
鱼佬:华为推荐算法赛提分经验!
针对广告推荐CTR点击率预估实践的入门实践已经发布。在该版本基础上,写了一版进阶的学习教程,包含详细的特征工程处理代码,希望能有助于大家提分。
实践背景
赛题任务
本赛题希望选手基于广告日志数据,用户基本信息和跨域数据优化广告ctr预估准确率。赛题详细信息可参考赛事官方网站。
报名及数据下载
报名地址:
https://developer.huawei.com/consumer/cn/activity/digixActivity/digixdetail/101655281685926449?ha_source=dw1&ha_sourceId=89000243
数据下载步骤:
https://xj15uxcopw.feishu.cn/docx/doxcnUGTrDBMefWFv4U8VfFVpDd
实践思路
实践基础思路
本次实践是一个经典点击率预估(CTR)的数据挖掘赛,任务是根据用户的测试数据来预测这个用户是否点击广告。
这种类型的任务是典型的二分类问题(点击/不点击),模型的预测输出为 0 或 1 (点击:1,未点击:0)
机器学习中,关于分类任务我们一般会想到逻辑回归、决策树等算法,在这个 Baseline 中,我们尝试使用CatBoost来构建我们的模型。我们在解决机器学习问题时,一般会遵循以下流程: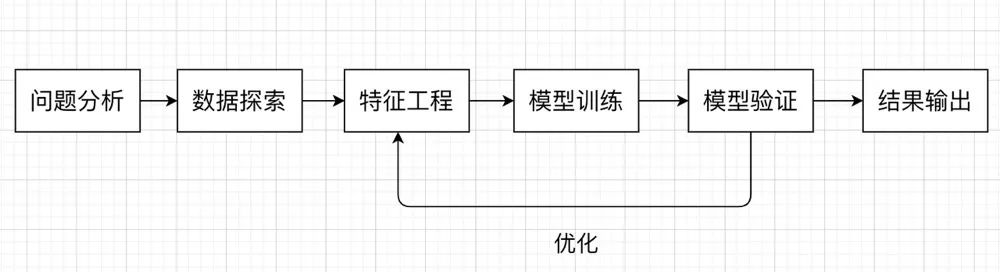
代码表现及优化建议
该Baseline代码在华为赛事提交的成绩为0.72+,排名50左右。若大家想学习提升,可参考以下三种思路:
继续尝试不同的预测模型或特征工程来提升模型预测的准确度 尝试模型融合等策略 查阅广告信息流跨域ctr预估预测相关资料,获取其他模型构建方法
代码实现
需要内存:10GB 运行时间:Tesla V100 32G,预计90分钟 代码环境:jupyter notbook或python编译器,可直接复制运行
#----------------环境配置----------------
#安装相关依赖库 如果是windows系统,cmd命令框中输入pip安装,参考上述环境配置
#!pip install sklearn
#!pip install pandas
#!pip install catboost
#--------------------------------------
#----------------导入库-----------------
# 数据探索模块使用第三方库
import pandas as pd
import numpy as np
import os
import gc
import matplotlib.pyplot as plt
from tqdm import *
# 核心模型使用第三方库
from catboost import CatBoostClassifier
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge
# 交叉验证所使用的第三方库
from sklearn.model_selection import StratifiedKFold, KFold
# 评估指标所使用的的第三方库
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, log_loss
# 忽略报警所使用的第三方库
import warnings
warnings.filterwarnings('ignore')
#--------------------------------------
# ----------------数据预处理-------------
# 读取训练数据和测试数据
train_data_ads = pd.read_csv('./2022_3_data/train/train_data_ads.csv')
train_data_feeds = pd.read_csv('./2022_3_data/train/train_data_feeds.csv')
test_data_ads = pd.read_csv('./2022_3_data/test/test_data_ads.csv')
test_data_feeds = pd.read_csv('./2022_3_data/test/test_data_feeds.csv')
# 合并数据
train_data_ads['istest'] = 0
test_data_ads['istest'] = 1
data_ads = pd.concat([train_data_ads, test_data_ads], axis=0, ignore_index=True)
train_data_feeds['istest'] = 0
test_data_feeds['istest'] = 1
data_feeds = pd.concat([train_data_feeds, test_data_feeds], axis=0, ignore_index=True)
del train_data_ads, test_data_ads, train_data_feeds, test_data_feeds
gc.collect()
# ----------------特征工程---------------
# 包含自然数编码、特征提取和内存压缩三部分内容。
# 1、自然数编码
def label_encode(series, series2):
unique = list(series.unique())
return series2.map(dict(zip(
unique, range(series.nunique())
)))
for col in ['ad_click_list_v001','ad_click_list_v002','ad_click_list_v003','ad_close_list_v001','ad_close_list_v002','ad_close_list_v003','u_newsCatInterestsST']:
data_ads[col] = label_encode(data_ads[col], data_ads[col])
# 2、特征提取
# data_feeds特征构建
# 特征提取部分围绕着data_feeds进行构建(添加源域信息)
# 主要是nunique属性数统计和mean均值统计。
# 由于是baseline方案,所以整体的提取比较粗暴,大家还是有很多的优化空间。
cols = [f for f in data_feeds.columns if f not in ['label','istest','u_userId']]
for col in tqdm(cols):
tmp = data_feeds.groupby(['u_userId'])[col].nunique().reset_index()
tmp.columns = ['user_id', col+'_feeds_nuni']
data_ads = data_ads.merge(tmp, on='user_id', how='left')
cols = [f for f in data_feeds.columns if f not in ['istest','u_userId','u_newsCatInterests','u_newsCatDislike','u_newsCatInterestsST','u_click_ca2_news','i_docId','i_s_sourceId','i_entities']]
for col in tqdm(cols):
tmp = data_feeds.groupby(['u_userId'])[col].mean().reset_index()
tmp.columns = ['user_id', col+'_feeds_mean']
data_ads = data_ads.merge(tmp, on='user_id', how='left')
# 3、内存压缩
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem))
return df
# 压缩使用内存
# 由于数据比较大,所以合理的压缩内存节省空间尤为的重要
# 使用reduce_mem_usage函数可以压缩近70%的内存占有。
data_ads = reduce_mem_usage(data_ads)
# Mem. usage decreased to 2351.47 Mb (69.3% reduction)
#--------------------------------------
# ----------------数据集划分-------------
# 划分训练集和测试集
cols = [f for f in data_ads.columns if f not in ['label','istest']]
x_train = data_ads[data_ads.istest==0][cols]
x_test = data_ads[data_ads.istest==1][cols]
y_train = data_ads[data_ads.istest==0]['label']
del data_ads, data_feeds
gc.collect()
#--------------------------------------
# ----------------训练模型---------------
def cv_model(clf, train_x, train_y, test_x, clf_name, seed=2022):
kf = KFold(n_splits=5, shuffle=True, random_state=seed)
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} {}************************************'.format(str(i+1), str(seed)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
params = {'learning_rate': 0.3, 'depth': 5, 'l2_leaf_reg': 10, 'bootstrap_type':'Bernoulli','random_seed':seed,
'od_type': 'Iter', 'od_wait': 50, 'random_seed': 11, 'allow_writing_files': False}
model = clf(iterations=20000, **params, eval_metric='AUC')
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=200,
cat_features=[],
use_best_model=True,
verbose=1)
val_pred = model.predict_proba(val_x)[:,1]
test_pred = model.predict_proba(test_x)[:,1]
train[valid_index] = val_pred
test += test_pred / kf.n_splits
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
print("%s_score_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test
cat_train, cat_test = cv_model(CatBoostClassifier, x_train, y_train, x_test, "cat")
#--------------------------------------
# ----------------结果保存---------------
x_test['pctr'] = cat_test
x_test[['log_id','pctr']].to_csv('submission.csv', index=False)参与内测
本文为Datawhale项目实践2.1教程,如果你是在校生,还在入门阶段,可以进内测学习群,我们在学习反馈中一起优化教程。(已参与不需要再进)
整理不易,点赞三连↓
评论