披上“AI战甲”
2016年,成都,一群人围坐在会议室里,眼神如哲学家般深邃,如圣徒一样虔诚,仿佛面前有一团篝火。
坐在C位的这个,名叫黄蓝枭。
你也许不认识这位老哥,但很可能以特别的方式和他“神交已久”。因为他就是现任王者荣耀的执行制作人,也是天美L1工作室的总经理。
多少个夜晚,你在被窝里端着手机上分的时候,四舍五入就是在黄蓝枭和他的同事们营造的王者峡谷里辗转缠绵。
当时,这群人正是在讨论这个古老而诗意的命题——能不能用人工智能控制王者荣耀的英雄去战斗?
看到这儿,你脑袋上可能又有问号了:王者荣耀的开发团队不好好做游戏,为啥非要用人工智能打游戏呢?
要搞清楚这个事儿,我们不妨坐在黄蓝枭和王者荣耀技术负责人杨光身边,听听他们在说什么。
彼时的《王者荣耀》还不是现在这般耀眼的“全民游戏”,里面可选的英雄也只有几十位,远没有后来的一百多个。
虽然很多英雄正在秘密开发中,但有一个问题贼拉困扰他们,那就是——这个英雄放出去之后,可不敢“太能打”。
这是为啥呢?
因为如果它的技能太牛X,那么,玩家用原来自己熟悉的英雄肯定打不过它,只好被迫抢着选这个英雄(或Ban掉它),这还有啥意思?
就像跷跷板一头被300斤的大胖子压得死死的,角色失去了“平衡性”。

平衡才有趣(截图出自短片《Balance》)
那怎么才能让一个新英雄在出生的那一刻,就和其他旧英雄是“平衡”的呢?
其实,在游戏开发界有一个祖传秘籍——新英雄发布之前,要找很多专业游戏测试员,用它跟老英雄打上几千场。各种姿势都尽量测试一遍,最终胜率在50%上下,那就说明它不比别人厉害也不比别人弱鸡嘛。
“祖宗之法”虽好,却有三个问题:
第一、测试员毕竟是人不是神,难以面面俱到。英雄放出去后,上亿玩家的智慧一起轰炸,还是难免发现一些骚操作,打破平衡性。
第二、人工测试太贵,越是要测试得万无一失,越是需要更多测试员,就越贵;
第三、测试员一多,又难免走漏风声。新英雄提前泄密,是游戏的大忌。
听到这儿,黄蓝枭看向你:这位同学,你有啥好办法?
估计你会说:
那能不能搞一个水平很高的机器人,左手新英雄,右手旧英雄,自己跟自己大战十万回合?
反正电脑也不吃盒饭,有电就能跑,不仅省时,还能比人类测试得更完善,还不担心泄密,一举三得!
你看,这不就回到我们刚才说的“用人工智能打游戏”了么?

人工智能脑补了十万场对局
“这个打游戏的人工智能是怎么做出来的呢?”我好奇心爆棚。
黄蓝枭示意我慢慢来,在继续讲故事之前,他得先给我科普一个小知识。
从游戏开发的角度,“用电脑控制的角色”有个统称,叫“智能体”。
他说。
如果宽泛地说,智能体的历史可非常悠久。
就拿大家都熟悉的1985版《超级玛丽》来说,那个一上来就收走了无数小白人头的“香菇怪”就可以看做是最简单的“智能体”。

进一步说,《仙剑》《最终幻想》里那些叨逼叨的 NPC 也是智能体;
再看《星际争霸》《王者荣耀》里,那些小兵、野怪就更是智能体了。

这里要猛敲黑板!!!
人工智能是近几年才成熟的,那在这之前,驱动“智能体”的经典技术叫做“状态机”或“行为树”。
所谓行为树,可以理解为是一个身上长满了“开关”的机器人。
比如天气黑了,就相当于触发了一个开关,机器人就要做一个动作;对手发了一个招,就触发了另一个开关,机器人就会躲避,然后按照预先写好的脚本还击。这个和工业上的机器人原理类似。
总之,所有反应的背后都是一条条具体的规则。规则越完备、越细致,机器人就看起来更聪明。
黄蓝枭解释。
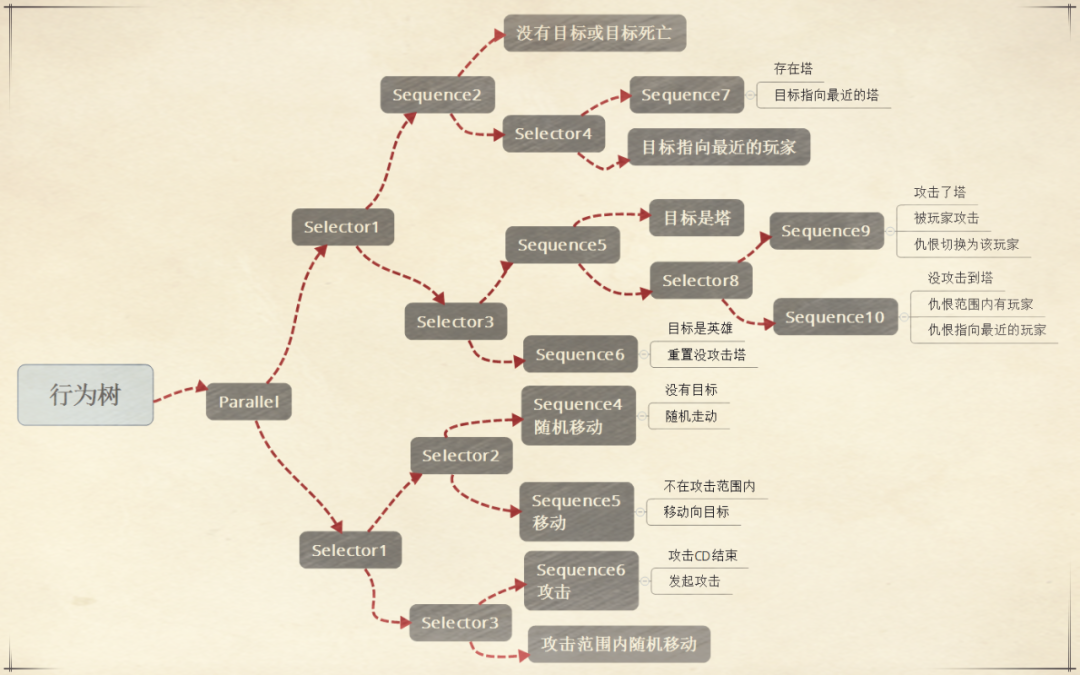
这是一个简单的行为树示意图。
用行为树驱动的智能体在《王者荣耀》里早就有了,用在小兵、野怪的控制、新手教程之类的很多地方。
那还要人工智能干啥?
这是因为,行为树存在天花板,里面的规则即使写得再精细,水平最多也就相当于“青铜”。
用“行为树”来测试新英雄的平衡性显然不靠谱——这就像战士们日常用棒子操练了十万次,上战场之后看到对手掏出了机关枪。。。

现在你就明白了,回到2016年,王者 AI 团队想要的东西准确来说是——“用人工智能驱动的高级智能体”。
做出这种“智能体”,所需的技术约等于人类科技的极限,纯靠天美工作室的能力恐怕不够。。。
大伙儿发愁,从哪儿找点厉害的帮手呢?
此时,我们不妨把王者团队的故事按下暂停,挪一下地图,从天府之国穿越到祖国南海。
2016年的深圳,腾讯总部,有另一帮人同样聚在会议室里,眼神如哲学家般深邃,如圣徒一样虔诚,仿佛面前有一团篝火。
这群人来自腾讯鼎鼎大名的人工智能实验室——腾讯 AI Lab。
给不熟悉的浅友多介绍一句,腾讯AI Lab,基本代表了他们人工智能技术的最高水准。
他们做出的病理 AI 云平台,可以辅助医生看细胞涂片,识别一些早期癌症的准确率相当于3~5年经验的医生;
他们做出的药物研发系统“云深”,可以大大加快新药研制的速度。
他们做出的围棋 AI 选手“绝艺”,可以优雅地让世界冠军柯洁两子还能击败他;
杨巍,就是腾讯 AI Lab 的创始成员之一。

杨巍
当时,他和同事们刚刚做出绝艺,虽然横扫一票人类围棋大师,但他感觉不到狂喜——因为半年前,DeepMind 刚刚用阿法狗虐完李世石,中国人做得再牛,也不是“首创”了。。。
那怎么才能做出比下围棋的AI更厉害的人工智能呢?
纠结中,杨巍划开手机屏幕,突然看到了《王者荣耀》的图标——“比围棋更复杂的游戏,我们腾讯有啊!”
王者荣耀团队和 AI Lab 一拍即合。
大家踌躇满志,既然要做出最能打的AI,那就得起个最能打的名字。斗战胜佛悟空不正是中国文化里最能打的人(猴)么?这个AI还是“绝艺”的同胞兄弟,按照“绝”字辈排下去,就叫“王者绝悟”!(为叙述简便,下文简称绝悟)

回忆起这个“梦开始的地方”,黄蓝枭还是激动不已。
用人工智能去测试英雄的平衡性、改善新手教学关卡,让玩家玩得更爽,这当然是现实目的,但仅仅这样理解它的意义,就太简单了。
我们看到了一个更大的机会:《王者荣耀》这个纯国产自研的IP如果可以突破“游戏”的局限,成为一个训练智能体协作的基础设施,那才能对社会和产业有更深远的帮助!
他说。
杨巍接受委派,成为了绝悟的AI技术带头人,心潮奔涌。
然而,热情的岩浆即刻冷却,变成了沉重的砖石。
举目四望,当时整个地球上还很少有人公开用AI打“复杂游戏”的计划,也没有研究者公布相关学术论文,更没有成熟的代码、算法可以参考——标准的“三无状态”。
该从哪儿下手呢?
(二)英雄的“内啡肽”
在普通人看来,围棋和《王者荣耀》是毫无关系的两种玩意儿——前门楼子和胯骨轴子。但在杨巍这种专业大牛的眼里,《王者荣耀》其实可以理解为升级版的围棋。
只不过,升级的跨度有点大就是了。。。

杨巍告诉我,它们的区别主要有三:
第一、围棋的玩法是一对一,王者荣耀的玩法是五对五(5v5),可以不严谨地理解为“10个人一起下的围棋”。
第二、围棋是回合制比赛,我下的时候你只能看。但王者荣耀是“即时竞技”,两边同时肝,谁犹豫一秒就会败北。
第三、围棋盘面就361个点,黑方和白方看到的局面都是完整的、一致的。可王者荣耀的游戏玩家只能看到自己视野内的局面,至于视野外的敌人具体在干嘛,那纯得靠“猜”了。
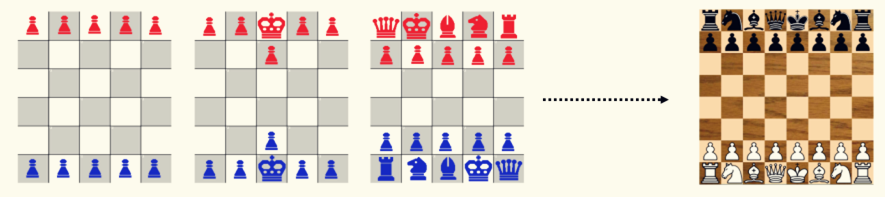
从数学的角度看,玩这种(有绝对强度的)对抗游戏,要想胜率达到绝对意义的100%,其实只有一种办法——穷举。
就拿围棋来说,对手下完一招棋之后,我如果可以把棋盘上所有能下子的点位都思考一遍,然后在每种可能性的基础上,再把接下来对手可能下的点位再思考一遍,以此类推,把亿万种不同的“剧本”全都尝试过,最终就能“遍历”所有的“状态空间”。
这相当于每一种走法将会导致的结局我全了如指掌,那想输也输不了。。。
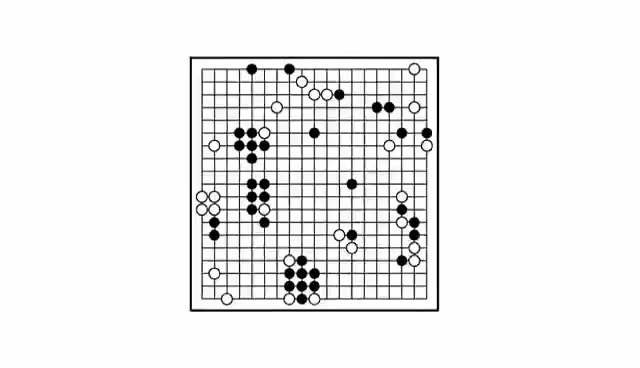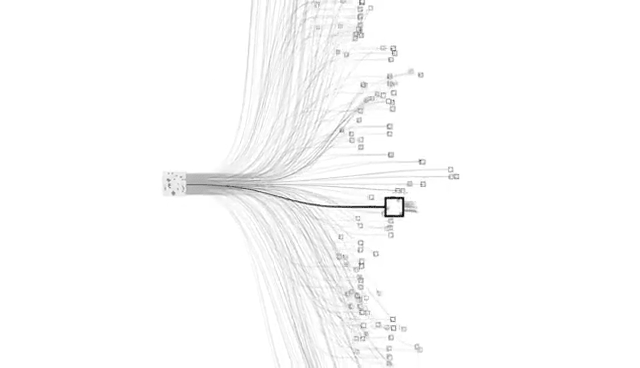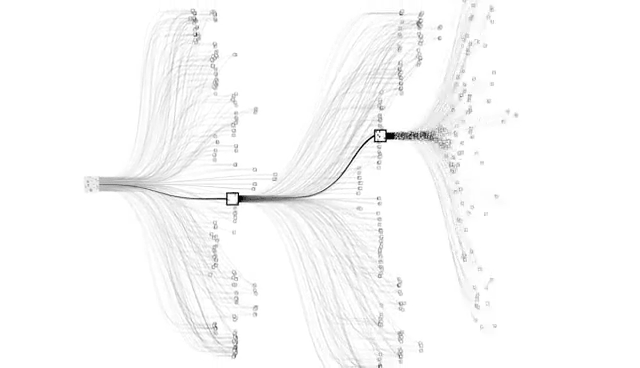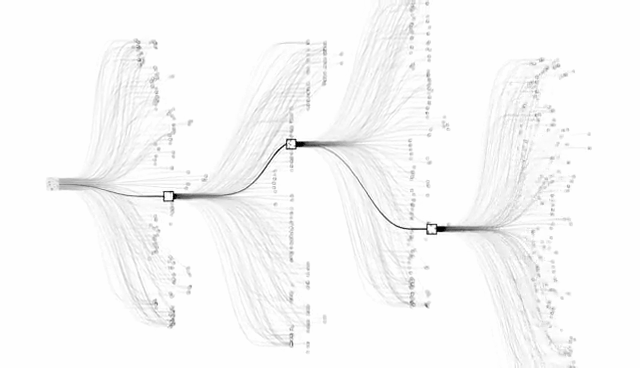
但坏消息是:穷举围棋的每一种姿势只在理论上可行,现实中,它已经超越了所有计算机的计算极限。
还有更坏的消息:王者荣耀的状态空间比围棋更大,更是超越人类计算机极限不知哪里去了。粗略估计一下,打一局王者,里面可能有10的20000次方种操作的可能性。不好意思,宇宙中原子的总数也只有10的80次方个。这事儿估计上帝也做不到。。。
不用穷举法,那用啥法呢?
用“依葫芦画瓢法”。
还是举个生活中的小栗子吧。
你是一个360斤的胖子,想减肥到120斤,这是你的终极目标。
为了达到这个目标,你得分成10086个步骤来做。而每一步里,你还面临10086种选择。
比如早晨第一步就有“不吃早餐”、“吃包子”、“吃面条”、“吃鸡蛋”、吃“肉夹馍”。。。(你完全没办法穷举)
可是,哪个操作能提高最终的“胜率”,你完全不知道啊!

这时候,最好的办法不是原地苦想,而是看哪位老哥曾经减肥成功,你模仿他的操作。
如果他早餐吃的是“鸡蛋沙拉”,那你也应该先尝试吃“鸡蛋沙拉”;他第二步是“晨跑30分钟”,那你也应该这样。(虽然从上帝视角来看,一定存在更适合你的办法,但你就!是!不!知!道!最好的选择只有模仿。。。)
绝悟最初学习打王者也是同样的道理,这个过程的学名叫“模仿学习”。

模仿谁呢?模仿职业电竞选手。
王者荣耀的高手大概都知道,有一个名叫 KPL(王者荣耀职业联赛)的比赛,是这款游戏的最高殿堂,每年职业选手都会在这里来一次华山论剑,而这些比赛录像都是公开的。
于是,腾讯 AI Lab 赶紧把这些录像都找来,让人工智能学习。

KPL 比赛现场
人工智能当然不会排排坐背着手听老师讲课——所谓学习是通过一种叫做“奖励”的东西实现的。
这一点和人类的进步过程也超级相似。人在不断实现目标的过程,大脑会分泌“奖励递质”内啡肽。
还拿减肥举例:今天你跑步半小时,内啡肽就会分泌;晚餐八分饱,又会分泌;睡个好觉头脑清醒,又会分泌;直至最后减肥成功,大分泌。
人类的“内啡肽分泌体系”是千万年进化的结果,可绝悟没这些,脑袋里是一张白纸——所有的“奖励机制”都需要人类从头设计。
所以,人工智能的训练,本质上就是奖励设计的过程!
杨巍一语道破天机。

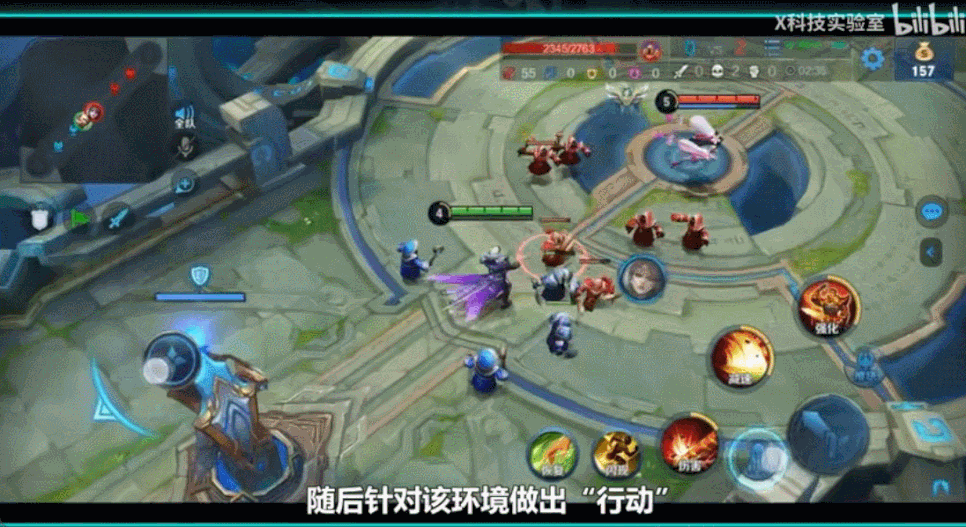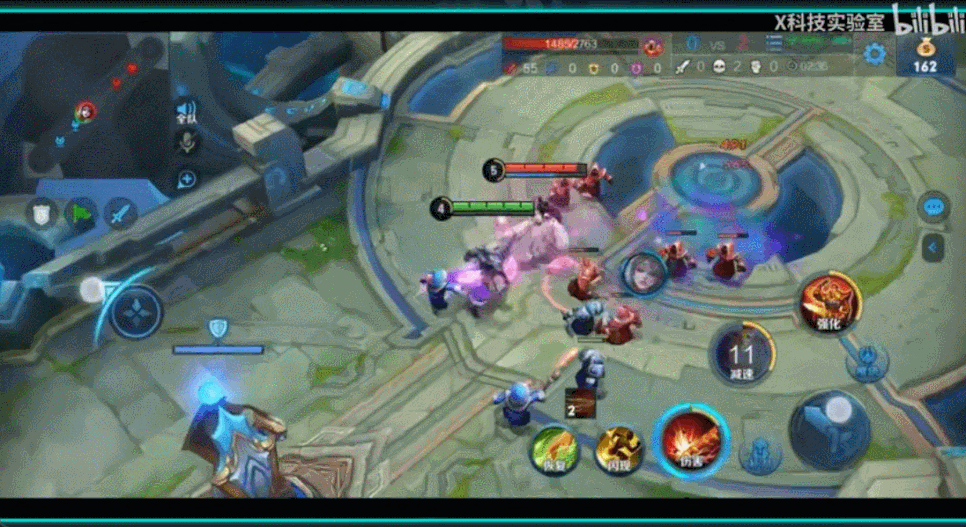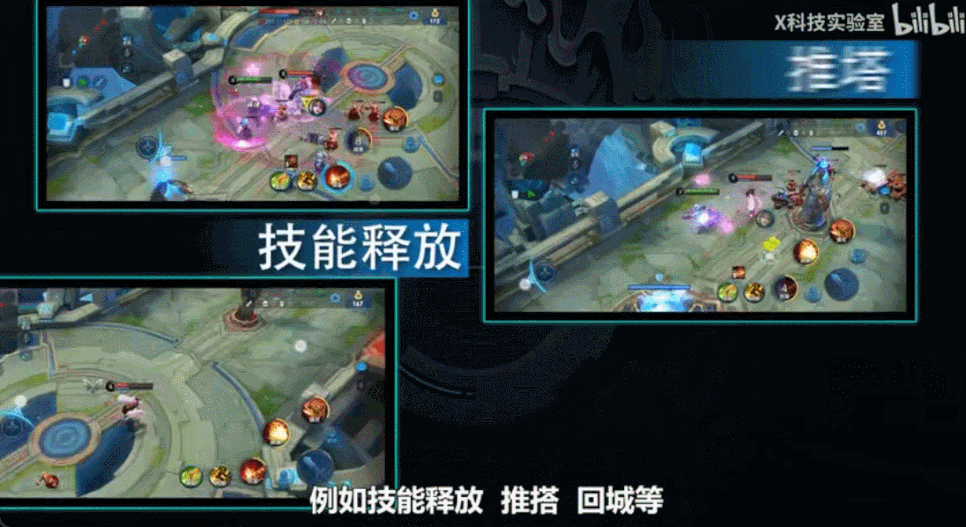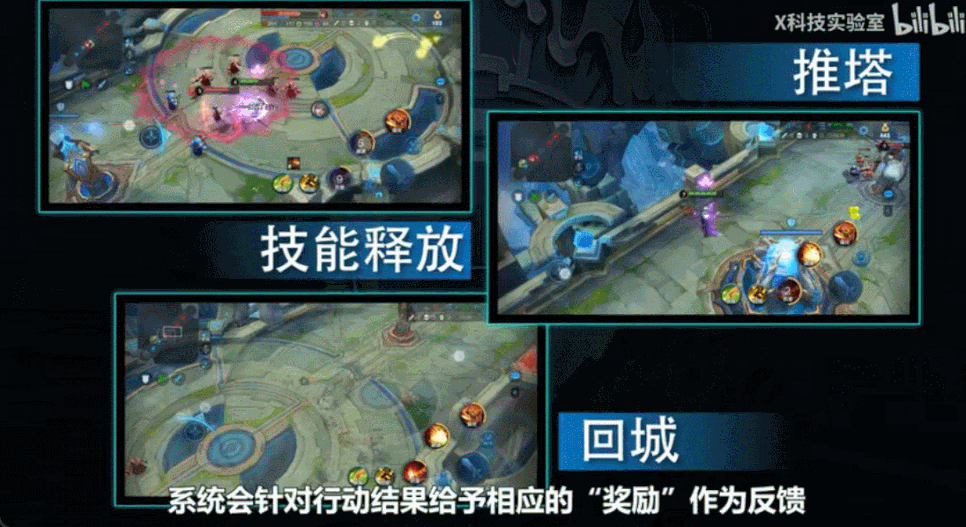
这段科普截取自X科技实验室的视频节目,他们很好地解释了绝悟的训练过程,非常推荐,链接附后。
比如,敌人被击中掉血,我方英雄该怎么赏?对方英雄出招被我躲过,赏多少?对方英雄被击杀,怎么赏?推掉一个塔,怎么赏?打团帮同伴挡住敌人大招,怎么赏?
当然除了正奖赏,还有负奖赏——罚。
比如,我方英雄被击中残血,应该罚多少?如果罚得太多,英雄就会不敢出战,各种逃窜,甚至掉一丝血就想回城补血;如果罚得太少,英雄又会傻冲,容易被团灭。
你看,这种奖励的设计过程非常精细——往往奖励值变化一点点,就会导致训练出来的英雄性格迥异。所以,需要技术宅们蹲在电脑前反复调整实验,才会试出理想的结果。
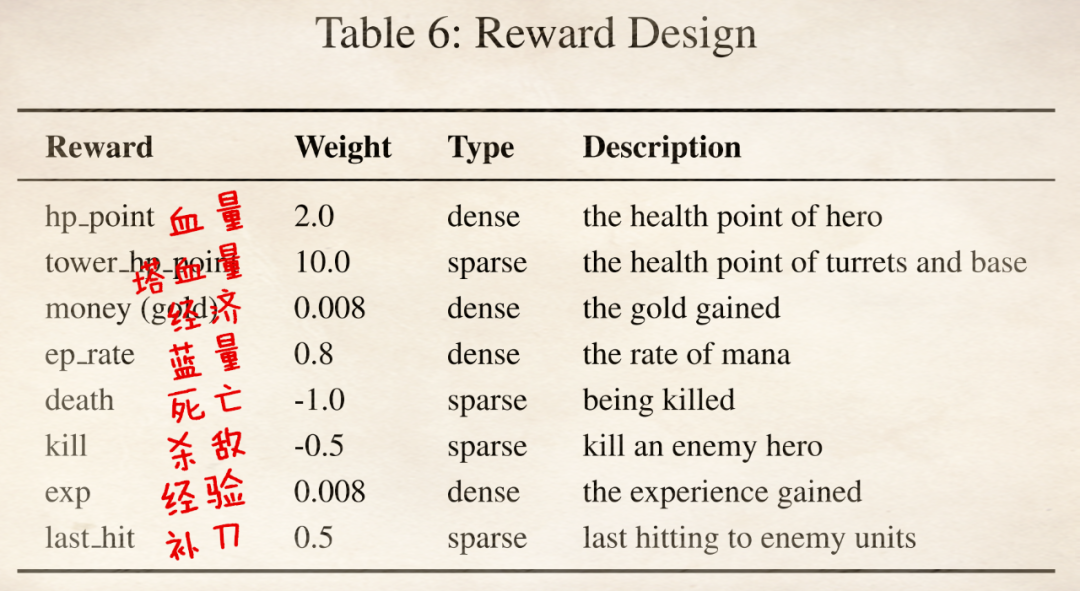
注意看,这里杀敌的奖励反而是负的,因为这个过程会导致其他奖励都在增加,如果此处再给奖励会让AI过于执着于击杀敌人。(由此可见奖励调整过程中有很多反直觉的操作。)
怎么样,听上去这个“绝悟训练计划”天衣无缝吧。
呵呵。
(三)少年绝悟
我们把时间轴拉到2017年。
彼时,已经“埋头苦练”半年的绝悟一招一式都有了模样,感觉棒棒哒,迫不及待想找个对手试一下。
“来,你们出个强人跟绝悟打一场!”杨巍对王者团队下战书。
王者的同学说,我们不是有负责新手教学的“行为树”么,绝悟先跟行为树打一仗,赢了再说呗。
“哼,竟然小瞧人。”杨巍他们哼着小曲把绝悟和行为树的接口连通,两边干了一架。
结果。。。。绝悟被打得满地找牙。
之前说过,行为树的水平大概是“倔强青铜”,这么一比的话,彼时的绝悟水平大概就是。。。躺平废柴。。。
啊,我们一群人开发了半年的人工智能,比不上一个王者开发同学花半个月写的行为树,那感觉简直无地自容。当时就觉得这玩意儿简直太难了。
杨巍回忆。
受了打击,他跟业内专家交流,倒倒苦水。
本想求点“练兵高招”,可大家的意见却如五雷轰顶:这玩意儿做出来的可能性确实不大,早点放弃,也不是不行。。。
可是,眼看团队同学们每天还在冥思苦想解决办法,自己放弃,这可怎么见江东父老呢?他只好顶住压力,装作无事发生,继续鼓励大伙儿。
果然,功夫不负苦心人,有两个方向渐渐在他们的视野里清晰起来:
第一,即便是 KPL 高手,也不意味着每一个操作都是正确的嘛!他们也有失误,也会有平庸的操作,不能啥都跟他们学。
第二,人类打游戏时是左手控制方向,右手控制出招,分别是两个脑区负责的。那是不是绝悟也应该把“走位”和“出招”分开来训练呢?
先说第一个方向。
怎么让 AI 学到人类精华呢?
黄蓝枭派出几位精锐的游戏策划师,他们不仅是游戏的主创成员,更是打游戏的高手。这些高手的任务很奇特:不用干别的,就盯着屏幕把比赛录像看N遍。
因为他们对游戏的理解特别深刻,所以,有些我们看上去炫酷的操作,在他们眼里反而是平平无奇的花架子;有些容易被忽略的微操,在他们心中恰恰是功底深厚的神来之笔(老玩家应该明白这种感觉)。
就这样,他们调动毕生经验,把真正的优秀操作一个不落地标记出来。
这个操作,就是人类高手的经验被“提纯”成《九阴真经》的过程。接下来,只要推着绝悟的后背传入它体内就好。

这是英雄学会了“利用草丛”,阴在草丛后面等对手进入攻击距离,猛然跳出一波带走。

这是两个英雄学会了“配合”,英雄A用护甲保护残血队友B,并且打出空间,队友B默契地用技能击杀对手。
再说第二个方向。
他们把涉及位置移动的操作全部交给一个系统训练,又把涉及出招的操作交给另一个系统训练。这样一分开,果然,绝悟的脑子不再是一团浆糊,操作清爽多了。
需要强调的是,这个思路还进一步启发了他们,除了左右手操作分开训练,是不是还能把其他一些重要的决策也独立训练呢?
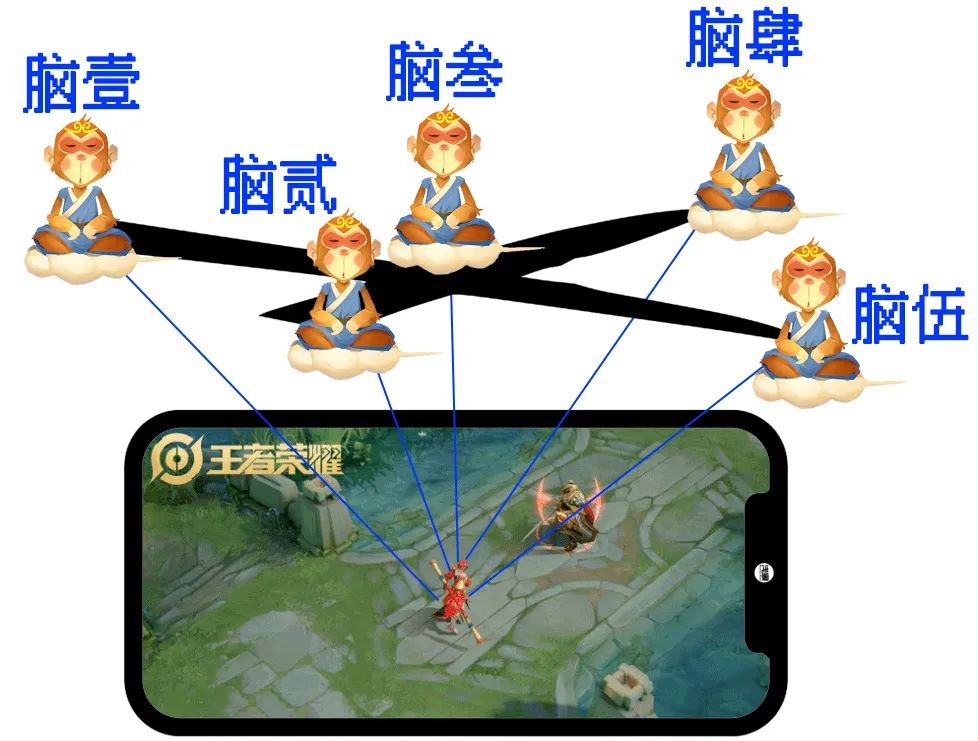
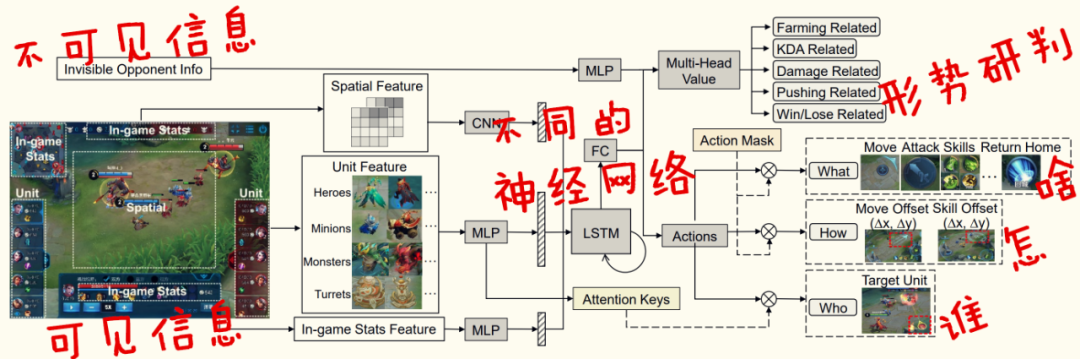
于是,他们又搞出了好几个独立的“脑区”:
比如有一个脑区专门负责“猜测敌人位置”:每时每刻根据现场的情况修改判断,比如在这个草丛没有见到对手,那对手在另外草丛的概率就会增高;
比如还有一个脑区专门负责“大局研判”,基于现在的战势,我应该往哪里走才对整体最有利?有了大局研判, 英雄的格局就打开了, 不会在屏幕这一小块区域里恋战,而是能运动起来,及时出现在险要位置。
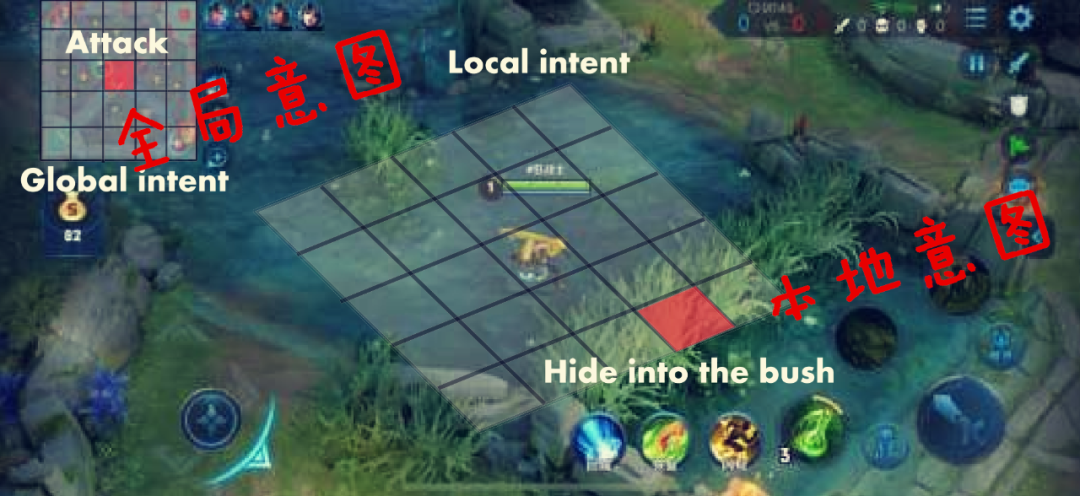
1、他们都能根据自己了解的情况产生“奖励值”; 2、诸多脑区的“奖励值”综合在一起,共同对英雄的行为施加影响; 3、这种操作,就像用几根细细的丝线来共同控制木偶那样。
“猥琐发育,别浪。”后来就成了我们王者绝悟的研发方针。和打游戏一个道理嘛。

虽然表面不能让别人看出来,但其实心里确实没底。 因为 AI 训练的原理就决定了它不可能覆盖所有可能性。对手一旦使出怪招,天知道会触发什么Bug。万一绝悟有啥弱点被对方拿捏了,第二天我们必败无疑啊。。。
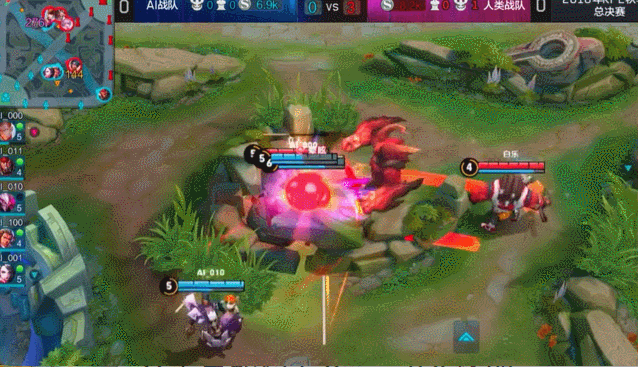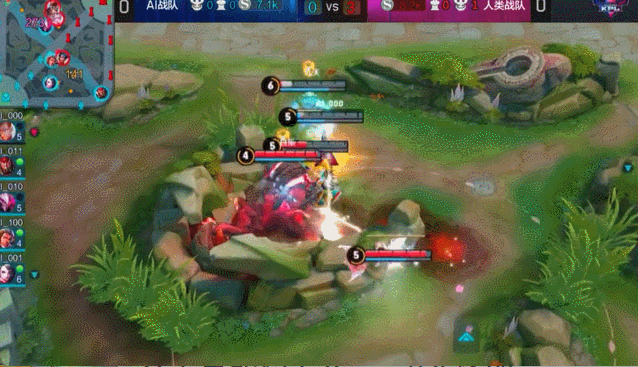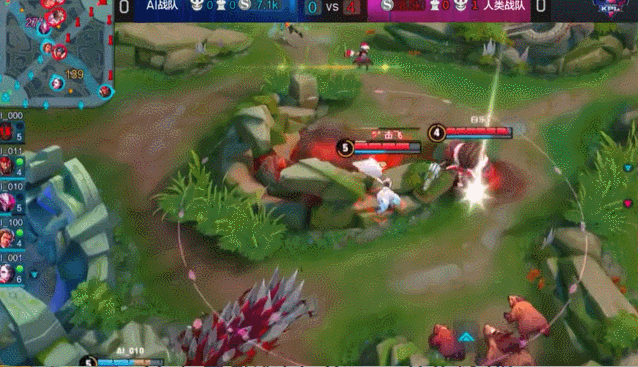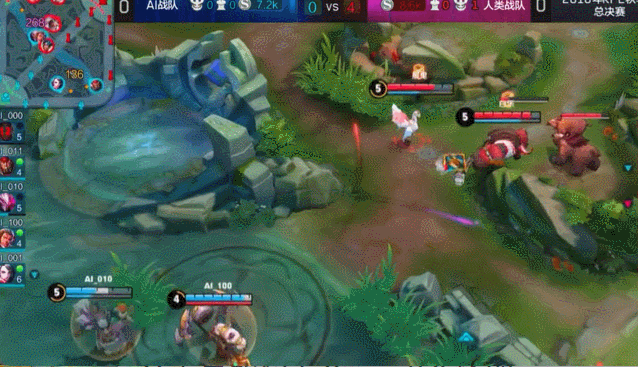
当时我已经开始想,如果输掉比赛,回去要怎么和领导交代,怎么总结教训了。。。
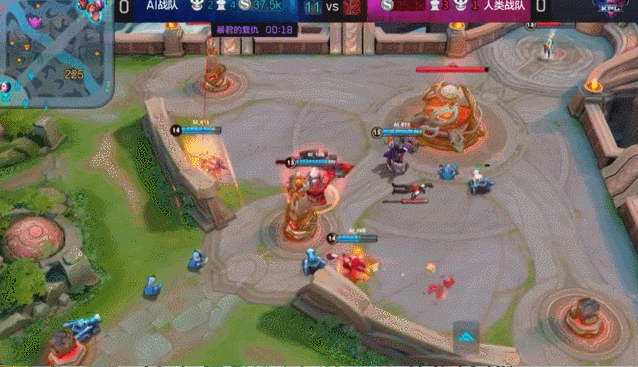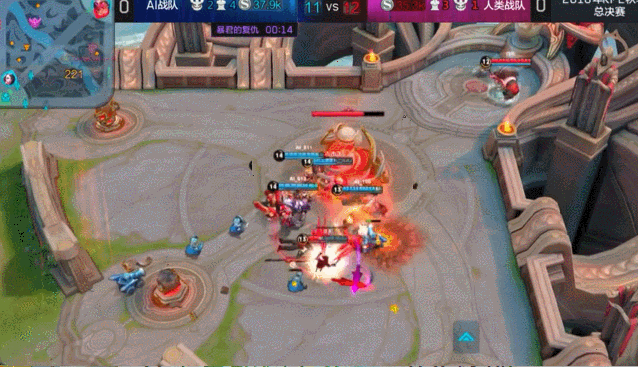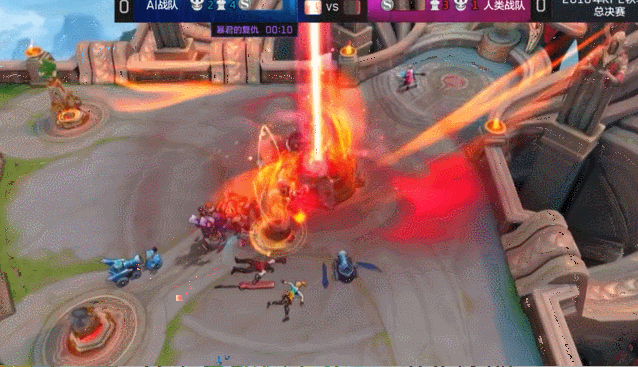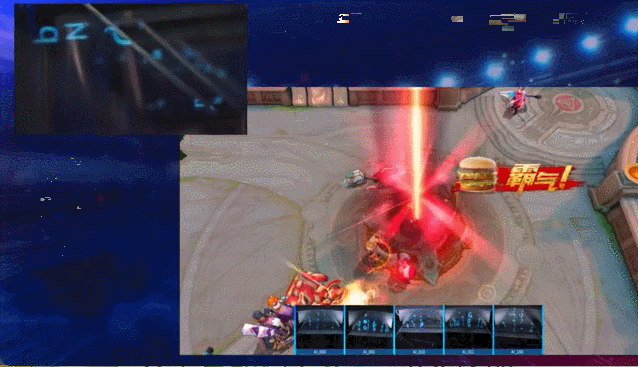

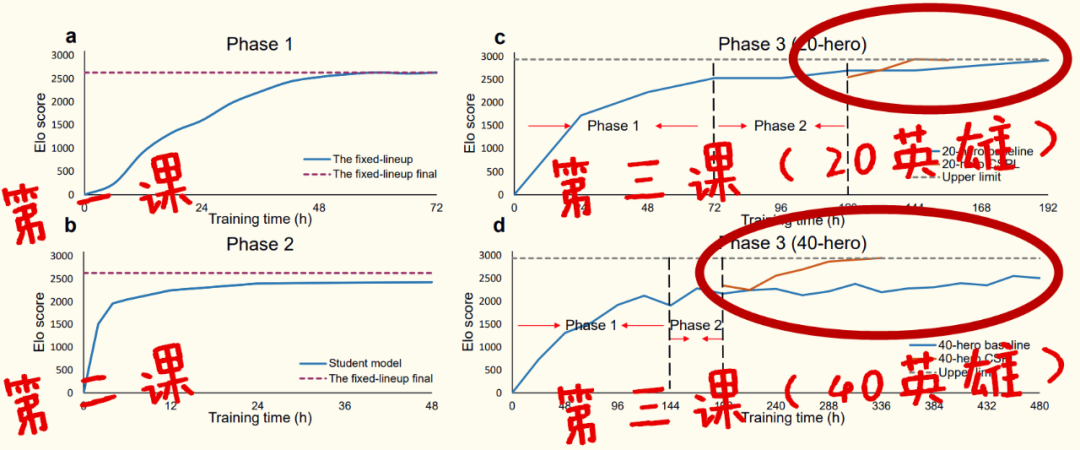
向左走,是把之前已经学成的“绝悟1.0”拿来继续深造成“2.0”; 向右走,是从零开始训练“绝悟2.0”。


最初数据看起来都很完美,但时间一点点过去,模型还是不收敛,而且曲线开始摇摆,甚至突然一下就跌到负值。。。
第一步,先在1v1的场景下把英雄分别练好。 第二步,把100个英雄分成20组,每5个英雄固定组队,让每组英雄自己和自己先进行5v5训练。 第三步,固定组队英雄训练完毕,再把英雄打乱编队,开始乱斗训练。


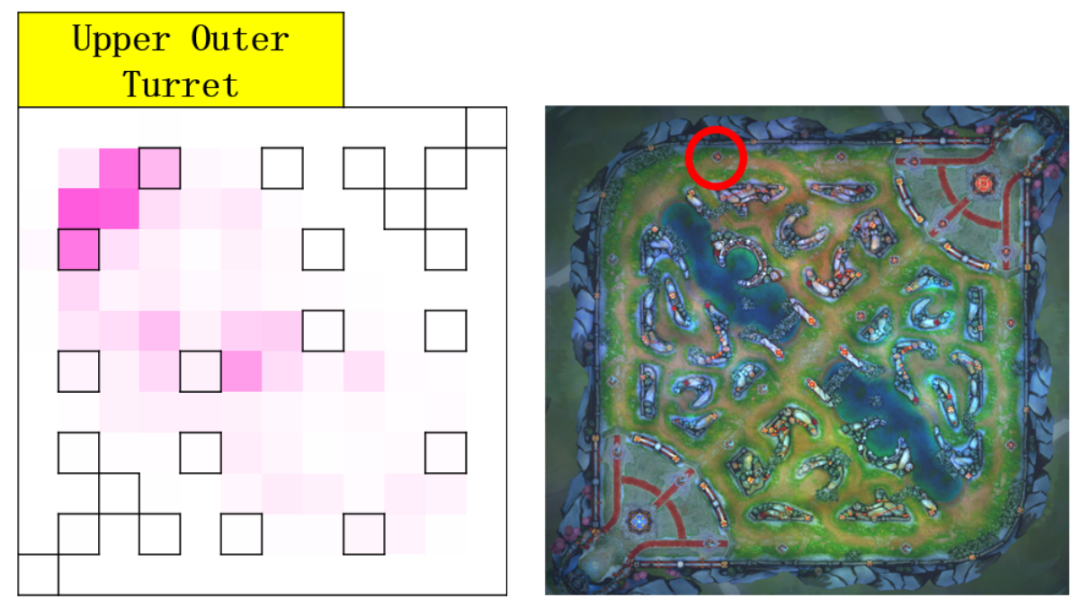
有时候看大家的帖子我觉得很有趣。因为AI的训练过程是一个复杂的“黑盒子”,很多绝悟的操作连我们团队自己都很难解释,别人猜的就更不准了。 但大家的热情很鼓舞我们。“AI的可解释性”确实是一个值得研究的前沿领域,所以后来我们也开发了解析模块,专门负责理解绝悟每一个操作背后的“理由”。


把王者荣耀的英雄们换成汽车,把地图换成街道,就变成了一个智能驾驶问题; 把英雄们的大招换成机械臂的动作,就变成了协作生产问题; 把游戏里的分路换成大厦里的电梯井,就变成了电梯调度问题; 把防御塔看成燃烧的火焰,那么,一群英雄围殴它就变成了火场救灾问题。

第一,同学们当然可以在其中训练出“属于自己的绝悟”,但其实这并不重要。 第二,通过训绝悟的实操过程,可以让更多人学会AI,爱上AI,成为AI人才,这才重要。 第三,这些人才可以带着他们的经验和代码走向各个产业,继续解决不同场景下具体的“智能体协作”问题,这更重要。

首先,你得把菜洗干净、把调料放好,这就是预制的算法和模型。 其次,你得把炒菜的原理和顺序给人家讲清楚,还要把用不到的调料藏在柜子里以防人家拿错,这就是AI训练框架。 最后,你还得给人家把煤气灶准备好,这就是数据和算力。


对于人工智能的热爱其实根植于很多人的心底,只是因为过去缺乏一个既有趣又好用门槛又低的学习平台,很多本来应该进入人工智能领域的人就这样错过了,这太可惜了。

你有没有发现,游戏和游戏其实是不同的? 围棋、《王者荣耀》所代表的游戏类型是竞技性的,这种游戏背后的逻辑是只要我的“绝对战力”比对手强,就能击败对手。 但还有一种游戏是博弈性的,比如猜拳、麻将。没有一种策略可以稳赢,我能不能赢取决于对手做了什么。
比如在王者中,有养猪流,就是4个人围绕一个人;有野核流,以打野为核心,还有鬼谷子体系、大乔体系等等。 其实完全可以通过调整奖励值来训练不同的“AI 风格”,这些训练经验未来就可以发展成人工智能的性格和情感。

比如你在打王者荣耀的时候,有时会和队友说:我要发起进攻了!这时候队友就知道了你的意图,当然他可以选择和你一起来,也可以选择不跟你来。 同理,你也应该可以和 AI 配合,你说你要发起进攻,AI也可以根据它对形势的判断,选择跟不跟你上。

我们做的虽然是技术,但技术的背后更是文化。 你有没有注意到,很多70后、80后甚至90后,他们一想起曹操,那个形象其实是日本人心中的曹操形象。原因很简单,我们儿时玩的三国游戏很多都来自日本,所以美学定义也同时被日本掌握了。

有朝一日,如果《王者荣耀》和开悟平台成为了国际上最流行的多智能体训练研究平台,那么,附加于人类最先进技术之上的文化角色,就顺理成章的是花木兰,是孙悟空,而不是米老鼠、唐老鸭。 由此,中国文化的包容和闪耀,也一同走向了不分种族肤色,所有人的内心深处,成为科技史中不可磨灭的地层。

技术的追求当然没有止境,而把文化融入科技记忆,这条路更是没有终点的。



再自我介绍一下吧。我叫史中,是一个倾心故事的科技记者。我的日常是和各路大神聊天。如果想和我做朋友,可以搜索微信:shizhongmax。
哦对了,如果喜欢文章,请别吝惜你的“在看”或“分享”。让有趣的灵魂有机会相遇,会是一件很美好的事情。
Thx with  in Beijing
in Beijing

