
云原生事件驱动组件之DIP

事件驱动架构思想一直是软件架构领域非常重要的一种设计思想,每一次架构浪潮下都会被提起。
DDD 时代,怎么解决两个领域下通信问题呢?事件驱动。
ESB 时代,事件总线就是非常重要的概念。
微服务时代,异步通信/MQ更是被广泛使用。
云原生时代了,事件驱动架构模式再次被提起,变成了云服务下的一个云原生产品了。
为了更好地理解云原生,了解云原生事件驱动产品的价值就是很好的一个切入点。
今天介绍的云原生事件驱动产品是DIP,主要解决的是云原生时代数据集成的问题。
随着移动互联网发展、数据量爆炸,围绕于数据接入、处理、清洗、展现的技术组件就不断在发展。
一个经典的数据链路架构图如下:
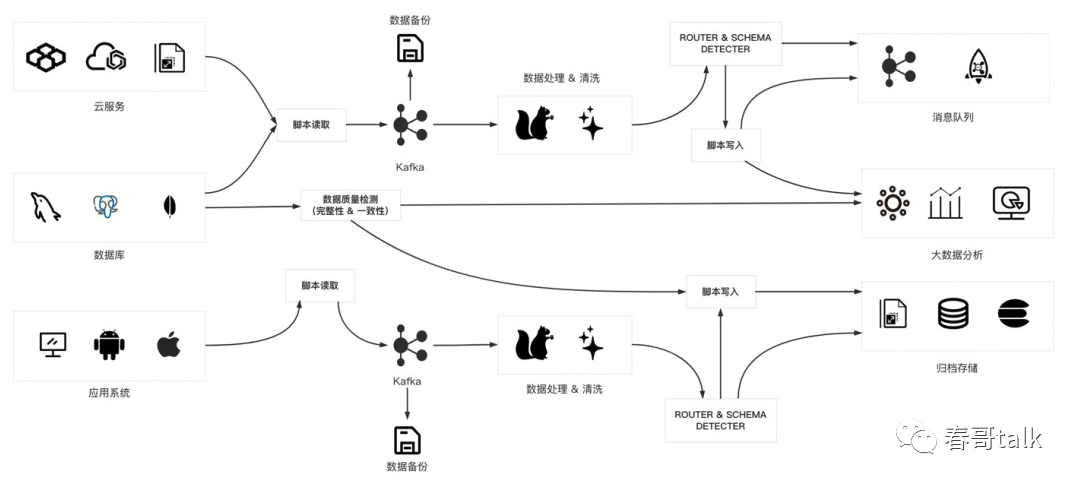
从数据源、数据接入、数据缓冲、数据目标,整个链路非常复杂。
云原生时代下,数据集成的新诉求是:SaaS 化、低代码、简单、可靠、高性能、按需付费。
DIP 是腾讯云的一款数据接入平台,目的是构建数据源和数据处理系统之间的桥梁。
定位是云上 SaaS 数据接入与处理平台,帮助客户一站式实现数据接入、处理、分发。
DIP 可以实现 Http/Tcp 协议的 SDK 数据上报、数据变更订阅机制、支持多种存储数据库。
DIP 类似于传统大数据解决方案中的 Kafka+Flink 的角色,但不能完全替代 Flink,只能解决一些通用数据接入场景,而复杂的数据处理还需要依赖于 Flink 流式计算实现。
DIP 是基于 Kafka 实现的,Kafka 定位于存储层,DIP 定位于分发平台,在 Kafka 基础上多了接入层与分发层。
Kafka 属于 PaaS 层能力,DIP 属于 SaaS 层能力,通过低代码、Serverless 方式,实现一站式数据链路搭建,免运维的效果。

接下来看下 DIP 是如何解决过去的一些高频数据处理场景的。
日常开发中,经常遇到一些比较简单的数据统一上报的需求,比如监控数据、用户行为数据、APP 操作数据等。需要将端到端的数据统一收集到服务端,供业务查询、处理、分析。
一般情况下,这些上报的数据需要存储到下游的分析系统里面(比如 ES、HDFS、Hive、数据湖等),再进行下一步处理。
但以上这些基础设施属于大数据相关组件,需要做数据接收、处理任务编写、存储等工作,对于研发人员和产品人员学习成本高,不够友好。同时大数据组件往往属于多租户产品,扩容难度大、成本高也不够灵活。
DIP 通过 SaaS 思路解决这个问题,通过简单的界面配置+SDK 上报方式,实现整个数据采集链路的搭建,简化了数据上报、处理、展示的闭环,降低了研发成本。
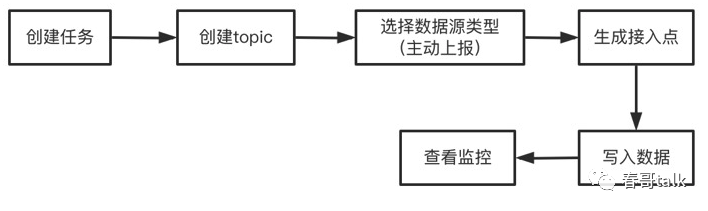
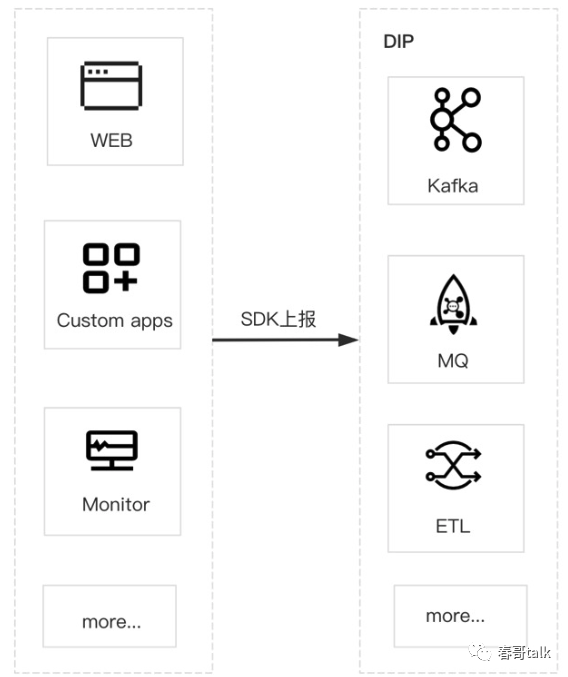
数据上报端,提供多种上报 SDK,屏蔽了上报协议和多种 MQ 存储协议的复杂性与差异性。
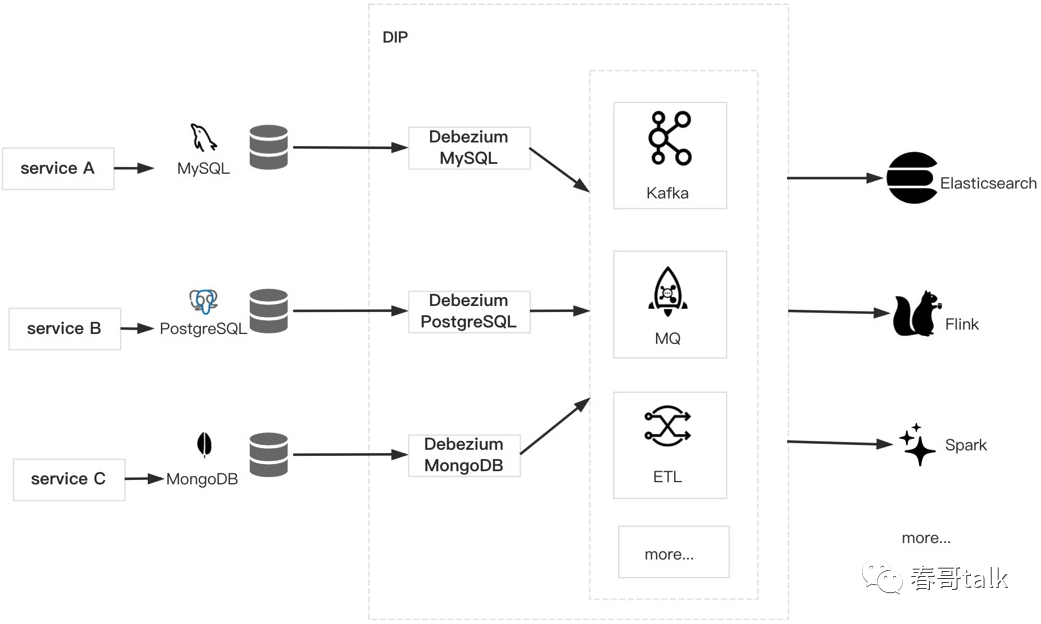
另一种数据集成常见的需求是监听 mysql 的 binlog,这种情况往往需要研发搭建自定义的数据变更订阅组件,比如基于 canal、databus 等。
而基于 DIP 提供的 SaaS 组件,通过界面配置的方式即可完成对 Mysql 的数据订阅、处理、转储等流程。
另一种常见的数据常见是数据的清洗与分发。比如数据接入之后,只需要简单的处理、过滤、归并,再做下一步的存储、转发、分析、查询。
过去,对于这个问题,需要下把预处理数据落存储,比如存储到 ES 或者 HDFS,然后自己写个 Flink 的任务,做过程清洗。成本高、效率低。
如果使用 DIP,可以通过提供的产品配置,完成一键配置,低代码方式实现数据的过滤和清洗。
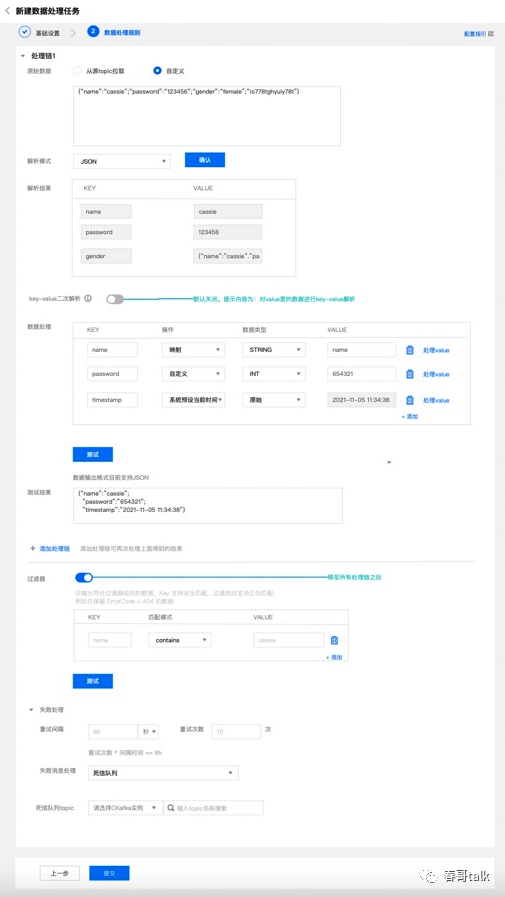
还有一种场景,是多个数据源的归并处理。比如有的数据来源于 SDK 上报,有的来源于 Kafka,有的是 MySql 的 binlog。过去对于这种问题,同样需要数据转储、分析、再处理,整个链路就比较长。
DIP 同样可以通过简单的配置,实现对多个数据源的接入。
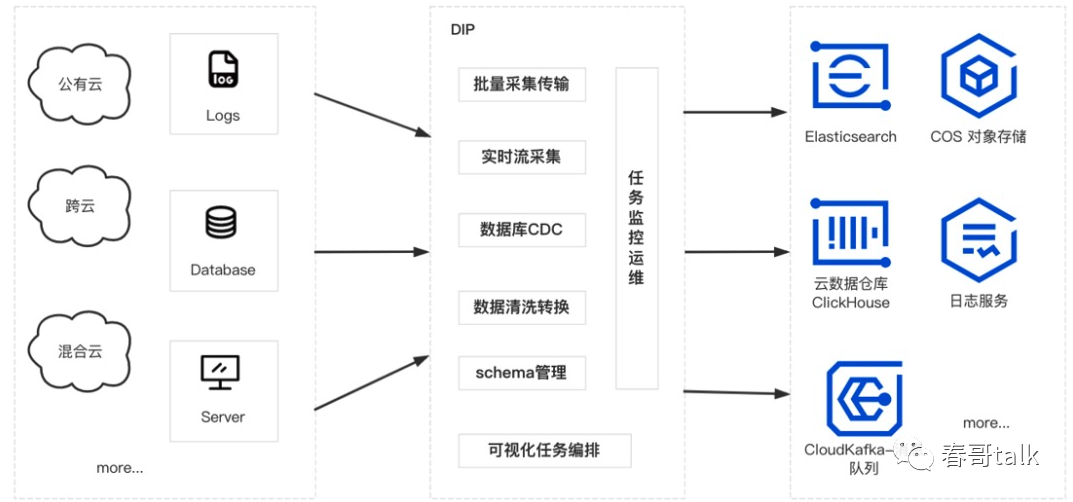
DIP 整体架构上,分为两层,一层是数据面、一层是管控面。
管控面围绕于资源管理、监控调度、自动扩缩容、迁移管理、配置告警等。
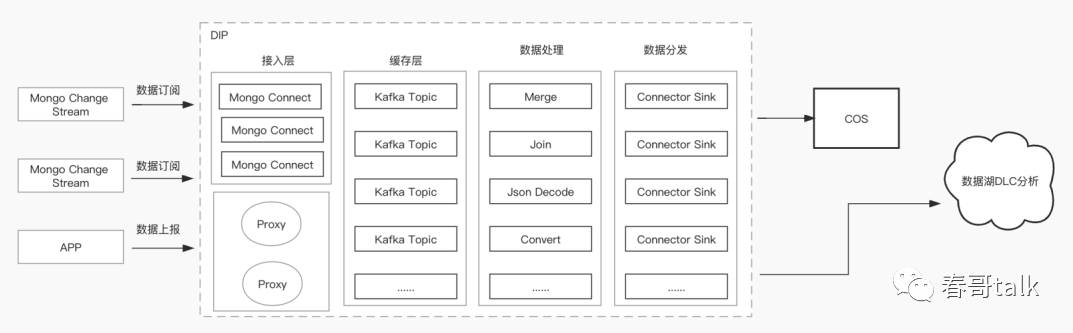
数据面围绕于数据流转的链路,分为数据接入、数据处理、数据流出三部分。
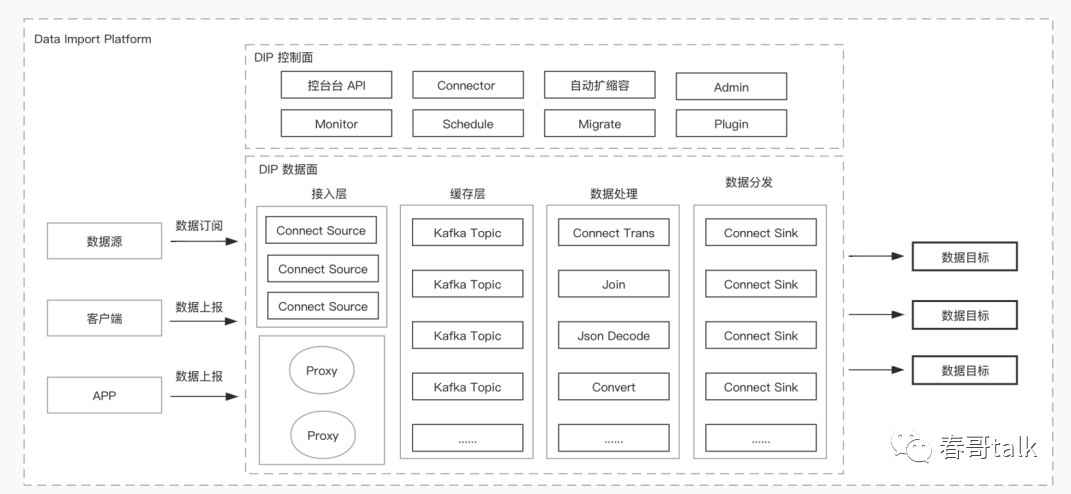
数据接入方式上,主要有三种:主动订阅、数据上报、跨云数据获取。
数据接入模块也有三类,一类是 mysql 、nosql这样的服务类数据上报;
一类是日志采集器;
一类是 http 的主动上报;
对于前两类,可以通过产品化配置界面,拖拉拽的方式快速配置数据链路,而无需关注底层实现。第三类则需要引入 DIP 的 sdk 作为数据接入点,有一定的侵入性和开发成本,但数据上报更灵活。
DIP 平台支持任务编排,在控制台上可以看到数据流转链路,比如数据源情况、转储处理、任务投递、数据详情等。通过编排方式可以增加或删除链路上的节点,做定制的数据处理链路。
DIP 架构上深度集成了 Kafka,通过 kafka 的 connector 将不同的数据源数据导进来。对于 http 数据上报,是通过 SDK 实现。本质是将 http 上报的数据放到 kafka 的 producer,导入到队列中,借助于 kafka 实现高可用、自动恢复、扩缩容等能力,提升稳定性。
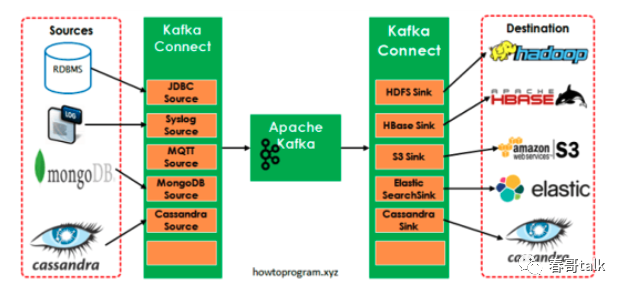
接下来,再看下DIP接入的一些案例。
多场景数据上报:将 web 端、移动端多种数据源上报,做检索查询。
自定义代码,引入 sdk,进行业务逻辑处理;
原始数据进入 ES 便于数据检索;
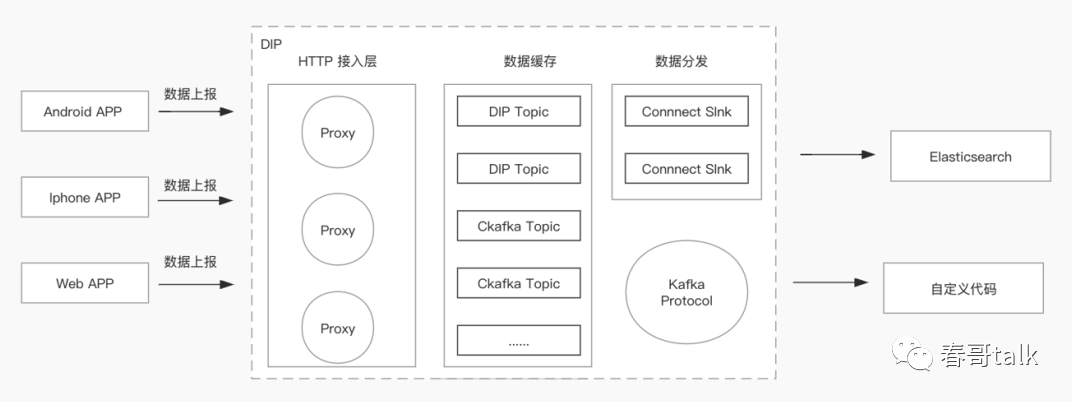
数据处理分发:采集服务日志,放入 es 做检索,部分数据清洗处理后,存储到 hdfs 持久化。
同一套数据源通过 kafka 上报,基于 DIP 实现不同需求的数据分发(用于检索、持久化、fink 计算)
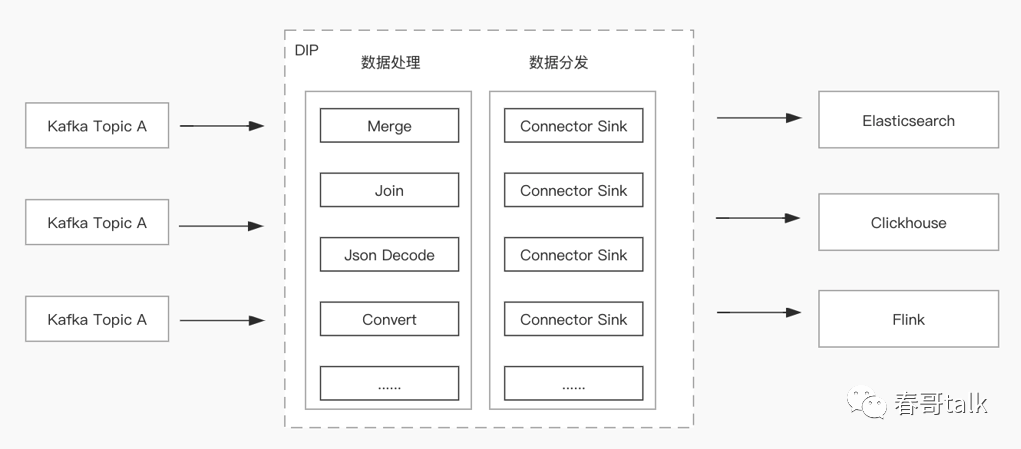
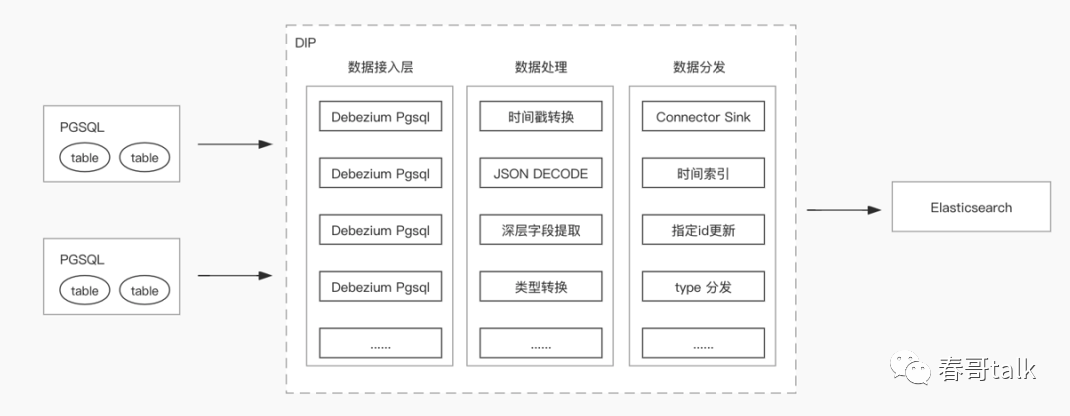
数据订阅:多套存储引擎中数据导入 ES 进行检索查询。
数据写入 ES 时跟进时间分索引;
数据量大,需要做一定的数据精简;
根据不同的表,将数据分发到不同的索引中;
原始架构链路:PGSQL + Debezium PGSQL + kafka connector + kafka + logstash + ESDIP架构链路:PGSQL + DIP + ES
http 数据接入 MQ:
简化客户端使用,最好用兼容性较好的 http 协议;
底层 MQ 引擎切换业务无感;
支持现有的 Http 协议 SDK;
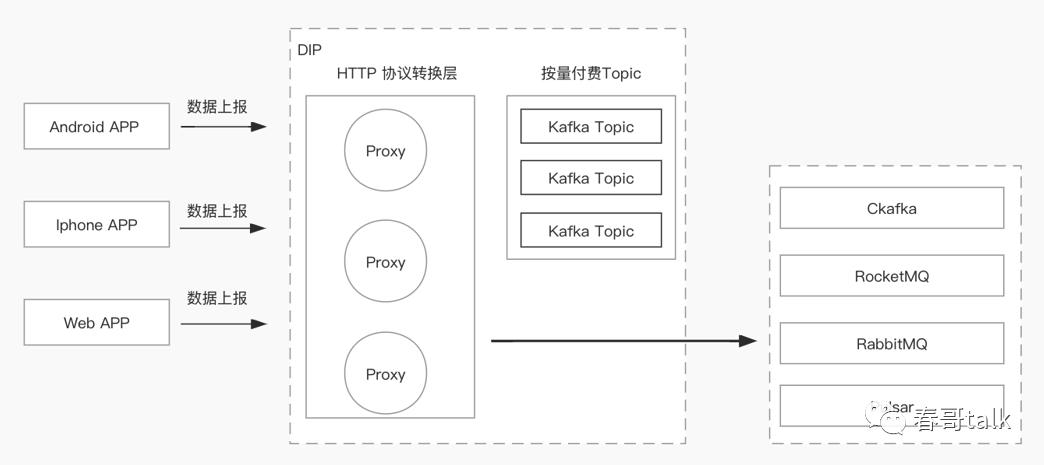
数据接入数据湖:多种数据源数据共同存储到数据湖。
希望通过对DIP的介绍,能帮助你在头脑中形成一个云原生时代,基础架构组件产品的全貌,帮助你看待及设计适用于云原生时代的技术组件。