
C++异步:libunifex的scheduler实现!
共 9869字,需浏览 20分钟
· 2022-07-16

导语 | 本篇我们将集中介绍在cpu thread类型的execution context,不涉及异构的execution context实现和调度。
前篇《C++异步:libunifex中的concepts详解!》中我们相对深入的介绍了libunifex中的concepts的方方面面,对execution的整体设计框架有了一个基础的认知,本篇我们将继续介绍作为execution执行基石的scheduler的实现细节。本篇的介绍集中在cpu thread类型的execution context上,不涉及异构的execution context实现和调度。
一、scheduler的实现概述
我们先来回顾一下scheduler在execution整体设计中的位置和作用:
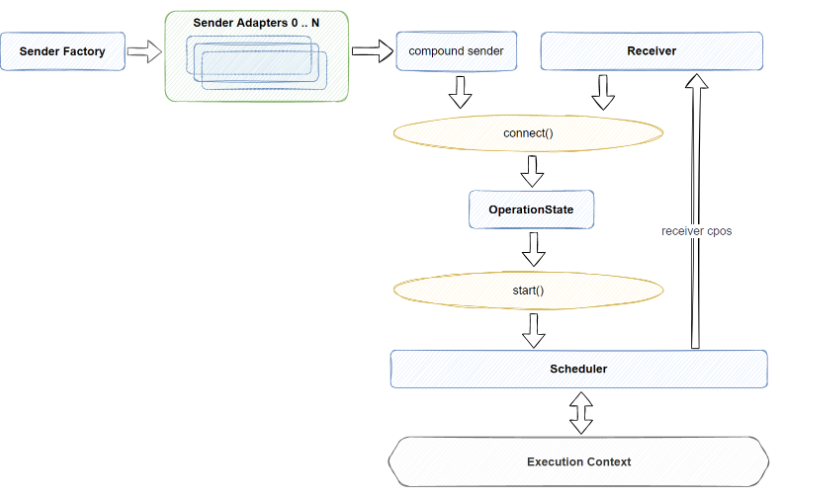
libunifex中的Scheduler其实就是一个轻量的Wrapper,真正负责异步任务执行的是底层的Execution Context实现。对于非异构的实现, 这里的Execution Context一般代表一个Cpu线程或者一组Cpu线程(线程池),最简单的情况是相关的任务被投递到一个线程上来执行。我们会通过Scheduler对相关的Execution Context再包装一次,pipeline组织的过程中将只涉及Scheduler,但Scheduler内部一般都会包含相关Exectuion Context的包装与实现。
未做任何加工的情况,我们能够想象,所有事情都将一口气在Assembly Thread上发生完毕,那如果我们要实现将异步操作调度到工作线程上执行,应该如何实现呢?这里我们直接以libunifex中比较常用的manual_event_loop实现来说明整个实现逻辑:
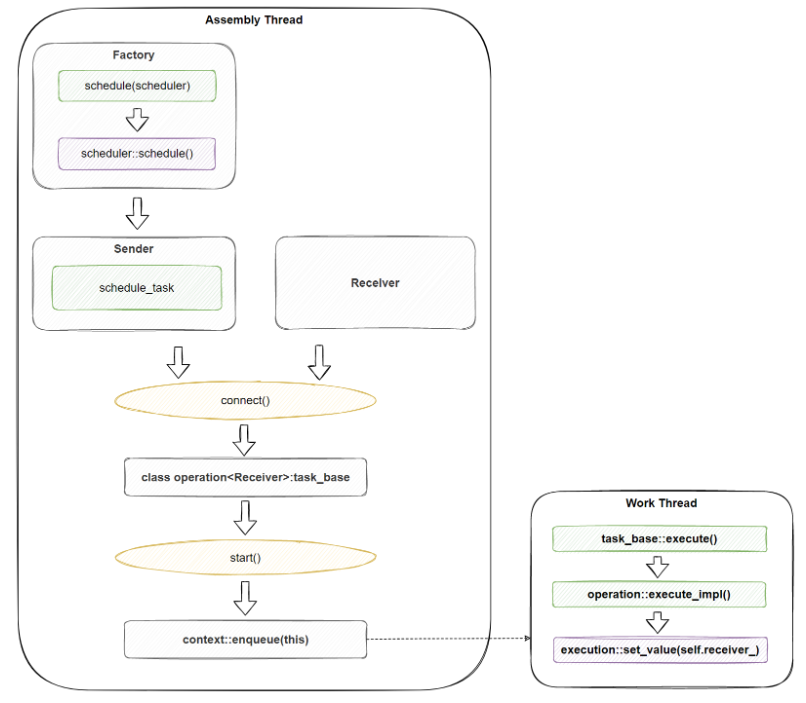
直接看图整个实现还是比较复杂的,但其实最重要的地方只有几处:
context实现-Work Thread本身的工作机制,它应该是能够主动执行自身包含的任务队列的。
与execution桥接-Work Thread提供机制,允许其它线程向自己插入待执行的任务,并且我们需要将相关的任务包装为符合exection设计的形态。
context与物理线程关联-我们最后肯定需要将context的运行与一个具体的物理线程关联起来,这样context才能不断的执行投递到其中的task。做到这几点,整个异步操作的执行就自然的转移到Work Thread了。
下文我们将结合具体的代码实现来分析这两点是怎么达成的。
二、context实现分析
manual_event_loop版
manual_event_loop版的context实现比较简洁。它的默认调度器实现的核心实现位于manual_event_loop.h&与大部分调度器实现类似,它采用context与task的相关抽象与线程是剥离的方式,主要完成两部分的功能:
实现一个标准的任务管理器,有标准的任务加入和执行接口。
完成与execution系统的桥接,这部分主要是由scheduler实现来完成的。
下面我们分开来看一下这两部分的实现:
(一)context与task_base的实现
一个标准的任务管理器在很多地方我们可能都会用到,比如libunifex中的异步任务调度,比如一些定时器的实现。相关的代码实现一般都比较简单,libunifex的实现也同样如此,相关的概览图如下:
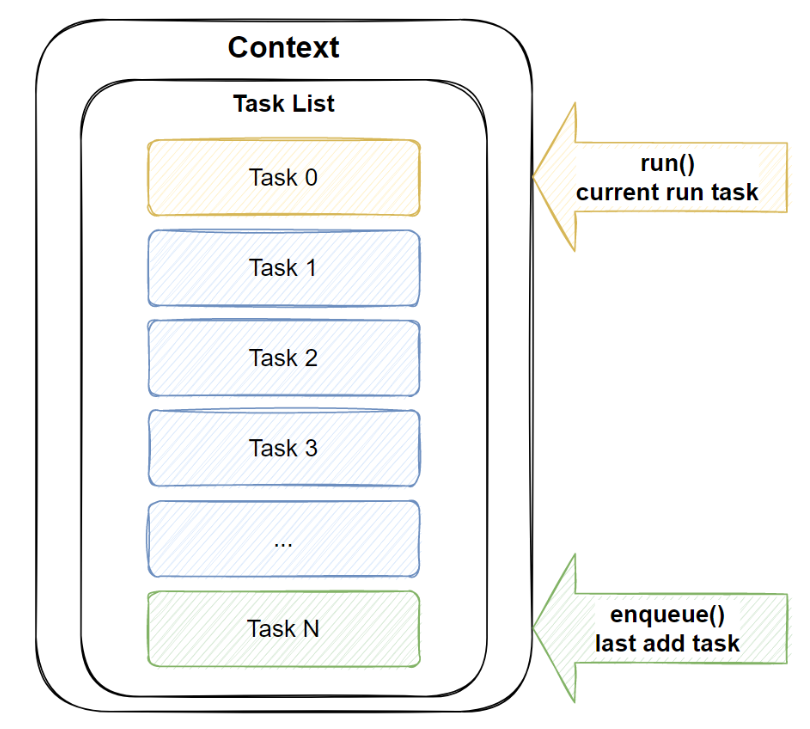
核心代码如下:task_base:
struct manual_event_loop::task_base {using execute_fn = void(task_base*) noexcept;explicit task_base(execute_fn* execute) noexcept: execute_(execute){}void execute() noexcept {this->execute_(this);}task_base* next_ = nullptr;execute_fn* execute_;};
context:
class manual_event_loop::context {void run() {std::unique_lock lock{mutex_};while (true) {while (head_ == nullptr) {if (stop_) return;cv_.wait(lock);}auto* task = head_;head_ = task->next_;if (head_ == nullptr) {tail_ = nullptr;}lock.unlock();task->execute();lock.lock();}}void stop() {std::unique_lock lock{mutex_};stop_ = true;cv_.notify_all();}private:void enqueue(task_base* task) {std::unique_lock lock{mutex_};if (head_ == nullptr) {head_ = task;} else {tail_->next_ = task;}tail_ = task;task->next_ = nullptr;cv_.notify_one();}std::mutex mutex_;std::condition_variable cv_;task_base* head_ = nullptr;task_base* tail_ = nullptr;bool stop_ = false;};
上述利用链表实现了一个FIFO的task队列,然后提供了一个enque()接口用于推送新任务到context,一个run()接口用于执行整个任务队列。核心代码使用了一个std::mutex和std::condition_variable,模拟了一个类似semaphore的作用,这样我们跨线程的执行run(),enque(),核心代码本身就是适配多线程的。代码细节我们不一一展开了,相关的实现直接看代码理解更方便。同时有心的读者可能会注意到,libunifex的任务管理器实现用的是raw pointer的task_base,这样会不会出现memory leak相关的问题呢?这部分的答案我们在下一章节解释。
从上面的代码中可以看到,libunifex的实现比较多的依赖临时命名空间(以'_'打头的命名空间),然后再通过using给出外部的使用名称。所以在代码里我们可能会看到不同临时命名空间下的很多context实现,注意区分好相关的命名空间,同名的context一般都是类同的实现,习惯了理解相关代码也是比较方便的。
三、与execution的桥接
区别于其他的task处理框架,如asio的lambda post模式,execution框架是通过泛型的connect()和start()来完成对sender和receiver的连接和使用的,libunifex关联context&task_base与execution框架其他部分的方式也沿续了这种思路。下面我们通过具体的代码来看libunifex是如何通过对task_base泛型的支持,以及特定的connect() + start()的实现,来完成相关的桥接的。tast_base的泛型实现:我们先来看一下task_base的泛型实现,其实也就是scheduler产生的sender和任意receiver执行connect()操作后产生的OperationState:
template <typename Receiver>class operation final : task_base {public:template <typename Receiver2>explicit type(Receiver2&& receiver, context* loop): task_base(&type::execute_impl), receiver_((Receiver2 &&) receiver), loop_(loop) {}void start() noexcept{loop_->enqueue(this);}private:static void execute_impl(task_base* t) noexcept {auto& self = *static_cast<type*>(t);execution::set_value(std::move(self.receiver_));// ... some code ignore here}Receiver receiver_;context* const loop_;};
可以看到,libunifex很巧妙的实现了一个继承自task_base的operation类,比较重要的是两点:
在该类构造的时候,会将最终处理receiver通知的execute_impl关联为task的execute()的目标函数。
该op类的start()方法,会将自己通过context::enqueue()加入到context的任务队列中等待执行通过这两步,我们完成了execution与一个任务调度器结合的绝大部分工作,当然,还差了connect()相关的处理代码,这部分是由剩下的scheduler_task与scheduler来共同完成的。
此处的context由于最后的using,外部的使用名称是manual_event_loop,这个我们需要注意一下,下文中会直接使用到这个名称。
注意此处内嵌类_op::type的定义方式,先是前置声明了type,后续直接通过class _op::type来定义相关的类,而不是直接在_op类中直接使用内嵌的方式来调用,这对于代码阅读是有利的,避免内嵌类层级化后导致的代码理解成本增加。
scheduler_task与scheduler: 在前文《C++异步:structured concurrency实现解析!》中我们介绍了Sender Factory,schedule()其实也是一个Sender Factory,而它产生的scheduler_task其实就是一个sender,所以它包含两部分sender的实现:
sender traits需要用到的类型定义,如value_types和error_types,这个地方都是void,因为它纯粹就是一个时机控制节点,不会向后续节点传递任何值。
connect()成员函数,可以很明显的看到此处只是简单的返回前面我们介绍的继承自task_base的operation<Receiver>。
scheduler_task是scheduler的内嵌类,此处为了方便阅读我们将scheduler_task外置:
class schedule_task {public:template </*...*/>using value_types = /*unspecified*/;template </*...*/>using error_types = Variant<>;static constexpr bool sends_done = true;template <typename Receiver>operation<Receiver> connect(Receiver&& receiver) const {return operation<Receiver>{(Receiver &&) receiver, loop_};}private:friend scheduler;explicit schedule_task(context* loop) noexcept: loop_(loop){}context* const loop_;};
class scheduler {explicit scheduler(context* loop) noexcept : loop_(loop) {}public:schedule_task schedule() const noexcept {return schedule_task{loop_};}friend bool operator==(scheduler a, scheduler b) noexcept {return a.loop_ == b.loop_;}friend bool operator!=(scheduler a, scheduler b) noexcept {return a.loop_ != b.loop_;}private:context* loop_;};
另外回到上一节中我们提到的问题,context的整个实现是使用的raw pointer的task,并没有对task的生命周期做管理,而此处构造的task对象,也是栈上的值类型,这是因为整个execution机制,都是依赖于前面提到过的operation state本身来保证生命周期的,对于此处来说,connect()的时候产生的栈对象operation<Receiver>,结束信号set_value调用完成前,也就是我们真正执行到operation<Receiver>::execute()的时候,它都是有效的。
这也就巧妙的保证了,虽然我们context的实现使用的是raw pointer,并没有对task的生命周期进行管理,但它的生命周期也会是符合预期的。
利用operation state进行生命周期管理,合理安排临时对象,也是execution本身的一大特色,及区别于其他异步库如asio的部分,这部分大家可以多与其他实现做横向对比,体会其中的优缺点,更容易把握到库本身所偏向的表达方法。
四、context与物理线程关联
前面我们也提到过,context&task的封装本身是不包含线程的,所以业务层使用, 还需要wrapper一下, 比如single_thread_context的实现:
class single_thread_context {manual_event_loop loop_;std::thread thread_;public:context() : loop_(), thread_([this] { loop_.run(); }) {}~context() {loop_.stop();thread_.join();}auto get_scheduler() noexcept {return loop_.get_scheduler();}std::thread::id get_thread_id() const noexcept {return thread_.get_id();}};
整体实现本身是对前面说的manual_event_loop的一个封装, single_thread_context创建时,会自动创建一个线程对象并绑定manual_event_loop::run(),自动开启任务执行循环。下面的例子子我们可以看到对single_thread_context的使用。
五、执行过程简述
我们结合一个简单的示例代码来看一下整体的执行过程:
single_thread_context tcontext;int count = 0;| then([&] { ++count; }) | sync_wait();
假设我们在manual_event_loop.hpp中下面的函数中断点:
template <typename Receiver>operation<Receiver> connect(Receiver&& receiver) const {return operation<Receiver>{(Receiver &&) receiver, loop_};}
也就是构造manual_event_loop::operation对象的地方(其实它就是一个context::task了),我们容易分析到,loop就是我们传入的context,后续start()的时候我们会把operation推送到它的task队列中去等待执行。此处模板嵌套的比较深,我们就不给出具体的调用栈了。我们可以来看下此处的receiver的类型:
execution::_then::_receiver<Reciever = execution::_sync_wait::_receiver<execution::_unit::unit>::type,Func =`Execution_TestAllocatePipe_Test::TestBody'::`2'::<lambda_1>>::type &&
结合上面的示例,我们比较容易分析出整体的类型大致形成的过程,这里不详细赘述了。有了具体的operation,通过前面的分析我们知道,start()的时候,相应的task会被加入到context的任务队列中等待执行,最后就成功的调用到了then()中包含的lambda,驱动count计数+1,因为sync_wait()本身是等待执行的,所以栈上声明的tcontext,count都能够正确的起作用。需要注意的是,如果不是同步等待的情况,这里的用法肯定是不适用的。
六、context的其他使用
除了标准的task执行支持,以及与execution的结合,libunifex中还有一种context的特殊使用,以一个独立的context,用作sync_wait()实现中的异步等待,这个作用类似我们经常在其他异步库看到的fence,libunifex这个地方偷了个懒,直接复用了context来做相关的实现。为了方便大家理解,这里我们沿用前面的示例,直接给出VS的Parallel Stacks执行情况,来方便大家直观感受相关实现的具体执行情况:
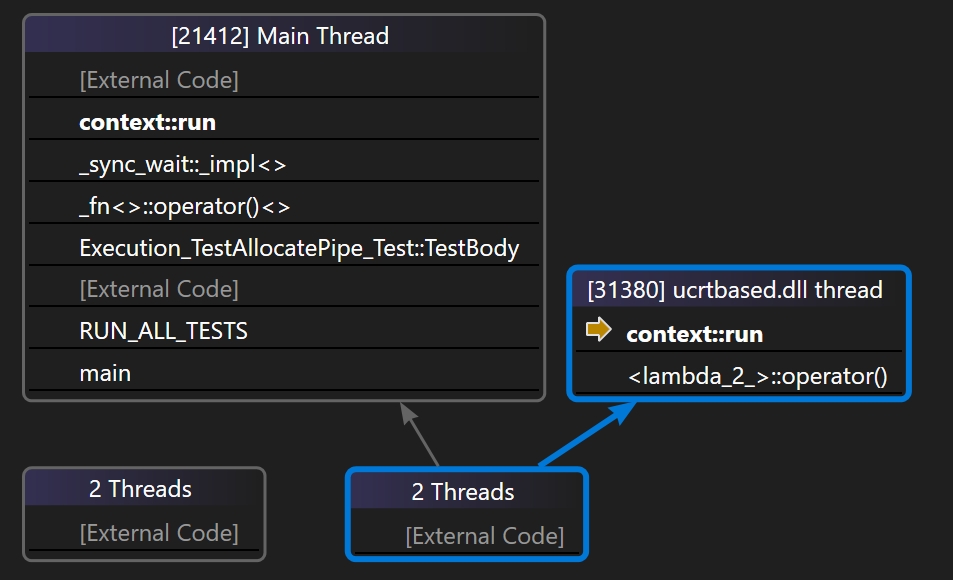
如上所示,这种sync_wait的方式,导致主线程在异步任务执行完成前,会无休眠的利用另外一个context::run空跑一个while(true)循环,直到对应task执行完成最终调用set_value(),才通过signal_complete()调用了主线程上这个context的stop()函数,退出这个死循环。这个实现还是有点简单直白了,实际业务使用,这种实现容易带来问题。当然,相关的改良方法我们后面会提到,这里不再进行展开了。
七、transfer-如何在执行中切换scheduler
除了前面介绍的整个pipeline在单个scheduler执行的情况,我们肯定容易想到,业务场景中比较容易出现,pipeline的不同部分需要工作在不同的scheduler上,这点是如何做到的呢?这部分我们先搁置一下,在后续的文章中将具体介绍相关的实现,libunifex本身不包含相关的实现,感觉可能原因是这部分与scheduler本身的实现比较强相关,而我们知道这块libunifex并没有做得特别好。
八、其他的scheduler与context实现
除了上面介绍的manual_event_loop,以及它的带线程的single_thread_context封装,libunifex还包含其他调度器的实现,相关的用途和实现这里简单列出,感兴趣的读者可以自行翻阅代码理解,相关的实现除了专有功能的实现,主体的封装方式和技巧都比较类同,理解了manual_event_loop的实现,再来看其他的实现,不会有太多的障碍。感觉大部分的实现跟实际业务的预期都会存在一定的距离,这里不详细分析了。不同的scheduler实现如下:
single_thread_context
前文已经介绍过了,创建一个后台线程对发起到它之上的任务进行执行的调度器。
inline_scheduler
其实就是不调度,相关的operation_state::start()时直接执行set_value,不存在task加入任务队列等待执行的过程。
trampoline_scheduler
限制单次最大执行数的调度器,感觉这应该作为其他调度器的一种可选功能,而不是作为一个单独的调度器来实现。
new_thread_context
遇到新的调度就尝试创建一条新线程去执行相关任务的调度器。
static_thread_pool
可以简单看成single_thread_context的线程池版本,其实可以直接考虑复用manual_event_loop的实现,不过这个地方是直接独立代码实现的,代码大量类同。
thread_unsafe_event_loop
区别于manual_event_loop,非线程安全的一版实现。
timed_single_thread_context
支持schedule_at()和schedule_after()这两个时间调度功能的调度器实现。
linux::io_uring_context
Linux io_uring的专有调度器实现,io_uring是linux下比较完整的操作系统级Async IO实现(对标Windows的完成端口)。
win::windows_thread_pool
利用Windows系统支持的线程池和Timer实现的Windows专用调度器。
win::low_latency_iocp_context
与linux::io_uring一样,利用iocp实现的调度器。
九、总结
从scheduler这部分来说,libunifex本身的实现也不是尽善尽美,贴合实际业务需求的,这可能本身与大部分异步库的抽象理念也有关,一般会剥离掉线程调度相关的那部分代码,各类业务差异巨大,都会有自己习惯的任务调度方式,这部分更多的意义感觉是让我们理解应该如何桥接一个自有的调度器与execution框架,而特定的调度器,更应该从业务侧出发,根据业务需求合理规划设计实现了。
参考资料:
1.libunifex源码库
作者简介

沈芳
腾讯后台开发工程师
IEG研发效能部开发人员,毕业于华中科技大学。目前负责CrossEngine Server的开发工作,对GamePlay技术比较感兴趣。
推荐阅读

温馨提示:因公众号平台更改了推送规则,公众号推送的文章文末需要点一下“赞”和“在看”,新的文章才会第一时间出现在你的订阅列表里噢~