 机器学习算法工程师
机器学习算法工程师




 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
我们在上一篇文章介绍了CLIP模型,它基于图像和文本特征对齐的方式构建了连接文本和图像的多模态模型,可以实现非常强的zero-shot能力,这篇文章我们将简单介绍Google最近的一篇工作CoCa: Contrastive Captioners are Image-Text Foundation Models。相比CLIP,CoCa在对比学习之外增加了生成式任务,即生成图像对应的文本描述,这其实也是CLIP尝试过的方法,但是限于训练效率而只采用了对比任务。将对比和生成式任务结合在一起的CoCa不仅能像CLIP那样应用于图像和文本的对齐任务(图像zero-shot识别,图像和文本检索),而且还可以应用在图像和文本的多模态理解任务,如图像字幕生成(Image Captioning)和视觉问答(Visual Question Answering,VQA),可谓是全能型多模态模型。更重要的一点,CoCa在这些下游应用任务上实现了更好的性能,其中在ImageNet-1K数据集上,**基于CoCa预训练的10亿参数的Image Encoder实现了86.3%的zero-shot效果,经过finetune后达到了新的SOTA:91.0%**。
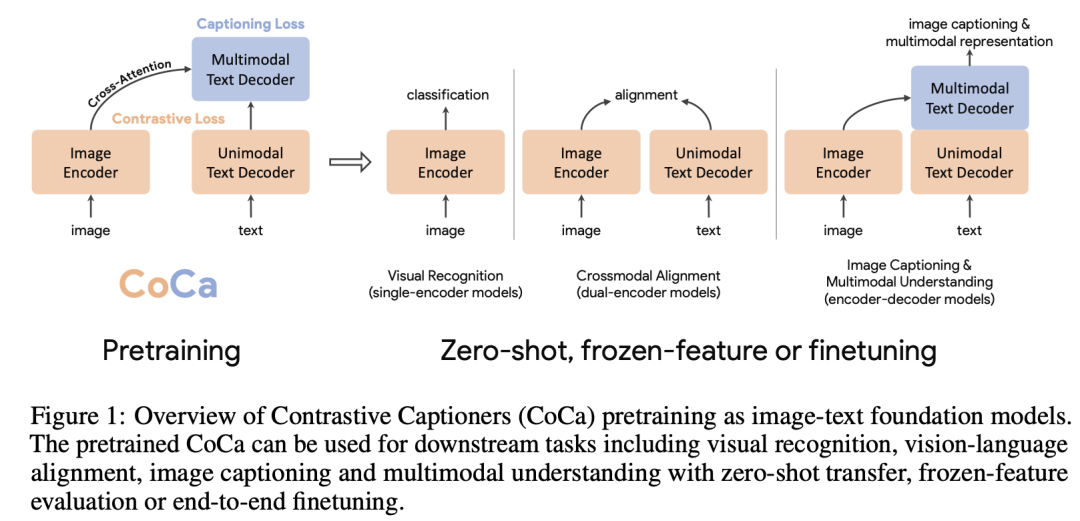 在这篇文章,作者首先将构建图像和文本的多模态基础模型的方法总结为三种,它们的主要区别是将自然语言作为监督信号的处理方式不同。
在这篇文章,作者首先将构建图像和文本的多模态基础模型的方法总结为三种,它们的主要区别是将自然语言作为监督信号的处理方式不同。
Single-Encoder Classification
单个encoder的方式是通过在一个大规模的图像标注数据集(如ImageNet或者JFT)进行图像分类来预训练一个图像encoder,这里采用的自然语言监督信号是图像的类别描述,而标注文本的词汇量是固定的,或者说类别数固定。我们通常需要将图像的类别描述转成离散的类别标签,比如ImageNet-1K数据集的类别标签是[0, 1000],然后通过交叉熵分类损失来进行训练:
这其实就是经典的大规模图像分类预训练,严格来讲并不是多模态模型,因为最后只能得到了图像的encoder,也只能应用在一些纯视觉的任务,如图像分类和视频分类等。
Dual-Encoder Contrastive Learning
第二种就是CLIP,它包括两个encoder,一个是图像encoder,一个是文本encoder,训练数据是图像-文本对,不同于图像分类任务的精细类别标注,这里的文本是图像的可包含噪音的一段描述,这样训练数据可以来自于网上的大规模图文数据。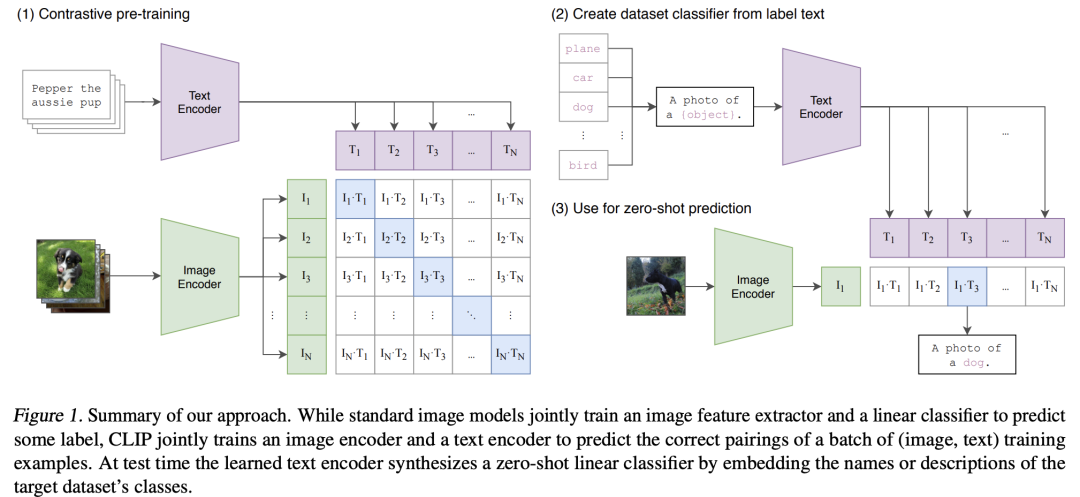 对于图像-文本对,分别用图像encoder和文本encoder提取图像特征和对应的文本特征,然后采用对比学习来进行训练:
对于图像-文本对,分别用图像encoder和文本encoder提取图像特征和对应的文本特征,然后采用对比学习来进行训练:
CLIP的图像encoder可以应用在视觉任务上。同时由于CLIP连接了图像和文本,所以CLIP可以应用在图像和文本的对齐任务上,比如用基于文本来检索图像,另外基于文本和图像的对比,CLIP可以实现zero-shot图像分类,这也是单个encoder所无法实现的。但是CLIP由于没有生成模块所以并不能直接用于多模态理解任务,如视觉问答。
Encoder-Decoder Captioning
那最后一种就是基于encoder和decoder的架构,它采用的是生成式任务,首先用图像encoder来提取图像的编码特征(不是全局特征),然后基于图像的编码特征采用文本decoder来自回归地生成图像对应的文本。Google之前的工作SimVLM就是采用这种架构。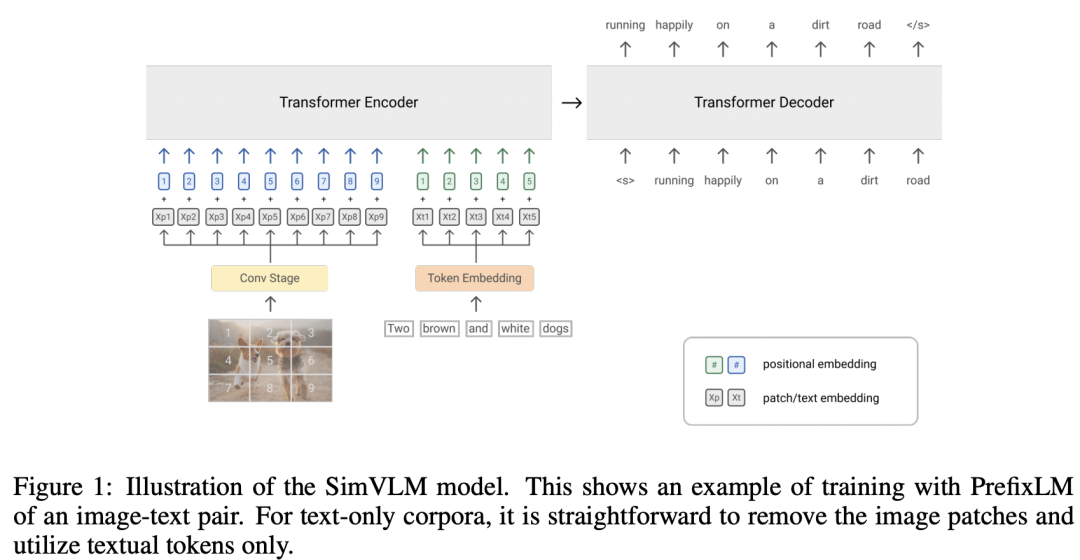
这里的训练损失如下所示,这里的图像编码特征相当于条件,然后基于自回归的方式(基于前面的文本预测下一个单词)最大化每个文本token的生成概率:
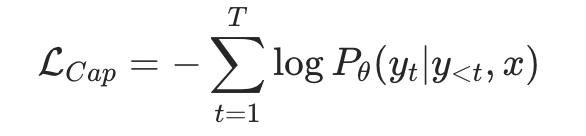
 生成式任务要比对比学习任务更难,因为要精确地预测每个文本的单词,CLIP中也提到对于直接来自网上的图文数据采用生成式任务其训练效率更低,这也主要是因为这些图文对数据噪音较大。虽然这种架构可以执行生成式任务,但是它却不能直接应用在一些图像和文本对齐的任务,如像CLIP那样基于文本检索图像。
生成式任务要比对比学习任务更难,因为要精确地预测每个文本的单词,CLIP中也提到对于直接来自网上的图文数据采用生成式任务其训练效率更低,这也主要是因为这些图文对数据噪音较大。虽然这种架构可以执行生成式任务,但是它却不能直接应用在一些图像和文本对齐的任务,如像CLIP那样基于文本检索图像。那么能不能将对比学习和生成式学习结合在一起呢?答案是肯定的,这也是CoCa的核心思路。如下图所示,CoCa也是构建在encoder-decoder基础上,不过这里将text decoder均分成两个部分:unimodal text decoder和multimodal text decoder。然后增加一个cls token在文本的最后,unimodal text decoder不参与对图像特征的cross-attention,这样cls token经过unimodal text decoder之后就能够得到整个句子的全局特征。同时采用attention pooling对image encoder得到特征提取图像的全局特征,两个全局特征就可以实现图像-文本的对比学习,这里的attention pooling其实就是一个multi-head attention,只不过key和value是image encoder得到的特征,而query是预先定义的一个可训练的embedding,由于我们只需要提取一个全局特征,所以只需要定义一个query就好了。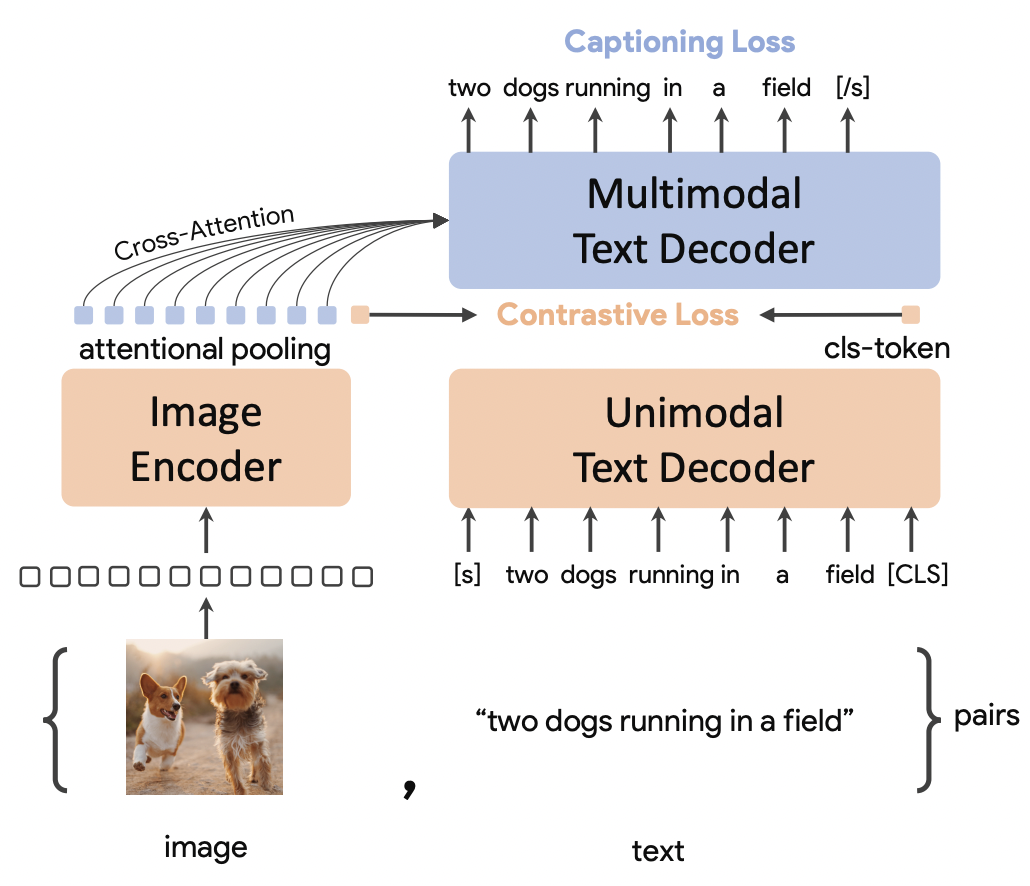 multimodal text decoder将用来执行生成任务,这里也通过一个attention pooling对image encoder得到的特征进行提取,不过这里query数量定义为256,这样attention pooling可以得到256个特征,它作为multimodal text decoder的cross-attention的输入。CoCa的伪代码如下所示:
multimodal text decoder将用来执行生成任务,这里也通过一个attention pooling对image encoder得到的特征进行提取,不过这里query数量定义为256,这样attention pooling可以得到256个特征,它作为multimodal text decoder的cross-attention的输入。CoCa的伪代码如下所示: 所以,CoCa将同时执行对比学习和文本生成任务,它的训练损失也包括两个部分:
所以,CoCa将同时执行对比学习和文本生成任务,它的训练损失也包括两个部分:
CoCa采用的模型架构如下所示,其中Image Encoder和Text Decoder均采用Transformer模型,其中Image Encoder的参数量为1B,而Text Decoder的参数量达到1.1B,这样整个CoCa模型的参数量为2.1B。对于图像,其输入大小为288×288,而patch size为18x18,这样总共有256个image tokens。同时,这里也设计了两个更小模型:CoCa-Base和CoCa-Large。 这里要重点说一下训练CoCa模型所采用的数据,它包含两个部分:一部分是ALIGN数据集,它包含从互联网上收集的1.8B的图像-文本对;另外一部分是JFT-3B数据集,这里将图像的类别名转成一个文本描述,具体地是采用CLIP中所用的prompt生成一个文本,比如
这里要重点说一下训练CoCa模型所采用的数据,它包含两个部分:一部分是ALIGN数据集,它包含从互联网上收集的1.8B的图像-文本对;另外一部分是JFT-3B数据集,这里将图像的类别名转成一个文本描述,具体地是采用CLIP中所用的prompt生成一个文本,比如a photo of the cat, animal。这里是将两部分数据混合在一起进行端到端的训练。CoCa不仅可以应用在视觉任务,如图像分类和视频分类,还可以像CLIP一样实现图像-文本检索,以及实现zero-shot图像分类,同时还可以用于多模态理解任务,如图像字幕生成和视觉问答。下图为CoCa与其它模型在不同任务上的效果对比,可以看到CoCa在各个任务均取得更好的效果。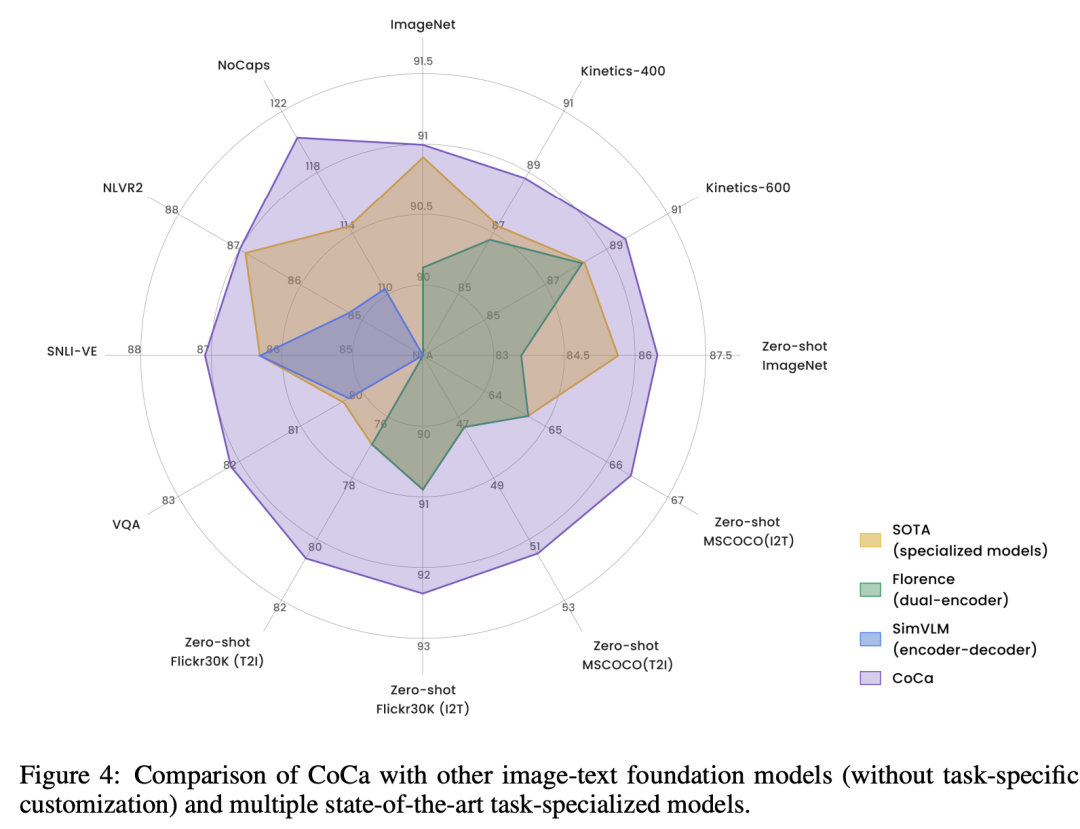 其中在ImageNet-1K数据集上,zero-shot效果可以达到86.3%,而finetune后达到了91.0%,这超过了之前所有的模型。
其中在ImageNet-1K数据集上,zero-shot效果可以达到86.3%,而finetune后达到了91.0%,这超过了之前所有的模型。
从CLIP到CoCa,相信基于大规模数据预训练的多模态模型将越来越成为一种趋势。
参考
CoCa: Contrastive Captioners are Image-Text Foundation Models SimVLM: Simple Visual Language Model Pretraining with Weak Supervision https://github.com/lucidrains/CoCa-pytorch https://jalammar.github.io/illustrated-gpt2/ Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号



