 极市平台
极市平台





极市导读
本文围绕Detection Transformer数据效率低下的问题,通过逐步的模型转化找到了影响数据效率的关键因素。作者成功用尽可能小的模型改动来大幅提升现有目标检测器的数据效率,并提出一种标签增强策略进一步提升其性能读。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

研究动机
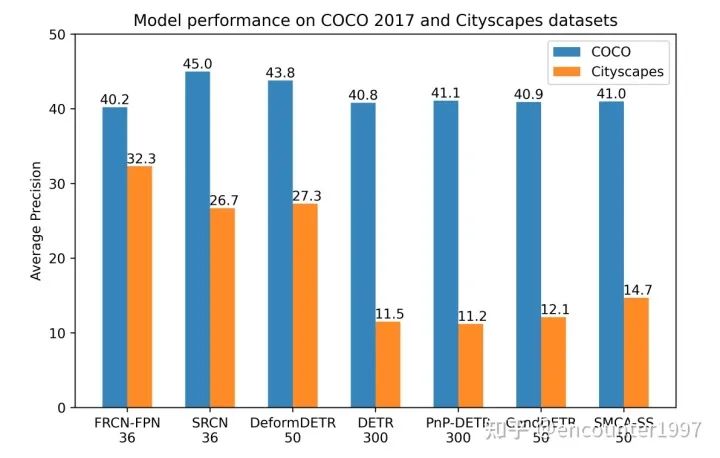
消融探究
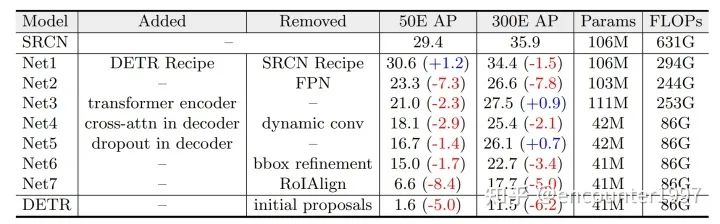
我们的方法
模型增强
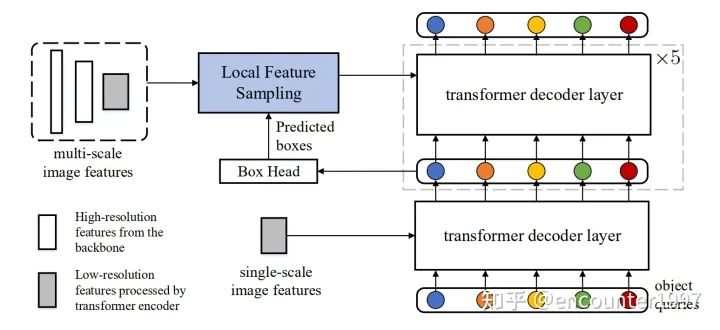
图2:我们的数据高效Detection Transformer模型结构。我们力求在尽可能少改动原模型的情况下,提升其数据效率。模型的backbone、transformer编码器和第一个解码器层均未变化
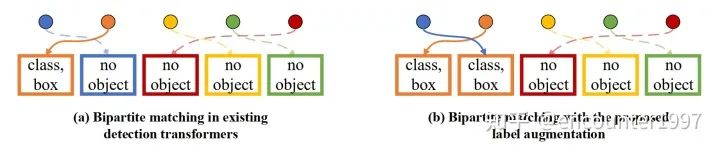
标签增强
实验

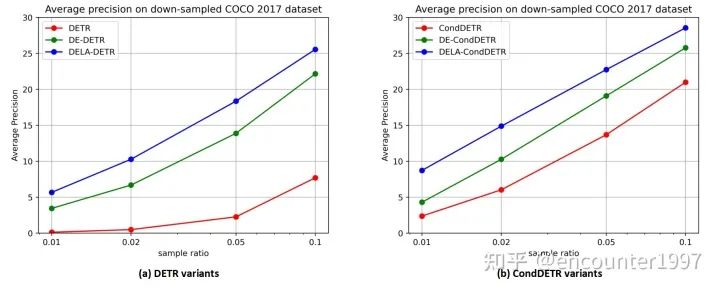
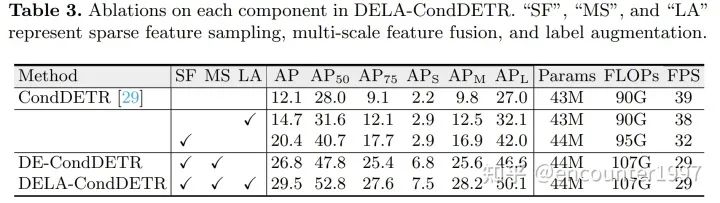
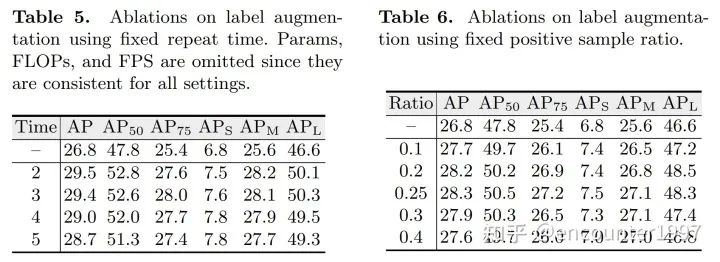
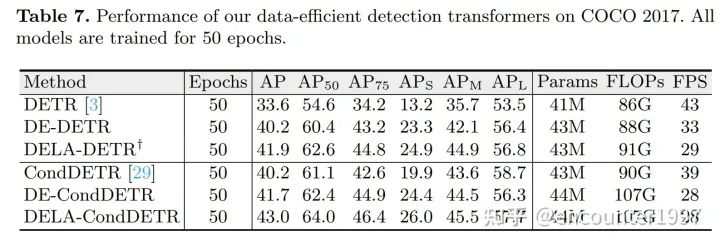

总结
End-to-end Object Detection with Transformers
Microsoft COCO: Common Objects in Context
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Conditional DETR for Fast Training Convergence
PnP-DETR: Towards Efficient Visual Analysis with Transformers
Fast Convergence of DETR with Spatially Modulated Co-Attention
The Cityscapes Dataset for Semantic Urban Scene Understanding
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
Visformer: The Vision-Friendly Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Deeply-Supervised Nets
公众号后台回复“ECCV2022”获取论文分类资源下载~
“
点击阅读原文进入CV社区
收获更多技术干货

