
[科普文] 浅谈 Function Programing 编程范式
推荐阅读: 让程序员越来越厉害的习惯和底层思维
大厂技术 坚持周更 精选好文
背景
设想一个场景,假如需要实现这样两个函数:
transform1:input 一个字符串,output 要全部转成大写并尾部加感叹号修饰;transform2:input 一个字符串,output 要全部转成小写并尾部加感叹号修饰。
如果按以往命令式编程思维,可能会这么写:
const transform1 = (str) => {
if (typeof str === "string") {
return `${str.toUpperCase()}!`;
}
return "Not a string";
};
const transform2 = (str) => {
if (typeof str === "string") {
return `${str.toLowerCase()}!`;
}
return "Not a string";
};
transform1("hello world"); // "HELLO WORLD !"
transform2("HELLO WORLD"); // "hello world !"
两个函数虽效果不同,但代码框架极为相似,逻辑冗余且僵硬,比较难实现复用。相对而言,函数式编程思维则会尽量将逻辑抽象拆解为可被复用的若干最小单位,同样的需求可能会这么实现:
const { flow } = require("lodash/fp");
const toUpper = (str) => str.toUpperCase();
const toLower = (str) => str.toLowerCase();
const exclaim = (str) => `${str}!`;
const isString = (str) => (typeof str === "string" ? str : "Not a string");
const transform1 = flow(isString, toUpper, exclaim);
const transform2 = flow(isString, toLower, exclaim);
transform1("hello world"); // "HELLO WORLD !"
transform2("HELLO WORLD"); // "hello world !"
刚开始可能觉得没什么必要,但是在中大型项目里尤其好用,因为我们也不知道未来需求会变得多复杂。FP 使用大量的Function,每个function都是一个单一的功能,再按功能需求以特定的方式组合起来,编写时易于复用,在出现bug时也易于快速定位到相关的功能函数,使得代码减少重复、容易理解、容易改变、容易排除错误和具有弹性。
核心概念
FP(Functional Programming)是一种通过简单地组合一组函数来编写程序的风格,它推荐我们将几乎所有东西都包装在函数中,编写大量可重用的小函数,然后简单地一个接一个地调用它们以获得类似的结果:( func1.func2.func3 ) 或以组合方式,例如:func1(func2 (func3()))。总而言之是:一种抽象思维、一种编程风格、一种编程规范。
FP 具有以下特点:
1. Function 为First-class citizen(一等公民)
这个特性意味着函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值,而 js 的function 本来就有这个特性。这也是 FP 得以实现的前提。
2. Declarative Programming(声明式编程)
FP 是 Declarative Programming 的代表,逻辑为用较为抽象的程式码,理解代码想要达到怎样的目标,Function 之间不会互相共用state 状态(着重 what)。而 Imperative Programming (命令式编程)比较容易写出状态互相依赖的代码(着重how)。举个加总 Array 🌰:
//Imperative 着重how一步步得出结果
var array = [3,2,1]
var total = 0
for( var i = 0 ; i <= array.length ; i ++ ){
total += array[i]
}
//OOP
//通过封装把状态(数据)和行为(方法)内聚到类中,对外提供能够访问或操作状态的方法。
class Total {
constructor(numbers = []) {
this._numbers = numbers;
}
calc() {
const numbers = this._numbers;
let totle = 0;
for (let i = 0; i < numbers.length; i++) {
totle += numbers[i]
}
return totle;
}
}
const totle1 = new Totle([1, 2, 3, 4, 5]);
console.log(totle1.calc());//15
//Declarative 只需要知道 reduce 做了什么,不关心reduce是怎样做的
var array = [3,2,1]
array.reduce( function( previous, current ){
return previous + current
})
3. 没有Side Effect(副作用)
Side Effect:在完成函数主要功能之外完成的其他副要功能。会导致不易维护代码、得到无法预期结果等等。而平常撰写javaScript 容易造成的Side Effect 非常之多,例如:
修改外部的state
// 改了 global 变量
var a = 0;
a++;
const list = [{type:'香蕉',age:18},...];
// 修改 list 中的 type 和 age
list.map(item => {
item.type = 1;
item.age++;
})
发送HTTP Request Rendering screen 使用会改变原数组/变量的JS method (eg. splice) 修改任何外部变量 DOM 操作 读取input 的值 Changing DB value logging & console: 改变了系统状态
4. Immutable data
所有的数据都是不可变的,这意味着如果想修改一个对象,那应该创建一个新的对象用来修改,而不是修改已有的对象。
// mutable
const balls = ['basketball', 'volleyball', 'billiards']
balls[1] = 'Table Tennis'; // 改变数组原有项
balls // ['Table Tennis', 'volleyball', 'billiards']
// immutable
const balls = ['basketball', 'volleyball', 'billiards']
const newBalls = [...balls] // 复制一份
newBalls[1] = 'Table Tennis';
balls // ['basketball', 'volleyball', 'billiards'] 跟原本一样
newBalls// ['Table Tennis', 'volleyball', 'billiards']
5. Stateless
对于一个函数,完全不依赖外部状态的变化
// Stateful
const x = 4;
x++; // x 变 5
// 省略 100 行...
x*2 // ??x是啥都忘了
//Stateless 不用担心x是什么
const x = {
val: 0
};
const x1 = x => { val: x.val + 1};
6. Pure Function
遵守one input, one output 原则,不管输入几次同样值,输出结果永远相同,且永远有输出值。只做运算与返回return,而且不对外部世界造成任何改变( 没有Side Effect)。Pure Function 里面data 多是immutable data 与stateless 的。另外当一个函数是pure function 且不依赖任何外部状态只依赖函数参数,也称作referential transparency (引用透明)。
//impure 有side effect
const add = (x, y) => {
console.log(`Adding ${x} ${y}`)
return x + y
}
//pure
const add = (x, y) => {
return {result: x + y, log: `Adding ${x} ${y}`}
}
//impure 当 n=4 没有返回值
function tll(i){
if(i<3){
return 0
}
if(i>5){
return 1
}
}
//pure
function tll(i){
if(i<3){
return 0
}else{
return 1
}
}
//impure 相同输入返回值不一样
let x = 1
const count = ()=>x++
//pure
const count = (x)=>x+1
7. 柯理化拆分,「Composition」合成
柯理化的意义是将具有多个参数的多元函数转化为具有较少参数的单元函数的过程。简单的柯理化函数是这样的:
const curry = (fn, length = fn.length, ...args) =>
args.length >= length ? fn(...args) : curry.bind(null, fn, length, ...args);
柯理化的作用是可以固定参数,降低函数通用性,提高函数的适合用性。举个🌰:
// 假设一个通用的请求 APIconst request = (type, url, options) => ...
// GET 请求
request('GET', 'http://....')
// POST 请求
request('POST', 'http://....')
// 但是通过柯理化,我们可以抽出特定 type 的 request
const get = request('GET');
get('http://', {..})
Composition思维一般有两种实现形式,一是compose:(fa,fb,fc)=>x=>fa(fb(fc(x))),一是pipe:(fa,fb,fc)=>x=>fc(fb(fa(x)))
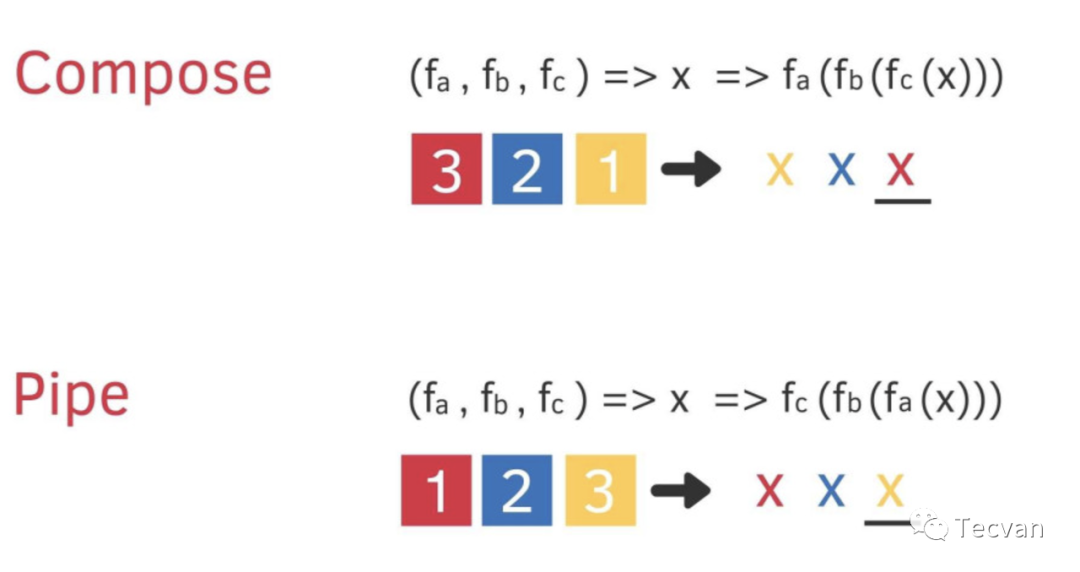
compose函数的简单实现:
function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg;
}
if (funcs.length === 1) {
return funcs[0];
}
return funcs.reduce((a, b) => (...args) => a(b(...args)));
}
pipe 函数的实现同上不过改变一下执行顺序而已:
function pipe(...funcs) {
if (funcs.length === 0) {
return arg => arg;
}
if (funcs.length === 1) {
return funcs[0];
}
return funcs.reduce((a, b) => (...args) => b(a(...args)));
}
举一个 lodash 与 lodash/fp 的🌰介绍柯理化与 Composition 组合的意义:
//lodash实现对请求数据的处理 =>套娃(无柯理化)
const getIncompleteTaskSummaries = async function (memberName) {
let data = await fetchData();
return sortBy(
map(reject(filter(get(data, "tasks"), "username"), "complete"), (task) =>
pick(task, ["id", "dueDate", "title", "priority"])
),
"dueDate"
);
};
//lodash/fp 对FP有着更好的支持,包括完全柯理化、data-last等
const getIncompleteTaskSummaries = async function (memberName) {
let data = await fetchData();
return compose(
sortBy("dueDate"),
map(pick(["id", "dueDate", "title", "priority"])),
reject("complete"),
filter("username"),
get("tasks")
)(data);
};
可以看到经过柯理化拆分提高函数适用性后,通过函数组合使得代码如此的流畅、简洁。通过柯理化拆分和函数组合可以使得FP发挥很大的效用,也是FP必不可少的两步操作,可以将柯理化后的函数比作加工站,函数组合比作流水线。
总结
lodash/fp、ramda都具备data-last、完全柯理化、组合函数、pure纯函数等利于FP的特点。但相比之下两者也有些差异:
lodash/fp依赖于lodash,是在lodash基础上实现的对函数式编程的倾斜,好上手,但是受限于lodash,有很多局限性。ramda没有前置依靠,完全FP,整个库贯穿FP思想,但是上手成本高。 ramda具备很多逻辑判断的函数(when,ifElse等),而lodash/fp暂无。 ramda有更友善的文档,lodash/fp更多要与lodash进行对照。
资料:
https://ramdajs.com/docs/ https://devdocs.io/lodash~4/index https://github.com/lodash/lodash/wiki/FP-Guide