
有这技术,活该涨工资!
大家好,我是 Jack。
我发现,技术开放日是个好东西,秀技术肌肉的好日子。
各大互联网公司都有这样的活动。
就比如,腾讯在 6 月 28 日就举行了首期的 Techo Day,这期的主题是“轻量级”。
所谓腾讯也围绕降低门槛,提高研效发布了几款新的云开发工具。
这里最让我眼前一亮的是腾讯云 TI 平台的 TI-ONE。
可以轻松地让我们训练自己想要的模型。
TI-ONE
这么好的工具,我也去体验了一番。
化繁为简,轻而易用。
TI-ONE 的官方定义是这样的:
腾讯云 TI 平台 TI-ONE 是为 AI 工程师打造的一站式机器学习平台,为用户提供从数据接入、模型训练、模型管理到模型服务的全流程开发支持。腾讯云 TI 平台 TI-ONE 支持多种训练方式和算法框架,满足不同 AI 应用场景的需求。
官方使用手册:
https://cloud.tencent.com/document/product/851
体验地址:
https://cloud.tencent.com/product/tione
应用场景
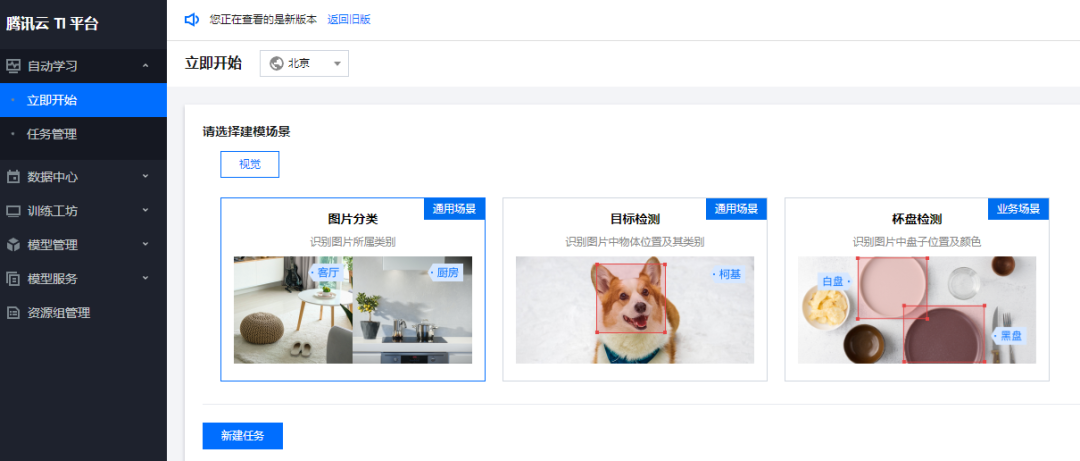
目前平台提供了低门槛训练场景:图像分类和图像检测。
除主流的训练场景外,其他类型的场景化训练工具,会持续升级丰富。
像现在,很多工业界都在逐渐使用深度学习算法进行缺陷检测与缺陷分类。
TI-ONE 就可以帮助这些技术积累少,但也想试一试这些算法的传统行业,帮助他们降本增效。
会用了这神器,让老板涨工资稳了!

今天就带大家一起实战试一试。
弄个简单的,试一试分类任务。
一提到分类任务,我就想到了之前写的文章,用传统方法做的色情图片识别,其实用深度学习方法效果更好,更稳定,但苦于无法分享数据集只能作罢。
今天就不来这种极限拉扯的了,来点正经干货!
数据集准备
我们都知道,想要训练一个基于监督学习的深度学习分类模型,必须得有数据,有标签。
对于分类任务,平台支持两种格式的数据:
TI 平台格式
其实就是有个 annotation.txt 写好数据的标注信息即可。
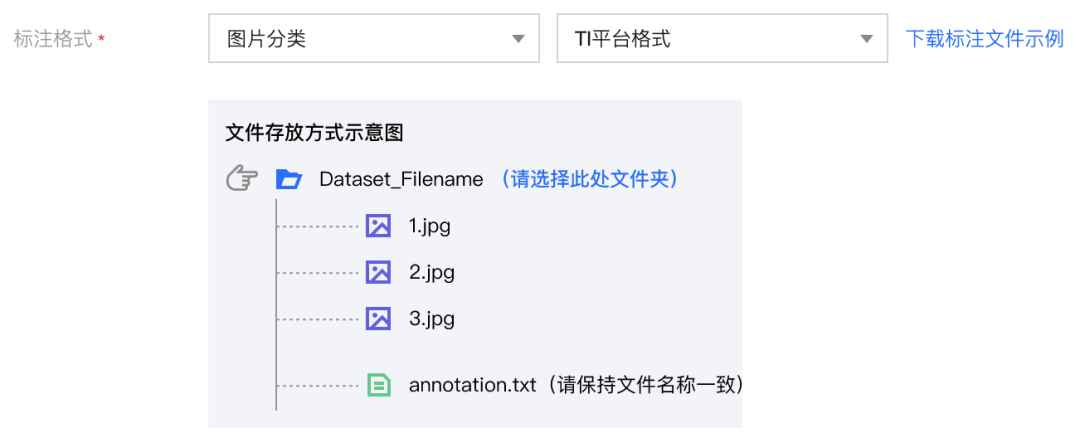
annotation.txt 文件的格式是这样的:
{
"info": { // 可选字段,表示图片的相关信息
"md5": "图片md5值", // 可选字段,表示图片的md5值
"path": "图片相对路径",
},
"tags": {
"classification_tags": [{
"first_class": "一级标签值",
"confidence_level": 置信度 // 可选字段,表示标签置信度
}]
}
}
这个其实需要使用者有一定的代码能力,写好标注数据,略有门槛。
文件目录结构
另外就是这种,不用写什么标注文件,直接一个类别一个文件夹就行。
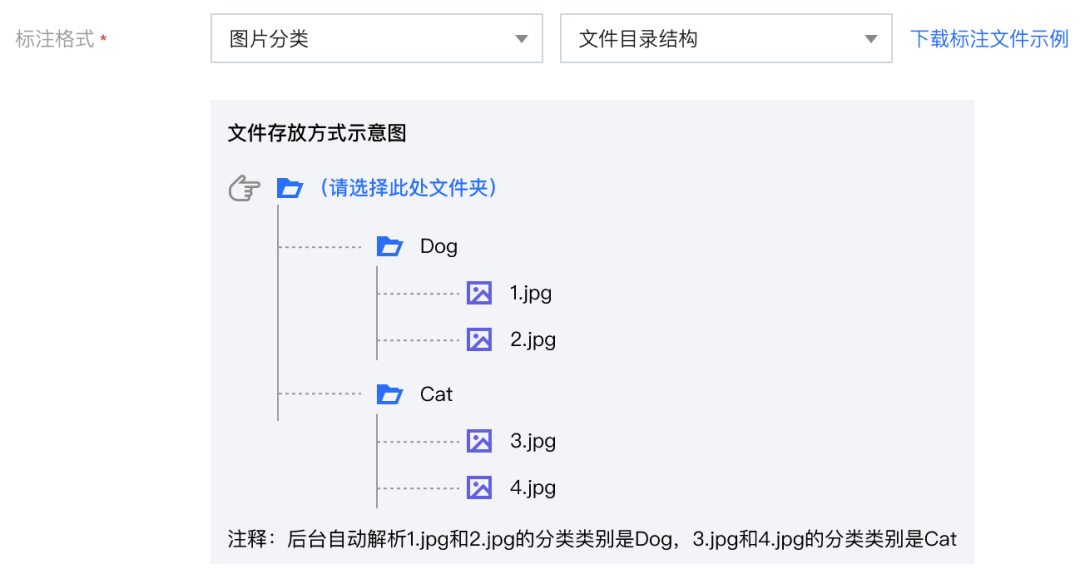
简单粗暴,无需额外上传标注文件。
这是有标签的数据,对于没有标签的数据,我们也可以使用 TI-ONE 平台进行标注:
自己一张一张标注数据就可以了:
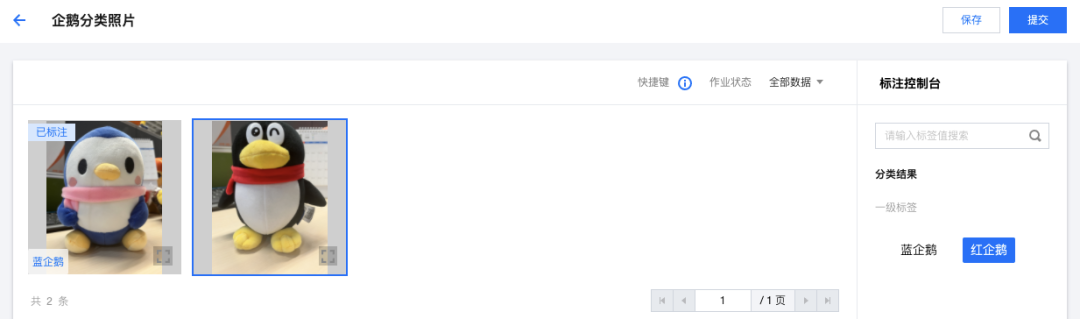
总结一下就是:
自己有数据,有标签,直接按照格式导入平台,就能使用了 自己有数据,没标签,也可以导入平台,然后一张一张标注
自动学习
数据准备好,我们就可以尝试训练模型了,选择图像分类。
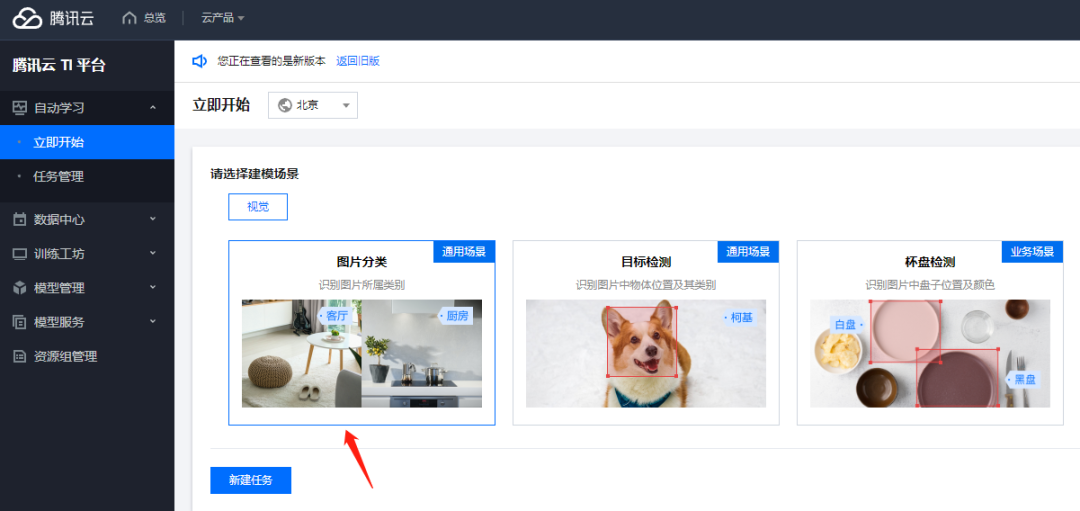
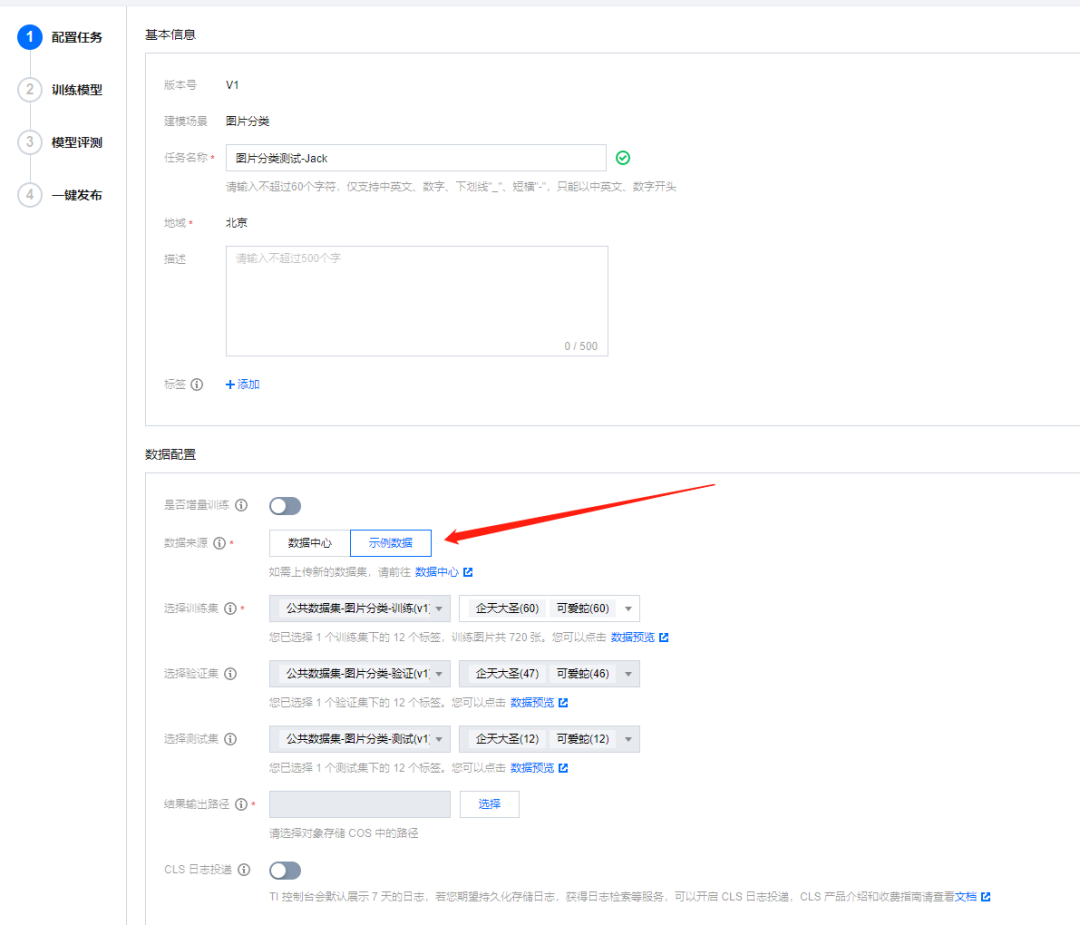
这里我直接使用示例数据进行测试,平台为我们准备好了一些任务的数据集。
如果是使用自己的数据集,可以选择数据中心,里面保存的就是我们自己上传的数据。
这是一个简单的分类任务,有各种小企鹅。
有齐天大圣:

有威威虎:
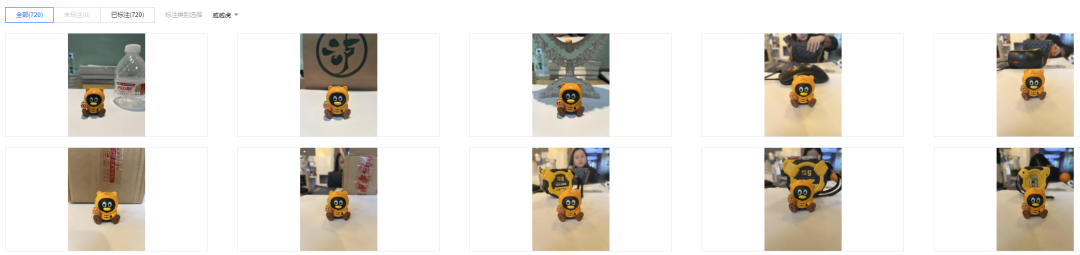
一共 12 个类别,共 720 张训练数据。
数据分为:
训练集:用来训练模型的数据。 验证集:训练的时候,是根据验证集的准召保存模型的,不参与训练。 测试集:训练好后,用测试集看模型的效果,不参与训练。
结果需要输出到 COS 中,就是一个对象存储,可以直接买一个 10G 的资源包,很便宜。
https://console.cloud.tencent.com/cos/bucket
一个月 8 毛~

然后创建一个存储桶,就能使用了,我这里直接取名 test。

这样就能选择这个 bucket,保存我们的训练结果了。
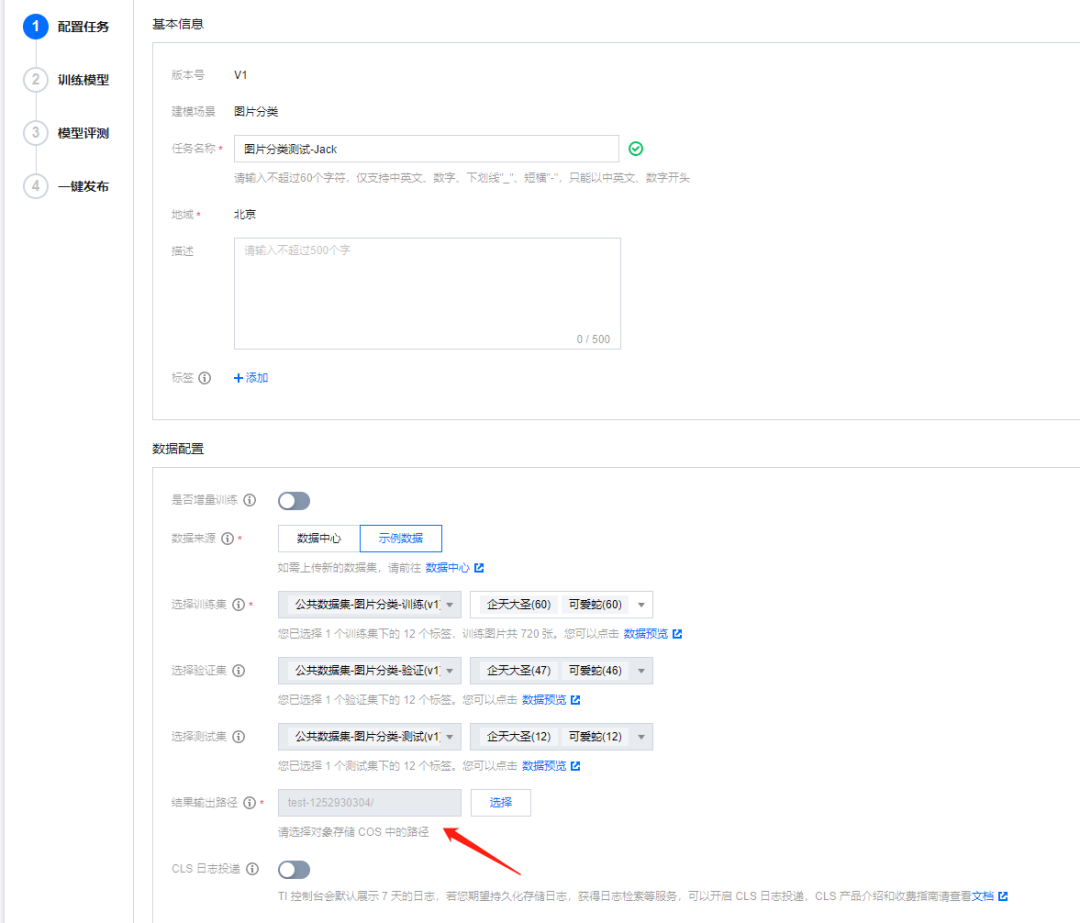
训练参数根据实际情况选择就行,对于很小数据集的分类任务,基本上 1 个小时轻松搞定,我这里就用默认参数了。
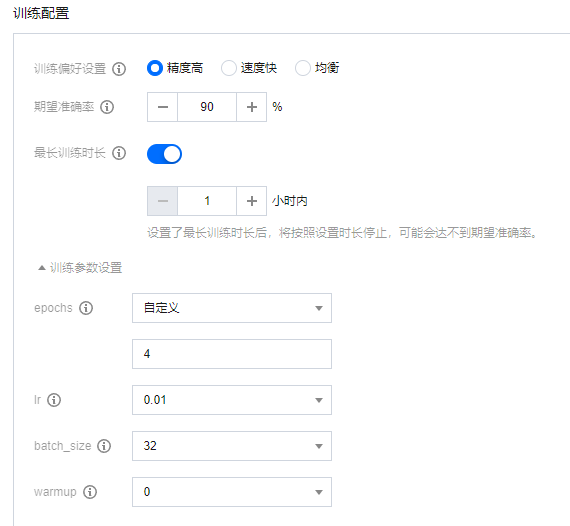
资源配置主要是选择 GPU,我这里用个 T4 就够用了。
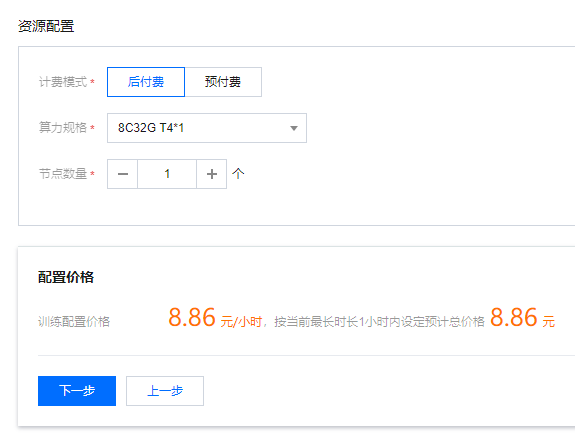
用这个卡训练,一小时 8 元多。
然后平台会自动配置机器,初始化环境,开启训练。
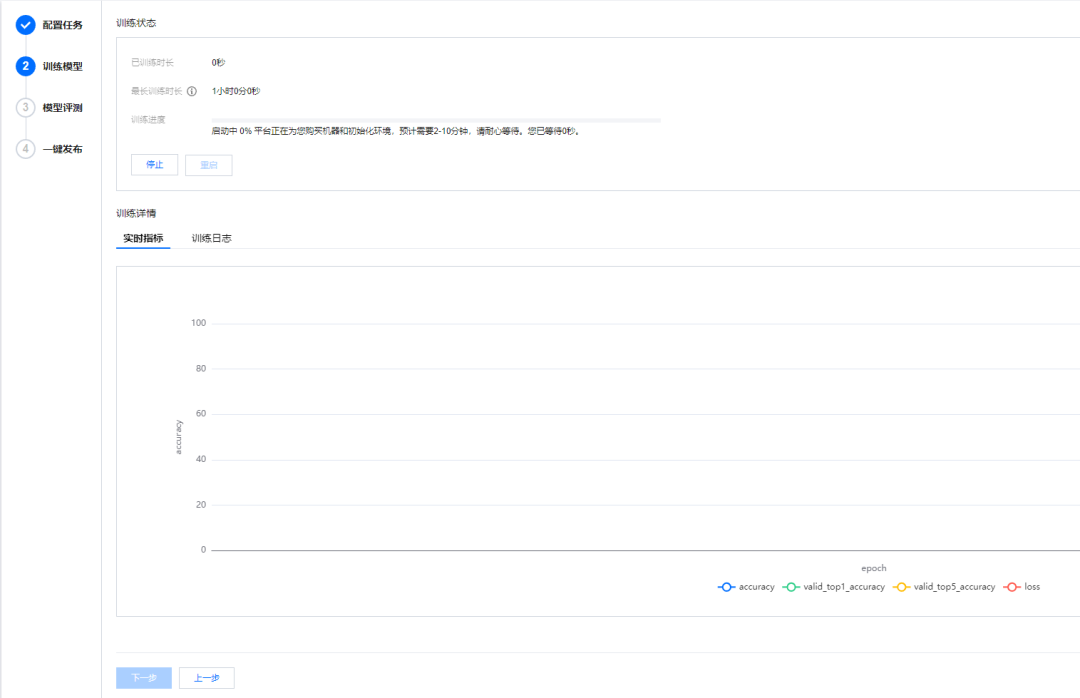
这种平台用起来,还是很方便的。
接下来就可以喝杯茶、泡杯咖啡,该干嘛干嘛,等 1 小时之后再回来看训练结果。
效果查看
我这个分类任务简单,所以训练很快,模型 5 分钟就收敛了。
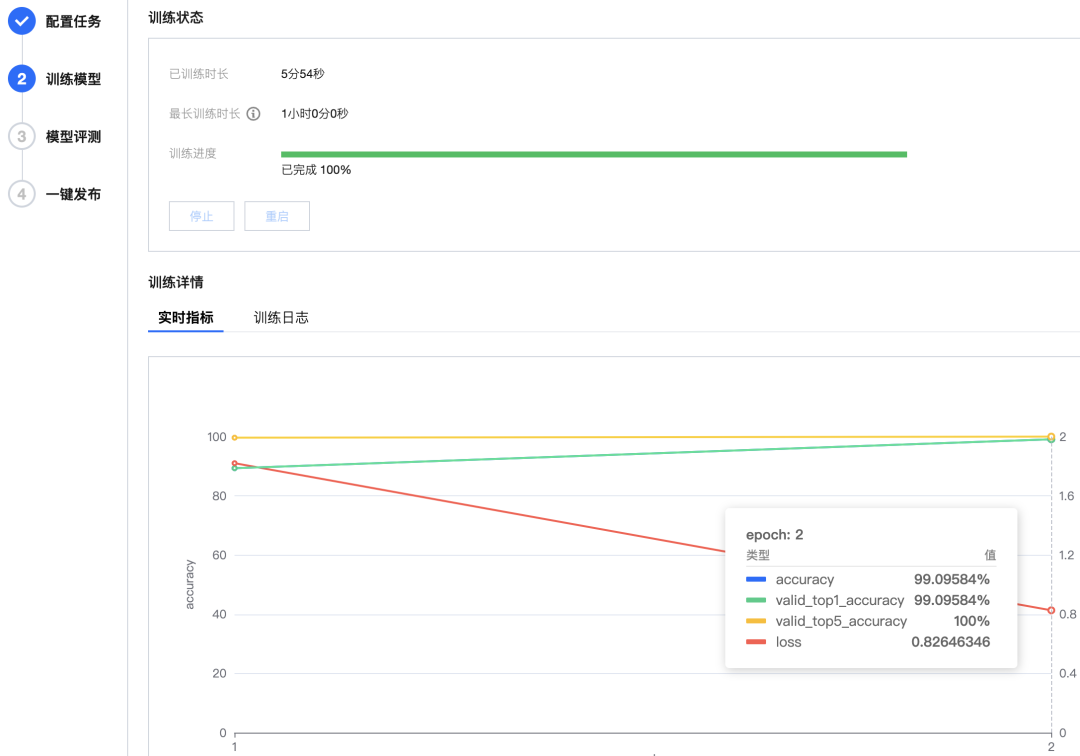
我猜内部应该是有个训练好的通用模型,直接在其上 fine-tune,所以又快又好。
然后也可以查看在测试集上的效果:
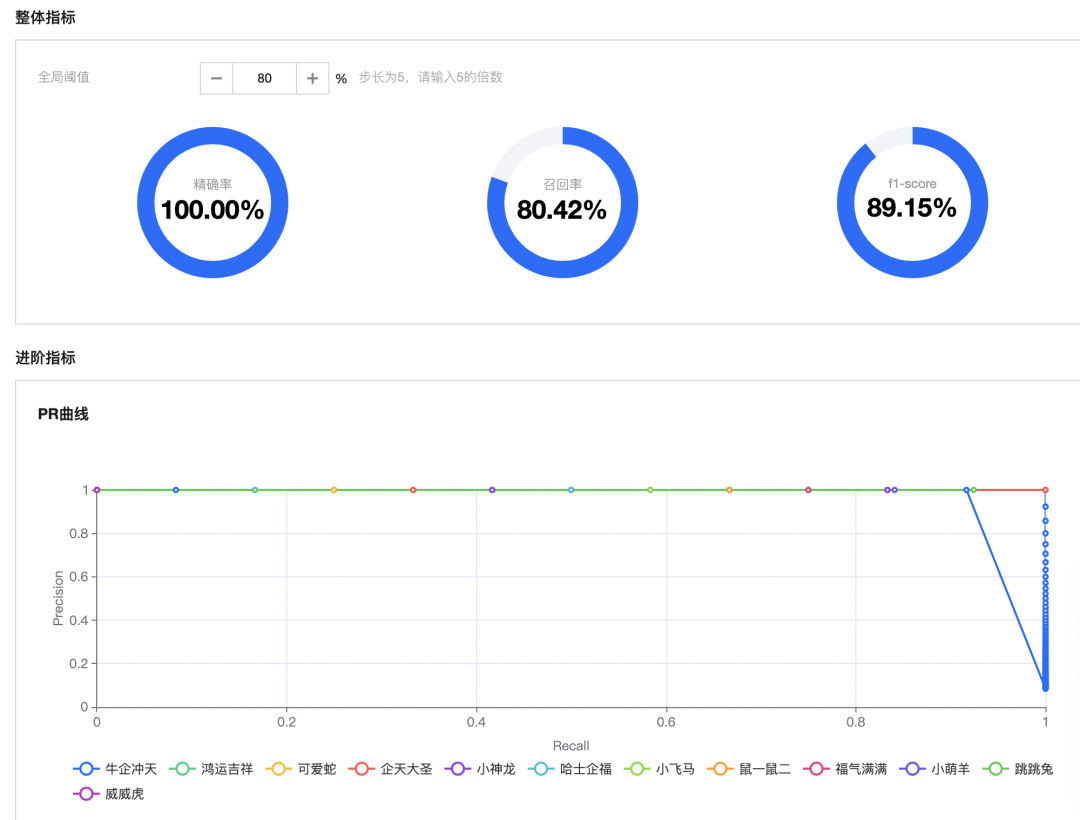
准确率、召回率、1-Score、PR曲线这些评估指标。
从结果可以看出,召回率有些低,因为数据少,可以补充一些数据再训练。
一般分类任务,不太复杂,每个类别准备一万张,在测试集上,准召怎么也都能 95% 以上。
这类分类任务,基本 1 小时,就收敛了。
感兴趣的小伙伴,有类似需求,又不想写太多代码,想快速完成任务,那完全可以试一试这个平台,方便好用。
后记
以上就是整个 TI-ONE 的体验,可以看到,整个过程非常方便快捷,有兴趣的同学也可以自行部署和体验。
昨天正好也参加了腾讯Techo Day技术开放日活动,看到了很多轻量化的云端工具,也分享了不少与之相关的技术原理及应用案例。
比如,使用 TI-ONE 训练自己的模型;使用Lighthouse快速构建属于自己的云端硬盘,搭建个个人网站,都很实用。
所有的资料和课件都被整合成了一份《腾讯云轻量级工具指南》,里面除了 TI-ONE 这种低门槛的 AI 平台以外,还有 Lighthouse 这类服务的使用,也涵盖了不少像如何利用Serverless实现事件驱动、如何基于Spring Cloud Tencent快速构建高可用轻量级微服务应用等课程及解决方案,能够帮助开发者实现降本提效,优化工作流程,感兴趣的朋友可以扫码领取课件资料。

可以直接点“阅读原文”下载查看。