
海外金融风控算法实践(Python)
一、海外信贷现状简介
自国内金融P2P暴雷,国内很多小贷机构便涌入了东南亚、非洲等未开拓的市场,像印尼、印度、菲律宾、泰国、越南、尼日利亚等国家。
分析这些东南亚/非洲国家的市场特点,有低金融包容性(2017年越南有30.8%的人拥有银行账户),对金融的高需求(2017年借贷的人口比例49.0%)和互联网普及率(2018年为66%)和移动连通性,为东南亚金融科技贷款的发展提供了最有利的条件,开启了野蛮生长的模式。
结合这些地域的贷款市场情况,通常征信体系建设及经济情况都比较差,且大部分的用户资质比较差(也并不满足银行的贷款资格)。种种因素下,机构对于放贷用户的信用/欺诈风险的掌握是比较差的,小贷机构坏账率普遍地高(如一些机构的新借贷用户坏账率可达 20~30%,而银行坏账通常在10%左右)。
在东南亚开展的小额贷款产品,普遍是714高炮(贷款周期7-14天,收取高额逾期费用或放贷时提前从本金中扣除利息-砍头息,有的实际年化利率竟达到300%)。
高利率必然带着高风险,这种业务也很容易受到金融监管政策的封杀。
二、小贷风控体系介绍
这么高的坏账情况,如果小贷机构在对借贷用户信用情况的掌握不足,即使高利率也未必覆盖这么高的信用风险。
可见,风控能力是小贷业务控制损失的核心,风控体系通常由 反欺诈(证件信息核实、人脸识别验证、黑名单)+ 申请评分模型组成。
风控好坏关键在于数据获取及积累。一个明显差异体现在于,机构新借贷的用户坏账率是20~30%(里面骗贷欺诈的比重应该挺高),而对于在机构内复贷的老用户(之前有借贷的再重复贷款的用户)坏账率仅有4%。
也就是,对于机构有掌握借贷历史的用户,其坏账率是显著较低的!信贷风控能力的差异其实也就是数据垄断优势的体现! 对于小贷机构,营销扩展新用户后,如何应用风控模型尽量准确地评估新用户,并给予较低的额度,当其有较好的信贷历史后再提高额度,好好维持及扩充这部分复贷用户就是业务盈利的关键。
海外的小贷机构申请评分模型的数据主要来源有:
机构历史借贷记录:如使用同一手机号申请贷款次数、逾期次数。在征信体系建设覆盖不完全的情况下,在机构内(或联合机构)的借贷历史往往也是最有说服力及有效的。 客户基本资料:如身份信息、联系方式、职业、收入、借款用途等信息。由于线上申请这些数据往往没有人工审核,信息的可靠性是存疑的,通常可以借助多方数据来核验这些是不是一致及可靠的。 征信机构的征信报告:全球三大商业个人征信巨头分别为益百利(Experian)、艾克发(Equifax)和环联(Trans union),可以提供贷款申请次数、贷款额度、信用账户数等信息。但不足的地方在于,对于征信体系建设不完善的地区,覆盖度、信息记录会比较差(本项目验证的Experian实际覆盖度80%左右)。 手机短信:短信可以提供很多有价值的信息,如话费欠费、银行卡收入支出、联系人数量、日常闲聊短信、机构催收短信、信贷广告数量。可以通过简单关键字匹配、词袋模型等方法抽取关键特征,进一步还可以通过短信分类、信息抽取(实体抽取)等方法统计催收短信数量、欠款金额、收入支出金额等数据(注:获取短信数据肯定是不合规的,对于机构只想要更多的数据保证,而对于用户急着用钱哪还管什么隐私数据。当前,有些APP已被禁止获取短信、通话记录,这也是要随着监管不断完善。) 手机通讯录:可用于统计关联的联系人的逾期次数等特征,以及其他的一些社交信息; APP数据:可统计安装信贷类APP、社交类APP的数量,以及app使用率; 登录IP、GPS、设备号信息:可以用于关联特征,如同一IP下逾期次数,以及建立IP、设备黑名单; 银行对账单数据:如工资流水等信息,可以比较有效体现用户还款能力。
三、申请评分模型实践
3.1 征信特征加工
本项目基于东南亚某国近期的500笔的小额贷款交易(数据源于网络,侵删),获取相应Experian征信报告数据,并用Python加工出滑动窗口的征信特征:如近30天的贷款次数,贷款平均额度、最近贷款日期间隔、历史逾期次数等特征,通过LightGBM构建申请评分模型。
(本项目建模较为简化,更为完整的评分卡建模全流程可以参考之前文章:一文梳理金融风控建模全流程(Python)) Experian征信报告原始报文包含了个人基本信息、近期贷款信息、信用卡、贷款等历史表现等信息。如下代码滑动时间窗口,提取相应的特征。
Experian征信报告原始报文包含了个人基本信息、近期贷款信息、信用卡、贷款等历史表现等信息。如下代码滑动时间窗口,提取相应的特征。
# 完整代码请关注公众号“算法进阶”或访问https://github.com/aialgorithm/Blog
def add_fea_grids(fea_dict, mult_datas, apply_dt='20200101', dt_key='Open_Date', calc_key="data['Amount_Past_Due']",groupfun=['count','sum', 'median','mean','max','min','std'], dt_grids=[7, 30,60,360,9999]):
"""
征信报告使用滑动时间窗口-近N天,加工字段A的 计数、平均、求和等特征.
fea_dict:最终特征存储的字典
mult_datas:多条的记录值
calc_key:数据特征字段的相对位置
"""
new_fea = {} # 记录各时间窗口的原始特征
for _dt in dt_grids:
new_fea.setdefault(_dt, [])# 按时间窗口初始化
fea_suffix = calc_key.split("'")[-2] + str(len(calc_key)) # 前缀备注
if mult_datas:
mult_datas = con_list(mult_datas)
for data in mult_datas:
if len(data[dt_key]) >=4 and data[dt_key] < apply_dt: #筛选申请日期前的记录,报告应该为准实时调用的
for _dt in dt_grids:
if (_dt==9999) or (ddt.datetime.strptime(str(data[dt_key]),"%Y%m%d") >= (ddt.datetime.strptime(str(apply_dt),"%Y%m%d") + ddt.timedelta(days=-_dt))) :# 筛选为近N天的记录,为9999则不做筛选
if "Date" in calc_key or "Year" in calc_key : #判断是否为日期型,日期直接计算为时间间隔
fea_value = diff_date(apply_dt, eval(calc_key) )
elif "mean" in groupfun: # 判断是否为数值型,直接提取到相应的时间窗
fea_value = to_float_ornan(eval(calc_key))
else:# 其他按字符型处理
fea_value = eval(calc_key)
new_fea[_dt].append(fea_value) # { 30: [2767.0, 0.0]}
for _k, data_list in new_fea.items(): # 生成具体特征
for fun in groupfun:
fea_name = fea_suffix+ '_'+ fun + '_' +str(_k)
fea_dict.setdefault(fea_name, [])
if len(data_list) > 0:
final_value = fun_dict[fun](data_list)
else :
final_value = np.nan
fea_dict[fea_name].append(final_value)

3.2 特征选择
考虑征信报告的隐私性,本项目仅提供一份报告示例做特征加工。特征加工后特征选择,关联逾期标签,形成如下最终数据特征宽表。
df2 = pd.read_pickle('filter_feas_df.pkl')
print(df2.label.value_counts()) # 逾期标签为label==0
df2.head()

3.3 模型训练
train_x, test_x, train_y, test_y = train_test_split(df2.drop('label',axis=1),df2.label,random_state=1)
lgb = lightgbm.LGBMClassifier()
lgb.fit(train_x, train_y,
eval_set=[(test_x,test_y)],
eval_metric='auc',
early_stopping_rounds=50,
verbose=-1)
print('train ',model_metrics2(lgb,train_x, train_y))
print('test ',model_metrics2(lgb,test_x,test_y))
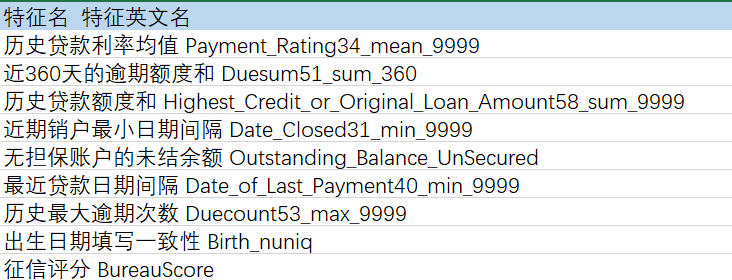
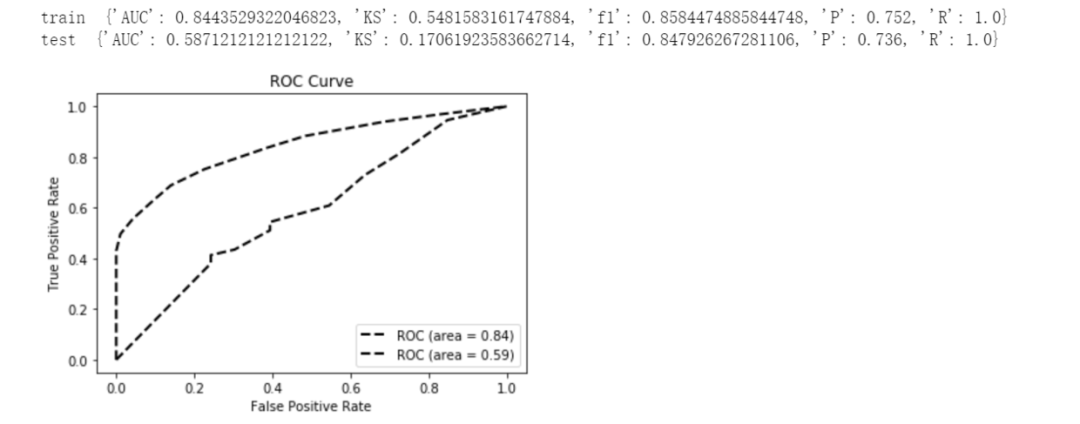 仅用征信报告数据的特征,可见对于逾期用户的识别效果很一般,Test AUC仅60%左右(后续还是得寄望于加入些短信类、历史借贷类等数据)。综合分析模型重要的特征,主要为:
仅用征信报告数据的特征,可见对于逾期用户的识别效果很一般,Test AUC仅60%左右(后续还是得寄望于加入些短信类、历史借贷类等数据)。综合分析模型重要的特征,主要为:
本团队可承接金融风控建模的项目,有合作需求可以联系微信号“Ai_Algorithms”
- END -参考链接:http://www.xinhuanet.com/fortune/2020-11/27/c_1126793844.htm https://www.163.com/dy/article/H84VU3OR051196HN.html https://zhuanlan.zhihu.com/p/88820665