 云加社区
云加社区





导语 | 在需要高性能、节省资源的场景下,比如海量的连接、很高的并发,我们发现Go开始变得吃力,不但内存开销大,而且还会有频繁的goroutine调度。GC时间也变得越来越长,甚至还会把系统搞挂。这时,我们就可以考虑用Go构建经典的Reactor网络模型,来应对这种场景。
一、常见的服务端网络编程模型
在具体讲Reactor网络库的实现前,我们先快速回顾下常见的服务端网络编程模型。
服务端网络编程主要解决两个问题,一个是服务端如何管理连接,特别是海量连接、高并发连接(经典的c10k/c100k问题),二是服务端如何处理请求(高并发时正常响应)。
针对这两个问题,有三种解决方案,分别对应三种模型:
传统IO阻塞模型。
Reactor模型。
Proactor模型。
下面两图分别是传统IO阻塞模型和Reactor模型,传统IO阻塞模型的特点是每条连接都是由单独的线/进程管理,业务逻辑(crud)跟数据处理(网络连接上的read和write)都在该线/进程完成。缺点很明显,并发大时,需要创建大量的线/进程,系统资源开销大;连接建立后,如果当前线/进程暂时还没数据可读,会阻塞在Read调用上,浪费系统资源。
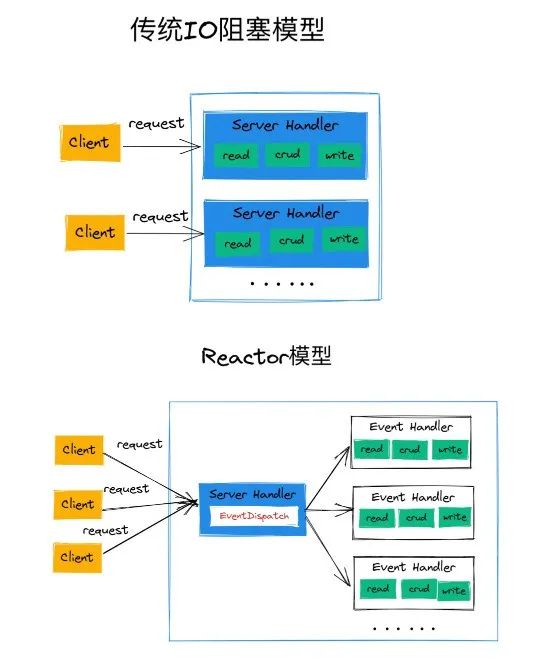
Reactor模型就是传统IO阻塞模型的改进,Reactor会起单独的线/进程去监听和分发事件,分发给其他EventHandlers处理数据读写和业务逻辑。这样,与传统IO阻塞模型不同的是,Reactor的连接都先到一个EventDispatcher上,一个核心的事件分发器,同时Reactor会使用IO多路复用在事件分发器上非阻塞地处理多个连接。
这个EventDispatcher跟后面的EventHandlers可以都在一个线/进程,也可以分开,下文会有区分。整体来看,Reactor就是一种事件分发机制,所以Reactor也被称为事件驱动模型。简而言之,Reactor=IO多路复用(I/O multiplexing)+非阻塞IO(non-blocking I/O)。
(一)Reactor模型的三种实现
根据Reactor的数量和业务线程的工作安排有3种典型实现:
单Reactor多线程
单Reactor多线程带线程池
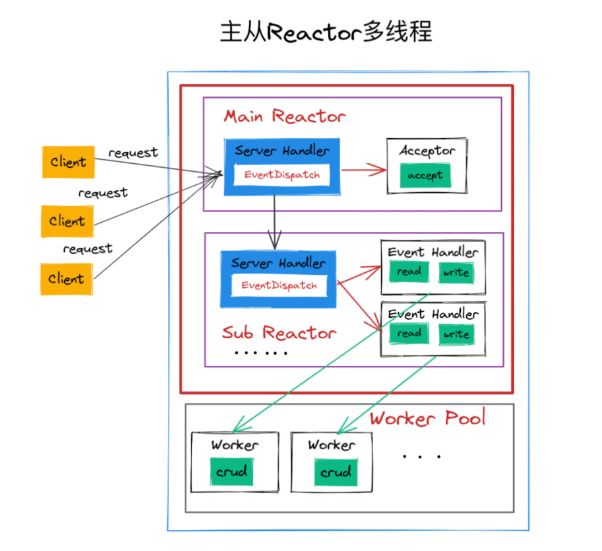
主从Reactor多线程(带线程池)
先看两个单Reactor:
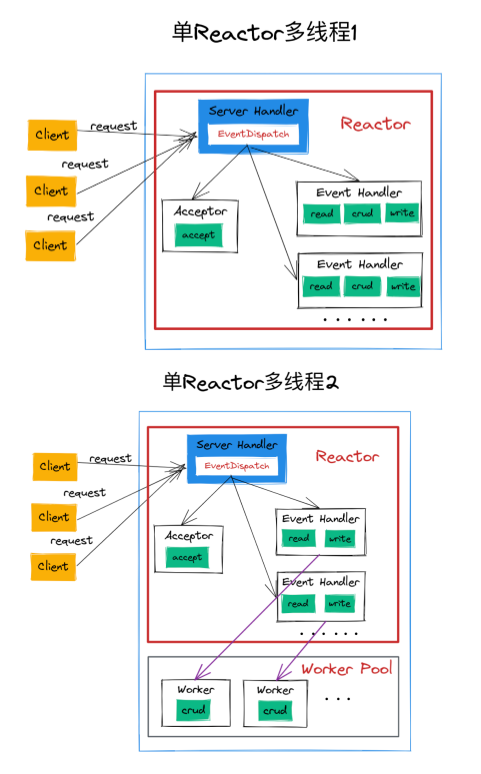
一个Reactor接管所有的事件安排,如果是建立连接事件,就交给Acceptor处理,接着创建对应的Handler处理该连接后续的读写事件。如果不是建立连接事件,就调用连接对应的Event Handler来响应。单Reator1和2的区别是2带了个线程池,一定程度上解放Event Handler线程,让Handler专注数据读写处理,特别是在遇到一些笨重、高耗时的业务逻辑时。
再来看多Reactor,这个是本文的主角,第三节内容就是怎么实现它。多Reactor就是主从多Reactor,它的特点是多个Reactor在多个单独的线/进程中运行,MainReactor负责处理建立连接事件,交给它的Acceptor处理,处理完了,它再分配连接给SubReactor;SubReactor则处理这个连接后续的读写事件,SubReactor自己调用EventHandlers做事情。
这种实现看起来职责就很明确,可以方便通过增加SubReactor数量来充分利用CPU资源,也是当前主流的服务端网络编程模型。
(二)Proactor模型自带主角光环
尽管本文的主角是主从多Reactor,但如果Proactor要当主角,就没Reactor什么事。
Proactor模型跟Reactor模型的本质区别是异步I/O和同步I/O的区别,即底层I/O实现。
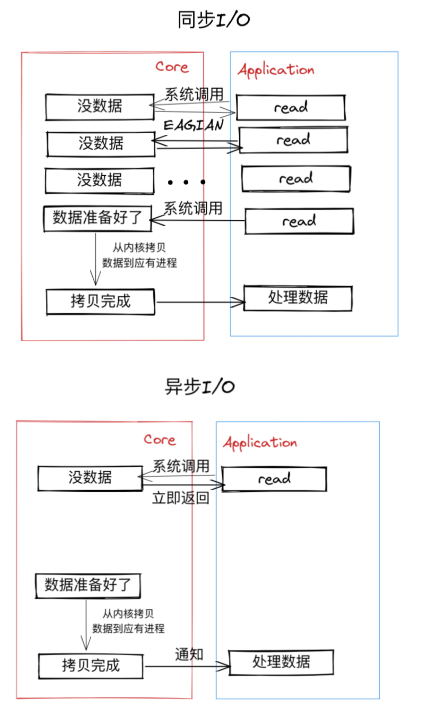
从上面两张图可以看出,Reactor模型依赖的同步I/O需要不断检查事件发生,然后拷贝数据处理,而Proactor模型使用的异步I/O只需等待系统通知,直接处理内核拷贝过来的数据,孰优孰劣,一言便知。
基于异步I/O的Proactor模型实现如下图:
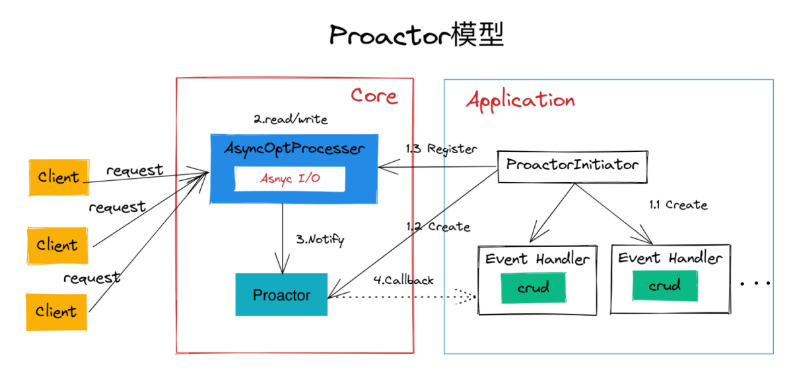
那为什么主角光环如此明显的Proactor不是当前主流的服务端网络编程模型呢?
原因是在Linux下的AIO API--io_uring还没有像同步I/O那样能够覆盖和支持很多场景,即还没成熟到被广泛使用。
二、Go原生网络模型简介
关于Go原生网络模型的实现,网上已经有很多文章,这里就不过多展开,读者可以结合下图追踪整个代码流程:
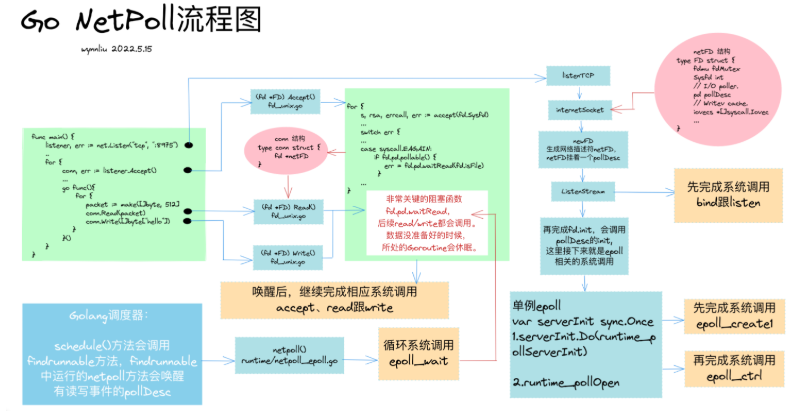
总结来说,Go所有的网络操作围绕网络描述符netFD展开,netFD与底层pollDesc结构绑定,当在一个netFD上读写遇到EAGAIN错误时,就将当前goroutine存储到绑定的pollDesc中,同时将goroutine给park住,直到这个netFD上的数据准备好,再唤醒goroutine完成数据读写。
再总结来说,Go原生网络模型就是个单Reactor多协程模型。
三、如何从0到1实现异步网络库
我们现在回顾了常见的服务端网络编程模型,也知道Go处理连接的方式是一个连接给分配一个协程处理,即goroutine-per-conn模式。
那本节就到了我们的重点,怎么去实现一个异步网络库(因为Reactor模型的实现,一般是主线程accept一个连接后,分给其他的线/进程异步处理后续的业务逻辑和数据读写,所以一般Reactor模型的网络库被称为异步网络库,并不是使用异步I/O的API)。
在具体实现之前,笔者先介绍下需求背景。
(一)需求背景
Go的协程非常轻量,大部分场景下,基于Go原生网络库构建的应用都不会有什么性能瓶颈,资源占用也很可观。
我们现在使用的网关是基于C++自研的一款网关,我们想统一技术栈,换成Go的,我们现在峰值会在百万连接上下,大概用了几十台机器,单机能稳定支撑几十万的连接。如果换成Go的话,我们一直疑惑,基于Go实现的网关单机能撑多少,内存跟CPU怎么样?能不能省点机器?
于是,笔者开始针对这种有大量连接的场景对Go做了一波压测,得出的结论也显而易见:随着连接数上升,Go的协程数也随之线性上升,内存开销增大,GC时间占比增加。当连接数到达一定数值时,Go的强制GC还会把进程搞挂,服务不可用。(下文会有网络库的对比压测数据)
接着,笔者翻阅内外网有同样场景的解决方案,基本都是往经典Reactor模型实现上做文章。比如最早的A Million WebSockets and Go,作者Sergey Kamardin使用epoll的方式代替goroutine-per-conn模式,百万连接场景下用少量的goroutine去代替一百万的goroutine。
A Million WebSockets and Go:
https://www.freecodecamp.org/news/million-websockets-and-go-cc58418460bb/
Sergey Kamardin的方案总结:
Let’s structure the optimizations I told you about.
A read goroutine with a buffer inside is expensive. Solution: netpoll (epoll, kqueue); reuse the buffers.
A write goroutine with a buffer inside is expensive. Solution: start the goroutine when necessary; reuse the buffers.
With a storm of connections, netpoll won’t work. Solution: reuse the goroutines with the limit on their number.
net/http is not the fastest way to handle Upgrade to WebSocket. Solution: use the zero-copy upgrade on bare TCP connection.
又比如字节基于Reactor网络库netpoll开发了RPC框架Kitex来应对高并发场景。
笔者简单用Go实现了一个网关,使用这些Reactor网络库再进行了一波压测,结果符合预期:连接数上去后的Go网关确实比之前的稳定,内存占用也很可观。但最终都没有选用这些开源Reactor库,原因是这些开源库都不是开箱即用,都没有实现HTTP/1.x、TLS等常见协议;API设计不够灵活且专注的场景并不适合网关,比如netpoll目前主要专注于RPC场景(字节上周才正式对外开源HTTP框架Hertz);整体改造成本高,难以适配运用到Go网关中。
Netpoll的场景说明:
另一方面,开源社区目前缺少专注于RPC方案的Go网络库。类似的项目如:evio,gnet等,均面向Redis,HAProxy这样的场景。
(二)总体分层设计
终于到了实现部分,我们先看一个Reactor库的总体分层设计,总体分为三层:应用层、连接层和基础层。
应用层就是常见的EchoServer、HTTPServer、TLSServer和GRPCServer等等,主要负责协议解析、执行业务逻辑,对应Reactor模型里边的EventHandler。
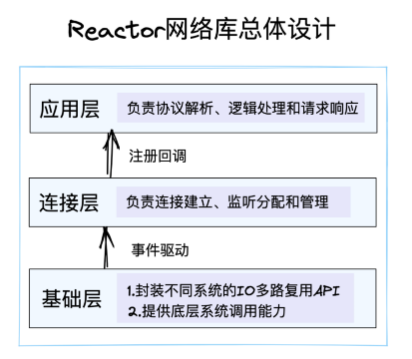
在Reactor模型中,应用层会实现事件处理的接口,等待连接层调用。
// Handler Core 注册接口type Handler interface {OnOpen(c *Conn) // happen on accept connOnClose(c *Conn, err error) // happen ob delete connOnData(c *Conn, data []byte) // happen on epoll waitOnStop()}
比如当连接建立后,可以调用OnOpen函数做些初始化逻辑,当连接上有新数据到来,可以调用OnData函数完成具体的协议解析和业务逻辑。
(三)连接层设计
连接层就是整个Reactor模型的核心,根据上文的主从Reactor多线程模型,连接层主要有两种Reactor,一主(Main Reactor)多从(Sub Reactor),也可以多主多从。
Main Reactor主要负责监听和接收连接,接着分配连接,它里边有个for循环,不断去accept新连接,这里的方法可以叫做acceptorLoop;Sub Reactor拿到Main Reactor分配的连接,它也是个for循环,一直等待着读写事件到来,然后干活,即回调应用层执行具体业务逻辑,它的方法可以叫做readWriteLoop。
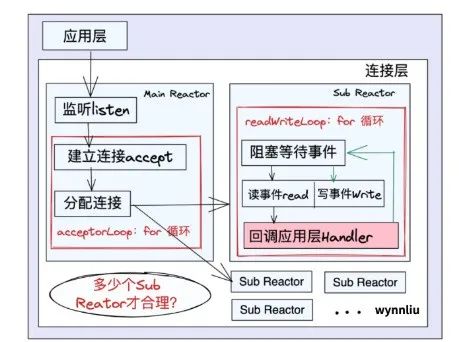
根据连接层的工作安排,可以发现我们需要以下三个数据结构:
EventLoop:事件循环,即Reactor,用isMain区分主从,如果是Sub Reactor,每个SubReactor上挂着很多Conn。
Poller:Sub Reactor的里的readWriteLoop需要不断处理读写事件,这些事件在不同系统下由不同的I/O API监听和通知,在Linux系统下就是经典的Epoll三组函数,在Unix系统下(比如Mac)就是Kqueue。
Conn:Main Reactor的listener accept之后建立的连接,与一个文件描述符fd绑定。
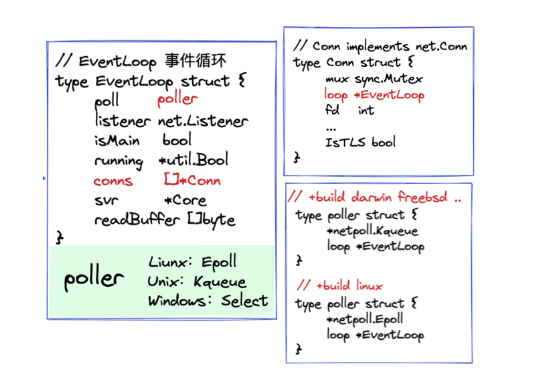
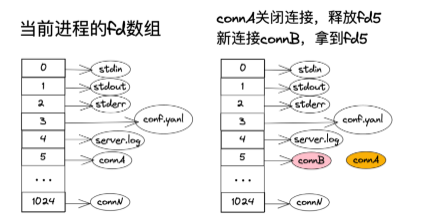
值得注意的fd竞态
每个连接都会与一个fd绑定,当某个连接关闭后,它会释放掉fd,供新连接绑定,这也叫fd的复用。
通常我们的应用层会在一个协程池中执行它的业务逻辑,在连接层有个Sub Reactor在处理这个连接上的读写事件。
如果在应用层那边关闭了连接,而在Sub Reactor那边刚好在准备读这个连接上的数据,即操作这个fd。
当Sub Reactor还没来得及读,但被应用层关闭释放掉的fd,已经给到了一个新连接,这时Sub Reactor继续读这个fd上的数据,就会把新连接的数据读走。
因此,我们需要针对fd的操作前后加个锁,即在关闭连接跟在连接上读写前先上锁,关闭后才释放掉锁,并且在连接上读写前判断连接是否关闭,这样才会避免脏数据。

不可忽略的负载均衡
除了注意fd复用带来的竞态,还有一个不可忽略的负载均衡,在Main Reactor分配连接到Sub Reactor这个环节。
未来避免某个Sub Reactor过载,我们可以参考Nginx的负载均衡策略,大概有以下三种方式:
轮询调度(Round-Robin Scheduling):轮询Sub Reactors,逐个分配。
Fd哈希:c.fd%len(s.workLoops),以fd值哈希整个Sub Reactors数量。
最小连接数(Least Connections):优先分配给连接数最小的sub reactor。
(四)基础层设计
Reactor的核心的活都在连接层干完了,基础层的作用是提供底层系统调用支持及做好内存管理。
系统调用就是常见的listen/accept/read/write/epoll_create/epoll_ctl/epoll_wait等,这里不展开。但内存管理的方式会极大地影响网络库的性能。
笔者曾经在处理连接上读事件的时候,先是用动态内存池的方式提供临时Buffer承接,对比使用固定Buffer去承接,前者需要一借一还,在某个简单Echo场景下压测,后者较前者提升了12wQPS,恐怖如斯。
以下是常见的内存管理方案,针对连接上读写处理时的内存使用优劣对比:
固定数组
每次读都申请固定大小的buffer。
好处是实现简单,坏处是会积累临时对象。
RingBuffer
读写分离,节省内存,但频繁扩容有性能损耗(扩容时需要搬迁老数据到新RingBuffer上)
LinkBuffer
读写分离,节省内存
池化Block节点,方便扩容缩容且无性能损耗
可以实现NoCopy API,进一步提高性能。
这里最理想的是第三种内存管理方案,字节的netpoll有实现。
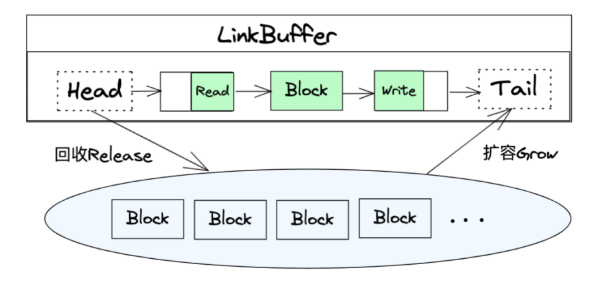
这里引用某个项目的实现说明,NoCopy体现在连接层读到的数据,可以不用拷贝给应用层使用,而是让应用层引用LinkBuffer使用。
首先来讲零拷贝读取接口,我们将读取操作分成了「引用读」「释放」两个步骤,「引用读」会把 Linked Buffer 中一定长度的字节数组以指针的形式取出,用户使用完这些数据后,主动执行「释放」告知 Linked Buffer 刚刚「引用读」的数据空间不会再被使用,可以释放掉,被「释放」了的数据不能再被读取和修改。
零拷贝写入接口则是将用户传入的字节数组构造成一个个节点,每个节点里包含了字节数组的指针,再将这些节点添加到Linked Buffer中,自始至终都是对字节数组的指针进行操作,没有任何的拷贝行为。
(五)性能测试
以上3小节就是一个Reactor网络库的框架和实现设计,流程并不复杂,笔者认为真正考验的是基于Reactor库去实现常见的HTTP/1.x协议、TLS协议甚至HTTP/2.0协议等等,笔者在实现HTTP/1.x的时候就试了很多开源解析器,很多性能都不尽人意;在尝试直接使用Go官方自带的TLS协议解析器,发现TLS四次握手并不是连续的包,第三次握手时,客户端发送的信息可以等一会...大部分问题都比较棘手,这估计也是很多开源库没有实现这些协议的原因吧~
压测结果
在开发完Reactor网络库及在这个库的基础上实现常见的应用层协议后,我们需要一波压测检验网络库的性能。
区别于网上大部分开源库只做简单的Echo压测,笔者这里构建了两种场景压测:
Echo场景:EchoServer不需要做协议解析,也不需要做什么业务逻辑,目的是跟同类型的Reactor库做横向对比。
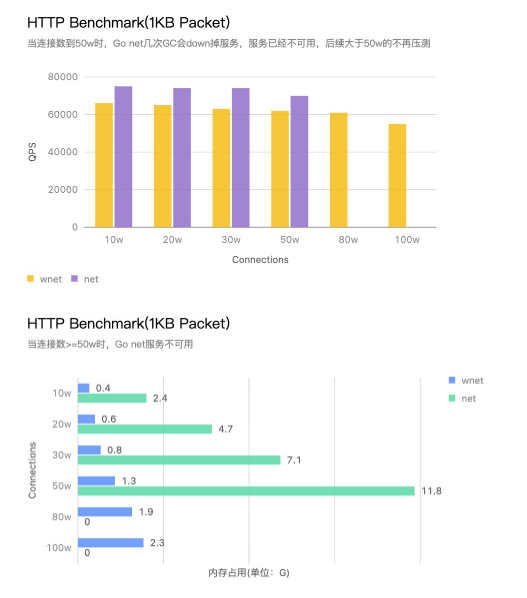
HTTP场景:HTTPServer需要解析HTTP/1.x协议,加上10w循环计数模拟业务逻辑,目的是跑到10w连接上跟Go net对比。
sum := 0for i := 0; i < 100000; i++ {sum += i}
最终的结果如下4张图,可以忽略字节netpoll的数据,大概是因为这两种场景并不是netpoll的目标场景,即RPC场景,所以压测的姿势大概率不对。
Echo场景下是4核机器跑的EchoServer,HTTP场景下是8核跑的HTTPServer。
图1:Echo场景下,固定1KB数据包,不断增加连接数。

图2:Echo场景下,固定1K连接数,不断增加数据包大小。
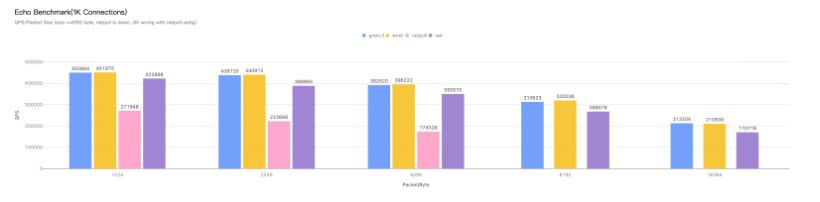
图3和图4:HTTP场景下,固定1KB数据包,不断增加连接数,QPS和内存占用情况。
总结
通过压测结果,可以看出大部分压测,Go原生网络库都没有什么拉胯表现,只有在连接数上去了之后,或者需要处理的数据包越来越大的情况下,Go原生网络库才逐渐显示出颓势。尤其是当连接上到30w到50w之后,Go原生网络库的内存开销增大的同时,伴随的GC时间也变长,到50w连接的时候,一波强制GC服务就down了。
这是Go原生网络库在50w连接时,强制GC后Down掉时的详情:
GC forcedgc 13 @146.006s 0%: 0.12+105+0.004 ms clock, 0.99+0/207/620+0.033 ms cpu, 5877->5877->4197 MB, 7006 MB goal, 8 Pgc 14 @197.643s 1%: 0.084+1084+0.061 ms clock, 0.67+5299/2139/1.8+0.49 ms cpu, 8187->8218->4825 MB, 8394 MB goal, 8 Pgc 15 @220.972s 1%: 4.1+1057+0.039 ms clock, 33+5215/2087/0+0.31 ms cpu, 9412->9442->4794 MB, 9651 MB goal, 8 PGC forced
这是Reactor网络库(wnet) 100w连接时,依然坚挺的GC详情:
gc 23 @208.600s 1%: 0.20+374+0.090 ms clock, 1.6+233/723/0+0.72 ms cpu, 873->891->450MB, 896 MB goal, 8 Pgc 24 @213.872s 1%: 0.18+419+0.051 ms clock, 1.5+4.8/830/0+0.41 ms cpu, 878->899->453MB, 900 MB goal, 8 Pgc 25 @219.270s 1%: 1.2+403+0.071 ms clock, 10+160/790/0+0.57 ms cpu, 884->907->454 MB,907 MB goal, 8 Pgc 26 @224.601s 1%: 0.12+425+0.056 ms clock, 1.0+112/849/0+0.44 ms cpu, 885->906->452MB, 908 MB goal, 8 Pgc 27 @229.851s 1%: 0.20+424+0.079 ms clock, 1.6+107/836/0+0.63 ms cpu, 881->903->453MB, 904 MB goal, 8 Pgc 28 @235.256s 1%: 0.17+431+0.038 ms clock, 1.4+77/863/0+0.30 ms cpu, 884->907->454MB, 907 MB goal, 8 Pgc 29 @240.622s 1%: 0.15+402+0.039 ms clock, 1.2+117/804/0+0.31 ms cpu, 885->907->452MB, 908 MB goal, 8 PGC forced
因此,综合来看,大部分应用场景,Go原生网络库就可以满足。相比Reactor网络库而言,Go原生网络库可以看作是以空间(内存、runtime)来换取时间(高吞吐量和低延时)。当空间紧张时,也就是连接数上来后,巨大的内存开销和相应的GC会导致服务不可用,而这种海量连接场景才是Reactor网络库的优势所在。比如电商大促等活动型场景,有预期的流量高峰,在高峰期会有海量的连接,海量的请求;还有一种直播弹幕、消息推送等长连接场景,也是有大量的长连接。
四、后记
本文的最终实现项目并未开源,读者朋友可以结合上述流程翻阅类似的开源实现,比如gnet、gev等项目理解Reactor网络库的设计,并基于第三部分的设计内容重构这些开源项目,相信读者朋友会做出更好的网络库。
作者简介

刘祥裕
腾讯后台开发工程师
腾讯后台工程师,目前主要负责电竞赛事相关服务开发。
推荐阅读

温馨提示:因公众号平台更改了推送规则,公众号推送的文章文末需要点一下“赞”和“在看”,新的文章才会第一时间出现在你的订阅列表里噢~

