 机器学习与生成对抗网络
机器学习与生成对抗网络




来源:知乎—Fatescript
如果突然出现了历史上没有出现过的问题(比如在某个版本之后突然内存开始泄漏了),用git bisect找到 first bad commit(前提项目管理的比较科学,不会出现很多feature杂糅在一个commit里面;还有就是git checkout之后复现问题的成本不高)。如果bisect大法失效,考虑下面的复现流程。 首先排除data的问题,也就是只创建一个dataloader,让这个loader不停地供数据,看看内存会不会涨(通常data是一系列对不上点、内存泄漏的重灾区)。 其次排除训练的问题,找一个固定数据,不停地让网络训练固定数据进行,看看是否发生泄漏。这一步主要是检查模型、优化器等组件的问题(通常模型本身不会发生泄漏,这一步经常能查出来一些自定义op的case) 最后就是检查一些外围组件了。比如各种自己写的utils/misc的内容。这块通常不是啥重灾区。
import torchimport osimport psutildef log_device_usage(count, use_cuda):mem_Mb = psutil.Process(os.getpid()).memory_info().rss / 1024 ** 2cuda_mem_Mb = torch.cuda.memory_allocated(0) / 1024 ** 2 if use_cuda else 0print(f"iter {count}, mem: {int(mem_Mb)}Mb, gpu mem:{int(cuda_mem_Mb)}Mb")def leak():use_cuda = torch.cuda.is_available()val = torch.rand(1).cuda() if use_cuda else torch.rand(1)count = 0log_iter = 20000while True:value = torch.rand(1).cuda() if use_cuda else torch.rand(1)val += value.requires_grad_()if count % log_iter == 0:log_device_usage(count, use_cuda)count += 1if __name__ == "__main__":leak()
为啥上面的程序会出现内存/显存泄漏? 为啥明明在gpu上的tensor会泄漏内存?
inline at::Tensor & Tensor::add_(const at::Tensor & other, const at::Scalar & alpha) const {return at::_ops::add__Tensor::call(const_cast<Tensor&>(*this), other, alpha);}
at::Tensor & add__Tensor(c10::DispatchKeySet ks, at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) {auto& self_ = unpack(self, "self", 0);auto& other_ = unpack(other, "other", 1);auto _any_requires_grad = compute_requires_grad( self, other );(void)_any_requires_grad;check_inplace(self, _any_requires_grad);c10::optional<at::Tensor> original_self;std::shared_ptr<AddBackward0> grad_fn;if (_any_requires_grad) {grad_fn = std::shared_ptr<AddBackward0>(new AddBackward0(), deleteNode);grad_fn->set_next_edges(collect_next_edges( self, other ));grad_fn->other_scalar_type = other.scalar_type();grad_fn->alpha = alpha;grad_fn->self_scalar_type = self.scalar_type();}{at::AutoDispatchBelowAutograd guard;at::redispatch::add_(ks & c10::after_autograd_keyset, self_, other_, alpha);}if (grad_fn) {rebase_history(flatten_tensor_args( self ), grad_fn);}return self;}
void set_gradient_edge(const Variable& self, Edge edge) {auto* meta = materialize_autograd_meta(self);meta->grad_fn_ = std::move(edge.function);meta->output_nr_ = edge.input_nr;}AutogradMeta* materialize_autograd_meta(const at::TensorBase& self) {auto p = self.unsafeGetTensorImpl();if (!p->autograd_meta()) {p->set_autograd_meta(std::make_unique<AutogradMeta>());}return get_autograd_meta(self);}AutogradMeta* get_autograd_meta(const at::TensorBase& self) {return static_cast<AutogradMeta*>(self.unsafeGetTensorImpl()->autograd_meta());}
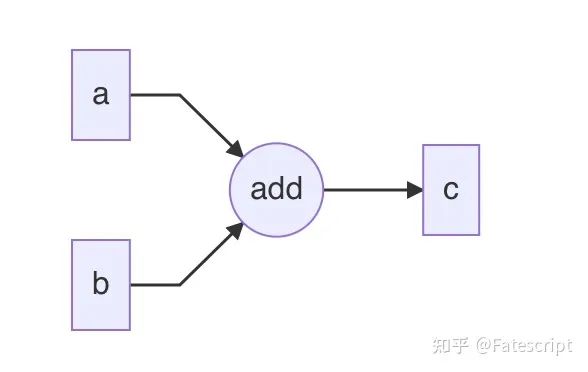
c = a + b的Graph形式
total_loss = 0for data in dataloader:loss = model(data)total_loss += losstotal_loss.backward()
def leak():use_cuda = torch.cuda.is_available()val = torch.rand(1).cuda() if use_cuda else torch.rand(1)val.requires_grad_() # 比如这个requires_grad_是在某个地方偷偷加的count = 0log_iter = 20000log_device_usage(count, use_cuda)while True:val += 1 # 这个1在torch里面会表示为一个cpu tensorif count % log_iter == 0:log_device_usage(count, use_cuda)count += 1

猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》


