 新机器视觉
新机器视觉




点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达

AI数钢筋
在社会智能化的发展趋势之下,越来越多的传统行业开始向着数字化的方向转型,而建筑行业也正经历着通过人工智能技术实现的改革。
钢筋是建筑业的重要材料,庞大的数量、工地现场环境复杂以及人工点验错漏等现实因素为钢筋点验工作制造了难度,那么如何才能快速且准确地完成对于整个建筑施工过程极为重要的钢筋点验工作环节呢?今天就带大家了解一下“AI数钢筋”——通过人工智能技术实现钢筋数量统计。
1
问题背景
钢筋数量统计是钢材生产、销售过程及建筑施工过程中的重要环节。目前,工地现场是采用人工计数的方式对进场的车辆装载的钢筋进行计数,验收人员需要对车上的钢筋进行现场人工点根,在对钢筋进行打捆后,通过不同颜色的标记来区分钢筋是否计数,在确认数量后钢筋车才能完成进场卸货,如图中所示:


这种人工计数的方式不仅浪费大量的时间和精力、效率低下,并且工人长时间高强度的工作使其视觉和大脑很容易出现疲劳,导致计数误差大大增加,人工计数已经不能满足钢筋生产厂家自动化生产和工地现场物料盘点精准性的需求,这种现状促使钢筋数量统计向着智能化方向发展。
所谓“AI数钢筋”就是,通过多目标检测机器视觉方法以实现钢筋数量智能统计,达到提高劳动效率和钢筋数量统计精确性的效果。目标检测算法通过与摄像头结合,可以实现自动钢筋计数,再结合人工修改少量误检的方式,可以智能、高效地完成钢筋计数任务。
2
算法介绍
2.1 目标检测介绍
首先,让我们一起了解一下什么是“目标检测”。
目标检测是对图像分类任务的进一步加深,目标检测不仅要识别出图片中各种类别的目标,还要将目标的位置找出来用矩形框框住。

目标检测结果如上图所示,将需要检测的目标检测出来并用边界框框出来,同时在框子上面显示出该目标属于该分类的一个得分情况。
2.2 目标检测算法的基本流程
目标检测实际上是要同时解决定位和识别两个问题。传统目标检测算法的基本流程是,首先给定待检测图片,对其进行候选框提取,候选框的提取是通过滑动窗口的方式进行的;再对每个窗口的局部信息进行特征提取;然后对候选区域提取出的特征进行分类判定,判断当前窗口中的对象是目标还是背景;最后采用非极大值抑制(Non-Maximum Suppression,NMS)方法进行筛选,去除重复窗口,找出最佳目标检测位置。
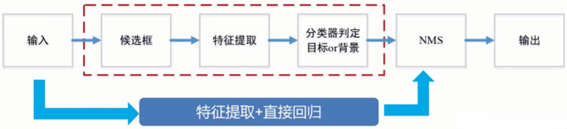
2.3 算法选择
本次钢筋计数任务,将选择单阶段目标检测YOLO系列算法来完成。YOLO系列算法是目前使用最多的目标检测算法,它最大的特点就是检测速度快,并且现在检测精度(即mAP)也逐步提高,因而成为时下最热门的目标检测算法之一。YOLO系列算法一共有5个版本,其中YOLO v1到v3是由同一个作者Joseph设计的,YOLO v4到v5则由其他作者设计,目前YOLO v1到YOLO v4已有相关论文和算法结构设计,而YOLO v5仅有算法结构设计,尚无论文发表,为此我们选择这一较新的YOLO v5算法作为本次钢筋计数算法研究的对象。

YOLO算法是将目标检测问题转化为回归问题,使用回归的思想,对给定输入图像,直接在图像的多个位置上回归出这个位置的目标边框以及目标类别。给定一个输入图像,将其划分为S*S的网格,如果某目标的中心落于网格中,则该网格负责预测该目标,对于每一个网格,预测B个边界框及边界框的置信度,包含边界框含有目标的可能性大小和边界框的准确性,此外对于每个网格还需预测在多个类别上的概率。在完成目标窗口的预测之后,根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可,整个过程非常简单,不需要中间的候选框生成网络,直接回归便完成了位置和类别的判定。下图是YOLO v5算法基本框架:
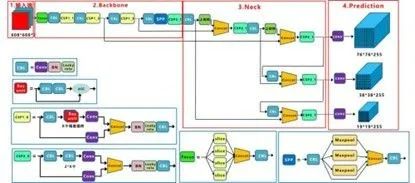
由上图可知,YOLO v5主要由输入端、Backbone、Neck以及Prediction四部分组成。其中各部分含义分别为:
Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
Prediction(输出端):对图像特征进行预测,生成边界框和并预测类别。
YOLO v5各组成部分包括的基础组件有:
CBL:由Conv+BN+Leaky_relu激活函数组成
Res unit:借鉴ResNet网络中的残差结构,用来构建深层网络
CSP1_X:借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成
CSP2_X:借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成
Focus:首先将多个slice结果Concat起来,然后将其送入CBL模块中
SPP:采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合
YOLO v5各组成部分详细介绍
(1)
输入端
YOLO v5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
1
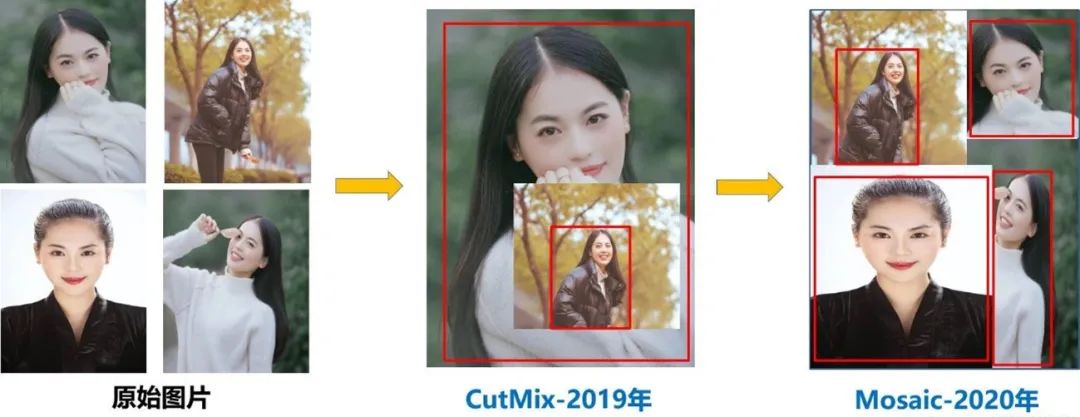
Mosaic数据增强
Mosaic数据增强利用四张图片,并且按照随机缩放、随机裁剪和随机排布的方式对四张图片进行拼接,每一张图片都有其对应的框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。该方法极大地丰富了检测物体的背景,且在标准化BN计算的时候一下子计算四张图片的数据,所以本身对batch size不是很依赖。
2
自适应锚框计算
在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框是比较关键的一环。
在YOLO v3和YOLO v4中,训练不同的数据集,都是通过单独的程序运行来获得初始锚点框。而在YOLO v5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,指令为:
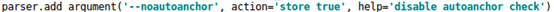
3
自适应图片缩放
在目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。而原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLO v5的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。具体的实现步骤如下所述:
① 根据原始图片大小以及输入到网络的图片大小计算缩放比例
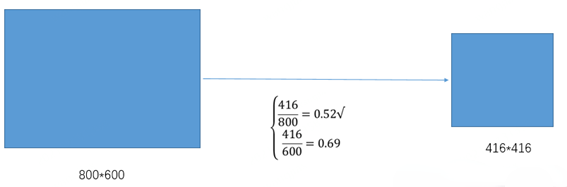
②根据原始图片大小与缩放比例计算缩放后的图片大小

③计算黑边填充数值

其中,416表示YOLO v5网络所要求的图片宽度,312表示缩放后图片的宽度。首先执行相减操作来获得需要填充的黑边长度104;然后对该数值执行取余操作,即104%32=8,使用32是因为整个YOLOv5网络执行了5次下采样操作。最后对该数值除以2,也就是将填充的区域分散到两边。这样将416*416大小的图片缩小到416*320大小,因而极大地提升了算法的推理速度。
(2)
Backone 网络
1
Focus结构
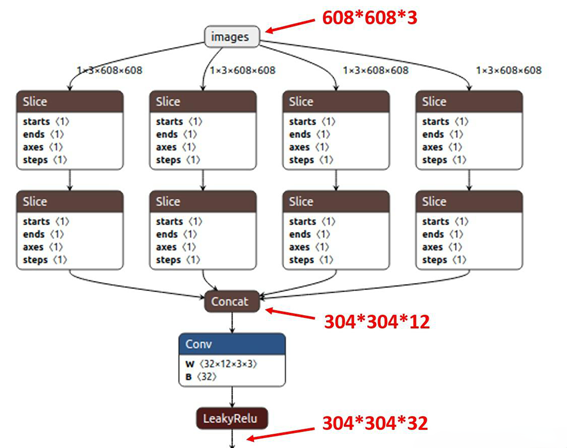
Focus对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,因此将W、H信息就集中到通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。如下图所示,原始输入图片大小为608*608*3,经过Slice与Concat操作之后输出一个304*304*12的特征映射;接着经过一个通道个数为32的Conv层,输出一个304*304*32大小的特征映射。
2
CSP结构
CSPNet主要是将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。在分类问题中,使用CSPNet可以降低计算量,但是准确率提升很小;在目标检测问题中,使用CSPNet作为Backbone带来的提升比较大,可以有效增强CNN的学习能力,同时也降低了计算量。YOLO v5设计了两种CSP结构,CSP1_X结构应用于Backbone网络中,CSP2_X结构应用于Neck网络中。
(3)
Neck网络
在YOLO v4中开始使用FPN-PAN。其结构如下图所示,FPN层自顶向下传达强语义特征,而PAN塔自底向上传达定位特征。
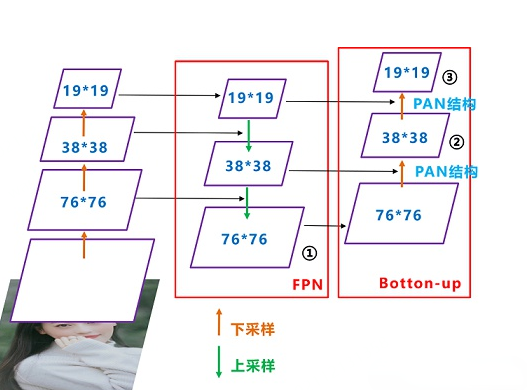
YOLO v5的Neck仍采用了FPN+PAN结构,但是在它的基础上做了一些改进操作,YOLO v4的Neck结构中,采用的都是普通的卷积操作,而YOLO v5的Neck中,采用CSPNet设计的CSP2结构,从而加强了网络特征融合能力。
(4)
输出端
YOLO v5采用CIOU_LOSS 作为bounding box 的损失函数,分类分支采用的loss是BCE,conf分支也是BCE。
YOLO v5中最有亮点的改变是对正样本的定义。在YOLO v3中,其正样本区域也就是anchor匹配策略非常粗暴:保证每个gt bbox一定有一个唯一的anchor进行对应,匹配规则就是IOU最大,并且某个gt一定不可能在三个预测层的某几层上同时进行匹配。然而,我们从FCOS等论文中了解到,增加高质量的正样本anchor能够加速模型收敛并提高召回。因此,YOLO v5对此做出了改进,提出匹配规则:
采用shape匹配规则,分别将ground truth的宽高与anchor的宽高求比值,如果宽高比例小于设定阈值,则说明该GT和anchor匹配,将该anchor认定为正样本。否则,该anchor被滤掉,不参与bbox与分类计算。
将GT的中心最邻近网格也作为正样本anchor的参考点。因此,bbox的xy回归分支的取值范围不再是0-1,而是-0.5-1.5(0.5是网格中心偏移),因为跨网格预测了
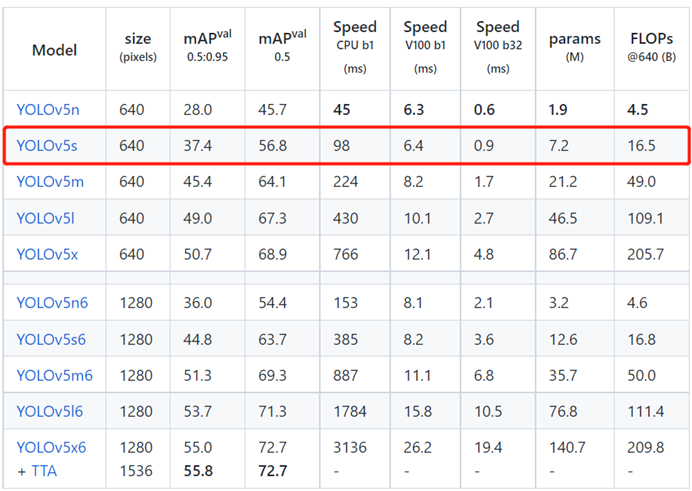
YOLO v5算法目前根据网络大小分为5n、5s、5m、5l、5x,具体参数量大小、单帧、检测速度和mAP如下图所示。

3
训练模型
3.1 数据集选择
我们选择公开钢筋计数数据集进行模型训练,可以从以下网址中获取数据集进行测试。
https://www.datafountain.cn/competitions/332/datasets
在上述数据集中,钢筋数据来自现场手机采集。钢筋车辆进库时,使用手机拍摄成捆钢筋的截面(一般保证较小倾角,尽量垂直于钢筋截面拍摄)。数据会包含直径从12mm-32mm等不同规格的钢筋图片。数据集中用于训练的图像集合共250张,用于测试的图像集合共200张。
由于选择的数据集规模较小且仅有一类检测目标(钢筋),为降低模型训练难度,防止模型出现过拟合,所以算法模型选择较小的yolov5s模型。如果选择不同的数据集,也可根据所选数据集的实际情况来选择算法模型。
3.2 模型训练
首先在以下网址获取YOLO v5算法的源码:
https://github.com/ultralytics/yolov5
其中所包含的项目文件有:
data:主要是存放一些超参数的配置文件以及官方提供测试的图片。
models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的五个不同的版本,分别为是5n、5s、5m、5l、5x。
utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
weights:放置训练好的权重参数。
detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
train.py:训练自己的数据集的函数。
test.py:测试训练的结果的函数。
requirements.txt:yolov5项目的环境依赖包
YOLO v5各组成部分详细介绍
接下来就要进行模型训练的具体操作,训练主要包括环境搭建、数据集准备及修改数据集配置、修改模型配置参数、下载预训练模型、开始训练以及模型测试这几个步骤。接下来依次对上述步骤展开介绍。
(1)
环境搭建
我们需要创建一个虚拟环境,打开conda powershell prompt创建一个用于训练的虚拟环境:
conda create -n yolov5 python==3.8然后激活虚拟环境安装所需模块(注意安装之前需要切换工作路径至yolov5文件夹)
python -m pip install -r requirements.txt -i http://pypi.douban.com/simple/ --trusted-host=pypi.douban.com/simple如果没有安装cuda默认安装pytorch-cpu版,如果有gpu可以安装pytorch-gpu版。
(2)
数据集准备及修改数据集配置
首先将下载好的数据集分类并按如下方式存储:

然后对数据集配置进行修改,修改data目录下的相应的yaml文件。找到目录下的coco.yaml文件,将该文件复制一份,将复制的文件重命名。
打开这个文件夹修改其中的参数,修改结果如下图所示:

其中第一个框的位置填写训练集测试集和验证集的目录地址,第二个框的位置填写检测目标类别数,第三个框填写待检测类别。
(3)
修改模型配置参数
由于我们最后选择yolov5s这个模型训练,并且使用官方yolov5s.pt预训练权重参数进行训练,所以需要修改模型配置文件。和上述修改data目录下的yaml文件一样,最好将yolov5s.yaml文件复制一份,然后将其重命名。
然后对重命名文件进行修改,修改第一行检测目标类别数。

(4)
下载预训练模型
我们需要在官网下载所需预训练模型,即在预训练模型地址(https://github.com/ultralytics/)中选择所需要的模型下载即可,这里我们选择下载yolov5s.pt。
模型下载完成后,将模型文件xx.pt复制到yolov5文件夹下。
(5)
开始训练
在Yolov5文件夹下打开终端输入以下命令:
Python train.py --weights yolov5s.pt --data data/gangjin.yaml --workers 1 --batch-size 8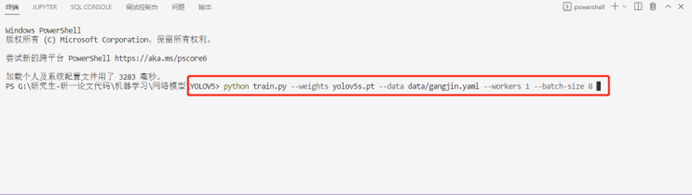
至此,模型训练正式开始。
(6)
模型测试
在模型训练完成后,将runs/exp/weights下的模型(best.pt)复制到yolov5文件夹下。

然后开始进行模型测试:
python detect.py --weights best.pt --source ../datasets/gangjin/images/val --save-txt其中,--weights best.pt是训练好的模型路径,--source:是测试的数据路径。测试结果保存在runs/detect/exp文件夹下。
4
测试结果及问题分析
4.1 测试结果
本算法的输入为较为清晰的成捆钢筋图片,例如输入以下图片:

算法的输出结果为result.txt文件与预测结果图,其中result.txt文件中会显示图片中每个检测框的位置、类别及置信度,并给出检测框的总个数,从而实现了钢筋自动计数。预测结果图如下:

从以上测试结果可以看出,YOLO v5算法对于该场景中的钢筋计数具有很好的准确性,并且有较大的置信度。
对更多的图片场景进行钢筋计数,并将输入的实际位置与识别出的效果图进行对比,观察YOLO v5算法对于该场景的计数效果。


上图中,左图为输入成捆钢筋,右图为数识别出的效果图,方框上数字为置信度。从以上测试结果可以看出,YOLO v5算法对于该场景中的钢筋计数同样具有很好的准确性以及较大的置信度。
4.2 问题分析
当然YOLO v5算法并非十全十美,它在钢筋检测中也存在一定的问题:
算法存在误判,将其他物体误判为钢筋头:

重复检测,一个钢筋头被多个检测框标注:

5
总结
以上就是对于数钢筋问题的介绍,主要从问题背景、算法介绍和训练模型三部分展开。首先简述了数钢筋问题的基本背景,然后介绍了目标检测算法的算法流程和选取的YOLO v5算法的基本知识,最后介绍了模型训练步骤,并选取一定的数据集,采用YOLO v5算法对输入的图像进行目标检测及计数。

大家对于“AI数钢筋”问题是不是有更多的了解了呢?
文案:张为(武汉理工大学交通与物流工程学院研究生一年级)
李诗颖(华中科技大学管理学院本科四年级)
排版:李诗颖(华中科技大学管理学院本科四年级)
指导老师:赵强伟老师(华中科技大学管理学院)
秦虎老师(华中科技大学管理学院)
如对文中内容有疑问,欢迎交流。PS:部分资源来自网络。
如有需求,可以联系:
秦虎老师(华中科技大学管理学院:professor.qin@qq.com)
赵强伟老师(华中科技大学管理学院:zhaoqiangwei2002@163.com)
张为(武汉理工大学交通与物流工程学院研一:921525492@qq.com)
李诗颖(华中科技大学管理学院本科四年级:2213499378@qq.com)
本文仅做学术分享,如有侵权,请联系删文。
—THE END—


