 极市平台
极市平台





极市导读
通用视觉模型一般以序列的结构或者网格的结构来处理图片信息,本文作者创新性地提出以图的方式来处理图片:计算机视觉的一个基本任务是识别图像中的物体。本文提出一种基于图表示的新型通用视觉架构ViG,这是一个在通用视觉模型方面有价值的探索。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 Vision GNN:把一张图片建模为一个图
(来自中国科学院大学,华为诺亚方舟实验室,北大)
1.1 Vision GNN 原理分析
1.1.1 背景和动机
1.1.2 图片的图表示 (Graph Representation)
1.1.3 使用 GNN 作为模型骨干
1.1.4 ViG Block
1.1.5 实验结果
1.1.6 可视化结果
1.2 Vision GNN PyTorch 伪代码
1 Vision GNN:把一张图片建模为一个图

论文地址:https://arxiv.org/pdf/2206.00272.pdf
PyTroch代码:https://github.com/huawei-noah/Efficient-AI-Backbones
MindSpore代码:https://gitee.com/mindspore/models
1.1 Vision GNN 原理分析
本文提出了一种 GNN 通用视觉模型,是来自中国科学院大学,北京华为诺亚方舟实验室的学者们在通用视觉模型方面有价值的探索。
1.1.1 背景和动机
在现代计算机视觉任务中,通用视觉模型最早以 CNN 为主。近期 Vision Transformer,Vision MLP 为代表的新型主干网络的研究进展将通用视觉模型推向了一个前所未有的高度。
不同的主干网络对于输入图片的处理方式也不一样,如下图1所示是一张图片的网格表示,序列表示和图表示。图像数据通常表示为欧几里得空间 (Euclidean space) 中的规则像素网格,CNN 通过在图片上进行滑动窗口操作引入平移不变形和局部性。而 Vision Transformer,Vision MLP 为代表的新型主干网络将图片视为图片块的序列,比如一般将 224×224 大小的图片分为196个 16×16 的图片块。
但是无论是上面的网格表示还是序列表示,图片都以一种非常规则的方式被建模了,也就是说,每个图片块之间的 "联系" 已经固化。比如图1中这条 "鱼" 的 "鱼头" 可能分布在多个图片块中,这些 Patch 按照网格表示或者序列表示都没有 "特殊" 的联系,但是它们在语义上其实都表示 "鱼头"。这或许就是传统的图片建模方法的不完美之处。
本文提出以一种更加灵活的方式来处理图片:计算机视觉的一个基本任务是识别图像中的物体。由于图片中的物体通常不是形状规则的方形,所以经典的网格表示或者序列表示在处理图片时显得冗余且不够灵活。比如一个对象可以被视为由很多部分的组合:例如,一个人可以粗略地分为头部、上身、手臂和腿,这些由关节连接的部分自然形成一个图结构。
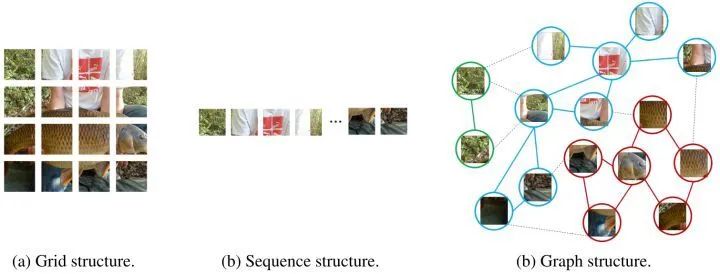
在网格表示中,像素或小块仅仅通过空间位置排序。在序列表示中,2D 图像被切分成为一系列小块。在图表示中,节点通过其内容链接起来,不受本地位置的约束。网格表示和序列表示都可以视为是图表示的特例。因此,将一张图片视为图是相对于前二者更加灵活且有效。
本文基于把图片视为图表示的观点,本文提出一种基于图表示的新型通用视觉架构 ViG。将输入图像分成许多小块,并将每个小块视为图中的一个节点。在构建好了输入图片的图表征之后,作者使用 ViG 模型在所有节点之间交换信息。ViG 的基本组成单元包括两部分:用于图形信息处理的 GCN (图形卷积网络) 模块和用于节点特征变换的 FFN (前馈网络) 模块。在图像识别,目标检测等视觉任务中证明了该方法的有效性。
1.1.2 图片的图表示 (Graph Representation)
对于一张大小为 大小的图片,首先分成 个 Patch。把每个 Patch 转化成向量 ,就可以得到 ,其中, 为 embedded dimension, 。这 个 Patch 的特征可以被视为一组无序结点,表示为 。对于每个结点 ,都找到 个最近邻结点 ,并添加一条从 ( ) 到 的边 。
这样就得到了一个图,表示为 ,其中 表示所有的边。通过这样的方式把 Image 建模成 Graph,就可以使用 GCN 处理图像数据了,如下图1所示。
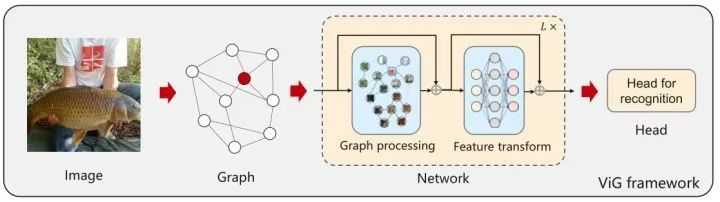
1.1.3 使用 GNN 作为模型骨干
总的来说,从特征 开始,作者首先构造一个图 。GCN 层可以通过聚合来自其邻居节点的特征来在节点之间交换信息。具体来说,GCN 的操作如下:
其中, 和 分别是聚合和更新操作的可学习的权重。具体而言,聚合操作通过聚合每一个节点周围所有的邻居节点的特征来计算当前节点的特征:
式中, 是节点 的相邻节点。这里,作者采用最大相对图卷积[1],因为它简单有效。
则以上的图维度的处理方法可以写成: 。
作者进一步引入了 multi-head 的结构,聚合之后的特征 被分为 个 head: ,然后每个 head 分别通过对应的权重进行更新,最终将 个 head 的结果 concat 在一起。
多头更新操作允许模型在多个表示子空间更新信息,有利于特征多样性。
1.1.4 ViG Block
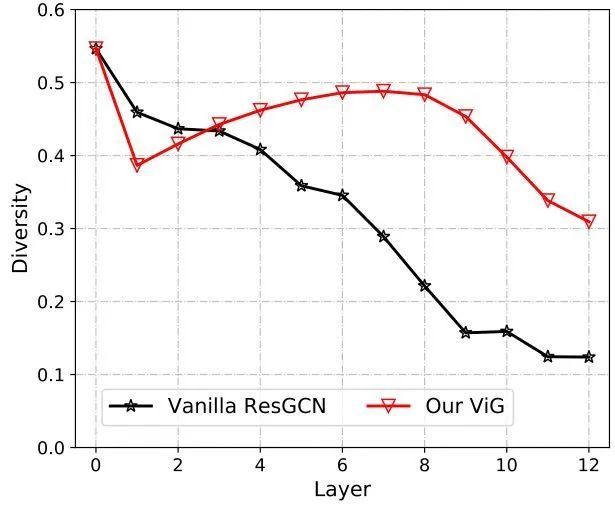
GCN 通过重复使用连续的几个图卷积层来提取图形数据的聚集特征。Deep GCN 中的过平滑现象会降低节点特征的独特性,并导致图像识别的性能下降。其中,多样性可以写成 ,其中 。为了缓解这个问题,我们在ViG块中引入了更多的特征变换和非线性激活。
作者在 GCN 之前和之后应用线性层,以将节点特征投影到同一域中,并增加特征多样性。在图形卷积后插入一个非线性激活函数以避免层特征的坍塌,得到的模块称为 Grapher 模块。可以表达成:
其中, , 和 是 FC 层的权重, 是激活函数。
Transformer 中常用的 FFN 层保持一致:
在 Grapher 和 FFN 模块中,在每个 FC 层或 GCN 层之后应用 BN,Grapher 模块和 FFN 模块的堆叠构成了 ViG模块,其用作构建网络的基本构建单元,如上图1所示。与 ResGCN 相比,ViG 的特征丰富度更高,如下图2所示。
1.1.5 模型架构
在计算机视觉领域,常用的 Transformer通常具有各向同性的架构,而 CNN 更喜欢使用金字塔架构。作者为 ViG 建立了两种网络结构,即各向同性结构和金字塔结构。
各向同性结构
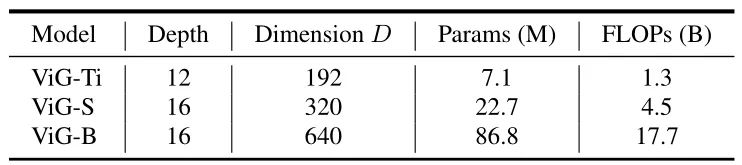
各向同性结构是指模型块从头到尾特征的尺寸都不发生变化。和 ViT,ResMLP 保持一致,作者设计了 ViG-Ti,ViG-S,ViG-B 三种不同的模型。节点数为 Patch 数196,为了逐渐扩大感受野,在这三个模型中,随着层的深入,邻居节点 的数量从9线性增加到18。默认情况下,head 数设置为 。
金字塔结构
金字塔结构模型的特征图随着网络的深入而逐渐变小,已经被很多视觉 Transformer 模型 (如 PVT[2],Swin [3]等) 证明是有效的性能提升的手段。因此,作者进一步建立了四个版本的金字塔 ViG 模型,如下图4所示。
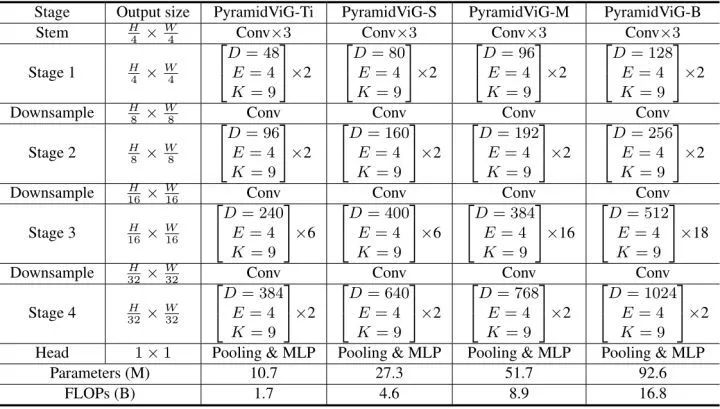
位置编码
为了表示节点的位置信息,作者对每个节点特征添加位置编码向量:
式中, 。
绝对位置编码适用于各向异性和金字塔结构。对于金字塔 ViG,作者遵循 Swin Transformer 的设计方法,进一步使用相对位置编码。对于节点 和 ,它们之间的相对位置距离是 ,这个相对位置距离会被添加到图的特征距离中。
1.1.5 实验结果
作者在 ImageNet 图像分类任务和 COCO 目标检测任务上验证了 ViG 的有效性。不同尺寸模型的实验设置如下。对于 COCO 目标检测任务,作者使用 RetinaNet 和 Mask R-CNN 作为检测框架,Pyramid ViG 作为骨干网络。训练策略采用 "1×" schedule。
ImageNet 图像分类任务
具有各向同性结构的神经网络在模型前向传播中保持特征大小不变,易于扩展,并且有利于硬件加速。实验结果如下图6所示。与同样尺寸的其他各向同性结构的 CNN,Transformer,或者 MLP 模型相比,ViG 性能更好。
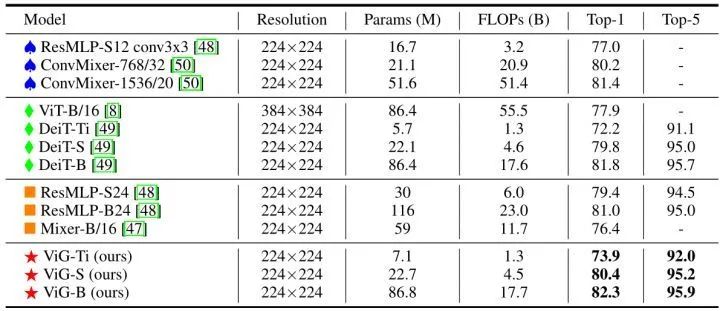
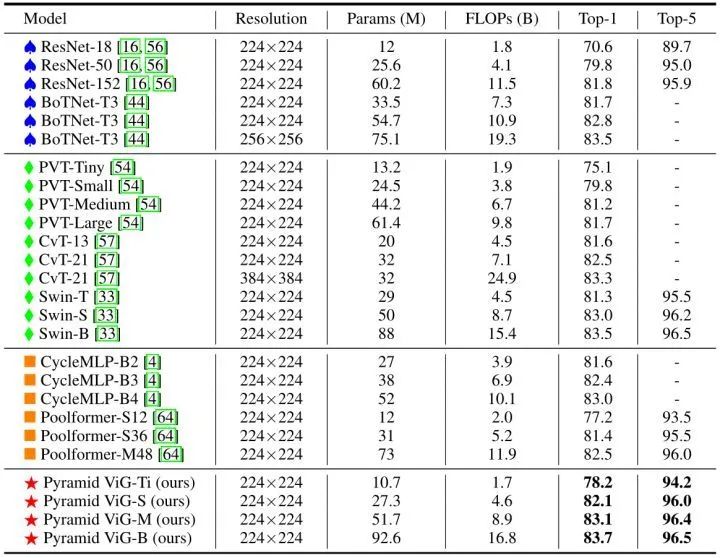
金字塔结构随着网络的深入,特征图逐渐变小,可以形成多尺度的特征。作者进一步将 Pyramid ViG 模型和几种典型的金字塔式 CNN,Transformer,MLP 模型进行比较,结果表明 ViG 系列可以超越或媲美最先进的金字塔网络,结果如下图7所示。这表明图形神经网络能很好地完成视觉任务,有潜力成为计算机视觉系统的基本组成部分。
消融实验
作者使用各向同性的 ViG-Ti 作为基础架构,在 ImageNet 分类任务上进行了消融实验。
消融实验1:图卷积的类型
作者测试了图卷积的代表性变体,包含:EdgeConv,GIN,GraphSAGE 和 Max-Relative GraphConv,结果如下图8所示。从图8中我们可以看到不同图卷积的 Top-1 精度优于 DeiT-Ti,表明了 ViG 架构的灵活性。其中Max-Relative 实现了 FLOPs 和精度的最佳权衡。因此本文实验默认使用 Max-Relative GraphConv 作为图卷积方案。
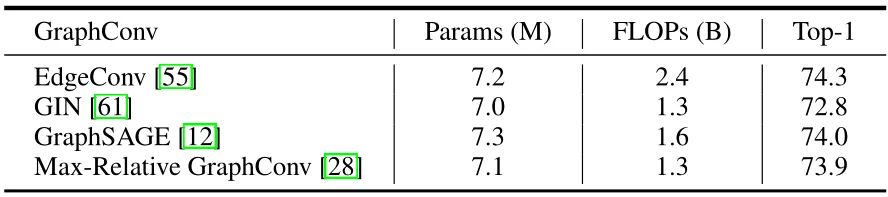
消融实验2:ViG 中不同模块的影响
为了使图形神经网络适应视觉任务,作者在 Grapher 模块中引入了 FC 层,并利用 FFN 块进行特征变换,通过消融研究来评估这些模块的效果,如下图9所示。可以看出,直接利用图卷积进行图像分类的效果很差。通过引入 FC 层和 FFN 来增加更多的特征变换,可以使得精度不断提高。

消融实验3:neighbors 数量的影响
在构建图的过程中,邻居节点数 是一个控制聚集范围的超参数。太少的邻居会降低信息交换的幅度,而太多的邻居会导致过平滑现象的出现。作者将 从3调至20,结果如图10所示。我们可以看到,在9到15范围内的邻居节点数可以很好地执行 ImageNet 分类任务。

消融实验4:head 数量的影响
multi-head 操作允许 Grapher 模块在不同的子空间中处理对应的节点特征。作者将 head 数从1调至8,结果如下图11所示。head 数量控制着子空间的多样性。对于不同的 head,ImageNet 上的 FLOPs 和 Top-1 精度略有不同。作者选择 作为默认值,以实现 FLOPs 和精度之间的最佳平衡。

目标检测实验结果
下图12是 COCO val2017 上的实验结果。为了进行公平的比较,作者使用 ImageNet 预训练的金字塔 ViG-S 作为 RetinaNet 和 Mask R-CNN 检测框架的主干。使用常用的 "1×" schedule 进行训练,以 1280×800 的输入大小计算 FLOPs。从下图12中的结果可以看出,金字塔 ViG-S 在 RetinaNet 和 Mask R-CNN 上的表现都优于ResNet,CycleMLP 和 Swin Transformer 等主干模型。
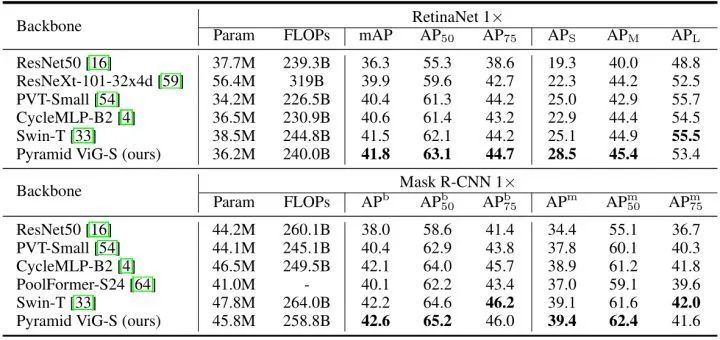
1.1.6 可视化结果
为了更好地理解 ViG 模型是如何工作的,作者在 ViG-S 中可视化了图结构。图13展示的是2个不同的样本在网络的不同深度中的图表示。五角星形是中心节点,颜色相同的节点是它的邻居,作者为了更简洁只画了两个顶点。这里有一个很有趣的现象:模型可以选择内容相关的节点作为一阶邻居。在浅层中,邻居节点倾向于基于低级和局部特征 (比如鱼的颜色和背景树木的纹理) 来选择。在深层中,中心节点倾向于选择语义信息更加接近的节点作为邻居,属于同一类别 (比如纸筒和卫生纸)。

1.2 Vision GNN PyTorch 伪代码
1) 导入必要的库

2) Grapher 模块伪代码


上式5中的 里面的 和 分别对应伪代码中的 self.fc1 和 self.fc2,二者都是由 nn.Conv2d(kernel=1) 进行实现,并在后面加上 nn.BatchNorm2d。
GCN 部分使用了https://github.com/lightaime/deep_gcns_torch中的 DynConv2d(in_channels, hidden_channels, k, dilation, act=None),激活函数 使用的是 nn.GeLU()。
3) FFN 模块伪代码
Linear Transformation 操作使用了 nn.Conv2d(kernel=1) 进行实现,并在后面加上 nn.BatchNorm2d 进一步执行归一化操作。

总结
通用视觉模型一般以序列的结构或者网格的结构来处理图片信息,本文作者创新性地提出以图的方式来处理图片:计算机视觉的一个基本任务是识别图像中的物体。由于图片中的物体通常不是形状规则的方形,所以经典的网格表示或者序列表示在处理图片时显得冗余且不够灵活。本文提出一种基于图表示的新型通用视觉架构 ViG。将输入图像分成许多小块,并将每个小块视为图中的一个节点。基于这些节点构造图形可以更好地表示不规则复杂的物体。
在构建好了输入图片的图表征之后,作者使用 ViG 模型在所有节点之间交换信息。ViG 的基本组成单元包括两部分:用于图形信息处理的 GCN (图形卷积网络) 模块和用于节点特征变换的 FFN (前馈网络) 模块。直接在图像图形结构上使用图形卷积存在过平滑问题,性能较差。因此作者在每个节点内部引入了更多的特征变换来促进信息的多样性。在图像识别,目标检测等视觉任务中证明了该方法的有效性。
参考
^Deepgcns: Can gcns go as deep as cnns? ^Pyramid vision transformer: A versatile backbone for dense prediction without convolutions ^Swin transformer: Hierarchical vision transformer using shifted windows
公众号后台回复“数据集”获取30+深度学习数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选



