 Python中文社区
Python中文社区




随着时间的推移,数字藏品领域越来越火。当一个加密朋克头像以15万美元的价格出售给Visa时,人们逐渐通过各种渠道去认识NFT。

方法论
这个生成器背后的方法很简单。通过将不同的特征结合在一起,创建一个独特的头像。
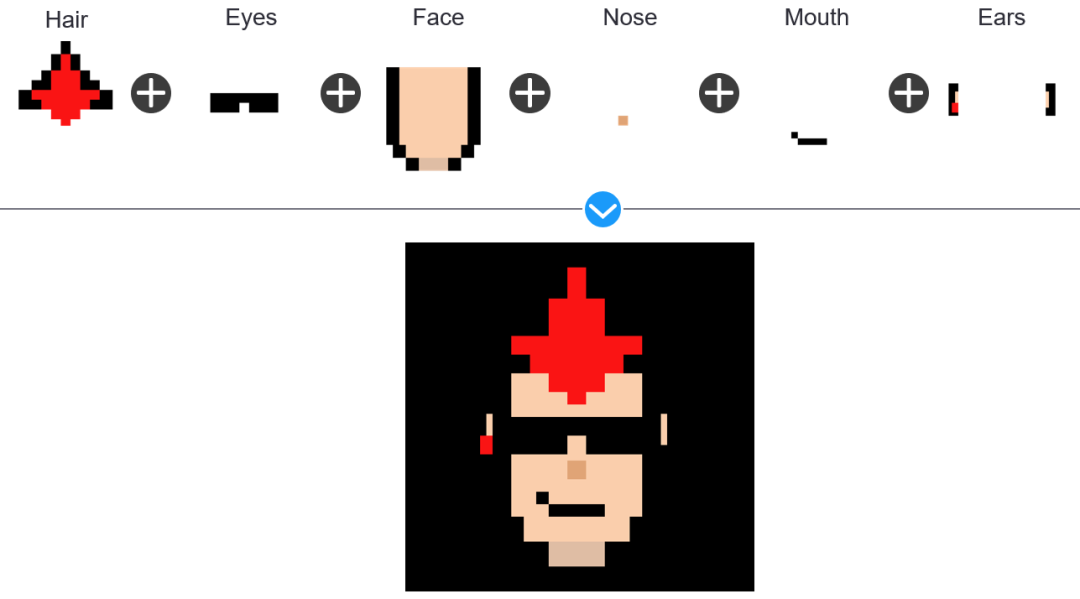
获取你的数据
你将使用 usetech-llc的 "Substrapunks "资源库中的数据。
在下面的链接中下载他们的资源库,并将压缩文件解压到你的本地电脑上。
https://github.com/usetech-llc/substrapunks/archive/refs/heads/master.zip
导入软件包
你将在这个项目中使用以下软件包:
PIL
IPython
Random
Json
OS
from PIL import Image
from IPython.display import display
import random
import json
import os
指定NFT特性的稀有性
每个独特的头像都由五个特征组成。
Face
Ears
Hair
Mouth
Nose
稀有性很重要,因为它创造了稀缺性,反过来又创造了价值。你将通过给一个特征中的不同类型分配权重来实现特征中的稀有性。权重的总和应该总是100。
有两种类型的脸(黑色和白色)。你在程序中可以规定,一张图片有60%的机会获得白脸,40%的机会获得黑脸。
# Each image is made up a series of traits
# The weightings for each trait drive the rarity and add up to 100%
face = ["White", "Black"]
face_weights = [60, 40]
ears = ["No Earring", "Left Earring", "Right Earring", "Two Earrings"]
ears_weights = [25, 30, 44, 1]
eyes = ["Regular", "Small", "Rayban", "Hipster", "Focused"]
eyes_weights = [70, 10, 5 , 1 , 14]
hair = ['Up Hair', 'Down Hair', 'Mohawk', 'Red Mohawk', 'Orange Hair', 'Bubble Hair', 'Emo Hair',
'Thin Hair',
'Bald',
'Blonde Hair',
'Caret Hair',
'Pony Tails']
hair_weights = [10 , 10 , 10 , 10 ,10, 10, 10 ,10 ,10, 7 , 1 , 2]
mouth = ['Black Lipstick', 'Red Lipstick', 'Big Smile', 'Smile', 'Teeth Smile', 'Purple Lipstick']
mouth_weights = [10, 10,50, 10,15, 5]
nose = ['Nose', 'Nose Ring']
nose_weights = [90, 10]
对特性进行分类
字典是用来将特征名称重定向到它们的文件名。你可以在以下位置找到特征文件名:
...\substrapunks-master\scripts\face_parts\ 。
特性名称 "White "被引导到face1,而 "Black "被引导到face2。

#Classify traits
face_files = {
"White": "face1",
"Black": "face2"
}
ears_files = {
"No Earring": "ears1",
"Left Earring": "ears2",
"Right Earring": "ears3",
"Two Earrings": "ears4"
}
eyes_files = {
"Regular": "eyes1",
"Small": "eyes2",
"Rayban": "eyes3",
"Hipster": "eyes4",
"Focused": "eyes5"
}
hair_files = {
"Up Hair": "hair1",
"Down Hair": "hair2",
"Mohawk": "hair3",
"Red Mohawk": "hair4",
"Orange Hair": "hair5",
"Bubble Hair": "hair6",
"Emo Hair": "hair7",
"Thin Hair": "hair8",
"Bald": "hair9",
"Blonde Hair": "hair10",
"Caret Hair": "hair11",
"Pony Tails": "hair12"
}
mouth_files = {
"Black Lipstick": "m1",
"Red Lipstick": "m2",
"Big Smile": "m3",
"Smile": "m4",
"Teeth Smile": "m5",
"Purple Lipstick": "m6"
}
nose_files = {
"Nose": "n1",
"Nose Ring": "n2"
}
定义图像特质
你要创建的每个头像都将是六张图片的组合:脸、鼻子、嘴、耳朵和眼睛。
因此,可以写一个for循环,将这些特征组合成一张图片,并指定图片的总数量。
一个函数为每张图片创建一个字典,指定它拥有哪些特征。
这些特征是根据 random.choice()函数给出的。
这个函数遍历脸部特征列表(白色、黑色),并返回白色(60%的机会)或黑色(40%的机会)。
## Generate Traits
TOTAL_IMAGES = 100 # Number of random unique images we want to generate
all_images = []
# A recursive function to generate unique image combinations
def create_new_image():
new_image = {} #
# For each trait category, select a random trait based on the weightings
new_image ["Face"] = random.choices(face, face_weights)[0]
new_image ["Ears"] = random.choices(ears, ears_weights)[0]
new_image ["Eyes"] = random.choices(eyes, eyes_weights)[0]
new_image ["Hair"] = random.choices(hair, hair_weights)[0]
new_image ["Mouth"] = random.choices(mouth, mouth_weights)[0]
new_image ["Nose"] = random.choices(nose, nose_weights)[0]
if new_image in all_images:
return create_new_image()
else:
return new_image
# Generate the unique combinations based on trait weightings
for i in range(TOTAL_IMAGES):
new_trait_image = create_new_image()
all_images.append(new_trait_image)
验证唯一性
对于NFT头像项目来说,每个头像都是独一无二的,这一点很重要。因此,需要检查所有的图像是否是唯一的。写一个简单的函数,在所有的图像上循环,将它们存储到一个列表中,并返回重复的图像。
接下来,为每个图像添加一个唯一的标识符。
# Returns true if all images are unique
def all_images_unique(all_images):
seen = list()
return not any(i in seen or seen.append(i) for i in all_images)
print("Are all images unique?", all_images_unique(all_images))
# Add token Id to each image
i = 0
for item in all_images:
item["tokenId"] = i
i = i + 1
print(all_images)
性状计数
根据预定的权重和随机函数来分配特征。这意味着,即使你将白色面孔的权重定义为60,你也不可能正好有60张白色面孔。为了准确了解每个特征的出现数量,必须跟踪现在有多少特征出现在你的图像集合中。
要做到这一点,要写下面的代码。
为每个特征定义一个字典,其中有它们各自的分类,并从0开始。
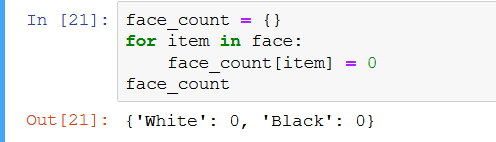
循环查看你创建的图像,如果遇到特质,就把它们添加到各自的特质字典中。
# Get Trait Counts
face_count = {}
for item in face:
face_count[item] = 0
ears_count = {}
for item in ears:
ears_count[item] = 0
eyes_count = {}
for item in eyes:
eyes_count[item] = 0
hair_count = {}
for item in hair:
hair_count[item] = 0
mouth_count = {}
for item in mouth:
mouth_count[item] = 0
nose_count = {}
for item in nose:
nose_count[item] = 0
for image in all_images:
face_count[image["Face"]] += 1
ears_count[image["Ears"]] += 1
eyes_count[image["Eyes"]] += 1
hair_count[image["Hair"]] += 1
mouth_count[image["Mouth"]] += 1
nose_count[image["Nose"]] += 1
print(face_count)
print(ears_count)
print(eyes_count)
print(hair_count)
print(mouth_count)
print(nose_count)
生成图像
这是最神奇的部分。对于每张图片,脚本将执行以下操作。
打开我们定义特质的图像特征文件

使用PIL软件包在你的目录中选择相应的性状图像。
将所有的性状组合成一个图像
转换为RGB,这是最传统的颜色模型
把它保存到你的电脑上
#### Generate Images
os.mkdir(f'./images')
for item in all_images:
im1 = Image.open(f'./scripts/face_parts/face/{face_files[item["Face"]]}.png').convert('RGBA')
im2 = Image.open(f'./scripts/face_parts/eyes/{eyes_files[item["Eyes"]]}.png').convert('RGBA')
im3 = Image.open(f'./scripts/face_parts/ears/{ears_files[item["Ears"]]}.png').convert('RGBA')
im4 = Image.open(f'./scripts/face_parts/hair/{hair_files[item["Hair"]]}.png').convert('RGBA')
im5 = Image.open(f'./scripts/face_parts/mouth/{mouth_files[item["Mouth"]]}.png').convert('RGBA')
im6 = Image.open(f'./scripts/face_parts/nose/{nose_files[item["Nose"]]}.png').convert('RGBA')
#Create each composite
com1 = Image.alpha_composite(im1, im2)
com2 = Image.alpha_composite(com1, im3)
com3 = Image.alpha_composite(com2, im4)
com4 = Image.alpha_composite(com3, im5)
com5 = Image.alpha_composite(com4, im6)
#Convert to RGB
rgb_im = com5.convert('RGB')
file_name = str(item["tokenId"]) + ".png"
rgb_im.save("./images/" + file_name)

 - 点击下方阅读原文加入社区会员 -
- 点击下方阅读原文加入社区会员 -

