
最新数据挖掘赛事方案梳理!

本文共1500字,建议阅读9分钟 本文带你沉浸式感受糖尿病遗传风险预测赛题的从0到1的参赛过程。
赛题介绍
赛题任务
赛题数据
训练集:共有5070条数据,用于构建您的预测模型 测试集:共有1000条数据,用于验证预测模型的性能。
评分标准
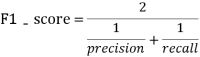


赛题Baseline
导入数据
import pandas as pdimport lightgbm
数据预处理
data1=pd.read_csv('比赛训练集.csv',encoding='gbk')data2=pd.read_csv('比赛测试集.csv',encoding='gbk')#label标记为-1data2['患有糖尿病标识']=-1#训练集和测试机合并data=pd.concat([data1,data2],axis=0,ignore_index=True)#特征工程"""人体的成人体重指数正常值是在18.5-24之间低于18.5是体重指数过轻在24-27之间是体重超重27以上考虑是肥胖高于32了就是非常的肥胖。"""def BMI(a):if a<18.5:return 0elif 18.5<=a<=24:return 1elif 24<a<=27:return 2elif 27<a<=32:return 3else:return 4data['BMI']=data['体重指数'].apply(BMI)data['出生年份']=2022-data['出生年份'] #换成年龄#糖尿病家族史"""无记录叔叔或者姑姑有一方患有糖尿病/叔叔或姑姑有一方患有糖尿病父母有一方患有糖尿病"""def FHOD(a):if a=='无记录':return 0elif a=='叔叔或者姑姑有一方患有糖尿病' or a=='叔叔或姑姑有一方患有糖尿病':return 1else:return 2data['糖尿病家族史']=data['糖尿病家族史'].apply(FHOD)data['舒张压']=data['舒张压'].fillna(-1)"""舒张压范围为60-90"""def DBP(a):if a<60:return 0elif 60<=a<=90:return 1elif a>90:return 2else:return adata['DBP']=data['舒张压'].apply(DBP)data
训练数据/测试数据准备
train=data[data['患有糖尿病标识'] !=-1]test=data[data['患有糖尿病标识'] ==-1]train_label=train['患有糖尿病标识']train=train.drop(['编号','患有糖尿病标识'],axis=1)test=test.drop(['编号','患有糖尿病标识'],axis=1)
构建模型
def select_by_lgb(train_data,train_label,test_data,random_state=2022,metric='auc',num_round=300):clf=lightgbmtrain_matrix=clf.Dataset(train_data,label=train_label)params={'boosting_type': 'gbdt','objective': 'binary','learning_rate': 0.1,'metric': metric,'seed': 2020,'nthread':-1 }model=clf.train(params,train_matrix,num_round)pre_y=model.predict(test_data)return pre_y
模型验证
test_data=select_by_lgb(train,train_label,test)pre_y=pd.DataFrame(test_data)pre_y['label']=pre_y[0].apply(lambda x:1 if x>0.5 else 0)result=pd.read_csv('提交示例.csv')result['label']=pre_y['label']result.to_csv('baseline.csv',index=False)
上分建议
评论