 码农有道公众号
码农有道公众号




无论是前端、后端,或者是客户端,还是算法;甚至是普通的非开发的用户,我觉得正则表达式都有必要去学习了解,因为它可以极大的提升我们的工作效率,这点对于开发人员来说可能体会更加深刻,特别是在定位线上问题的时候,面对密密麻麻的日志,怎样才能找出我们需要的那几条关键的日志,正则表达式就派上用场了。
什么是正则表达式
我不会在这里直接解释”正则表达式”是什么东东,我一直认为用一些专业词汇去给一个东西下定义就是一个扯淡的事情,只会让读者更加犯迷糊。
这里,我会演示日常中的一些需求,通过这些需求,你肯定就明白了什么是”正则表达式”。
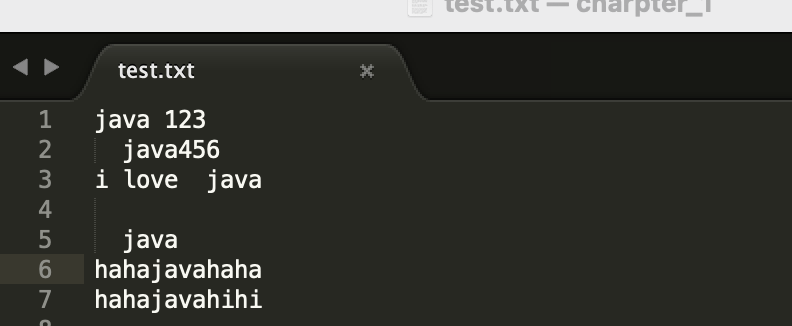
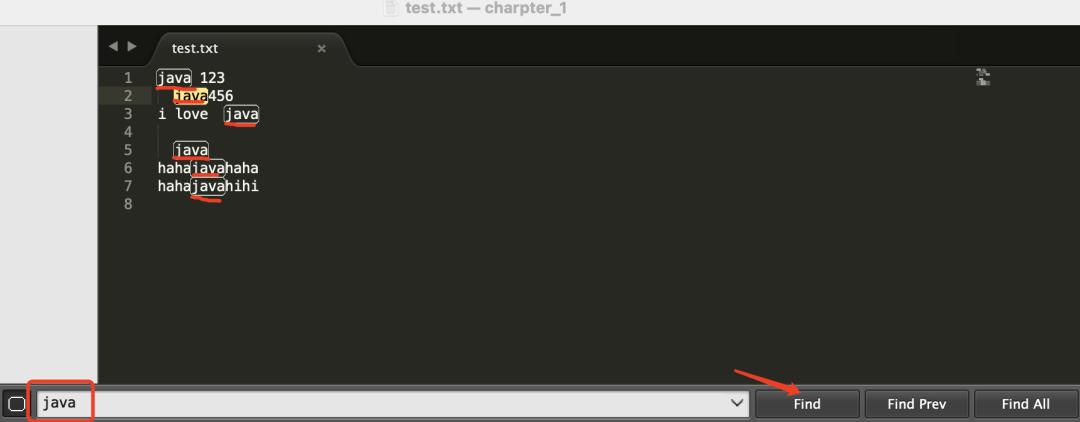
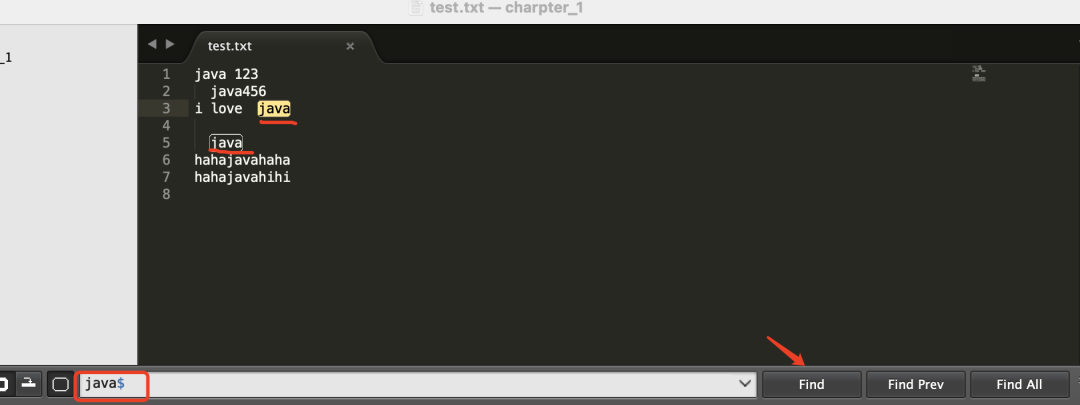
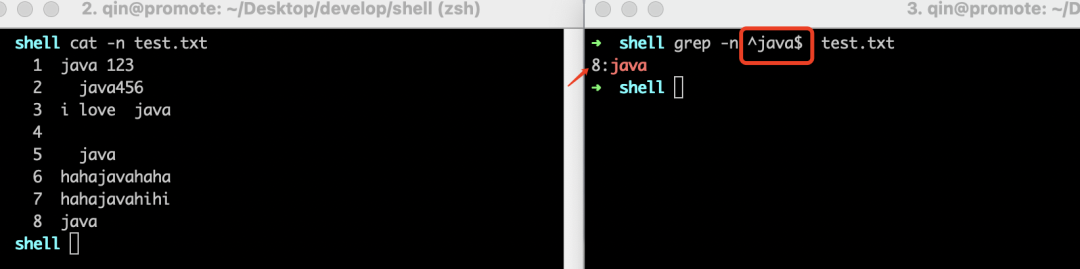
可以看到,在搜索框输入"java$",然后点击搜索,只有"java"位于行尾的第3行和第5行被标记满足条件。
好了,现在可以来解释什么是正则表达式了:”正则表达式”又称”规则表达式”,通常用来检索符合某个规则的文本。上面的例子,在正则表达式中,”$”就表示行尾,"java$"表达的规则就是位于行尾的java字符串。
正则表达式表达的规则有不少,下面按照分类给大家一一演示,演示过程中会用到grep命令,新手友情提示,这个命令也是大家必须掌握的一个命令。
鉴于正则表达式内容还是比较多的,因此还是想用两篇文章来介绍,这是第一篇。
位置规则
所谓的位置规则,其实是我自己取得一个名字,这组规则主要是用来描述你要搜索的词要出现在指定的位置才会匹配上。
| 正则符号 | 含义 |
| ^ | 匹配行首,此符号后面的内容必须出现在行首,才能匹配 |
| $ | 匹配行尾,此符号后面的内容必须出现在行尾,才能匹配 |
| \< | 匹配词首,其符号后面的内容必须在单词首部,才能匹配 |
| \> | 匹配词尾,其符号前面的内容必须在单词首尾,才能匹配 |
| ^$ | 匹配空行 |
| \B | 匹配非单词边界 |
对于上面表格中不明白的地方,没关系,看完下面的演示,相信肯定就能全明白了。
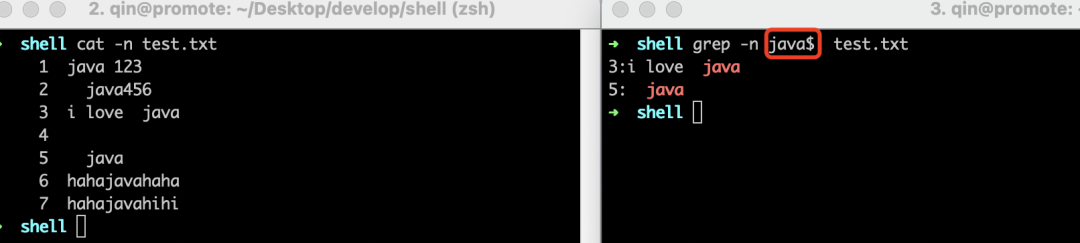
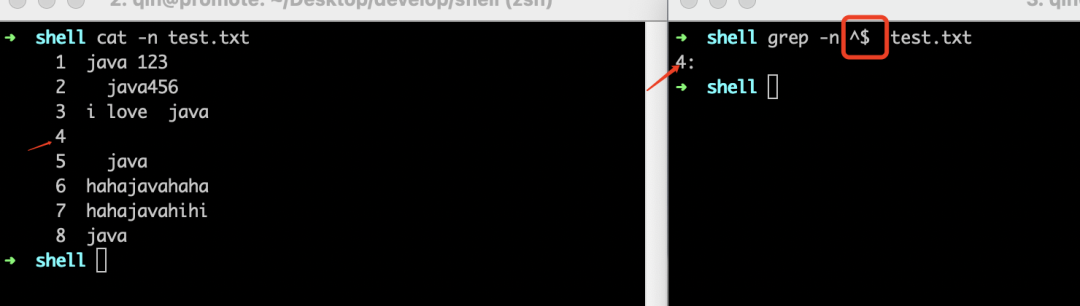
^和$

只有第一行的"java"是位于行首,被搜索出来了。其它6行尽管都包含"java",但是都不符合位于行首这个条件。
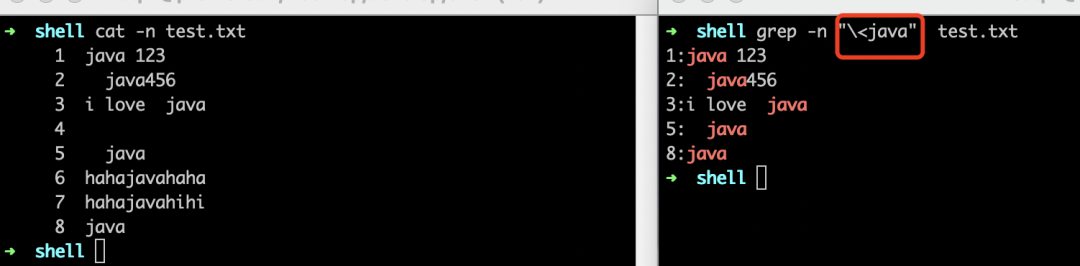
\<和\>
理解了"^"和"$",再来理解\<和\>的含义就容易多了,这里就不过多解释了,还是给几个示例,大家对着示例以及结果慢慢琢磨,不难理解\<和\>的用法。
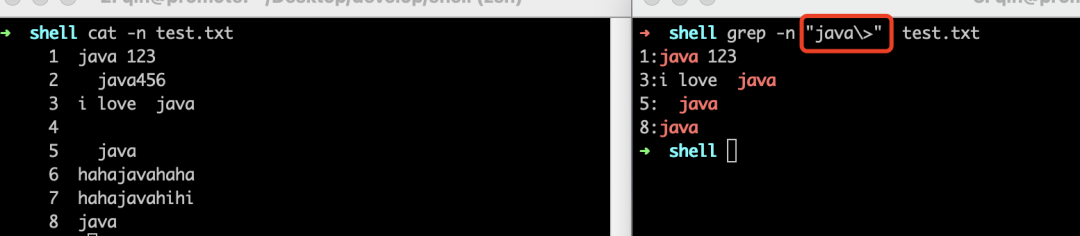
• 搜索"java"出现在词尾的行
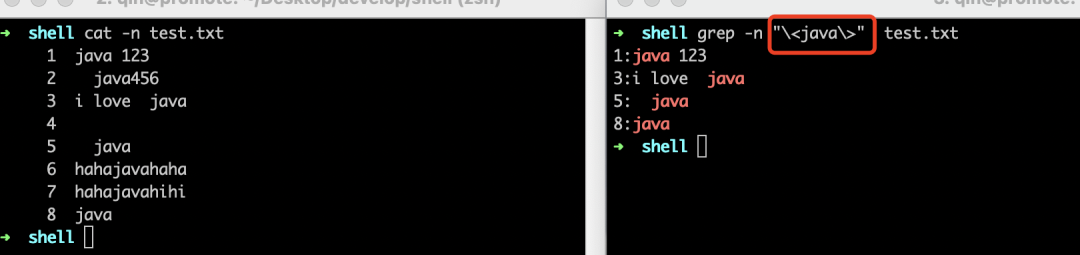
\B
“\B”是用来匹配”非单词边界”的,作用和"\<"以及"\>"相反,什么意思了,"<java"表示匹配"java"出现在词首的行,"\Bjava"则表示匹配"java"不出现在词首的行。同理,"java\B"则表示匹配"java"不出现在词尾的行。
这样说可能如果还没理解,看了示例就会秒懂,示例如下。
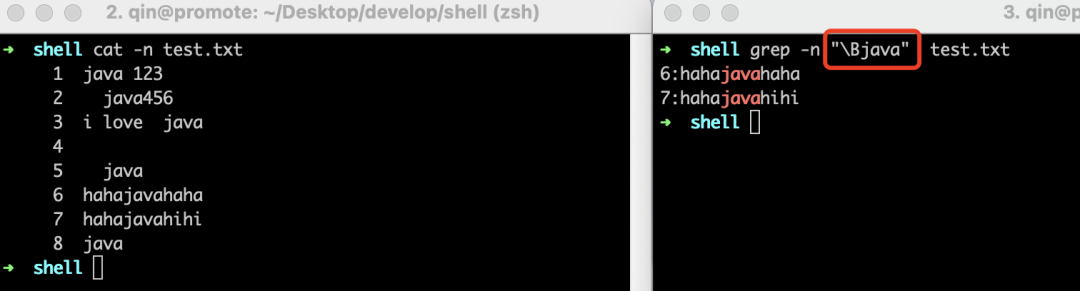
• 搜索"java"不出现在词尾的
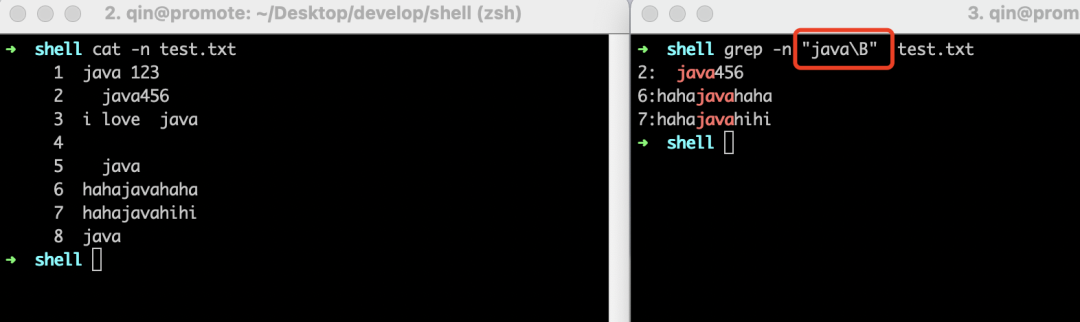
匹配次数规则
利用正则表达式可以匹配指定的字符出现指定的次数,这些正则表达式有以下几个:
| 正则符号 | 含义 |
| . | 表示任意单个字符。 |
| \? | 前面指定的字符出现0次或者1次,就会被匹配到 |
| \+ | 前面指定的字符连续出现至少1次,就会被匹配到 |
| * | 前面指定的字符连续出现任意次,包括0次,就会被匹配到 |
| \{m, n\} | 前面指定的字符至少连续出现m次,最多连续出现n次 |
| \{m,\} | 前面指定的字符至少连续出现m次,就会被匹配到 |
| \{,n\} | 前面指定的字符最多连续出现n次,就会被匹配到 |
| \{m\} | 前面指定的字符连续出现m次,就会被匹配到 |
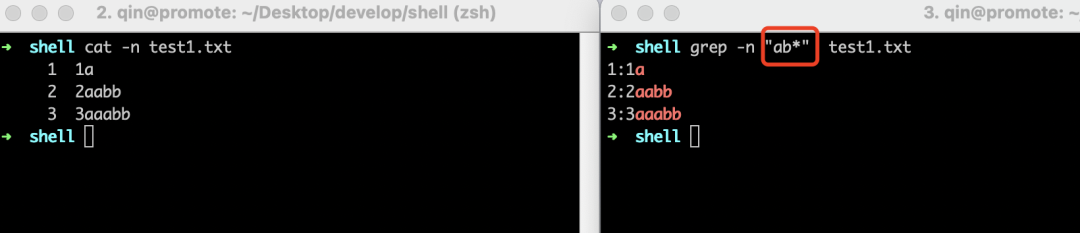
\? \+ *
我们先来认识第一一个用于匹配次数的正则符号,它就是*,它表示之前的字符连续出现任意次数。
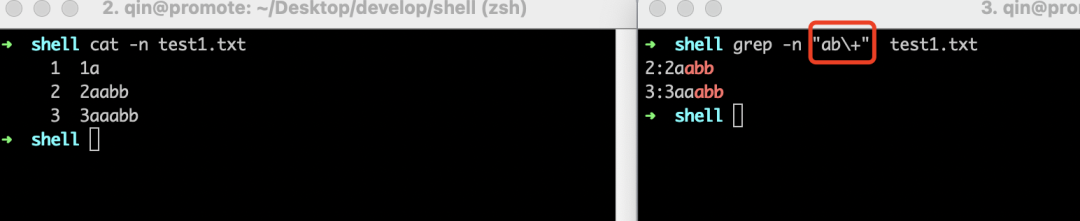
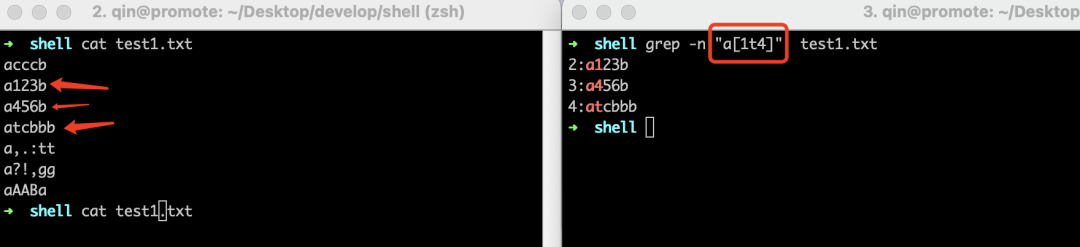
好了,我们再看看"\+"这个正则符号,它表示匹配其前面的字符至少1次,还是来看看下面的示例,可以看到第1行没有被匹配上,因为"ab\+"表示的是"a"字符后面的"b"字符至少要出现1次,第1行的字符"a"后面没有"b"字符,所以没有匹配上。
介绍完了"\+"以及"*",配合上面表格的描述,聪明的你一定也知道了"\?"的用法了,这里就不介绍了,大家可以自己猜想并动手进行实验验证。
{}系列
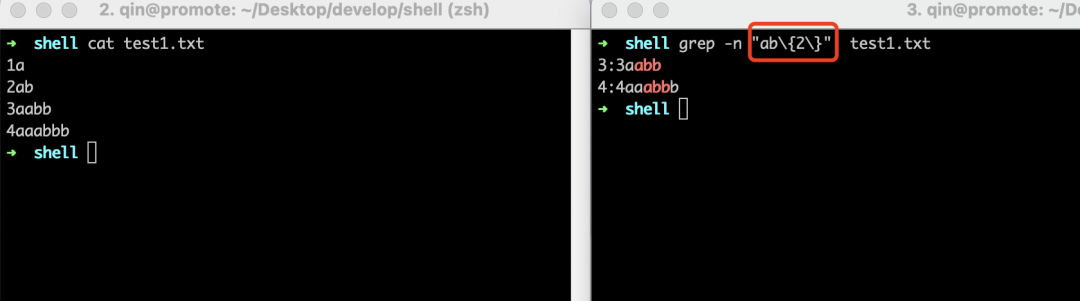
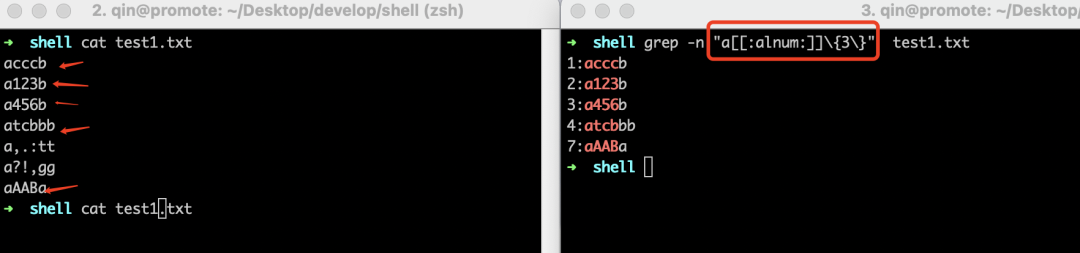
"\{m}\"表示匹配前面的字符m次。如果我们想要从test1.txt文件中找出哪些行包含两个连续"b",很简单,用"ab\{2\}"匹配即可。如下所示:

.



常用符号
正则表达式中,用来表达特定含义的常用符号有如下几个:
| 正则符号 | 含义 |
| [[:alpha:]] | 匹配任意大小写字母 |
| [[:lower:]] | 匹配任意小写字母 |
| [[:upper:]] | 匹配任意大写字母 |
| [[:digit:]] | 匹配0到9之间的任意单个数字 |
| [[:alnum:]] | 匹配任意数字或字母 |
| [[:space:]] | 匹配任意空白字符,包括"空格"、"tab键"等。 |
| [[:punct:]] | 匹配任意标点符号 |
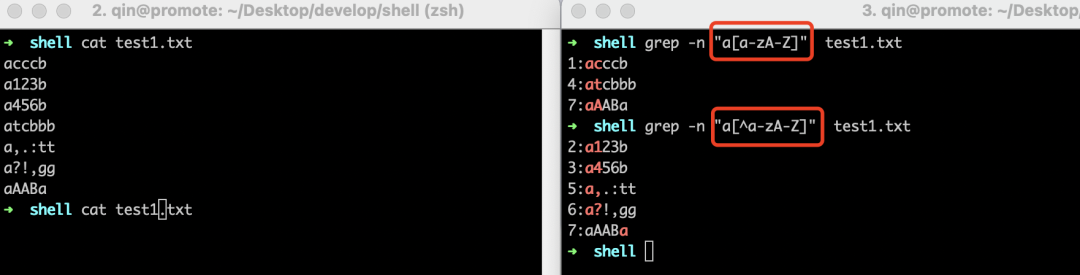
| [] | 匹配指定范围内的任意单个字符,如[agh]表示只要匹配上"a","g", "h"的任意一个都算匹配上。 |
| [^ ] | 和[]相反,表示指定范围外的任意单个字符 |
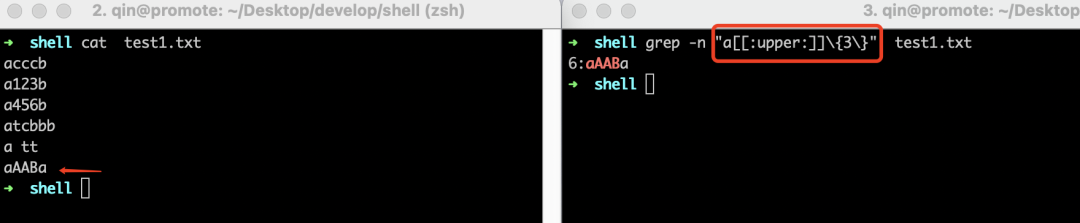
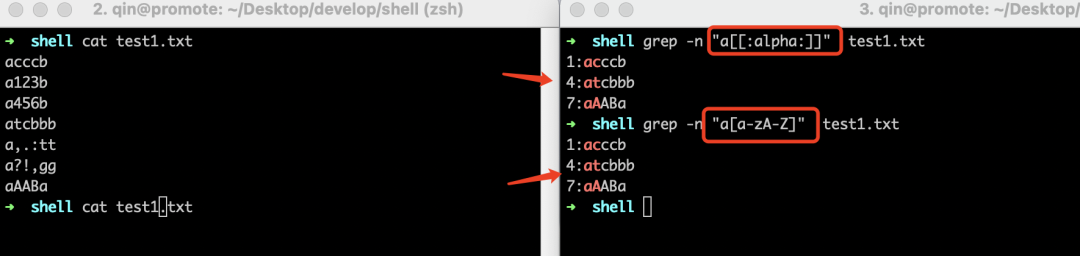
我们先来看看[[:alpha:]]这个符号,在介绍它之前,我们先来看看这样一个需求:需要匹配test1.txt文件中"a"后面出现三个任意字符的行,通过前面的学习,不难写出:

好了,很棒,但是现在我们改需求了:要求"a"后面出现的三个字符必须是字母,没错,这个需求就可以用[[:alpha:]]这个符号解决,[[:alpha:]]表示匹配任意大小写字母。如下所示:

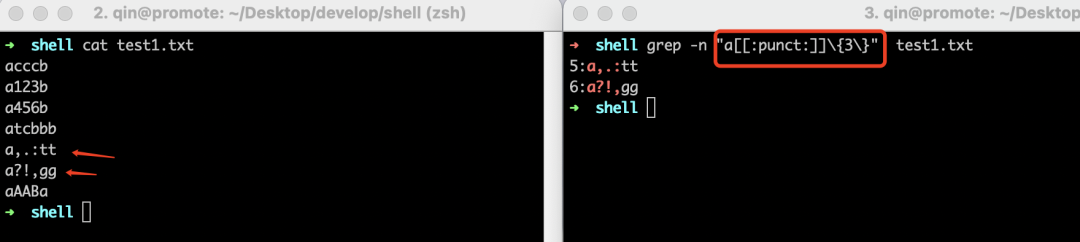
理解了[[:alpha:]],那么其它的也很容易理解了,这里不过多再解释了,下面给出几个示例,大家对着前面表格的描述,肯定是能理解的。



| 正则表达式 | 等效表达式 |
| [[:alpha:]] | [a-zA-Z] |
| [:upper:]] | [A-Z] |
| [[:lower:]] | [a-z] |
| [[:digit:]] | [0-9] |
| [[:alnum:]] | [a-zA-Z0-9] |
分组引用
我们来了解一下正则中的”分组”与”后向引用”。首先来看看什么是分组?还是先看个案例:需要从某个文件中找出,"ha"连续出现2次的行。

如果想要满足我们的需求,就需要用到”分组”,将”ha”当做一个”分组”,也就是说当做一个”整体”,才可以达到我们的目的,正确的写法如下:

后向引用
介绍完了分组,我们再来看看什么是后向引用,如果对分组还没理解的同学还是建议好好回过头复习下,否则后面会完全不知道在说什么。
后向引用是以分组为前提的,只有先进行分组,才能实现后向引用。为了描述清楚什么是后向引用,我们还是先循序渐进看几个例子。



可以看到,使用正则表达式"\(h.\{3\}\)java\1"达到了我们的要求,我们来分析下这个表达式的含义:
红色部分\(h.\{3\}\):表示大写字母h的后面跟随了3个任意字符,并且字母h与后面的3个字符将作为一个整体看待。
蓝色部分”\1″:表示整个正则中第1个分组中的正则所匹配到的结果,什么意思了,拿这个例子来说,整个正则表达式只有一个分组\(h.\{3\}\), 当分组与文件第一行匹配会匹配出haha,那么\1就表示haha。当分组与文件第二行匹配会匹配出hihi,那么\1就表示hihi。也就是说,”\1″引用了整个正则中第1个分组中的正则所匹配到的结果。

上面的两个正则表达式中,都出现了两个分组,一个分组嵌套着另一个分组。红色标注的符号是一对分组符号,蓝色标注的符号是一对分组符号,红色分组嵌套这蓝色分组。
再来详细分析两个正则表达式,除了”后向引用”的数字不一样,其它都是一模一样,但是得到的结果完全不一样。
在正则表达式中,分组的顺序取决于分组符号的左侧部分的顺序,也就是说,红色标注的左侧在蓝色标注左侧的前面,所以红色标注是第1个分组,蓝色标注的是第2个分组。
理解了上面这一点,再来分析两个正则表达式就很简单了,第一个正则表达式"\(x\(yz\)ab\)\1"中,后向引用的是第1个分组,而第1个分组是外面的\(x\(yz\)ab\),它匹配到xyzab,\1表示后向引用第1个分组匹配的结果xyzab,那么整个正则表达式匹配的是xyzabxyzab。
第一个正则表达式"\(x\(yz\)ab\)\2"中,后向引用的是第2个分组,而第2个分组是外面的\(yz\),它匹配到yz,\2表示后向引用第2个分组匹配的结果yz,那么整个正则表达式匹配的是xyzabyz。
扩展正则表达式
前面我们介绍的都是基本正则表达式,其实在Linux中,正则表达式可以分为”基本正则表达式”和”扩展正则表达式”。
看到这里,有同学可能就懵了,好不容易将前面的内容理解的差不多了,你竟然跟我说还有扩展正则表达式,不过不要担心,只要你掌握了基本正则表达式的用法,我可以保证你掌握扩展正则表达式那是分分钟的事。
其实,扩展正则表达式和前面介绍的基本正则表达式的符号至少80%是一样的。
这里我们将两者不同的地方总结如下:
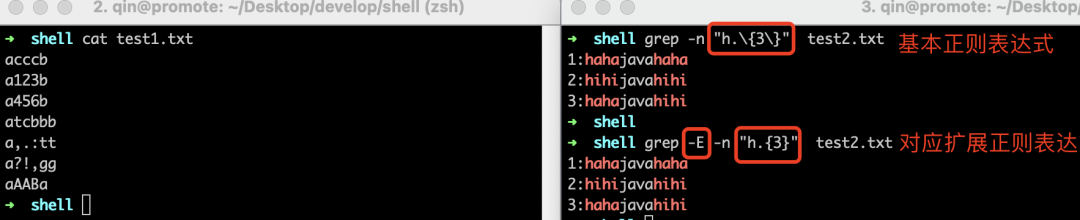
| 含义 | 基本正则表达式 | 对应的扩展正则表达式 |
| 匹配其前面的字符0或1次 | \? | ? |
| 匹配其前面的字符1或多次 | \+ | + |
| 匹配前面的字符连续出现m次 | \{m}\ | {m} |
| 匹配前面的字符至少连续出现m次 | \{m,}\ | {m,} |
| 匹配前面的字符最多连续出现n次 | \{,n}\ | {,n} |
| 匹配前面的字符连续出现至少m次,最多n次 | \{m,n}\ | {m,n} |
| 或 | 无 | | |
可以看到,相对于基本正则表达式,对于次数匹配的很多符号,其对应的扩展正则表达式少了前面的”\”,更加简洁了,可读性也就就变强了。


好了,重头戏来了,现在我们想要找出文件中行首以"ha"开始的行,或者行首以"hi"开始的行,这就用到了"|"。“|”在扩展正则表达式中,就表示”或”的含义,如下所示:


