 云加社区
云加社区





导语 | 本文主要介绍一下线程、协程的原理,以及写成的基本使用,希望能对此方面感兴趣的开发者提供一些经验和启发。
引言
Golang的语法和运行时直接内置了对并发的支持。Golang里的并发指的是能让某个函数独立于其他函数运行的能力。当一个函数创建为goroutine时,Golang会将其视为一个独立的工作单元。这个单元会被调度到可用的逻辑处理器上执行。
Golang运行时的调度器是一个复杂的软件,能管理被创建的所有goroutine并为其分配执行时间。这个调度器在操作系统之上,将操作系统的线程与语言运行时的逻辑处理器绑定,并在逻辑处理器上运行goroutine。调度器在任何给定的时间,都会全面控制哪个goroutine要在哪个逻辑处理器上运行。Golang的并发同步模型来自一个叫作通信顺序进程(Communicating Sequential Processes,CSP)的范型(paradigm)。CSP是一种消息传递模型,通过在goroutine之间传递数据来传递消息,而不是对数据进行加锁来实现同步访问。用于在goroutine之间同步和传递数据的关键数据类型叫作通道(channel)。
调度器对可以创建的逻辑处理器的数量没有限制,但语言运行时默认限制每个程序最多创建10000个线程。这个限制值可以通过调用runtime/debug包的SetMaxThreads方法来更改。如果程序试图使用更多的线程,就会崩溃。
一、mac的cpu处理器个数、核数、超线程
查看CPU信息
sysctl machdep.cpu其中
machdep.cpu.xsave.extended_state: 31 832 1088 0machdep.cpu.xsave.extended_state1: 15 832 256 0machdep.cpu.tlb.data.small: 64machdep.cpu.tlb.data.small_level1: 64machdep.cpu.tlb.inst.large: 8machdep.cpu.thermal.ACNT_MCNT: 1machdep.cpu.thermal.core_power_limits: 1machdep.cpu.thermal.dynamic_acceleration: 1machdep.cpu.thermal.energy_policy: 1machdep.cpu.thermal.fine_grain_clock_mod: 1machdep.cpu.thermal.hardware_feedback: 0machdep.cpu.thermal.invariant_APIC_timer: 1machdep.cpu.thermal.package_thermal_intr: 1machdep.cpu.thermal.sensor: 1machdep.cpu.thermal.thresholds: 2machdep.cpu.mwait.extensions: 3machdep.cpu.mwait.linesize_max: 64machdep.cpu.mwait.linesize_min: 64machdep.cpu.mwait.sub_Cstates: 286531872machdep.cpu.cache.L2_associativity: 4machdep.cpu.cache.linesize: 64machdep.cpu.cache.size: 256machdep.cpu.arch_perf.events: 0machdep.cpu.arch_perf.events_number: 7machdep.cpu.arch_perf.fixed_number: 3machdep.cpu.arch_perf.fixed_width: 48machdep.cpu.arch_perf.number: 4machdep.cpu.arch_perf.version: 4machdep.cpu.arch_perf.width: 48machdep.cpu.address_bits.physical: 39machdep.cpu.address_bits.virtual: 48machdep.cpu.tsc_ccc.denominator: 2machdep.cpu.tsc_ccc.numerator: 300machdep.cpu.brand: 0machdep.cpu.brand_string: Intel(R) Core(TM) i9-9900K CPU @ 3.60GHzmachdep.cpu.core_count: 8machdep.cpu.cores_per_package: 8machdep.cpu.extfamily: 0machdep.cpu.extfeature_bits: 1241984796928machdep.cpu.extfeatures: SYSCALL XD 1GBPAGE EM64T LAHF LZCNT PREFETCHW RDTSCP TSCImachdep.cpu.extmodel: 9machdep.cpu.family: 6machdep.cpu.feature_bits: 9221960262849657855machdep.cpu.features: FPU VME DE PSE TSC MSR PAE MCE CX8 APIC SEP MTRR PGE MCA CMOV PAT PSE36 CLFSH DS ACPI MMX FXSR SSE SSE2 SS HTT TM PBE SSE3 PCLMULQDQ DTES64 MON DSCPL VMX SMX EST TM2 SSSE3 FMA CX16 TPR PDCM SSE4.1 SSE4.2 x2APIC MOVBE POPCNT AES PCID XSAVE OSXSAVE SEGLIM64 TSCTMR AVX1.0 RDRAND F16Cmachdep.cpu.leaf7_feature_bits: 43804591 1073741824machdep.cpu.leaf7_feature_bits_edx: 3154118144machdep.cpu.leaf7_features: RDWRFSGS TSC_THREAD_OFFSET SGX BMI1 AVX2 SMEP BMI2 ERMS INVPCID FPU_CSDS MPX RDSEED ADX SMAP CLFSOPT IPT SGXLC MDCLEAR IBRS STIBP L1DF ACAPMSR SSBDmachdep.cpu.logical_per_package: 16machdep.cpu.max_basic: 22machdep.cpu.max_ext: 2147483656machdep.cpu.microcode_version: 234machdep.cpu.model: 158machdep.cpu.processor_flag: 1machdep.cpu.signature: 591597machdep.cpu.stepping: 13machdep.cpu.thread_count: 16machdep.cpu.vendor: GenuineIntel
machdep.cpu.core_count核数为8machdep.cpu.thread_count cpu数量为16,使用了超线程技术。
二、进程、线程和协程
进程
当运行一个应用程序的时候,操作系统会为这个应用程序启动一个进程。可以将这个进程看作一个包含了应用程序在运行中需要用到和维护的各种资源的容器。这些资源包括但不限于内存地址空间、文件和设备的句柄以及线程。
线程
一个线程是一个执行空间,这个空间会被操作系统调度来运行函数中所写的代码。每个进程至少包含一个线程,每个进程的初始线程被称作主线程。因为执行这个线程的空间是应用程序的本身的空间,所以当主线程终止时,应用程序也会终止。操作系统将线程调度到某个处理器上运行,这个处理器并不一定是进程所在的处理器。下图展示了一个运行中的应用程序的进程和线程视图:
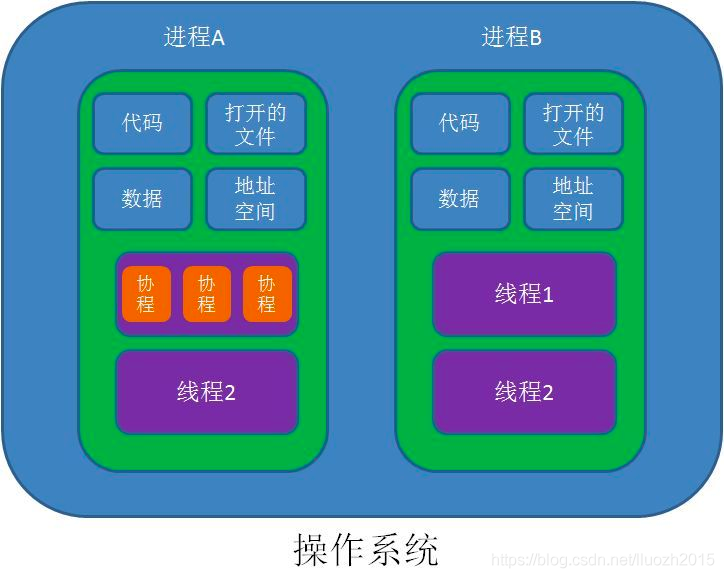
https://github.com/golang/go/blob/master/src/runtime/runtime2.go
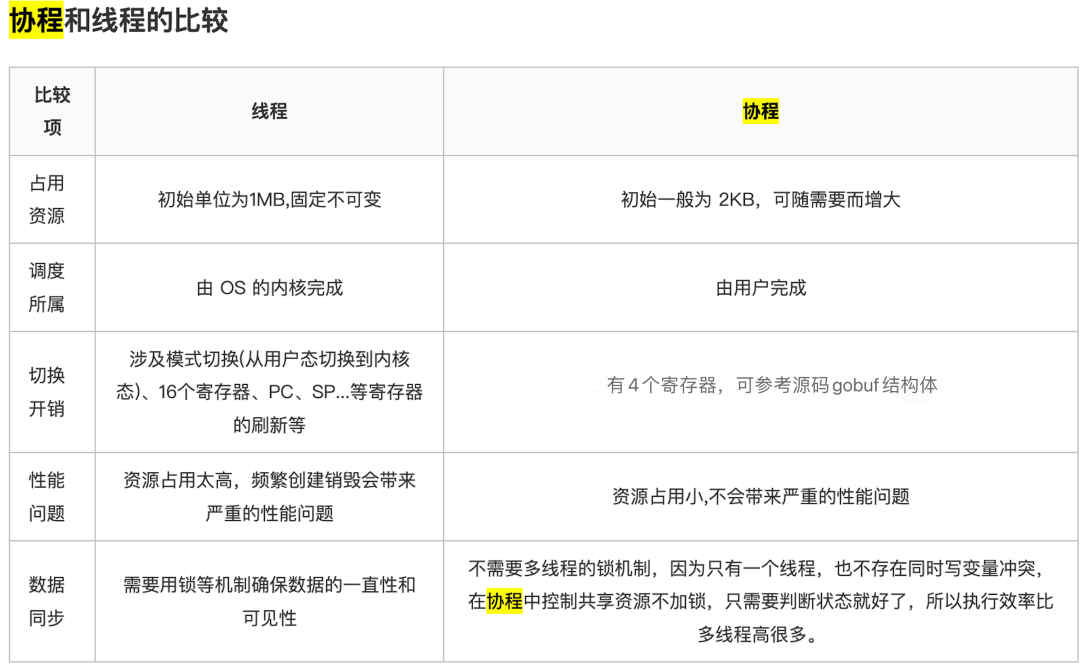
type gobuf struct {// The offsets of sp, pc, and g are known to (hard-coded in) libmach.//// ctxt is unusual with respect to GC: it may be a// heap-allocated funcval, so GC needs to track it, but it// needs to be set and cleared from assembly, where it's// difficult to have write barriers. However, ctxt is really a// saved, live register, and we only ever exchange it between// the real register and the gobuf. Hence, we treat it as a// root during stack scanning, which means assembly that saves// and restores it doesn't need write barriers. It's still// typed as a pointer so that any other writes from Go get// write barriers.sp uintptrpc uintptrg guintptrctxt unsafe.Pointerret uintptrlr uintptrbp uintptr // for framepointer-enabled architectures}
与栈相关的SP和BP寄存器
PC寄存器
用于保存函数闭包的上下文信息,也就是DX寄存器
上述的说的go的4个寄存器是基于我的CPU查看的。具体几个要看CPU型号,寄存器是和CPU强关联的实现,具体可参考:
https://github.com/golang/go/tree/master/src/runtime1
三、逻辑处理器与本地运行队列
(一)逻辑处理器
Golang的运行时会在逻辑处理器上调度goroutine来运行。每个逻辑处理器都与一个操作系统线程绑定。在Golang 1.5及以后的版本中,运行时默认会为每个可用的物理处理器分配一个逻辑处理器。
(二)本地运行队列
每个逻辑处理器有一个本地运行队列。如果创建一个goroutine并准备运行,这个goroutine首先会被放到调度器的全局运行队列中。之后,调度器会将全局运行队列中的goroutine分配给一个逻辑处理器,并放到这个逻辑处理器的本地运行队列中。本地运行队列中的goroutine会一直等待直到被分配的逻辑处理器执行。下图展示了操作系统线程、逻辑处理器和本地运行队列之间的关系:
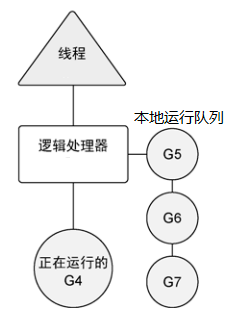
有时,正在运行的goroutine需要执行一个阻塞的系统调用,如打开一个文件。当这类调用发生时,线程和goroutine会从逻辑处理器上分离,该线程会继续阻塞,等待系统调用的返回。与此同时,这个逻辑处理器就失去了用来运行的线程。所以,调度器会创建一个新线程,并将其绑定到该逻辑处理器上。之后,调度器会从本地运行队列里选择另一个goroutine来运行。一旦被阻塞的系统调用执行完成并返回,对应的goroutine会放回到本地运行队列,而之前的线程会保存好,以便之后可以继续使用。
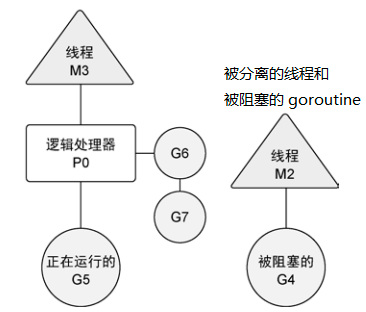
如果一个goroutine需要做一个网络I/O调用,流程上会有些不一样。在这种情况下,goroutine会和逻辑处理器分离,并移到集成了网络轮询器的运行时。一旦该轮询器指示某个网络读或者写操作已经就绪,对应的goroutine 就会重新分配到逻辑处理器上来完成操作。
注意:Golang运行时默认限制每个程序最多创建10000个线程。这个限制值可以通过调用runtime/debug包的SetMaxThreads方法来更改。如果程序试图使用更多的线程,就会崩溃。
四、并发与并行
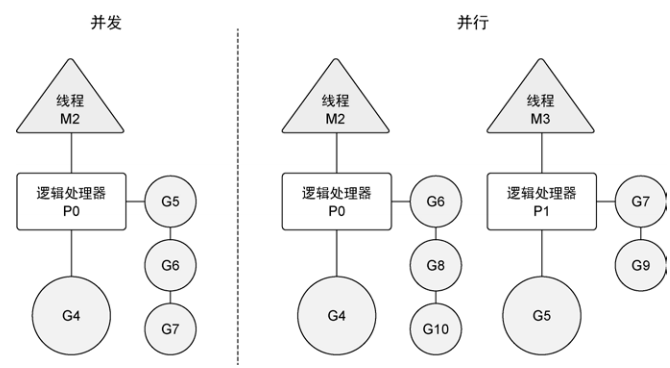
并发(concurrency)与并行(parallelism)不同。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了(Golang的并发通过切换多个线程达到减少物理处理器空闲等待的目的)。在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。这种“使用较少的资源做更多的事情”的哲学,也是指导Golang设计的哲学。如果希望让goroutine并行,必须使用多于一个逻辑处理器。当有多个逻辑处理器时,调度器会将goroutine平等分配到每个逻辑处理器上。这会让goroutine在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕Golang运行时使用多个线程,goroutine依然会在同一个物理处理器上并发运行,达不到并行的效果。下图展示了在一个逻辑处理器上并发运行goroutine和在两个逻辑处理器上并行运行两个并发的goroutine之间的区别:
五、一个进程最多能创建多少个线程?
在Linux操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常⻅的32位和64位系统,如下所示:
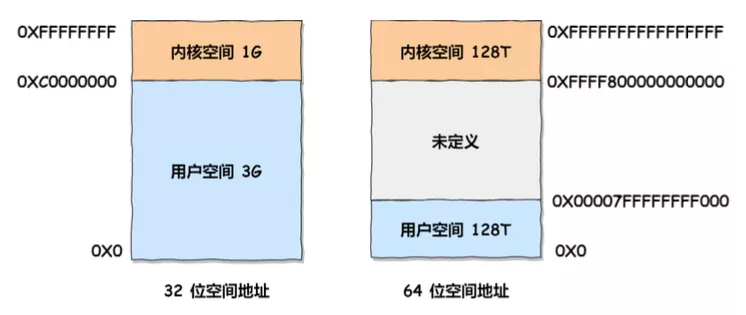
通过这里可以看出:
32位系统的内核空间占用1G,位于最高处,剩下的3G是用户空间。
64位系统的内核空间和用户空间都是128T ,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
在前面我们知道,在32位Linux系统里,一个进程的虚拟空间是4G,内核分走了1G,留给用户用的只有3G。那么假设创建一个线程需要占用10M虚拟内存,总共有3G虚拟内存可以使用。于是我们可以算出,最多可以创建差不多300个(3G/10M)左右的线程。
如果想使得进程创建上千个线程,那么我们可以调整创建线程时分配的栈空间大小,比如调整为512k:
ulimit -s 512简单总结下:
32位系统,用户态的虚拟空间只有3G,如果创建线程时分配的栈空间是10M,那么一个进程最多只能创建300个左右的线程。
64位系统,用户态的虚拟空间大到有128T,理论上不会受虚拟内存大小的限制,而会受系统的参数或性能限制。
六、基本用法
runtime调度器是个非常有用的东西,关于runtime包几个方法:
Gosched:让当前线程让出cpu以让其它线程运行,它不会挂起当前线程,因此当前线程未来会继续执行。
NumCPU:返回当前系统的CPU核数量。
GOMAXPROCS:设置最大的可同时使用的CPU核数。
Goexit:退出当前goroutine (但是defer语句会照常执行)
NumGoroutine:返回正在执行和排队的任务总数。
GOOS:目标操作系统。
七、等待goroutine完成任务
创建一个WaitGroup实例,比如名称为:wg
调用wg.Add(n),其中n是等待的goroutine的数量
在每个goroutine 运行的函数中执行defer wg.Done()
调用wg.Wait()阻塞主逻辑
package mainimport ("time""fmt""sync")func main() {var wg sync.WaitGroupwg.Add(2)say2("hello", &wg)say2("world", &wg)fmt.Println("over!")}func say2(s string, waitGroup *sync.WaitGroup) {defer waitGroup.Done()for i := 0; i < 3; i++ {fmt.Println(s)}}
输出
hellohellohelloworldworldworldover!
八、锁
(一)原子锁
对于一个整数类型T,sync/atomic标准库包提供了下列原子操作函数。其中T可以是内置int32、int64、uint32、uint64和uintptr类型
func AddT(addr *T, delta T)(new T)func LoadT(addr *T) (val T)func StoreT(addr *T, val T)func SwapT(addr *T, new T) (old T)func CompareAndSwapT(addr *T, old, new T) (swapped bool)
sync/atomic标准库包也提供了一个Value类型。以它为基的指针类型*Value拥有两个方法:Load和Store。Value值用来原子读取和修改任何类型的Go值。
func (v *Value) Load() (x interface{})func (v *Value) Store(x interface{})
注意点1
一旦v.Store方法( (v).Store的简写形式)被曾经调用一次,则传递给值v的后续方法调用的实参的具体类型必须和传递给它的第一次调用的实参的具体类型一致;否则,将产生一个恐慌。nil接口类型实参也将导致v.Store()方法调用产生恐慌。比如:
package mainimport ("fmt""sync/atomic")func main() {type T struct{ a, b, c int }var ta = T{1, 2, 3}var v atomic.Valuev.Store(ta)var tb = v.Load().(T)fmt.Println(tb) // {1 2 3}fmt.Println(ta == tb) // truev.Store("hello") // 将导致一个恐慌}
输出结果:
goroutine 1 [running]:sync/atomic.(*Value).Store(0x14000110210, {0x102f47900, 0x102f58038})/opt/homebrew/Cellar/go@1.17/1.17.10/libexec/src/sync/atomic/value.go:77 +0xf4main.main()/Users/tomxiang/github/go-demo/hello/routine/routine07.go:17 +0x218Process finished with the exit code 2
注意点2
一个CompareAndSwapT函数调用传递的旧值和目标值的当前值匹配的情况下才会将目标值改为新值,并返回true;否则立即返回false 。
import ("fmt""sync/atomic")func main() {type T struct{ a, b, c int }var x = T{1, 2, 3}var y = T{4, 5, 6}var z = T{7, 8, 9}var v atomic.Valuev.Store(x)fmt.Println(v) // {{1 2 3}}old := v.Swap(y)fmt.Println("old:", old)fmt.Println("v:", v) // {{4 5 6}}fmt.Println("old.(T)", old.(T)) // {1 2 3}swapped := v.CompareAndSwap(x, z)fmt.Println(swapped, v) // false {{4 5 6}}swapped = v.CompareAndSwap(y, z)fmt.Println(swapped, v) // true {{7 8 9}}}
输出结果:
2 3}}old: {1 2 3}v: {{4 5 6}}{1 2 3}false {{4 5 6}}true {{7 8 9}}
(二)互斥锁
例:Gosched切换任务
mutex.Lock
// Package main 这个示例程序展示如何使用互斥锁来// 定义一段需要同步访问的代码临界区// 资源的同步访问package mainimport ("fmt""runtime""sync")var (// counter是所有goroutine都要增加其值的变量counter int// wg用来等待程序结束wg sync.WaitGroup// mutex 用来定义一段代码临界区mutex sync.Mutex)// main 是所有Go程序的入口func main() {// 计数加2,表示要等待两个goroutinewg.Add(2)// 创建两个goroutinego incCounter(1)go incCounter(2)// 等待goroutine结束wg.Wait()fmt.Printf("Final Counter: %d\n", counter)}// incCounter 使用互斥锁来同步并保证安全访问,// 增加包里counter变量的值func incCounter(id int) {// 在函数退出时调用Done来通知main函数工作已经完成defer wg.Done()for count := 0; count < 2; count++ {// 同一时刻只允许一个goroutine进入// 这个临界区mutex.Lock(){ // 使用大括号只是为了让临界区看起来更清晰,并不是必需的。// 捕获counter的值value := counter// 当前goroutine从线程退出,并放回到队列runtime.Gosched()// 增加本地value变量的值value++// 将该值保存回countercounter = value}mutex.Unlock()// 释放锁,允许其他正在等待的goroutine// 进入临界区}}
输出结果:
4对counter变量的操作在第46行和第60行的Lock()和Unlock()函数调用定义的临界区里被保护起来。同一时刻只有一个goroutine可以进入临界区。之后,直到调用Unlock()函数之后,其他goroutine才能进入临界区。当第52行强制将当前goroutine退出当前线程后,调度器会再次分配这个goroutine继续运行。当程序结束时,我们得到正确的值4,竞争状态不再存在。
例2
在一个goroutine获得Mutex后,其他goroutine只能等到这个goroutine释放该Mutex。
使用Lock()加锁后,不能再继续对其加锁,直到利用Unlock()解锁后才能再加锁。
在Lock()之前使用Unlock()会导致panic异常。
已经锁定的Mutex并不与特定的goroutine相关联,这样可以利用一个goroutine对其加锁,再利用其他goroutine对其解锁。
在同一个goroutine中的Mutex解锁之前再次进行加锁,会导致死锁。
适用于读写不确定,并且只有一个读或者写的场景。
参考资料:
1.Golang入门 : 理解并发与并行
2.浅谈内存管理单元(MMU)
3.一个进程最多能创建多少个线程?
4.Golang入门: 等待goroutine完成任务
5.Golang中runtime的使用
6.sync/atomic标准库包中提供的原子操作
7.Go学习笔记(23)— 并发(02)[竞争,锁资源,原子函数sync/atomic、互斥锁sync.Mutex]
8.Go标准库——sync.Mutex互斥锁
9.寄存器数目
作者简介

向晨宇
腾讯专家工程师
腾讯专家工程师,目前负责腾讯医药和腾讯健康药箱的两款应用程序的开发工作。座右铭: 热爱编程,追求完美,个性执着。
推荐阅读

温馨提示:因公众号平台更改了推送规则,公众号推送的文章文末需要点一下“赞”和“在看”,新的文章才会第一时间出现在你的订阅列表里噢~

