
权威科普:高性能计算原理
共 1758字,需浏览 4分钟
· 2022-07-09
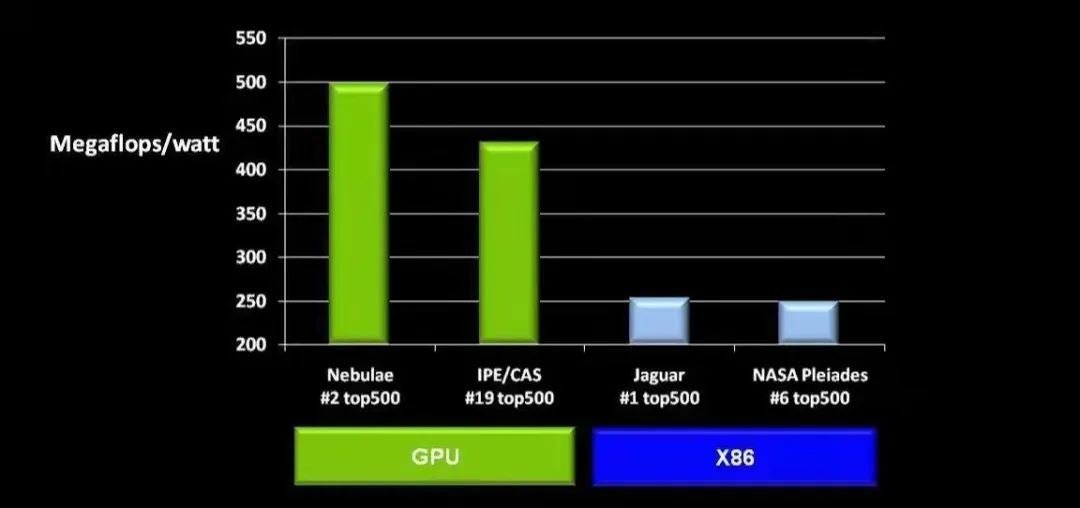

高性能计算(HPC)利用超级计算机和并行处理技术,快速完成耗时较长的任务或同时完成多个任务。HPC市场既是一个传统的市场,又是一个新兴的、高速发展的市场。定位高端用户、标杆项目,影响力大、平民化趋势、快速发展。
高性能计算的工作原理
在高性能计算中,处理信息的两种主要方式为:
串行处理,由中央处理器 (CPU) 完成。每个 CPU 核心通常每次只能处理一个任务。CPU 对于运行各种功能而言至关重要,如操作系统和基本应用程序(如文字处理、办公生产力工具等)。

并行处理,可利用多个 CPU 或图形处理器 (GPU) 完成。GPU 最初是专为图形处理而设计的。它可在数据矩阵(如屏幕像素)中同时执行多种算术运算。同时在多个数据平面上工作的能力使 GPU 非常适合在机器学习 (ML) 应用任务中进行并行处理,如识别视频中的物体。
突破超级计算的极限需要不同的系统架构。大多数高性能计算系统通过超高带宽将多个处理器和内存模块互连并聚合,从而实现并行处理。一些高性能计算系统将 CPU 和 GPU 结合在一起,被称为异构计算。
计算机计算能力的度量单位被称为“FLOPS”(每秒浮点运算次数)。截至 2019 年初,现有的高端超级计算机可以执行 143.5 千万亿次 FLOPS (143 × 1015)。此类超级计算机被称为千万亿次级,可以执行超过千万亿次 FLOPS。相比之下,高端游戏台式机的速度要慢 1,000,000 倍以上,可执行约 200 千兆次 FLOPS (1 × 109)。超级计算在处理和吞吐量方面的重大突破很快将会实现超级计算的下一个重大级别——百亿亿次级,该级别的速度比千万亿次级约快 1,000 倍。这意味着百亿亿次级超级计算机每秒将能够执行 1018(或者 10 亿 x 10 亿)次运算。
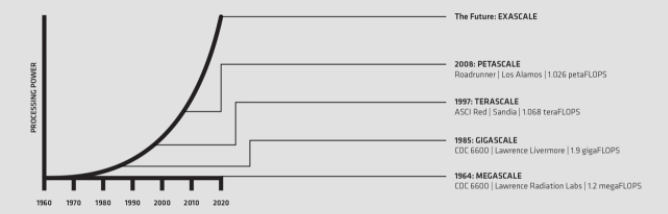
“FLOPS”是对理论处理速度的描述,实现该速度需要连续向处理器传输数据。因此,系统设计必须考虑到数据吞吐量这一因素。系统内存以及处理节点之间的互连会影响数据传输到处理器的速度。

为了实现1百亿亿次级 FLOPS 的下一级超级计算机处理性能,大概需要 5,000,000 个台式机。*假定每个台式机具备 200 千兆次 FLOPS 的能力。
术语知识
高性能计算 (HPC):一个广义上的强大计算系统,其范围涵盖简单计算机(如 1 个 CPU + 8 个 GPU),乃至世界一流的超级计算机 超级计算机:最先进的高性能计算机,以不断提高的性能标准为依据 异构计算:优化串行 (CPU) 和并行 (GPU) 处理能力的高性能计算架构 内存:在高性能计算系统中为实现快速访问而存储数据的地方 互连:可令处理节点互相通信的系统层;在超级计算机中存在多个级别的互连 千万亿次级:为达到每秒执行千万亿次 (1015) 运算而设计的超级计算机 百亿亿次级:为达到每秒执行百亿亿次 (1018) 运算而设计的超级计算机
从系统的角度:集成系统资源,以满足不断增长的对性能和功能的要求
从应用的角度:适当分解应用,以实现更大规模或更细致的计算
解决问题: 科学和工程问题的数值模拟与仿真(计算密集、数据密集、网络密集、三种混合)。
HPC报告合集:






















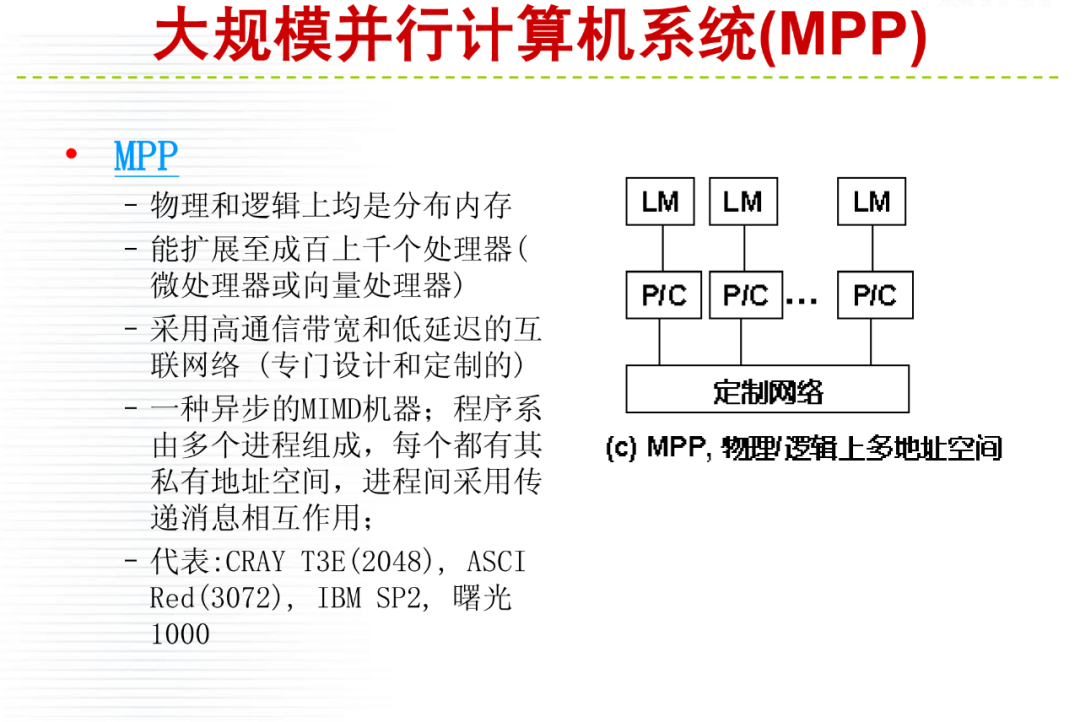
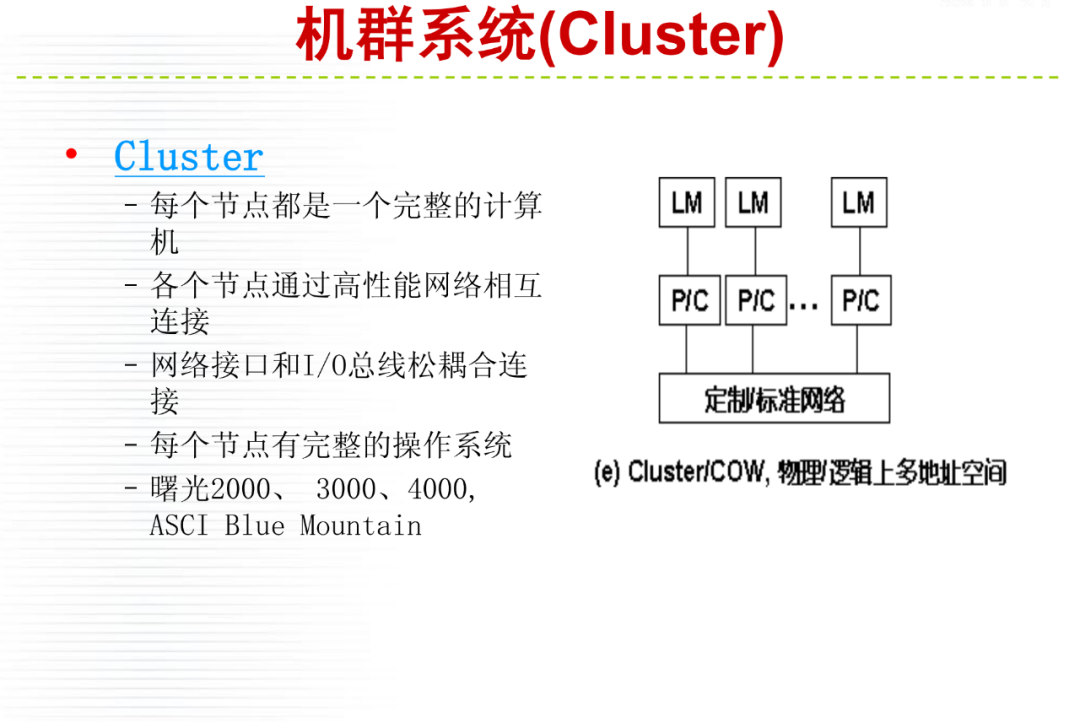
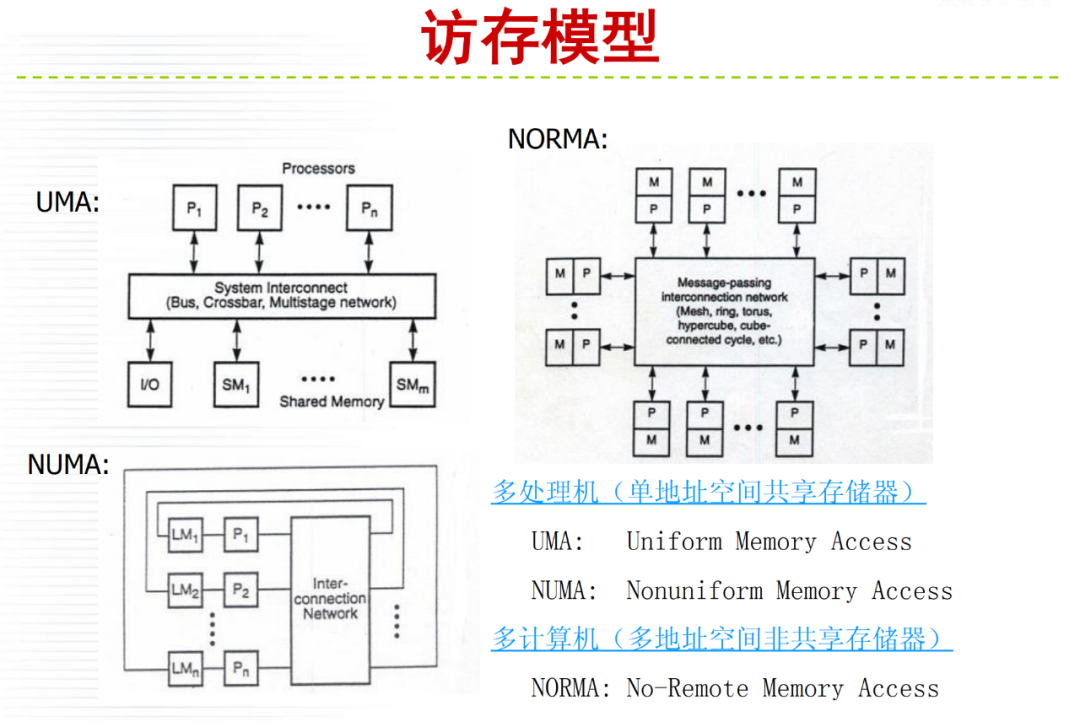
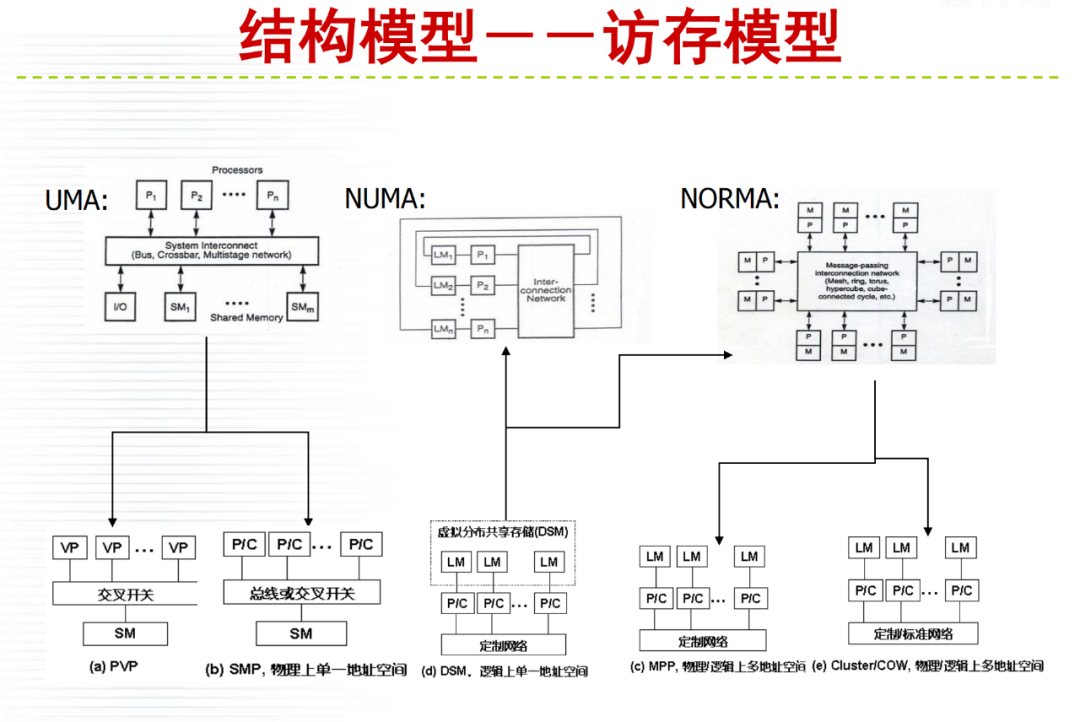
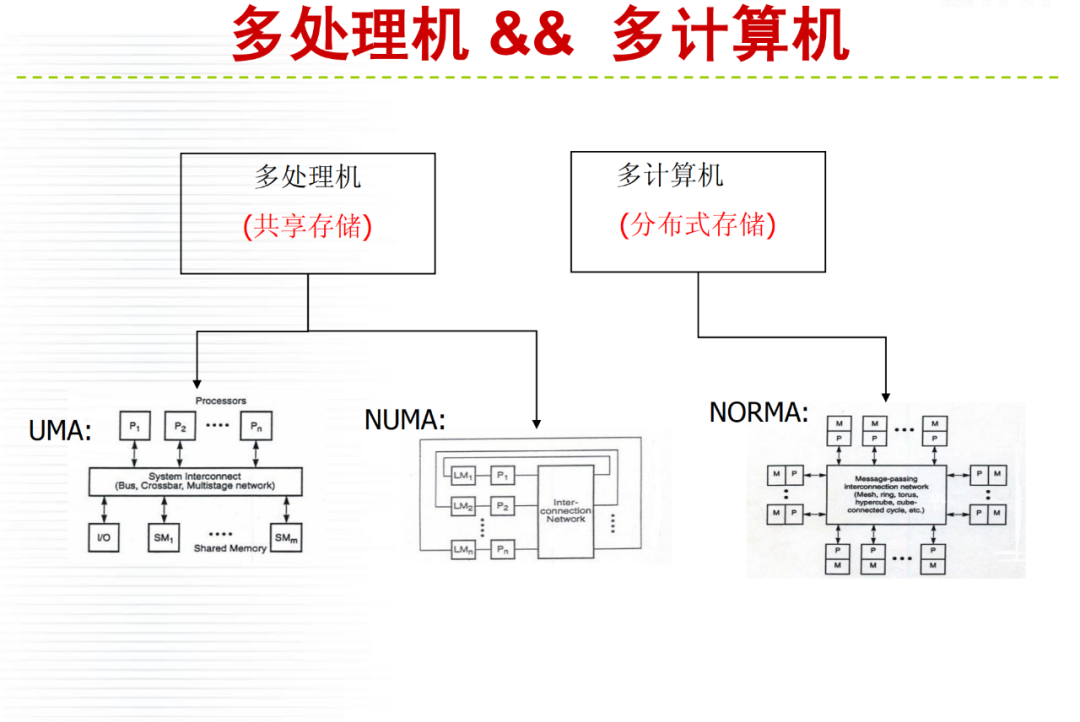
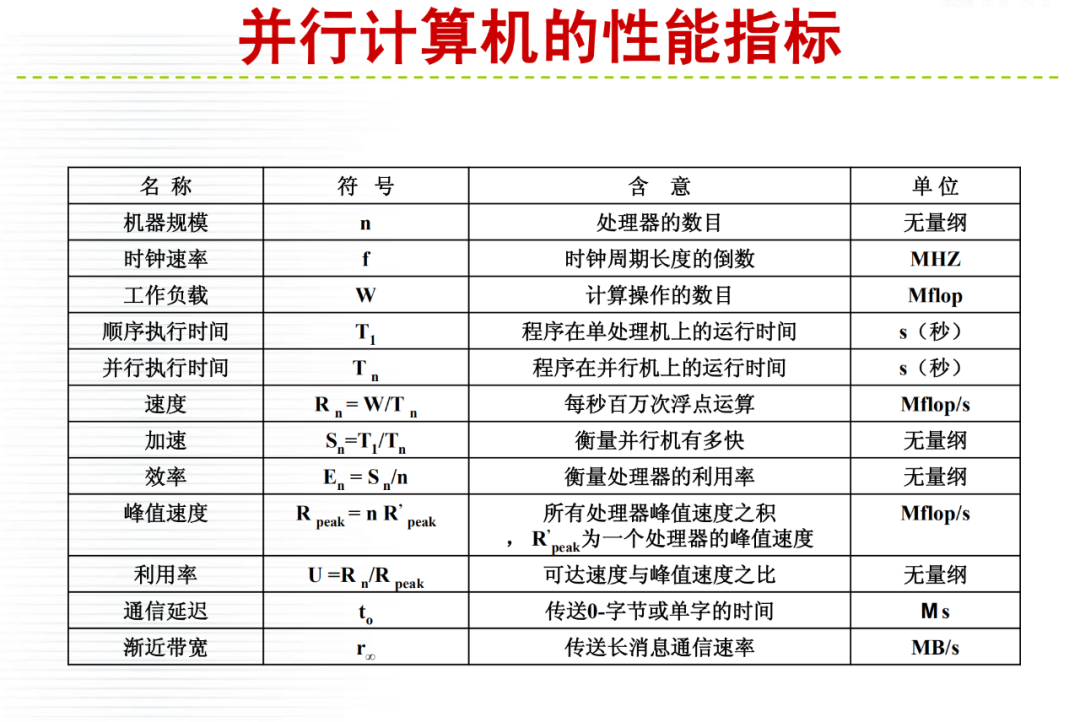













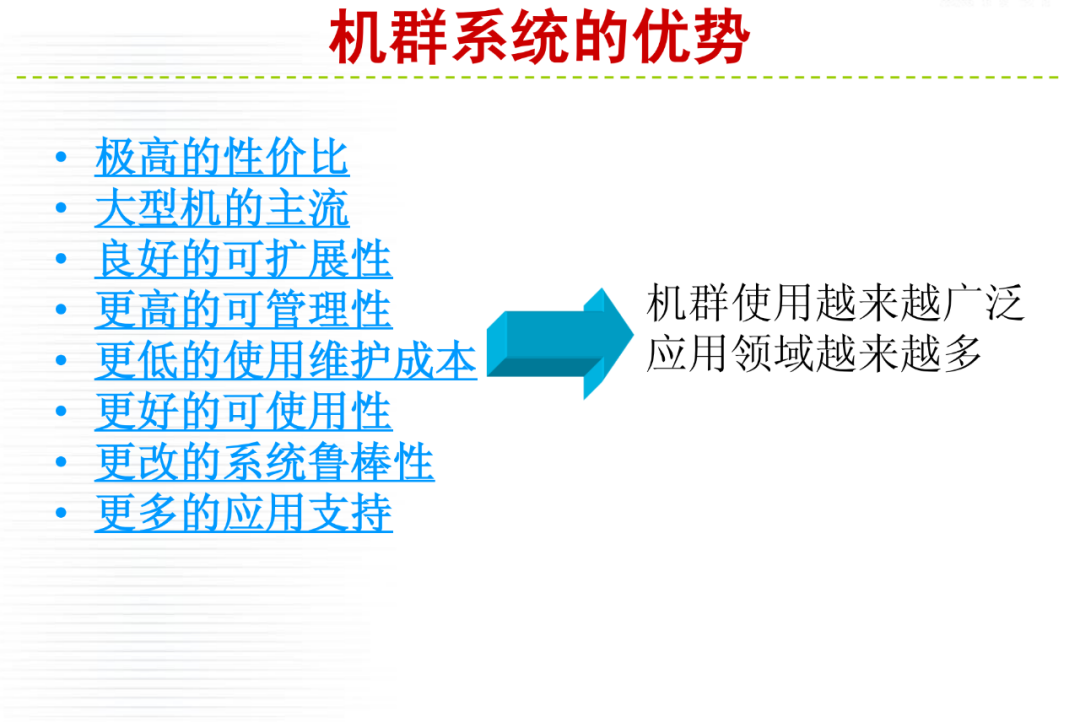

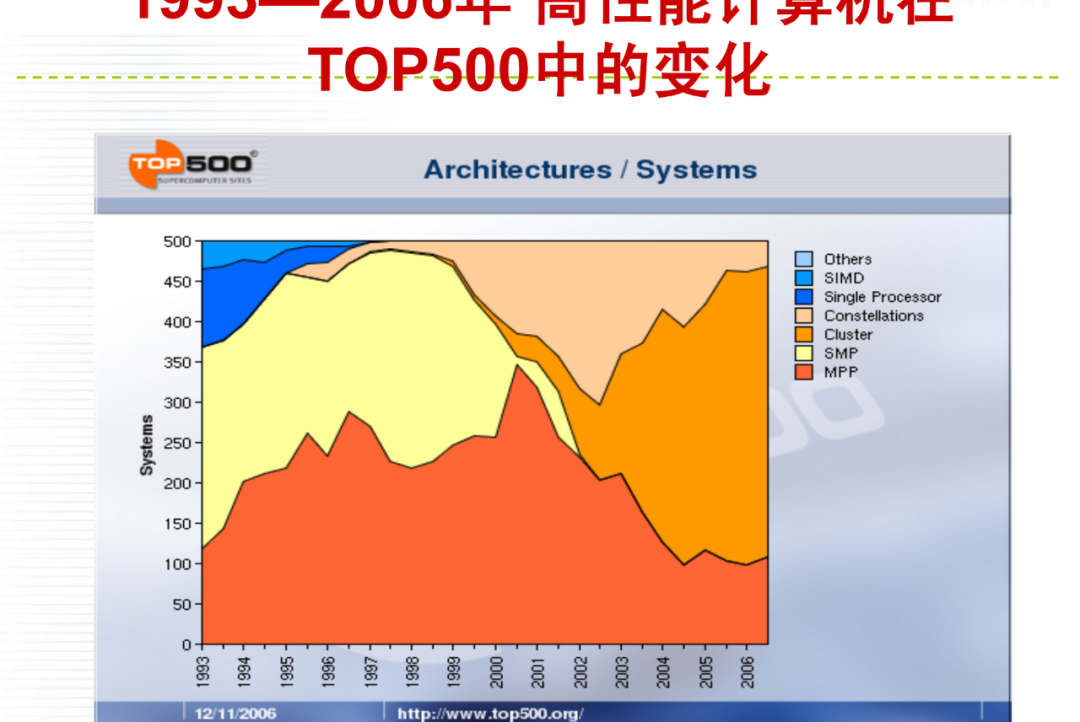
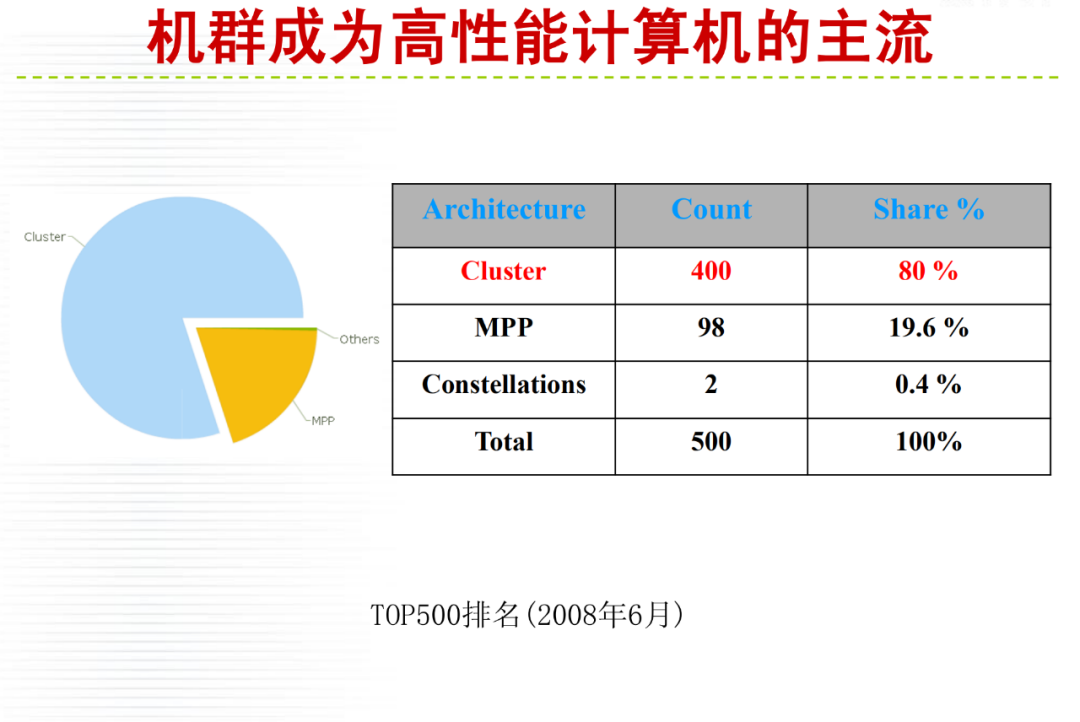

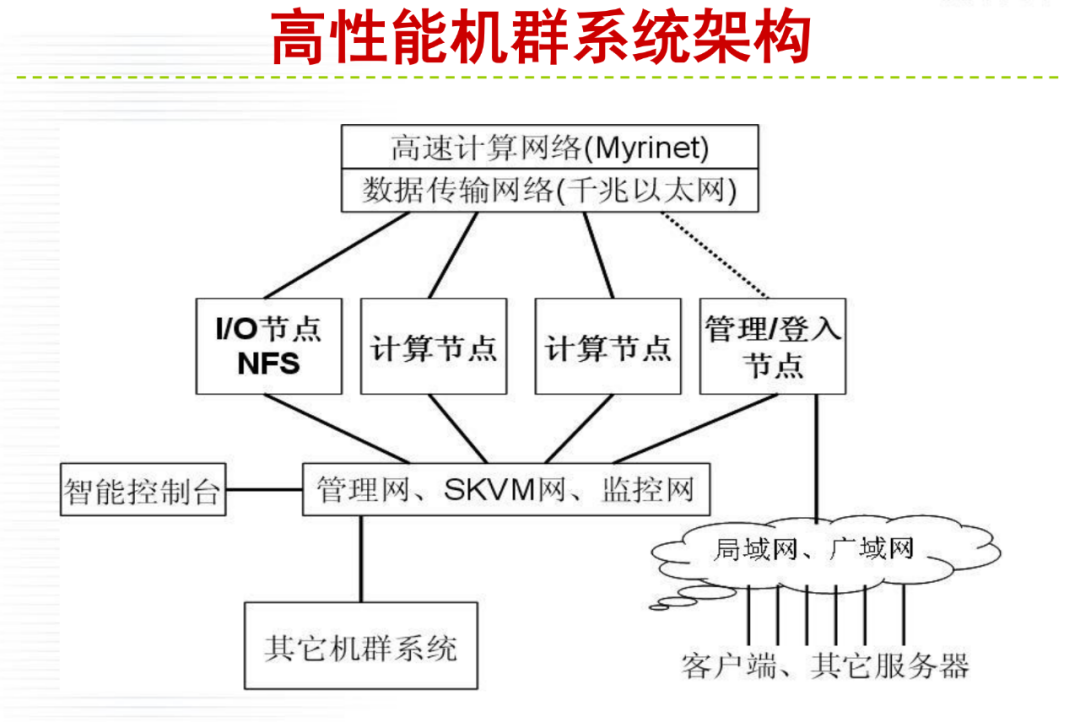

详细内容请大家参考微店电子书目录,购买过<高性能计算(HPC)技术、方案和行业全面解析>或微店全店铺技术资料打包(全)的读者,请在微店留言,免费获取更新下载地址。
来源:智能计算芯世界
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
