
基于各种机器学习和深度学习的中文微博情感分析
数据派THU
共 836字,需浏览 2分钟
· 2022-07-08

来源:机器学习AI算法工程 本文约600字,建议阅读5分钟
本文中,我们介绍了中文微博情感分析的情况。
中文微博情感分类语料库
"情感分析"是我本科的毕业设计,也是我入门并爱上NLP的项目hhh,当时网上相关语料库的质量都太低了,索性就自己写了个爬虫,一边标注一边爬,现在就把它发出来供大家交流。因为是自己的项目,所以标注是相当认真的,还请了朋友帮忙校验,过滤掉了广告/太短/太长/表意不明等语料,语料质量是绝对可以保证的。 带情感标注的微博语料数量: 10000(train.txt)+500(test.txt)
数据格式
文档的每一行代表一条语料。 每条语料的第一个数据为微博对应的mid,是每条微博的唯一标签,可以通过"https://m.weibo.cn/status/" + mid 访问到该条微博的网页(部分微博可能已被博主删除)。 第二个数据为情感标签,0表示负面,1表示正面。
项目说明
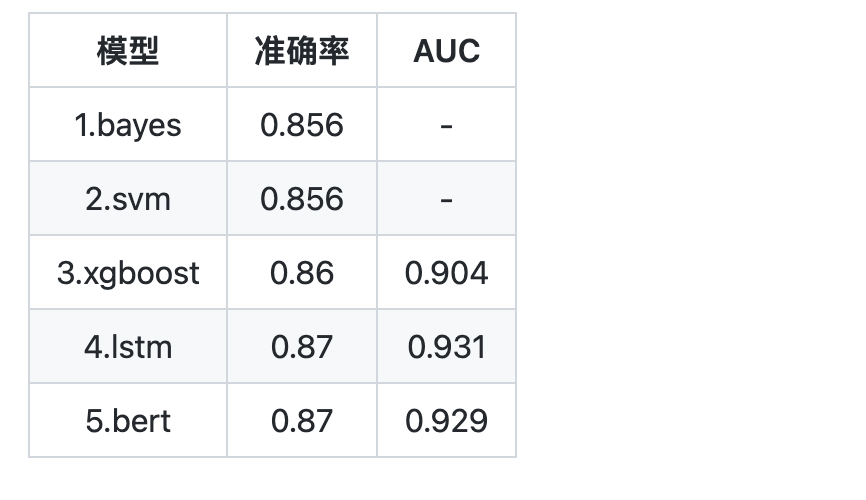
训练集10000条语料,测试集500条语料。 使用朴素贝叶斯、SVM、XGBoost、LSTM和Bert,等多种模型搭建并训练二分类模型。 前3个模型都采用端到端的训练方法。 LSTM先预训练得到Word2Vec词向量,在训练神经网络。 Bert使用的是哈工大的预训练模型,用Bert的[CLS]位输出在一个下游网络上进行finetune。预训练模型需要自行下载。
实验结果
项目资料:
基于情感词典、k-NN、Bayes、最大熵、SVM的情感分析
https://github.com/chaoming0625/SentimentPolarityAnalysis
风险事件文本分类(达观杯Rank4)
https://github.com/DA-southampton/DaguanFengxian
编辑:王菁
校对:林亦霖
评论
了解加密货币到加密货币的互换
1、什么是加密货币互换?加密货币到加密货币的互换是指以现行市场汇率将一种加密货币直接兑换为另一种加密货币。与需要法定货币存款和较长流程的传统交易所不同,加密货币到加密货币的互换可以无缝地促进交换。掉期在提高加密货币的流动性和效率方面发挥着重要作用。该功能使用户能够将他们的加密货币与钱包中的其他代币进
区块链头条
0
李彦宏:开源大模型不如闭源,后者会持续领先;周鸿祎:“开源不如闭源” 的言论是胡说八道
架构师大咖
架构师大咖,打造有价值的架构师交流平台。分享架构师干货、教程、课程、资讯。架构师大咖,每日推送。
公众号该公众号已被封禁0、李彦宏:开源大模型不如闭源,后者会持续领先当今
源码共读
0
【第129期】程序员的新宠:三款终端工具,让你告别Xshell!
概述 WindTerm:跨平台的SSH利器 首先介绍的是WindTerm,这是一款使用C语言开发的跨平台SSH客户端。它不仅完全免费,而且没有商业使用的限制。WindTerm支持SSH v2、Telnet、Raw Tcp等协议,而且性能出色,甚至超过了FinalShell和Electerm。功能
前端微服务
0
字节员工:35岁以后被裁员的,后来都走了哪条路?现在2-2,要不要利用最后一年拼命上个岸。
架构师大咖
架构师大咖,打造有价值的架构师交流平台。分享架构师干货、教程、课程、资讯。架构师大咖,每日推送。
公众号该公众号已被封禁在当今竞争激烈的职场环境中,年龄并不总是一个决定性
源码共读
0
互联网晚报 | 大麦网已退款凤凰传奇演唱会“柱子票”;钟薛高再成被执行人;iPhone 16或取消实体音量键和电源键
大麦网回应凤凰传奇演唱会买到“柱子票”:已退票退款据报道,凤凰传奇2024巡回演唱会常州站演出结束的第二天,有网友称自己在大麦网买到“柱子票”,因为观看效果不佳,要求退款被拒。23日,记者从涉事网友处了解到,大麦方面给出了退款建议,但被其拒绝,“我希望平台退款加赔偿,并重视屡次出现的‘柱子票’问题。
产品刘
0
上班的时候,有一群摸鱼搭子非常重要...
上班的时候,有一群摸鱼搭子非常重要!一到上班时间,他们就从四面八方涌进群里冒泡...从八卦聊到股市、从职场聊到乌X兰局势,偶尔还会复读、相亲、battle...然后,下午6点钟准时消失不见...所以你要不要加入我们一起摸鱼?我们有北京、上海、深圳、广州、杭州、武汉、成都、南京等8个城市的摸鱼群,还有
产品经理日记
0
AI论文写作工具和生成器(一)
随着人工智能和大模型的迅猛发展,AI对研究人员和学生提供了极大的写作便利。本文将介绍市面上常用的AI论文写作工具,帮助你提高论文写作效率并遵循学术道德。请仅将AI论文生成器视为辅助参考手段,切勿直接挪用全文。XPaper AlXPaper AI是由点击式创作工具晓语台推出的一款论文写作生成平台,只需
IQ前端
0
周四002 瑞超:同样落寞的境遇——北雪平vs埃尔夫斯堡
上赛季最终排名联赛第9的北雪平本赛季伊始表现不佳,4轮战罢他们仅以1胜1平2负的战绩排在倒数第三,这支历史上曾夺得13次联赛冠军、6次杯赛冠军老牌劲旅,正如英格兰赛场上的一众百年俱乐部,在低谷中不断探索着出路。球队主教练安德烈亚斯·阿尔姆曾是AIK索尔纳及赫根队的主教练,他于今年年初刚刚拿起球队教鞭
产品与体验
0