
OpenKruise 源码分析之 ContainerRecreateRequest
OpenKruise 是基于 CRD 的拓展,包含了很多应用工作负载和运维增强能力,本系列文章会从源码和底层原理上解读各个组件,以帮助大家更好地使用和理解 OpenKruise。让我们开始 OpenKruise 的源码之旅吧!
前言
在上一篇文章[1]中我们解读了 OpenKruise 原地升级的原理和相关代码,在此基础上我们来研究一个基于原地升级能力的组件 - ContainerRecreateRequest[2]。ContainerRecreateRequest(下文简称 CRR) 能够重建 Pod 中一个或多个容器。该功能和 Kruise 提供的原地升级类似,当一个容器重建的时候,Pod 中的其他容器还保持正常运行。重建完成后,Pod 中除了该容器的 restartCount 增加以外不会有什么其他变化。如果挂载了 volume mount 挂载卷,卷中的数据不会丢失也不需要重新挂载。这个功能实现了运维容器与业务容器的管理分离,比如一个 Pod 中会有主容器中运行核心业务,sidecar 中运行运维容器,比如日志收集等.当业务容器需要重启的时候,传统的更新方式会让整个 Pod 重启从而导致运维容器无故被重启从而中断服务,而使用 ContainerRecreateRequest 可以实现只让特定的容器重启,高效的同时更加安全。
今天就让我们从源码的角度来看一下 ContainerRecreateRequest 的实现原理。
源码解读
我们先来看一下整个 CRR 的代码流程概览,可以看到整个过程主要有三个组件参与,包括 CRR 的 admission webhook, controller manager,以及我们上一篇就提到过的原地升级中的重要组件 - kruise-daemon 中的 crr daemon controller。
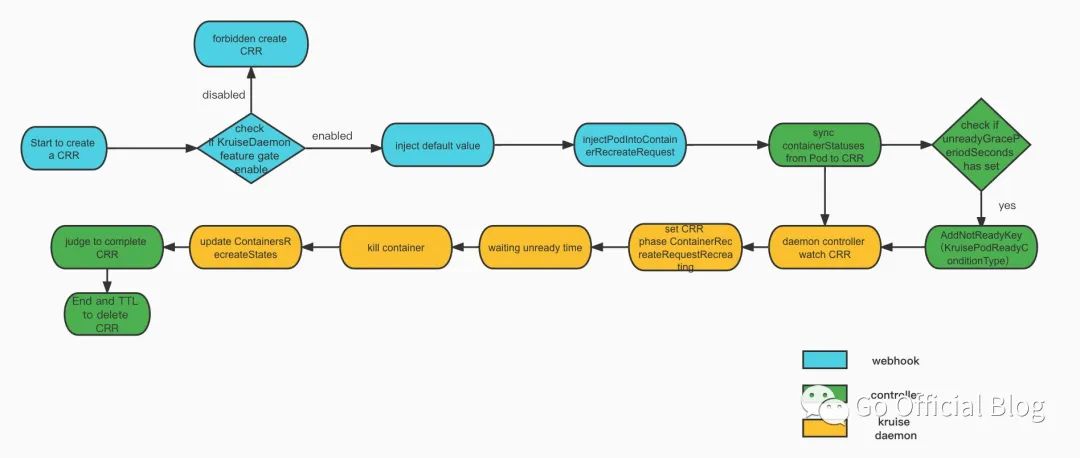
然后我们再逐步拆开讲解每一步的内容。
1. create CRR
先看一下 CRR 这个自定义资源的 schema 定义:
apiVersion: apps.kruise.io/v1alpha1
kind: ContainerRecreateRequest
metadata:
namespace: pod-namespace
name: xxx
spec:
podName: pod-name
containers: # 要重建的容器名字列表,至少要有 1 个
- name: app
- name: sidecar
strategy:
failurePolicy: Fail # 'Fail' 或 'Ignore',表示一旦有某个容器停止或重建失败, CRR 立即结束
orderedRecreate: false # 'true' 表示要等前一个容器重建完成了,再开始重建下一个
terminationGracePeriodSeconds: 30 # 等待容器优雅退出的时间,不填默认用 Pod 中定义的
unreadyGracePeriodSeconds: 3 # 在重建之前先把 Pod 设为 not ready,并等待这段时间后再开始执行重建
minStartedSeconds: 10 # 重建后新容器至少保持运行这段时间,才认为该容器重建成功
activeDeadlineSeconds: 300 # 如果 CRR 执行超过这个时间,则直接标记为结束(未结束的容器标记为失败)
ttlSecondsAfterFinished: 1800 # CRR 结束后,过了这段时间自动被删除掉
然后开始走读代码流程。
1.1 检查 feature-gate
当我们创建一个 CRR 的时候,会最先经过 adminssion webhook,webhook 中会最先检查当前 feature gates 中是否开启了 kruise-daemon ,因为这个功能依赖于 kruise-daemon 组件来停止 Pod 容器,如果 KruiseDaemon feature-gate 被关闭了,ContainerRecreateRequest 也将无法使用。
func (h *ContainerRecreateRequestHandler) Handle(ctx context.Context, req admission.Request) admission.Response {
if !utilfeature.DefaultFeatureGate.Enabled(features.KruiseDaemon) {
return admission.Errored(http.StatusForbidden, fmt.Errorf("feature-gate %s is not enabled", features.KruiseDaemon))
}
...
}
1.2 注入默认值并检查 Pod
创建 CRR 的时候要为其注入一些特定的标签,为后面控制启动容器的流程做准备,比如打上 ContainerRecreateRequestPodNameKey,ContainerRecreateRequestActiveKey的标签:
obj.Labels[appsv1alpha1.ContainerRecreateRequestPodNameKey] = obj.Spec.PodName
obj.Labels[appsv1alpha1.ContainerRecreateRequestActiveKey] = "true"
检查当前处理的 Pod 是否符合更新条件,比如 Pod 是否是 active 的:
func IsPodActive(p *v1.Pod) bool {
return v1.PodSucceeded != p.Status.Phase &&
v1.PodFailed != p.Status.Phase &&
p.DeletionTimestamp == nil
}
以及 Pod 是否已经完成调度,如果未完成调度的话就无法完成原地重启(无法使用部署到节点上的 kruise-daemon):
if !kubecontroller.IsPodActive(pod) {
return admission.Errored(http.StatusBadRequest, fmt.Errorf("not allowed to recreate containers in an inactive Pod"))
} else if pod.Spec.NodeName == "" {
return admission.Errored(http.StatusBadRequest, fmt.Errorf("not allowed to recreate containers in a pending Pod"))
}
1.3 将 Pod 中的信息注入到 CRR
CRR 的运行需要获取 Pod 的信息,比如获取 Pod 中的 Lifecycle.PreStop 让 kruise-daemon 执行 preStop hook 后把容器停掉,获取指定容器的 containerID 来判断重启后 containerID 的变化等。
err = injectPodIntoContainerRecreateRequest(obj, pod)
if err != nil {
return admission.Errored(http.StatusBadRequest, err)
}
...
if podContainer.Lifecycle != nil && podContainer.Lifecycle.PreStop != nil {
c.PreStop = &appsv1alpha1.ProbeHandler{
Exec: podContainer.Lifecycle.PreStop.Exec,
HTTPGet: podContainer.Lifecycle.PreStop.HTTPGet,
TCPSocket: podContainer.Lifecycle.PreStop.TCPSocket,
}
}
......
2. CRR controller
创建 CRR 并为其注入相关信息后,CRR 的 controller manager 接管 CRR 的更新。
2.1 同步 container status
CRR 的 status 中包含所要重启的 container 的相关状态信息:
type ContainerRecreateRequestStatus struct {
// Phase of this ContainerRecreateRequest, e.g. Pending, Recreating, Completed
Phase ContainerRecreateRequestPhase `json:"phase"`
// Represents time when the ContainerRecreateRequest was completed. It is not guaranteed to
// be set in happens-before order across separate operations.
// It is represented in RFC3339 form and is in UTC.
CompletionTime *metav1.Time `json:"completionTime,omitempty"`
// A human readable message indicating details about this ContainerRecreateRequest.
Message string `json:"message,omitempty"`
// ContainerRecreateStates contains the recreation states of the containers.
ContainerRecreateStates []ContainerRecreateRequestContainerRecreateState `json:"containerRecreateStates,omitempty"`
}
type ContainerRecreateRequestContainerRecreateState struct {
// Name of the container.
Name string `json:"name"`
// Phase indicates the recreation phase of the container.
Phase ContainerRecreateRequestPhase `json:"phase"`
// A human readable message indicating details about this state.
Message string `json:"message,omitempty"`
}
CRR controller 不断更新 container 的重启信息到 status 中。
func (r *ReconcileContainerRecreateRequest) syncContainerStatuses(crr *appsv1alpha1.ContainerRecreateRequest, pod *v1.Pod) error {
...
}
controller 同步 container status 的逻辑非常重要,在这里笔者曾经遇到一个诡异的问题,就是创建了好几个 CRR 后,其中几个 CRR 一直卡在 Recreating 的状态,即使 container 已经重启完成或者 TTL 到期也不会发生变化,详情可以见这个 issue[3]。原因就是同步 container status 的逻辑跟时钟同步有关:
containerStatus := util.GetContainerStatus(c.Name, pod)
if containerStatus == nil {
klog.Warningf("Not found %s container in Pod Status for CRR %s/%s", c.Name, crr.Namespace, crr.Name)
continue
} else if containerStatus.State.Running == nil || containerStatus.State.Running.StartedAt.Before(&crr.CreationTimestamp) {
// 只有 container 的创建时间晚于 crr 的创建时间,才认为 crr 重启了 container,假如此时 CRR 所处节点或者 Pod 所在节点的时钟发生漂移,那有可能出现 container 创建的时间早于 crr 创建时间,即使该 container 是由 crr 控制重启。
continue
}
...
经过排查后发现确实是好多 k8s Node 的 NTP server 出现问题导致时钟漂移,再加上上述的逻辑,就不难解释为何 CRR 会卡住不动了。
2.2 make pod not ready
CRR 在重启 container 之前会给 Pod 注入一个 v1.PodConditionType - KruisePodReadyConditionType 并置为 false, 使 Pod 进入 not ready 状态,从 service 的 Endpoint 上摘掉流量。
condition := GetReadinessCondition(newPod) // 获取 KruisePodReadyConditionType condition
if condition == nil { // 如果没有设置,就新建一个
_, messages := addMessage("", msg)
newPod.Status.Conditions = append(newPod.Status.Conditions, v1.PodCondition{
Type: appspub.KruisePodReadyConditionType,
Message: messages.dump(),
LastTransitionTime: metav1.Now(),
})
} else {// 如果存在该 condition,就置为 false
changed, messages := addMessage(condition.Message, msg)
if !changed {
return nil
}
condition.Status = v1.ConditionFalse
condition.Message = messages.dump()
condition.LastTransitionTime = metav1.Now()
}
3. kruise daemon controller
CRR kruise daemon controller 会监听 CRR 资源的 create, update, delete 事件,然后在 manage 函数中更新 CRR。
3.1 watch CRR
CRR controller 将 update 和 create 事件都加入到 process 队列中,等待处理。
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
crr, ok := obj.(*appsv1alpha1.ContainerRecreateRequest)
if ok {
enqueue(queue, crr)
}
},
UpdateFunc: func(oldObj, newObj interface{}) {
crr, ok := newObj.(*appsv1alpha1.ContainerRecreateRequest)
if ok {
enqueue(queue, crr)
}
},
DeleteFunc: func(obj interface{}) {
crr, ok := obj.(*appsv1alpha1.ContainerRecreateRequest)
if ok {
resourceVersionExpectation.Delete(crr)
}
},
})
3.2 CRR phase to recreating
daemon controller 的代码入口处先把 CRR 的 phase 设置为 ContainerRecreateRequestRecreating
// once first update its phase to recreating
if crr.Status.Phase != appsv1alpha1.ContainerRecreateRequestRecreating {
return c.updateCRRPhase(crr, appsv1alpha1.ContainerRecreateRequestRecreating)
}
3.3 wait for unready grace period
CRR 中的 unreadyGracePeriodSeconds 表示在 2.2 步骤中将 Pod 设置为 not ready 后等待多久再执行 restart container。
// crr_daemon_controller.go
leftTime := time.Duration(*crr.Spec.Strategy.UnreadyGracePeriodSeconds)*time.Second - time.Since(unreadyTime)
if leftTime > 0 {
klog.Infof("CRR %s/%s is waiting for unready grace period %v left time.", crr.Namespace, crr.Name, leftTime)
c.queue.AddAfter(crr.Namespace+"/"+crr.Spec.PodName, leftTime+100*time.Millisecond)
return nil
}
3.4 KillContainer
kruise-daemon 会执行 preStop hook 后把容器停掉,然后 kubelet 感知到容器退出,则会新建一个容器并启动。最后 kruise-daemon 看到新容器已经启动成功超过 minStartedSeconds 时间后,会上报这个容器的 phase 状态为 Succeeded。
// crr_daemon_controller.go
err := runtimeManager.KillContainer(pod, kubeContainerStatus.ID, state.Name, msg, nil)
3.5 更新 CRRContainerRecreateStates
不断更新 CRR status 中关于 container 的状态信息 - containerRecreateStates。
c.patchCRRContainerRecreateStates(crr, newCRRContainerRecreateStates)
4. 完成 CRR
4.1 CRR 置为 completed
这部分逻辑在 controller manager 和 kruise daemon 都有,而且判定 CRR completed 的方式比较多,这里举几个典型的例子:
4.1.1
当完成重启 container 的数量跟 CRR 中 ContainerRecreateStates 的数组长度一致的时候认为已经完成所有容器的重启工作,可以标记 CRR 为完成。
if completedCount == len(newCRRContainerRecreateStates) {
return c.completeCRRStatus(crr, "")
}
4.1.2
当发现有容器重启失败了,并且策略是 ignore 就直接标记本次 CRR 为 completed。
case appsv1alpha1.ContainerRecreateRequestFailed:
completedCount++
if crr.Spec.Strategy.FailurePolicy == appsv1alpha1.ContainerRecreateRequestFailurePolicyIgnore {
continue
}
return c.completeCRRStatus(crr, "")
4.1.3
上面两个例子都是在 crr_daemon_controller.go 中的,这里列一个 crr_controller 判定完成的例子:
if crr.Spec.ActiveDeadlineSeconds != nil {
leftTime := time.Duration(*crr.Spec.ActiveDeadlineSeconds)*time.Second - time.Since(crr.CreationTimestamp.Time)
if leftTime <= 0 {
klog.Warningf("Complete CRR %s/%s as failure for recreating has exceeded the activeDeadlineSeconds", crr.Namespace, crr.Name)
return reconcile.Result{}, r.completeCRR(crr, "recreating has exceeded the activeDeadlineSeconds")
}
duration.Update(leftTime)
}
CRR 在规定的 TTL 时间里没有完成任务,会被在这里标记为完成,但是会标记一个含有失败信息的 message。
4.2 到期删除 CRR
如果 CRR 设置了 TTLSecondsAfterFinished 字段,达到该时间后,系统就会将 CRR 删除,这对定期清理已经完成的 CRR 很有帮助。
if crr.Spec.TTLSecondsAfterFinished != nil {
leftTime = time.Duration(*crr.Spec.TTLSecondsAfterFinished)*time.Second - time.Since(crr.Status.CompletionTime.Time)
if leftTime <= 0 {
klog.Infof("Deleting CRR %s/%s for ttlSecondsAfterFinished", crr.Namespace, crr.Name)
if err = r.Delete(context.TODO(), crr); err != nil {
return reconcile.Result{}, fmt.Errorf("delete CRR error: %v", err)
}
return reconcile.Result{}, nil
}
}
结语
文章的结尾再来回顾一下 CRR 是如何在几个组件协作之下工作的: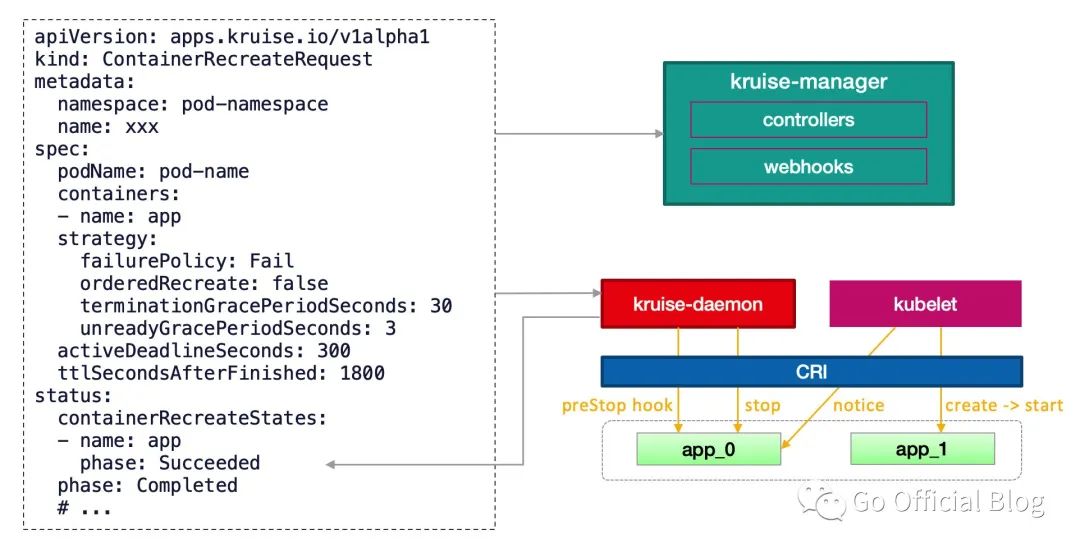
传统的 Pod 重启就是将原有的 Pod 删除,等待重建新的 Pod,而 CRR 的出现为我们提供了一种全新的重启服务的方式。
参考资料
OpenKruise 源码分析之原地升级: https://cloudsjhan.github.io/2022/06/19/OpenKruise-源码解读之原地升级/
[2]kruise CRR: https://openkruise.io/zh/docs/user-manuals/containerrecreaterequest
[3]kruise issue 895: https://github.com/openkruise/kruise/issues/895