
特征选择的通俗讲解!
算法进阶
共 8287字,需浏览 17分钟
· 2022-07-31
收集的数据格式不对(如 SQL 数据库、JSON、CSV 等)
缺失值和异常值
标准化
减少数据集中存在的固有噪声(部分存储数据可能已损坏)
数据集中的某些功能可能无法收集任何信息以供分析
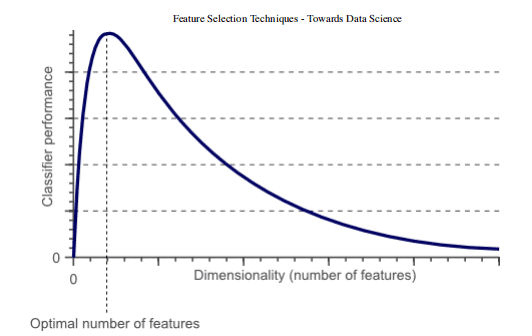
提高精度
降低过拟合风险
加快训练速度
改进数据可视化
增加我们模型的可解释性


X = df.drop(['class'], axis = 1)Y = df['class']X = pd.get_dummies(X, prefix_sep='_')Y = LabelEncoder().fit_transform(Y)X2 = StandardScaler().fit_transform(X)X_Train, X_Test, Y_Train, Y_Test = train_test_split(X2, Y, test_size = 0.30, random_state = 101)
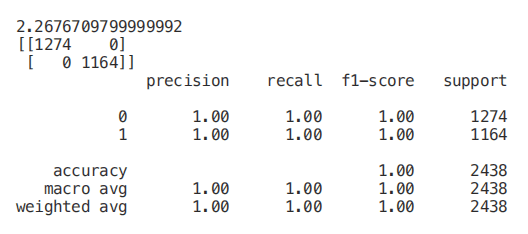
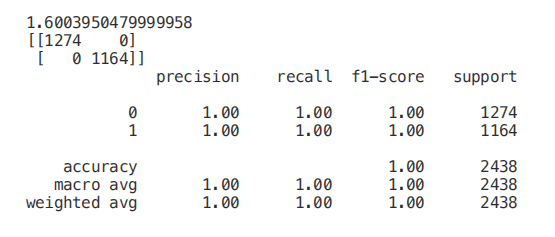
start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train,Y_Train)print(time.process_time() - start)predictionforest = trainedforest.predict(X_Test)print(confusion_matrix(Y_Test,predictionforest))print(classification_report(Y_Test,predictionforest))
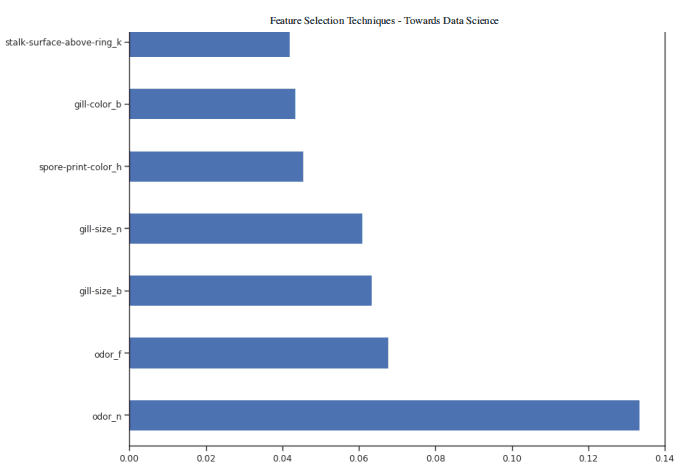
figure(num=None, figsize=(20, 22), dpi=80, facecolor='w', edgecolor='k')feat_importances = pd.Series(trainedforest.feature_importances_, index= X.columns)feat_importances.nlargest(7).plot(kind='barh')
X_Reduced = X[['odor_n','odor_f', 'gill-size_n','gill-size_b']]X_Reduced = StandardScaler().fit_transform(X_Reduced)X_Train2, X_Test2, Y_Train2, Y_Test2 = train_test_split(X_Reduced, Y, test_size = 0.30, random_state = 101)start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train2,Y_Train2)print(time.process_time() - start)predictionforest = trainedforest.predict(X_Test2)print(confusion_matrix(Y_Test2,predictionforest))print(classification_report(Y_Test2,predictionforest))
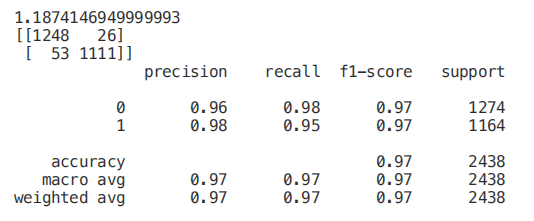
start = time.process_time()trainedtree = tree.DecisionTreeClassifier().fit(X_Train, Y_Train)print(time.process_time() - start)predictionstree = trainedtree.predict(X_Test)print(confusion_matrix(Y_Test,predictionstree))print(classification_report(Y_Test,predictionstree))
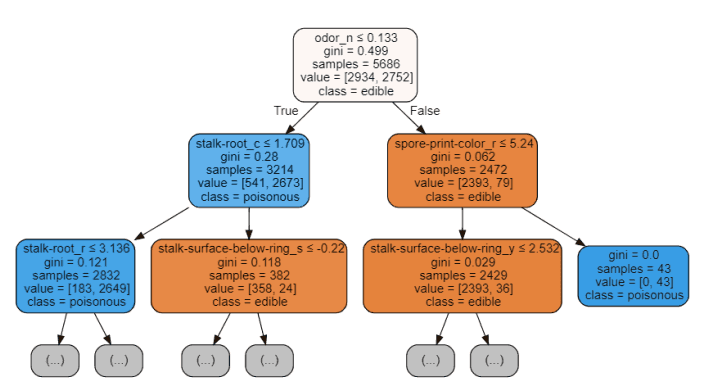
import graphvizfrom sklearn.tree import DecisionTreeClassifier, export_graphvizdata = export_graphviz(trainedtree,out_file=None,feature_names= X.columns,class_names=['edible', 'poisonous'],filled=True, rounded=True,max_depth=2,special_characters=True)graph = graphviz.Source(data)graph
from sklearn.feature_selection import RFEmodel = RandomForestClassifier(n_estimators=700)rfe = RFE(model, 4)start = time.process_time()RFE_X_Train = rfe.fit_transform(X_Train,Y_Train)RFE_X_Test = rfe.transform(X_Test)rfe = rfe.fit(RFE_X_Train,Y_Train)print(time.process_time() - start)print("Overall Accuracy using RFE: ", rfe.score(RFE_X_Test,Y_Test))
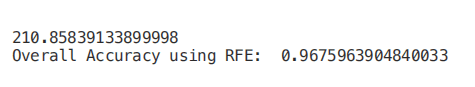
SelecFromModel
from sklearn.ensemble import ExtraTreesClassifierfrom sklearn.feature_selection import SelectFromModelmodel = ExtraTreesClassifier()start = time.process_time()model = model.fit(X_Train,Y_Train)model = SelectFromModel(model, prefit=True)print(time.process_time() - start)Selected_X = model.transform(X_Train)start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(Selected_X, Y_Train)print(time.process_time() - start)Selected_X_Test = model.transform(X_Test)predictionforest = trainedforest.predict(Selected_X_Test)print(confusion_matrix(Y_Test,predictionforest))print(classification_report(Y_Test,predictionforest))
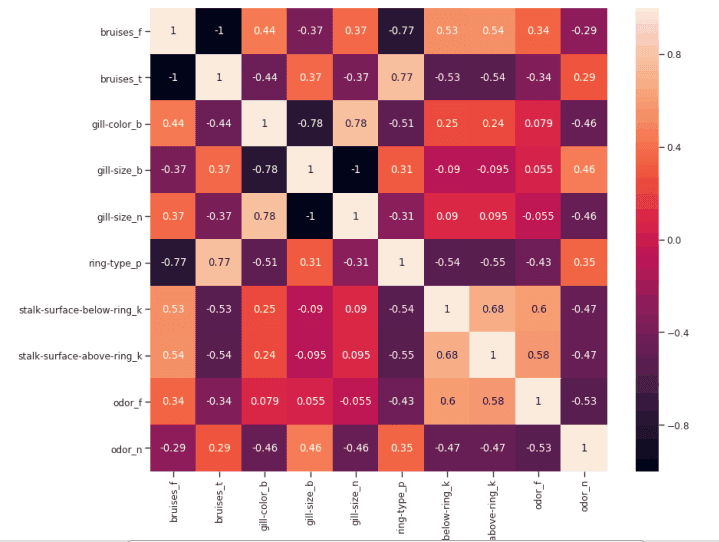
如果两个特征之间的相关性为 0,则意味着更改这两个特征中的任何一个都不会影响另一个。
如果两个特征之间的相关性大于 0,这意味着增加一个特征中的值也会增加另一个特征中的值(相关系数越接近 1,两个不同特征之间的这种联系就越强)。
如果两个特征之间的相关性小于 0,这意味着增加一个特征中的值将使减少另一个特征中的值(相关性系数越接近-1,两个不同特征之间的这种关系将越强)。
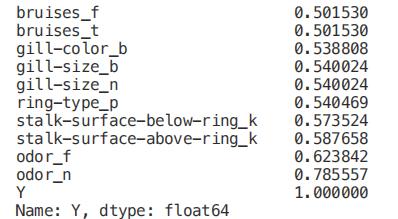
Numeric_df = pd.DataFrame(X)Numeric_df['Y'] = Ycorr= Numeric_df.corr()corr_y = abs(corr["Y"])highest_corr = corr_y[corr_y >0.5]highest_corr.sort_values(ascending=True)
figure(num=None, figsize=(12, 10), dpi=80, facecolor='w', edgecolor='k')corr2 = Numeric_df[['bruises_f' , 'bruises_t' , 'gill-color_b' , 'gill-size_b' , 'gill-size_n' , 'ring-type_p' , 'stalk-surface-below-ring_k' , 'stalk-surface-above-ring_k' , 'odor_f', 'odor_n']].corr()sns.heatmap(corr2, annot=True, fmt=".2g")
单变量选择
Classification = chi2, f_classif, mutual_info_classif
Regression = f_regression, mutual_info_regression
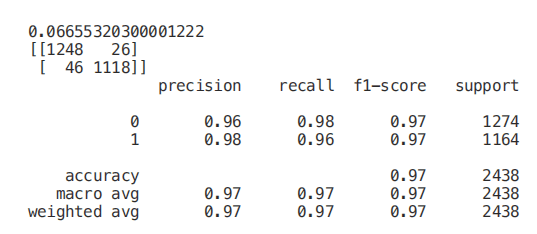
from sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2min_max_scaler = preprocessing.MinMaxScaler()Scaled_X = min_max_scaler.fit_transform(X2)X_new = SelectKBest(chi2, k=2).fit_transform(Scaled_X, Y)X_Train3, X_Test3, Y_Train3, Y_Test3 = train_test_split(X_new, Y, test_size = 0.30, random_state = 101)start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train3,Y_Train3)print(time.process_time() - start)predictionforest = trainedforest.predict(X_Test3)print(confusion_matrix(Y_Test3,predictionforest))print(classification_report(Y_Test3,predictionforest))
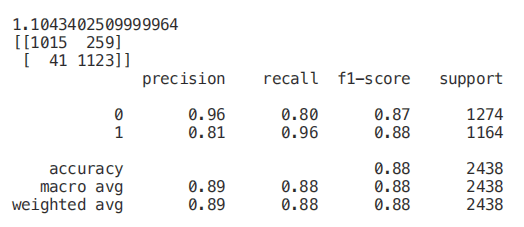
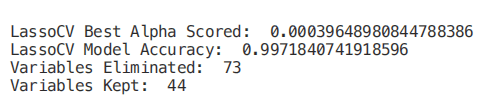
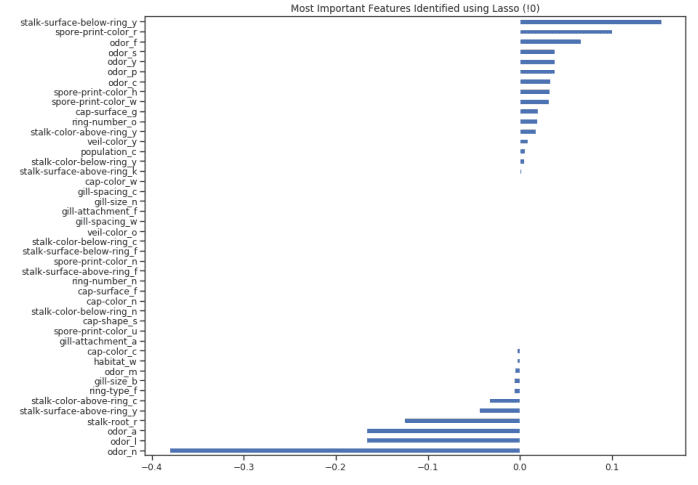
from sklearn.linear_model import LassoCVregr = LassoCV(cv=5, random_state=101)regr.fit(X_Train,Y_Train)print("LassoCV Best Alpha Scored: ", regr.alpha_)print("LassoCV Model Accuracy: ", regr.score(X_Test, Y_Test))model_coef = pd.Series(regr.coef_, index = list(X.columns[:-1]))print("Variables Eliminated: ", str(sum(model_coef == 0)))print("Variables Kept: ", str(sum(model_coef != 0)))
figure(num=None, figsize=(12, 10), dpi=80, facecolor='w', edgecolor='k')top_coef = model_coef.sort_values()top_coef[top_coef != 0].plot(kind = "barh")plt.title("Most Important Features Identified using Lasso (!0)")
评论
【第129期】程序员的新宠:三款终端工具,让你告别Xshell!
概述 WindTerm:跨平台的SSH利器 首先介绍的是WindTerm,这是一款使用C语言开发的跨平台SSH客户端。它不仅完全免费,而且没有商业使用的限制。WindTerm支持SSH v2、Telnet、Raw Tcp等协议,而且性能出色,甚至超过了FinalShell和Electerm。功能
前端微服务
0
上班的时候,有一群摸鱼搭子非常重要...
上班的时候,有一群摸鱼搭子非常重要!一到上班时间,他们就从四面八方涌进群里冒泡...从八卦聊到股市、从职场聊到乌X兰局势,偶尔还会复读、相亲、battle...然后,下午6点钟准时消失不见...所以你要不要加入我们一起摸鱼?我们有北京、上海、深圳、广州、杭州、武汉、成都、南京等8个城市的摸鱼群,还有
产品经理日记
0
周四002 瑞超:同样落寞的境遇——北雪平vs埃尔夫斯堡
上赛季最终排名联赛第9的北雪平本赛季伊始表现不佳,4轮战罢他们仅以1胜1平2负的战绩排在倒数第三,这支历史上曾夺得13次联赛冠军、6次杯赛冠军老牌劲旅,正如英格兰赛场上的一众百年俱乐部,在低谷中不断探索着出路。球队主教练安德烈亚斯·阿尔姆曾是AIK索尔纳及赫根队的主教练,他于今年年初刚刚拿起球队教鞭
产品与体验
0
日本影山优佳最新杂志照,展现充满透明感的美丽
今天的图文分享的是影山优佳的杂志写真。元日向坂46的影山优佳,登上了写真杂志《周刊FLASH》5/7和5/14合并号的封面。影山优佳是日本艺人、女演员、前偶像。身高155厘米。2001年5月8日出生于东京都。2023年7月从组合日向坂46毕业,之后作为演员活跃的影山优佳,在《周刊FLAS
python教程
0
盘点一个使用超级鹰识别验证码并自动登录的案例
点击上方“Python共享之家”,进行关注回复“资源”即可获赠Python学习资料今日鸡汤江上几人在,天涯孤棹还。大家好,我是皮皮。一、前言前几天在Python钻石交流群【静惜】问了一个Python实现识别验证码并自动登录的问题,提问截图如下:验证码的截图如下所示:二、实现过程这里大家激烈的探讨,【
IT共享之家
0
朋友,你也不想一个人孤孤单单的上班吧?
上班的时候,有一群摸鱼搭子非常重要!一到上班时间,他们就从四面八方涌进群里冒泡...从八卦聊到股市、从职场聊到乌X兰局势,偶尔还会复读、相亲、battle...然后,下午6点钟准时消失不见...所以你要不要加入我们一起摸鱼?我们有北京、上海、深圳、广州、杭州、武汉、成都、南京等8个城市的摸鱼群,还有
产品经理日记
0
美团社招一面,比预想的简单。
面试题大全:www.javacn.site面试这件事就很玄学,有时候你觉得他可能很难,但面完之后竟然出奇的顺利,问的问题你都会;有些你觉得这次面试应该很简单,但去了之后就被问懵了,所以面试这件事有很多一部分运气的成分。所以说,在没有 Offer 之前就是多准备、楞怂面,主打一个大力出奇迹。这不,逛牛
Java中文社群
0
Eiten 一个构建投资组合的好帮手
Eiten是Tradytics的一个开源工具包,它实现了各种统计和算法投资策略,如Eigen组合、最小方差组合、最大夏普比率组合和基于遗传算法的组合。Eiten允许你用自己的股票组合建立自己的投资组合。Eiten中自带的严格测试框架使你能够对你的投资组合更有自信。1.准备开始之前,你要确保Pytho
Python实用宝典
0