
浅聊对比学习(Contrastive Learning)
共 8518字,需浏览 18分钟
· 2022-07-31
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文通过解读对比学习的经典论文和综述,介绍对比学习的概念,主流方法和优势。对于不同方法的算法设计和实验结果,作者提供了他的深入思考。
什么是对比学习?
对比学习在解决什么问题?
如何学习representation
解决数据稀疏的问题
如何更好的利用没有label的数据
未打标的数据远远多于打标的数据,不用简直太浪费了,但是要打标又是一个耗时耗力耗钱的事儿 有监督学习的缺点:
泛化能力 Spurious Correlations伪相关 (https://www.zhihu.com/question/409100594) Adversarial Attacks对抗攻击 (https://zhuanlan.zhihu.com/p/104532285)
为什么现有的方法解决不了这个问题?
有监督学习天然所带来的问题:泛化能力、过拟合、对抗攻击等等 有监督学习本身就无法使用无标签的数据
现有的对比学习方法
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models
知乎:https://zhuanlan.zhihu.com/p/58369131 CSDN:https://blog.csdn.net/littlely_ll/article/details/79252064
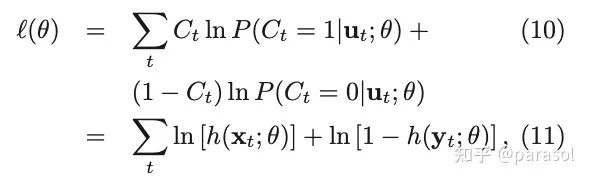
但是这里会出现一个问题,如果我们的noise分布选的不好,效果可能并不一定会好,所以在这篇paper里作者也提到了在增加noise的时候,尽量和现有的数据分布相似,这样能最大程度上提高训练的效果。
Intuitively, the noise distribution should be close to the data distribution, because otherwise, the classification problem might be too easy and would not require the system to learn much about the structure of the data. As a consequence, one could choose a noise distribution by first estimating a preliminary model of the data, and then use this preliminary model as the noise distribution.
这个方法在推荐里的应用,个人观点是可以在召回里来尝试,毕竟现在的召回面临着很大的selection bias问题(有朋友在召回里尝试过,效果一般,只能说明老paper时间比较久了,已经被现在的SOTA beat掉了,不过这篇文章的idea很有意思,数学证明也很不错,可以学习下)
Representation Learning with Contrastive Predictive Coding
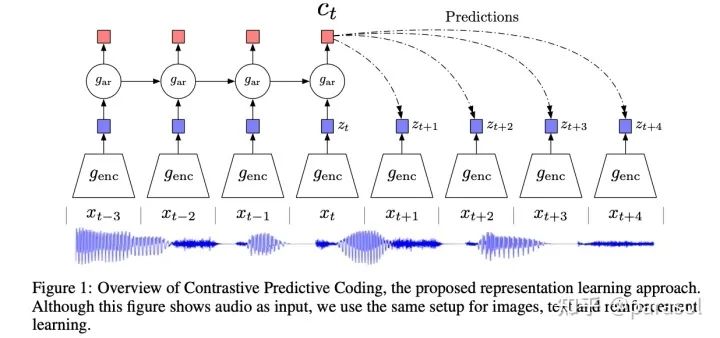
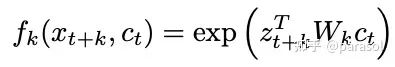

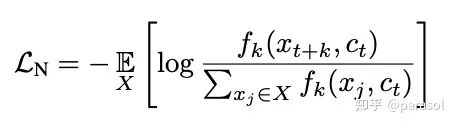
从而将一个生成模型 转变成了分类模型
训练出来的 和 可以用于下游的任务:比如分类任务等等
文章比较有意思的点:证明了互信息的下界和总样本数是有关的,N越大,互信息越大

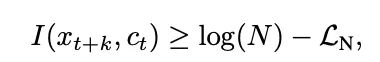
Learning Deep Representations by Mutual Information Estimation and Maximization
我对这一点有点concern,什么样的编码空间是 更好的空间呢?这个先验也只能去拍,怎么去拍,只能不断的去尝试吗,是不是可以学成一个动态的空间,如果我们的数据是多峰的,可能一个分布就不太能拟合,混合高斯分布会不会更优?感觉都是可以改进的方向)
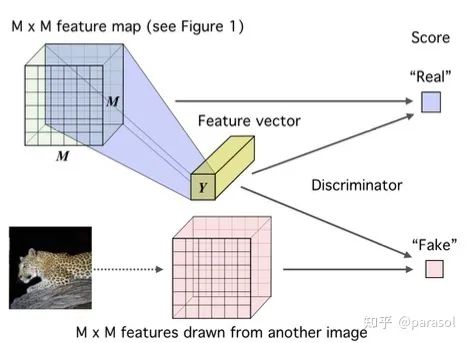
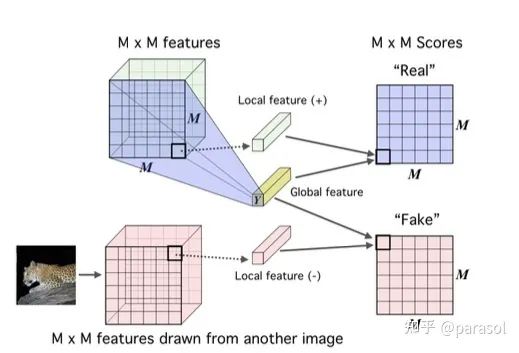
global MI/local MI: 这俩没啥好介绍的,global是拿输入和全局的feature去做MI的计算,local是拿中间的feature和全局的feature去做MI的计算(多的这部分local的loss,我个人的理解其实也是换了种方式来增大样本数量,进而带来了收益)
Prior matching(adversarial autoencoders):拍了一个feature的先验分布,训练一个discriminator,然后让这个discriminator和模型学到的全局feature进行battle(对抗学习的min-max方式),编码器的输出更符合先验的分布,感觉这个就有点玄学了~
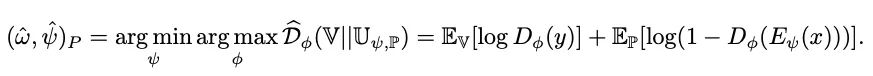
Loss:前面两项分别对应global和local,最后一项对应Prior matching
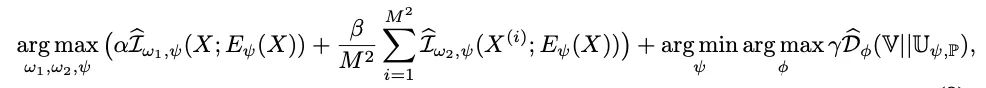
SimCLR-A Simple Framework for Contrasting Learning of Visual Representations
loss就是softmax loss + temperature 这里有个需要注意的点,他在学到的 后面加了一个 ,然后进行loss的计算和梯度的回传,最后真正在使用的时候用的只有 ,这里作者的猜想和实验确实很有意思,很值得借鉴。(虽然在SimCLRV2中这个结论有变的很不一样了哈哈哈,后面会讲到) 框架图:模型训练的时候 和 同时训练,但是训练完后,就把 扔掉了,只保留 ,这里是我觉得这篇论文最有意思的点,一般的思路其实应该是直接用 的输出去计算对比学习的loss~
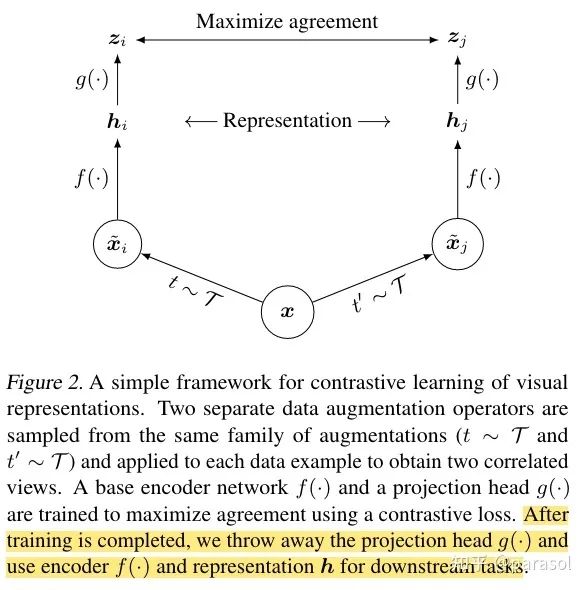
代表data augmentation方式的集合:比如旋转,灰度,裁剪等等 batch_size = N,对每个batch内的每张图片,随机从 中选择两种data augmentation,得到两张图片,这两张图片就是一个正样本对,总共可以生成2N个样本,每个样本有一个样本和自己是正样本对,剩下的2N-2都是负样本,这里是用了一个softmax+temperature的loss

实验图太多就不贴了,想看detail的可以直接看我的「paper_reading记录:https://bytedance.feishu.cn/docx/doxcn0hAWqSip1niZE2ZCpyO4yb」,只对个人认为有意思的点说下
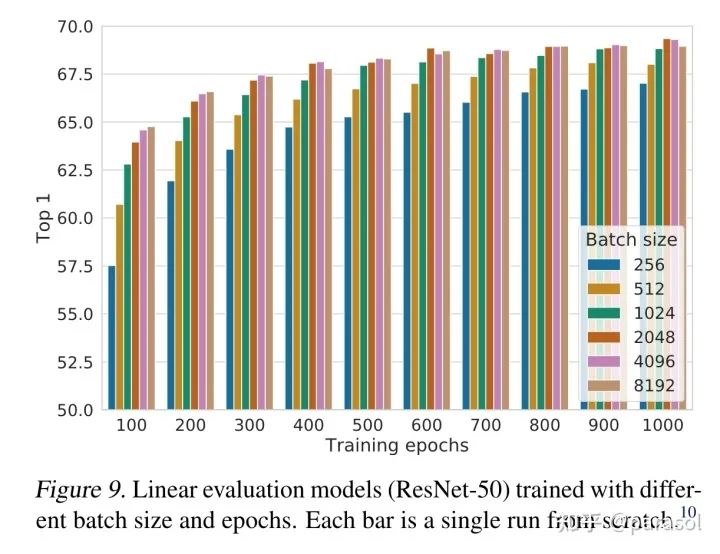
实验证明对比学习可以从更大的batch size和更长的训练时间上受益
作者自己在这里也说:效果的提升是来自于batch_size越大,训练时间越久,见过的负样本越多,所以效果越好,这里其实和batch_softmax也有异曲同工之妙,在推荐里其实也有类似的经验~
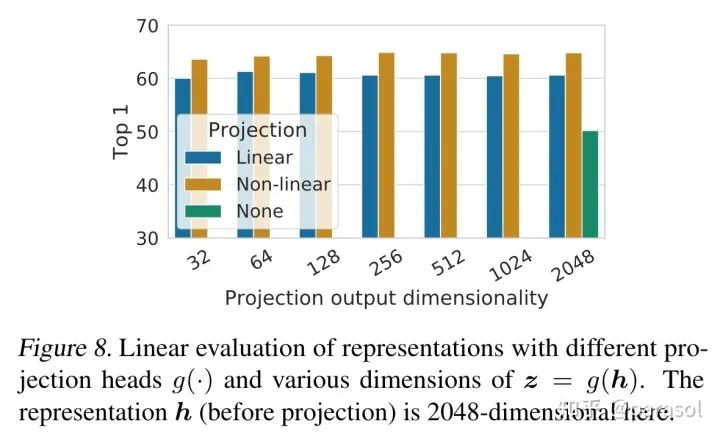
验证在对比学习loss计算之前加入一个非线性的映射层会提高效果
作者认为是g被训练的能够自动去掉data transformation的噪音,为了验证这个猜想,作者做了这个实验:用h和g(h)来区分做了哪种data transformation,从下面第二张实验结果图看出,h确实保留了data transformation的信息
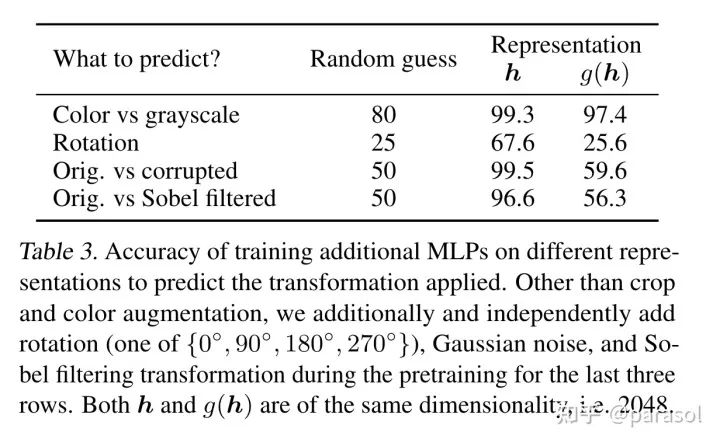
其他贡献
实验证明「组合不同的data augumentation」的重要性
实验证明对比学习需要比有监督学习需要更强的data agumentation
实验证明无监督对比学习会在更大的模型上受益
实验证明了不同loss对效果的影响
SimCLRV2-Big Self-Supervised Models are Strong Semi-Supervised Learners
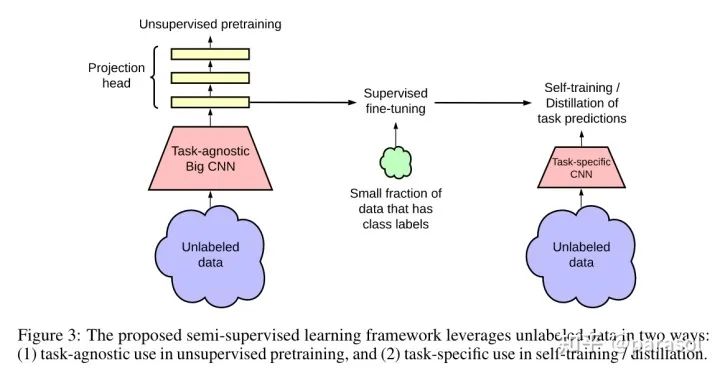
Pretraining:用了SimCLR,然后用了更深的projection head,同时不是直接把projection head丢了,而是用projection head的1st layer,来做后面的fine tune。(这也太trick了吧) Fine-tune:用SimCLR训练出来的网络,接下游的MLP,做classification任务,进行fine-tune disitill:用训好的teacher network给无label的数据打上标签,作为ground truth,送给student network训练。这个地方作者也尝试了加入有标签的(样本+标签),发现差距不大,所以就没有使用有监督样本的(样本+标签)
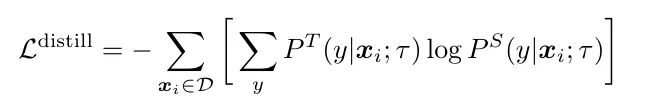
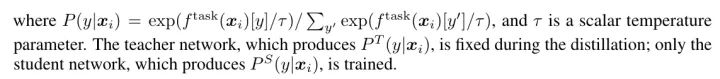
实验图就不全贴了,想看detail的可以直接看我的「paper_reading记录:https://bytedance.feishu.cn/docx/doxcn9P6oMZzuwZOrYAhYc5AUUe」
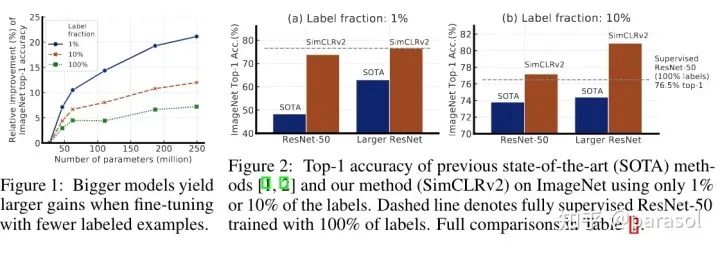
Distillation Using Unlabeled Data Improves Semi-Supervised Learning
这个实验很有意思的点是,无论是self-distillation还是distill small model,效果都比teacher model效果好,这里的解释可以看这里:
知乎:https://zhuanlan.zhihu.com/p/347890400;
原文:https://arxiv.org/pdf/2012.09816.pdf
很有趣~主要在说:distill能让student学到更多的视图,从而提升了效果~
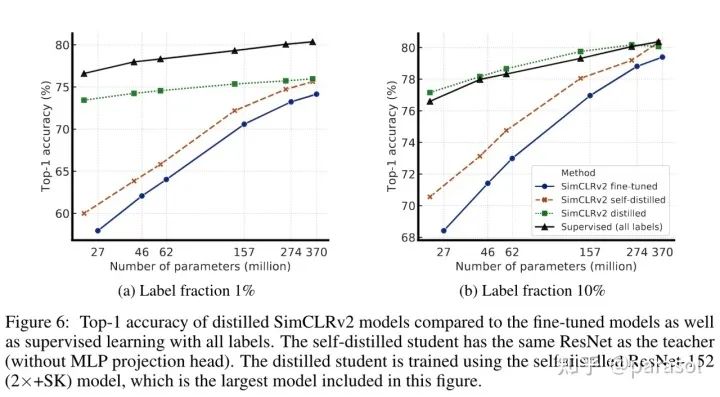
Bigger Models Are More Label-Efficient
Bigger/Deeper Projection Heads Improve Representation Learning
Mutual Information Neural Estimation
给定一个batch内的数据 ,其中 就是我们的训练集,batch_size = b 然后从训练集中随机sample b个z,作为负样本 计算loss,并回传梯度

实验图就不全贴了,想看detail的可以直接看我的「paper_reading记录:https://bytedance.feishu.cn/docx/doxcnMHzZBeWFV4HZV6NAU7W73o」
捕获非线性的依赖的能力
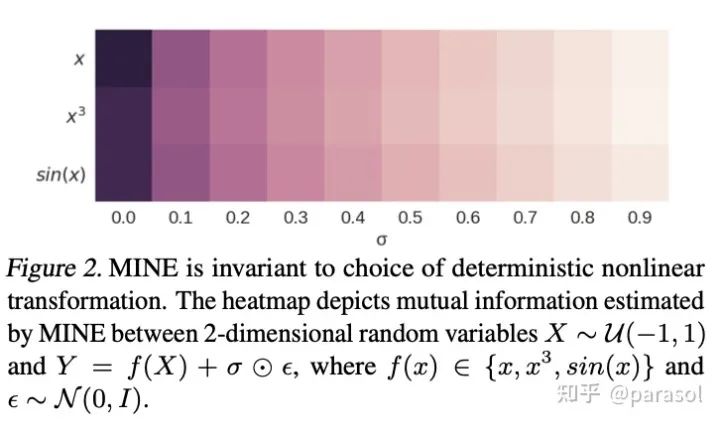
GAN上的应用:

Bi-GAN上的应用:
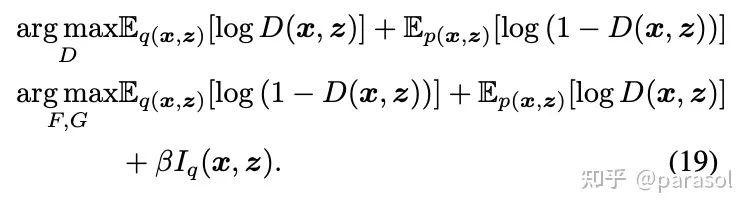
对比学习在推荐里的应用场景
负采样逻辑优化:现在很多推荐系统里的负采样都是随机采样的,虽然随机采样已经能拿到不错的效果了,但是一定还有优化空间,比如InfoNce文章中提到的增大负采样的个数能够提升互信息的下界,同时在工业界的best practice中,往往也能发现batch_softmax的效果也很不错 i2i召回:基于item2item召回的时候,往往是基于item1的embedding去召回与item1相似的items,这时候embedding的相似性就显得尤为重要,但是这里有个问题,如何选择构造与item1相似的item作为正样本?(用户点击过的作为item作为相似的样本也不合理,毕竟用户的兴趣是多维的,点过的每个样本不可能都属于同一个类别或者相似的,虽然通过推荐的大量数据,协同过滤可能可以在全局找到一个还不错的结果,但是直接拿用户序列作为正样本来做一定是不合理的)
一点小思考
可以比较好的单独优化representation,和下游任务无关,能够最大程度上的保留meta-information,如果一旦做有监督的学习,那抽取出来的信息就是和当前目标相关的,不排除可能学到一些噪音特征 在做data augumentation,模型见到了更多的样本,记忆的东西更全,效果好也是预期之中的 去噪
Reference
Gutmann M, Hyvärinen A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models[C]//Proceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2010: 297-304. Oord A, Li Y, Vinyals O. Representation learning with contrastive predictive coding[J]. arXiv preprint arXiv:1807.03748, 2018. Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. arXiv preprint arXiv:1808.06670, 2018. Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. arXiv preprint arXiv:1808.06670, 2018. GitHub - asheeshcric/awesome-contrastive-self-supervised-learning: A comprehensive list of awesome contrastive self-supervised learning papers. (https://github.com/asheeshcric/awesome-contrastive-self-supervised-learning) 张俊林:对比学习(Contrastive Learning):研究进展精要 (https://zhuanlan.zhihu.com/p/367290573) 极市平台:深度学习三大谜团:集成、知识蒸馏和自蒸馏:https://zhuanlan.zhihu.com/p/347890400 Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607. Chen T, Kornblith S, Swersky K, et al. Big self-supervised models are strong semi-supervised learners[J]. Advances in neural information processing systems, 2020, 33: 22243-22255. Belghazi M I, Baratin A, Rajeshwar S, et al. Mutual information neural estimation[C]//International conference on machine learning. PMLR, 2018: 531-540. Allen-Zhu Z, Li Y. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning[J]. arXiv preprint arXiv:2012.09816, 2020.

点个在看 paper不断!