 机器学习与生成对抗网络
机器学习与生成对抗网络




1 什么是半监督学习?
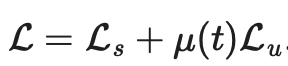 。其中监督损失
。其中监督损失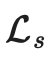
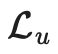 。加权项
。加权项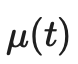 通常选择使用斜坡函数,其中t是训练步数,随着训练次数的增加,的占比提升。
通常选择使用斜坡函数,其中t是训练步数,随着训练次数的增加,的占比提升。
2 符号说明表
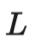 | |
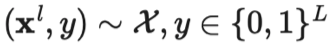 | 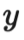 是真实标签的独热表示。 是真实标签的独热表示。 |
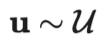 | |
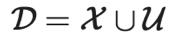 | |
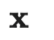 | |
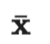 | |
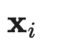 | |
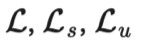 | |
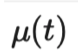 | |
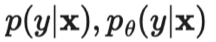 | |
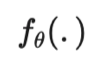 | |
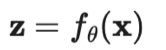 | |
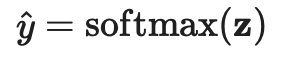 | |
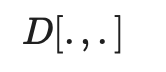 | |
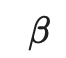 | |
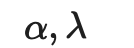 |  |
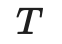 | |
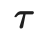 |
3 假设
高维数据往往位于低维流形上。尽管现实世界的数据可能是在非常高的维度上被观察到的(例如,真实世界的物体/场景的图像),但它们实际上可以被更低维的流形捕获,这种低维流形上会捕获数据的某些属性,并将一些相似的数据点进行紧密组合(例如真实世界的物体/场景的图像,并不是源自于所有像素组合的均匀分布)。这就使得模型能够学习一种更有效的表征方法去发现和评估无标签数据点之间的相似性。这也是表征学习的基础。关于此假设,更详细的阐述可参考《如何理解半监督学习中的流行假设》这篇文章。
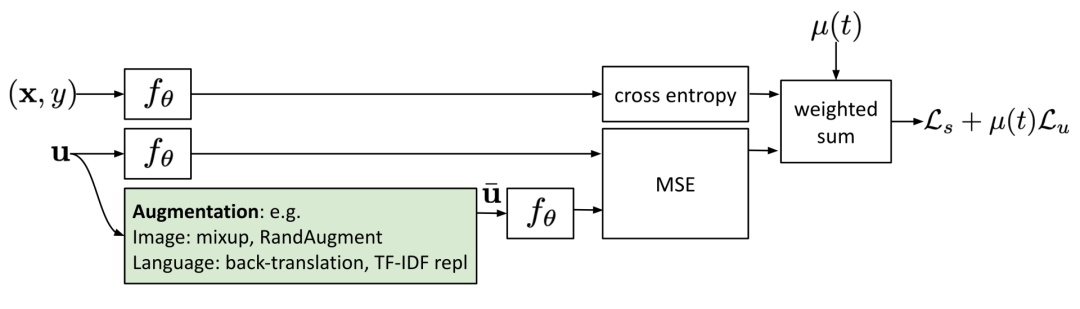
4 一致性正则化(Consistency Regularization)
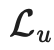 。
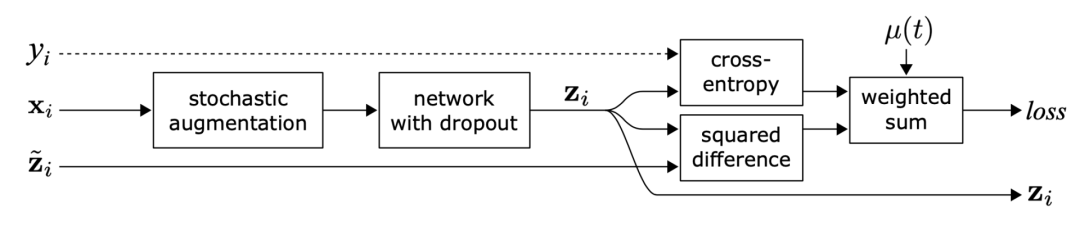
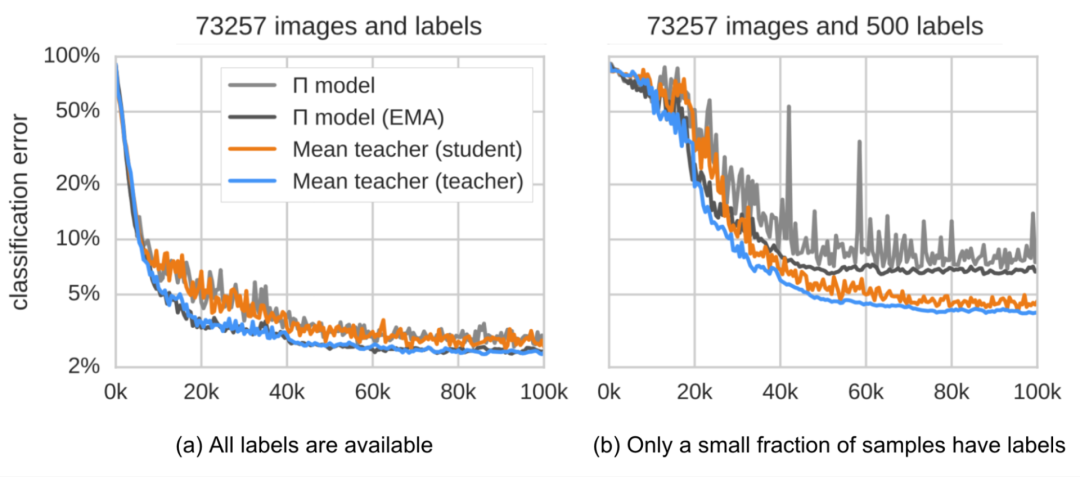
。1.Π模型

图1:Π-模型概览。同一个输入经过不同的随机增强和 dropout掩膜的扰动产生两个版本,通过网络得到两个输出,Π-模型预测这两个输出是一致的。(图片来源:Laine 、 Aila 2017发表的论文《半监督学习的时序集成》 )
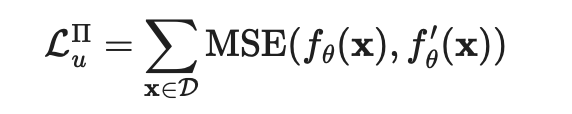
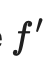 指同一个神经网络应用不同的随机增强或dropout掩膜的取值。该损失使用整个数据集。
指同一个神经网络应用不同的随机增强或dropout掩膜的取值。该损失使用整个数据集。2.时序集成(Temporal ensembling)
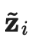 的实时模型预测的指数移动平均值(EMA)作为学习目标,EMA 在每轮迭代中仅需计算和更新一次。由于时序集成模型的输出
的实时模型预测的指数移动平均值(EMA)作为学习目标,EMA 在每轮迭代中仅需计算和更新一次。由于时序集成模型的输出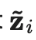 被初始化为0,因而除以
被初始化为0,因而除以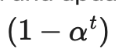 进行归一化来纠正这一启动偏差。出于同一原因,Adam 优化器也有这样的偏差纠正项。
进行归一化来纠正这一启动偏差。出于同一原因,Adam 优化器也有这样的偏差纠正项。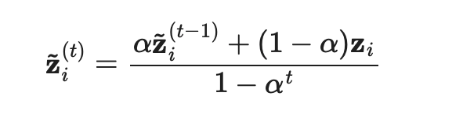
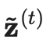 是在第t轮迭代中的集成预测,
是在第t轮迭代中的集成预测,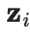 是在当前回合的模型预测。需要注意的是,由于
是在当前回合的模型预测。需要注意的是,由于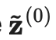 =0,进行偏差纠正后,
=0,进行偏差纠正后,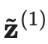 就完全等于在第1轮迭代中的模型预测值。
就完全等于在第1轮迭代中的模型预测值。3.均值教师(Mean teachers)
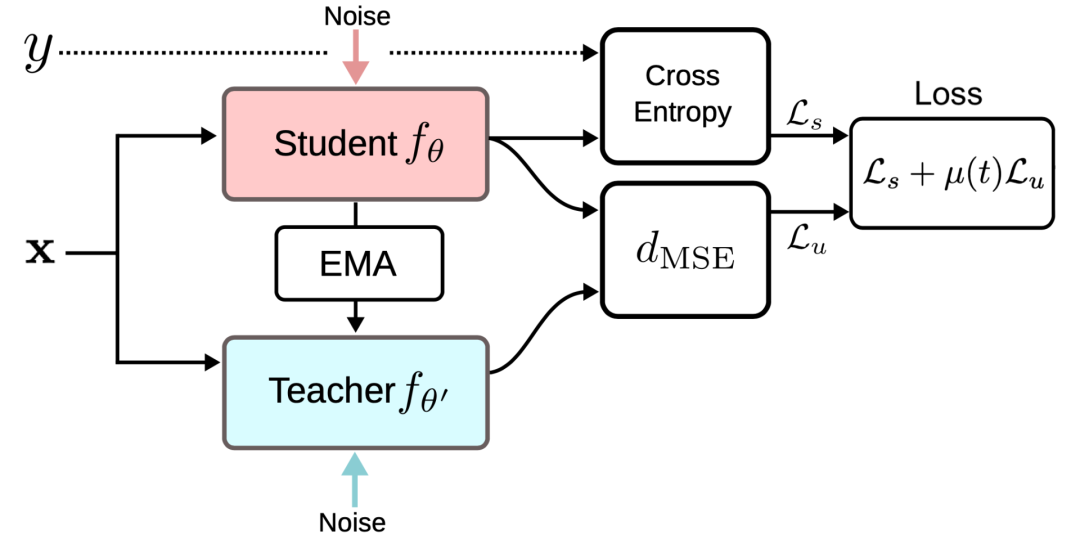
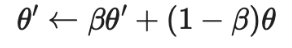
输入增强方法(例如,输入图像的随机翻转、高斯噪声)或对Student模型进行dropout处理对于模型实现良好的性能是必要的。Teacher模式不需要进行dropout处理。 性能对指数移动平均值的衰减超参数β敏感。一个比较好的策略是在增长阶段使用较小的β=0.99,在后期Student模型改进放缓时使用较大的β=0.999。 结果发现,一致性成本函数的均方误差(MSE)比KL发散等其他成本函数的表现更好。
4.将噪声样本作为学习目标
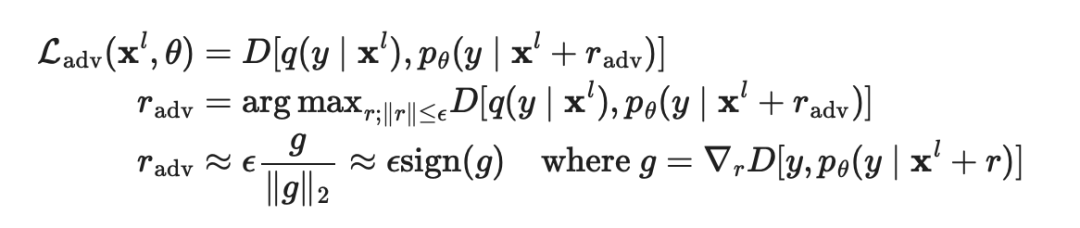
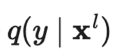 是真实分布,近似于真值标签的独热编码,
是真实分布,近似于真值标签的独热编码,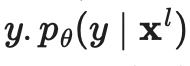 是模型预测,
是模型预测,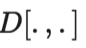 是计算两个分布之间差异的距离函数。
是计算两个分布之间差异的距离函数。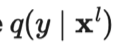 是未知的,VAT 将该未知项替换为当前权重设定为
是未知的,VAT 将该未知项替换为当前权重设定为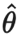 时,当前模型对原始输入的预测。需要注意的是,是模型权重的的固定值,因而在上不会进行梯度更新。
时,当前模型对原始输入的预测。需要注意的是,是模型权重的的固定值,因而在上不会进行梯度更新。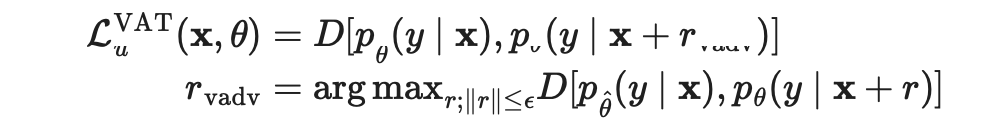
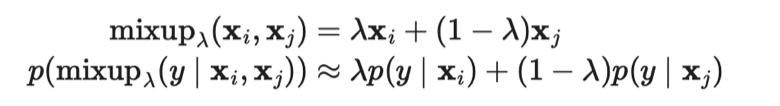
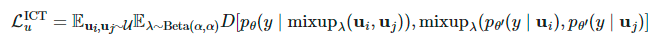
 ),能进一步提升性能。
),能进一步提升性能。
低置信度掩膜(Low confidence masking):如果样本的预测置信度低于阈值 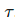 ,则对其进行掩膜处理。
,则对其进行掩膜处理。锐化预测分布(Sharpening Prediction Distribution):在Softmax中使用低温 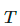 来对预测概率分布进行锐化。
来对预测概率分布进行锐化。域内数据过滤(In-Domain Data Filtration):为了从大的域外数据集中提取更多的域内数据 ,研究人员训练一个分类器来预测域内标签,然后保留具有高置信度预测的样本作为域内候选样本。
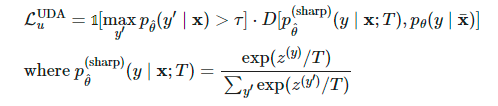
5 伪标签(Pseudo Labeling)
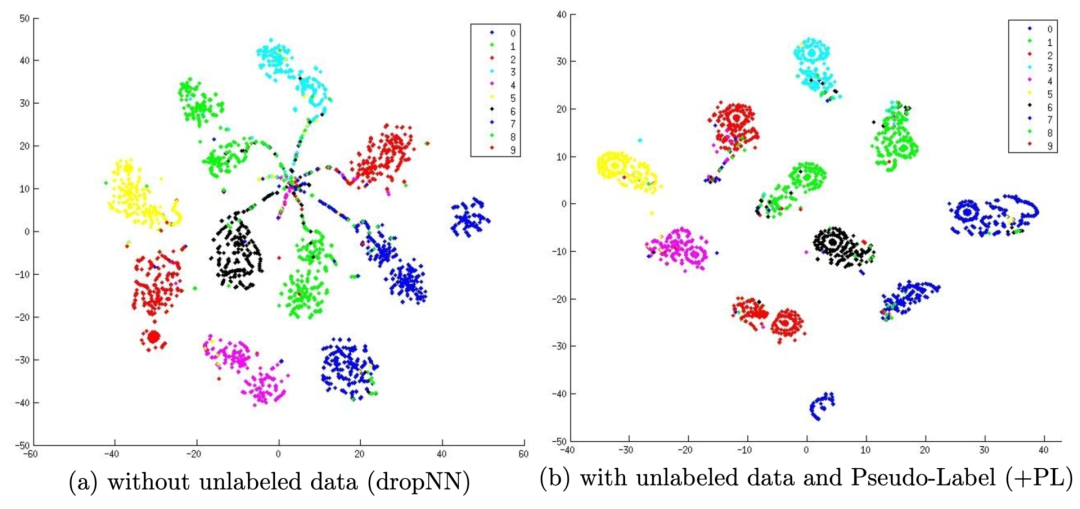
1.标签传播(Label propagation)
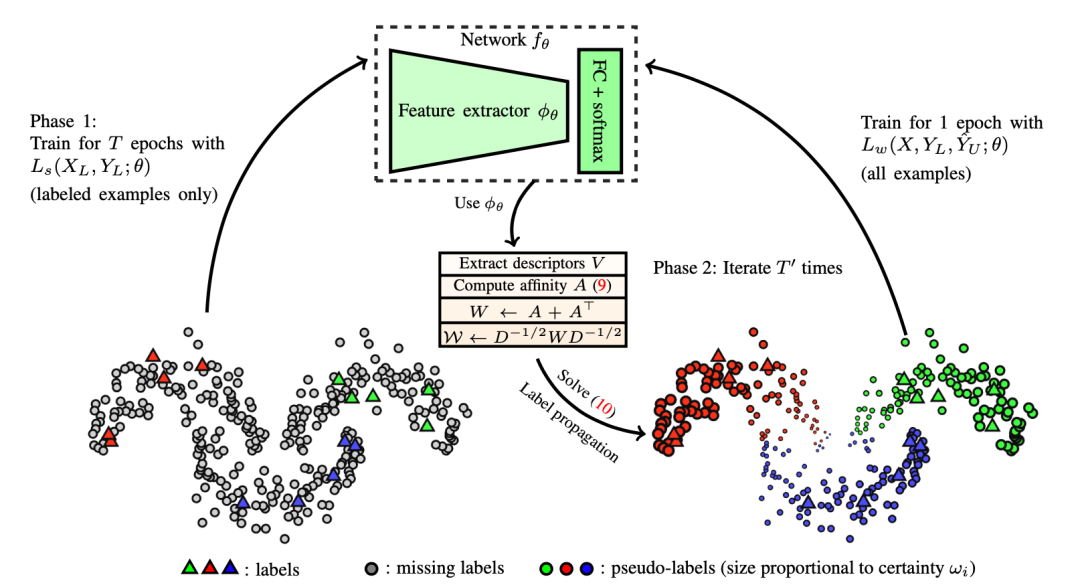
2.自训练(Self-Training)
首先,它在标签数据上构建分类器。 接着,它使用该分类器预测无标签数据的标签,并将置信度最高的标签转换为标签样本。
Student 模型加应该足够大(即比Teacher 模型大),以适用于更多数据。 加入噪声的Student 模型应该结合数据平衡方法,这对于平衡每个类重的伪标签图像的数量尤其重要。 软伪标签比硬标签效果更好。
3.减小确认偏误(Confirmation Bias)
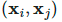 两个样本和它们对应的真标签和伪标签
两个样本和它们对应的真标签和伪标签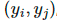 ,插值标签方程可以转化为softmax输出的交叉熵损失:
,插值标签方程可以转化为softmax输出的交叉熵损失: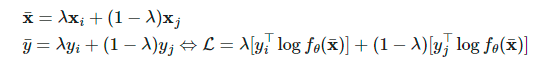
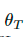 和的函数
和的函数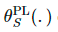 ,并倾向于通过优化Teacher模型来相应地最小化这一损失。
,并倾向于通过优化Teacher模型来相应地最小化这一损失。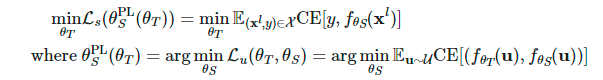

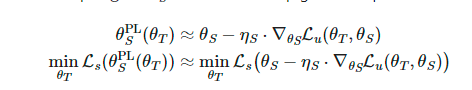
Student模型更新:给定一批无标签样本 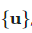 ,我们可以通过函数
,我们可以通过函数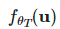 生成伪标签,并使用一步随机梯度下降优化
生成伪标签,并使用一步随机梯度下降优化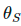 :
: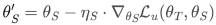 。
。Teacher模型更新:给定一批标签样本 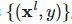 ,我们重复使用Student模型的更新来优化
,我们重复使用Student模型的更新来优化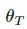 :
: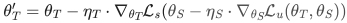 。此外,还将UDA对象应用于Teacher模型以兼并一致性正则化。
。此外,还将UDA对象应用于Teacher模型以兼并一致性正则化。
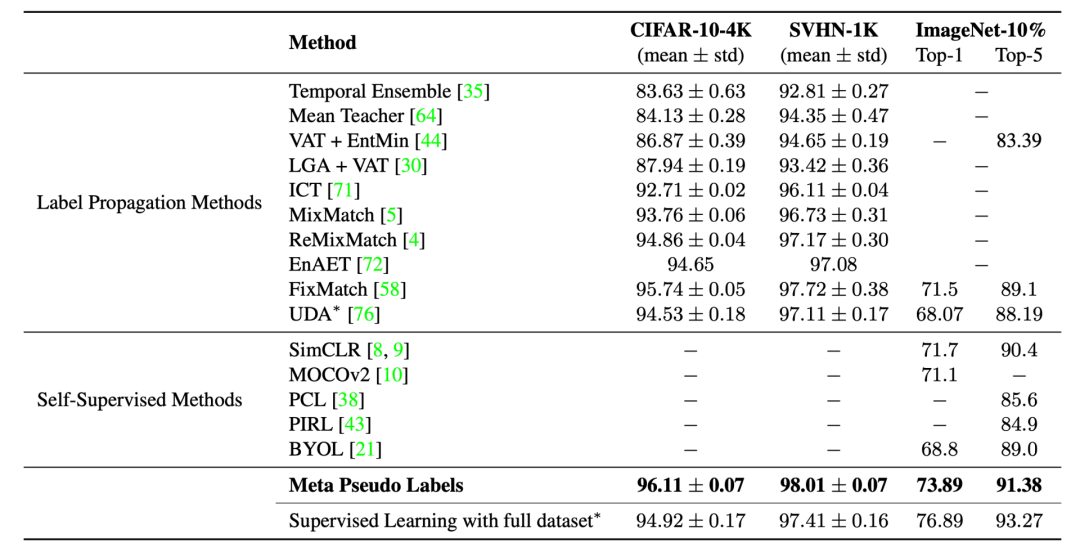
6 一致性正则化+伪标签
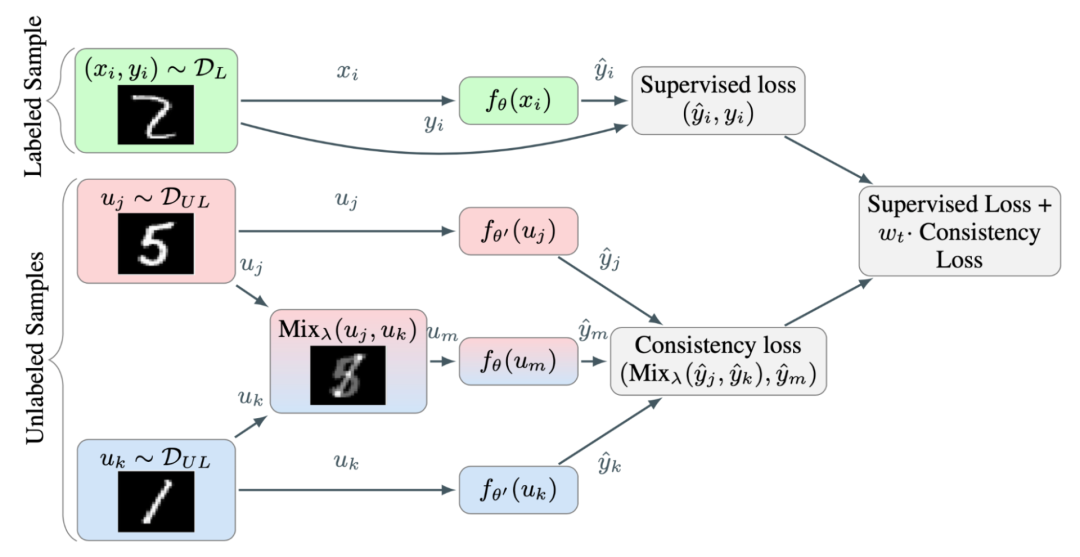
1.MixMatch
一致性正则化(Consistency regularization):让模型对受到扰动的无标签样本输出相同的预测。 熵最小化(Entropy minimization):让模型对无标签数据输出置信预测。 MixUp 增强:让模型在样本之间进行线性行为。
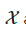 和无标签数据
和无标签数据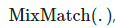 运算得到其增强版本,
运算得到其增强版本,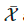 和
和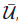 分别表示增强样本和给无标签样本预测到的标签。
分别表示增强样本和给无标签样本预测到的标签。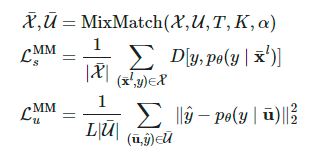
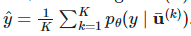 来猜测伪标签。
来猜测伪标签。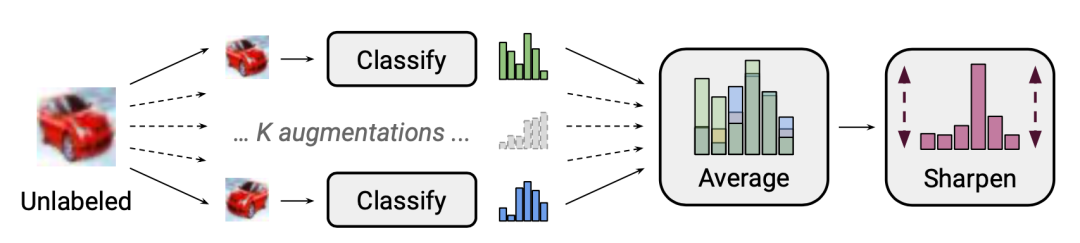
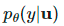 经过归一化处理为
经过归一化处理为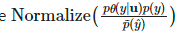 以匹配真实边缘分布。
以匹配真实边缘分布。应用了数据增强和Mixup方法的监督损失 应用了数据增强和Mixup方法却使用伪标签作为目标的无监督损失 不使用Mixup方法情况下,单个强增强的无标签图像的交叉熵损失 自监督学习中的旋转损失( rotation loss)。
2.DivideMix
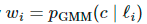 (即样本属于干净样本集的概率)大于阈值,则该样本被视为干净样本,否则被视为噪声样本。
(即样本属于干净样本集的概率)大于阈值,则该样本被视为干净样本,否则被视为噪声样本。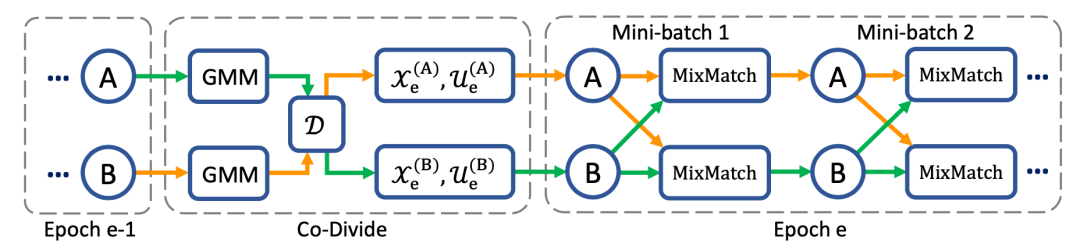

3.FixMatch
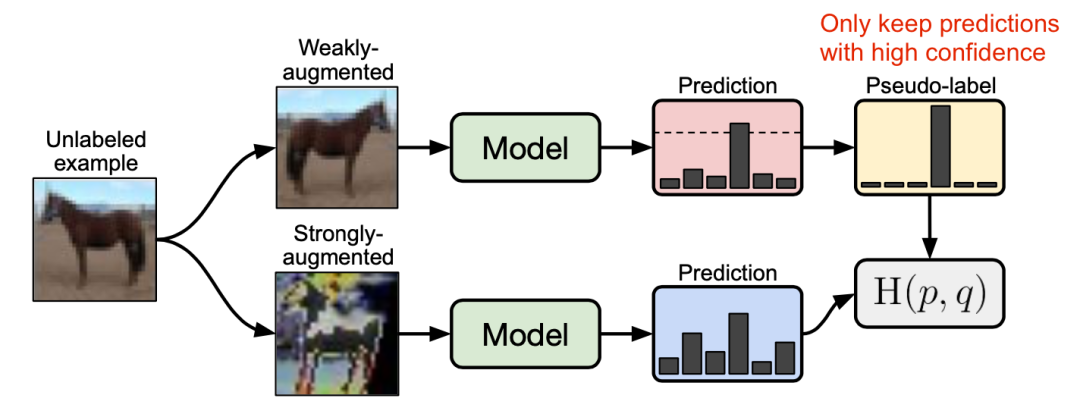 图16:FixMatch方法的工作原理图示。(图片来源:Sohn等人在2020年的论文《FixMatch: 使用一致性和置信度简化半监督学习》)
图16:FixMatch方法的工作原理图示。(图片来源:Sohn等人在2020年的论文《FixMatch: 使用一致性和置信度简化半监督学习》)
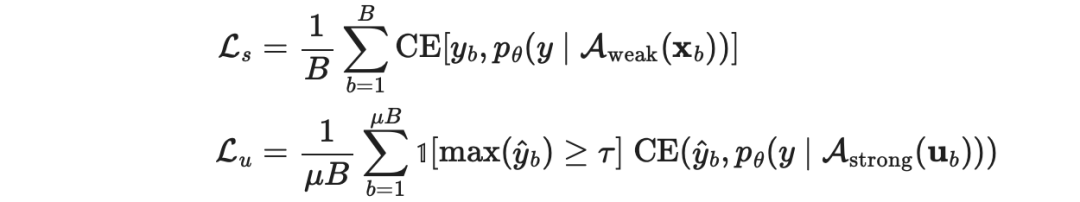
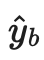 是无标签样本的伪标签;
是无标签样本的伪标签;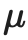 是决定
是决定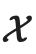 和
和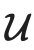 的相对大小的超参数。
的相对大小的超参数。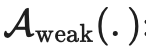 :标准的平移和变换增强。
:标准的平移和变换增强。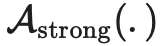 :AutoAugment、 Cutout、 RandAugment和 CTAugment等数据增强方法。
:AutoAugment、 Cutout、 RandAugment和 CTAugment等数据增强方法。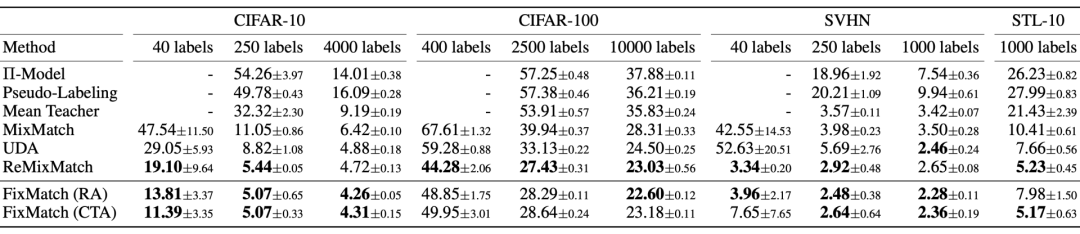
当使用阈值τ时,使用温度参数T对锐化预测分布不会产生显著影响。 Cutout和CTAugment是强增强方法,对模型达到良好的性能“功不可没”。 当标签猜测使用强增强来取代弱增强时,模型在训练早期就发散了。如果舍弃弱增强,模型就会过度拟合猜测的标签。 使用弱增强而不是强增强进行伪标签预测,会导致模型性能不稳定。强数据增强,对于模型性能的稳定性而言,至关重要。
7 结合强大的预训练
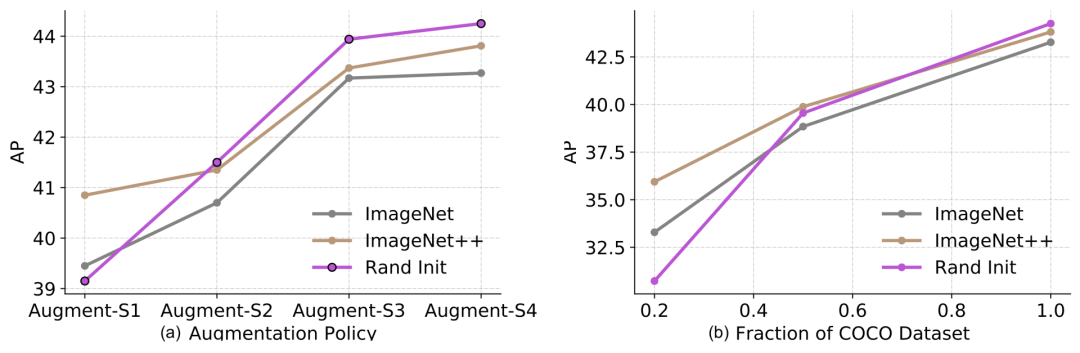
可用于下游任务的标签样本越多,预训练的有效性就越低。预训练在低数据模式(20%)下是有帮助的,但在高数据情况下是中性的或起反作用的。 在高数据/强增强模式下,即便预训练会起反作用,自训练也是有帮助的。 即使使用相同的数据源,自训练也可以在预训练的基础上带来额外的改进。 自监督预训练(例如通过 SimCLR进行预训练)会损害模型在高数据模式下的性能,跟监督预训练差不多。 联合训练监督和自监督学习目标有助于解决预训练和下游任务之间的不匹配问题。预训练、联合训练和自训练都是加性的。 噪声标签或非目标标签(即预训练标签未与下游任务标签对齐)比目标的伪标签更差。 自训练在计算上比在预训练模型上进行微调,更昂贵。
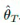 。
。 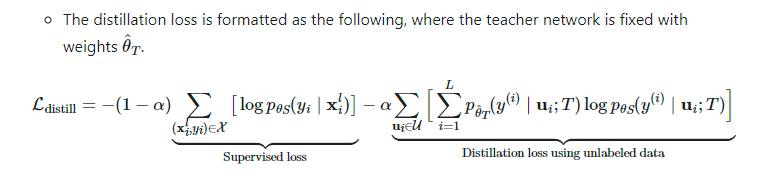
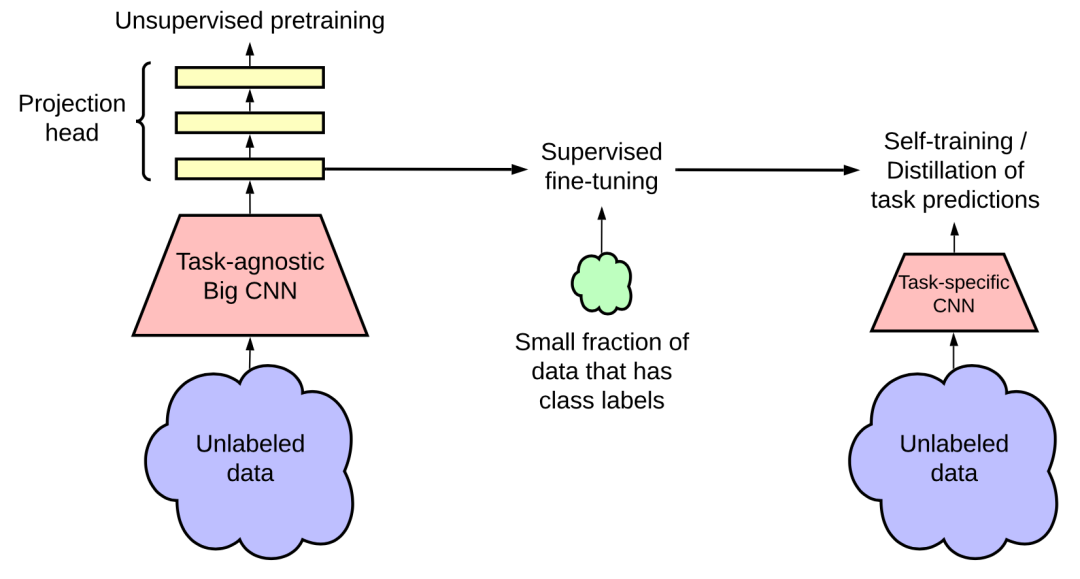
图19:半监督学习框架通过与任务无关的无监督预训练(左)和特定任务的自训练和蒸馏(右)来使用无标签的数据语料库。(图片来源:Ting Chen等人在2020年的论文《大型自监督模型是强大的半监督学习者》)
更大模型的标签学习更加高效; SimCLR 中更大/更深的project heads可以改善表征学习; 使用无标签数据进行蒸馏,能优化半监督学习。
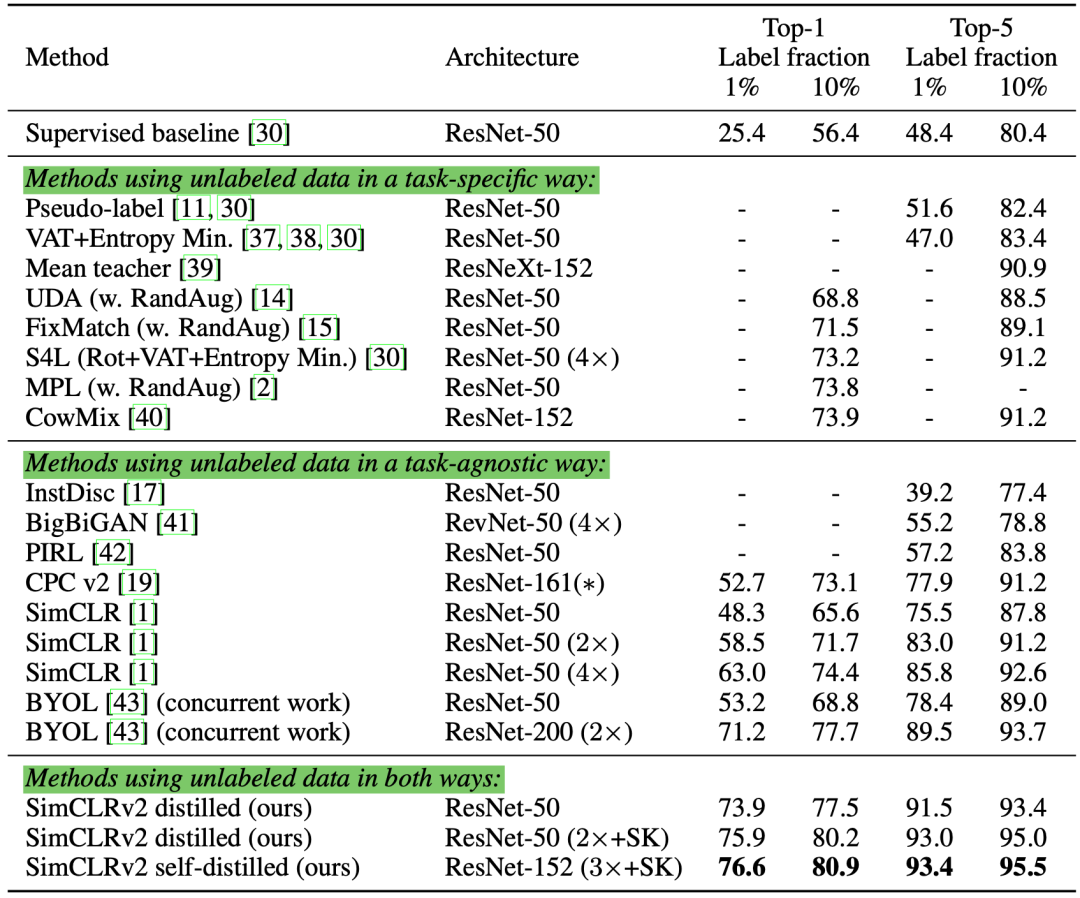
通过先进的数据增强方法将有效且多样化的噪声应用于样本。 在处理图像时,MixUp 是一种有效的数据增强方法。该方法同样可用于语言任务,实现较小的增量优化((Guo et al. 2019)。 设置阈值,并去掉置信度低的伪标签。 设置每个小批量中的标签样本的最少数量。 锐化伪标签分布来减少类重叠。
@article{weng2021semi, title = "Learning with not Enough Data Part 1: Semi-Supervised Learning",
author = "Weng, Lilian",
journal = "lilianweng.github.io",
year = "2021",
url = "https://lilianweng.github.io/posts/2021-12-05-semi-supervised/"
}
参考文献:
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》


