昨天,谷歌提交的一篇论文引发了机器学习圈的关注,其提出的语言模型学会了人类做数学题时的方法「一步一步推理」。在 MATH 数据集上,谷歌的新模型能实现 50% 的准确率——此前对人类的评测结果是:「一个不特别喜欢数学的计算机科学博士生能答对大约 40%,而三届国际数学奥林匹克竞赛(IMO)金牌得主能达到 90%。」
语言模型在各种 NLP 任务上都表现出了卓越的性能。事实上,在众多研究中科研人员总结出一条经验,即以无监督方式在大规模不同数据上训练的神经网络,在不同任务上表现更好。这条经验也适用于 BERT、GPT-3、Gopher 和 PaLM 在内的模型。和人类相比,在定量推理方面,语言模型的差距还很大。想让语言模型能够解决数学和科学类问题,语言模型还需要掌握各种综合技能,这些技能包括模型能够利用自然语言和数学符号正确解析问题、可以准确利用相关公式和常数、以及生成涉及数值计算和符号操作的解决方案。但这些都面临着挑战,人们通常认为,使用机器学习来解决定量推理问题,需要在模型架构和训练技术方面取得显著进步,这样一来允许模型访问外部工具,如 Python 解释器。在 Google Research 提交的这篇论文中,他们推出了语言模型 Minerva,该模型能够解决数学和科学问题,让模型一步一步来。通过收集与定量推理问题相关的训练数据、大规模训练模型,以及使用先进的推理技术,该研究在各种较难的定量推理任务上取得了显著的性能提升。
论文地址:https://storage.googleapis.com/minerva-paper/minerva_paper.pdfMinerva 通过生成解决方案来解决问题,解决方案包括数值计算、符号操作,而不需要依赖计算器等外部工具。Minerva 将自然语言和数学符号进行结合来解析和回答数学问题。此外,Minerva 还结合了多种技术,包括小样本提示、思维链、暂存器提示以及多数投票原则,从而在 STEM 推理任务上实现 SOTA 性能。此次,谷歌还提供了交互式示例浏览器来探索 Minerva 的输出!从 Minerva 浏览器界面可以看出,Minerva 不仅可以解决代数问题,还能解决物理、数论、几何、生物、化学、天文学等众多问题。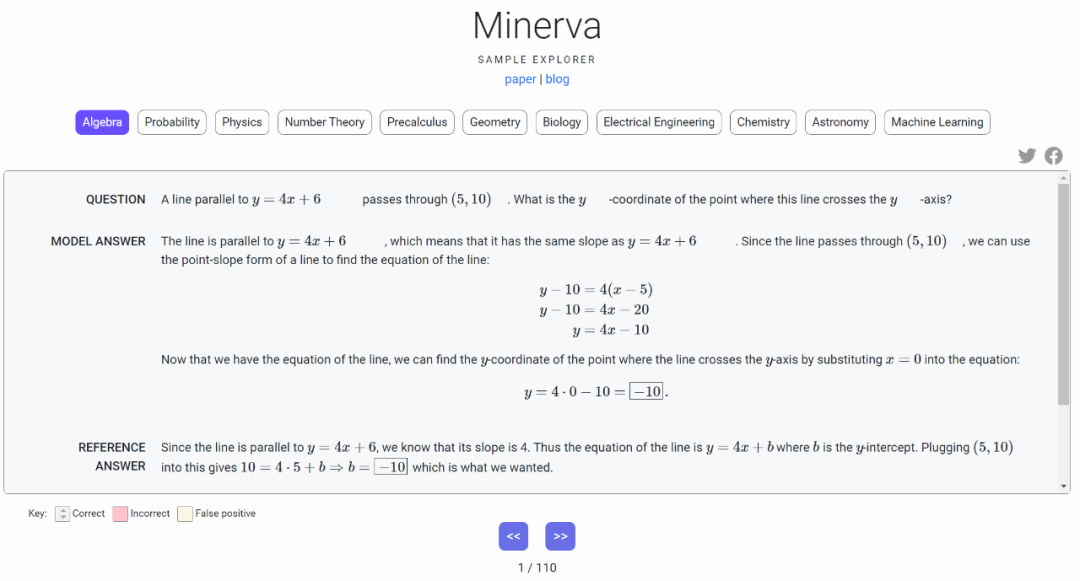
试用地址:https://minerva-demo.github.io/#category=Algebra&index=1下面是 Minerva 解决几何问题,立方体的每个边都是 3 英寸长,求立方体的总表面积是多少平方英寸?模型回答:由于立方体有 6 个面,每个面是一个边长为 3 英寸的正方形,总表面积为 (6)(3)^2=54。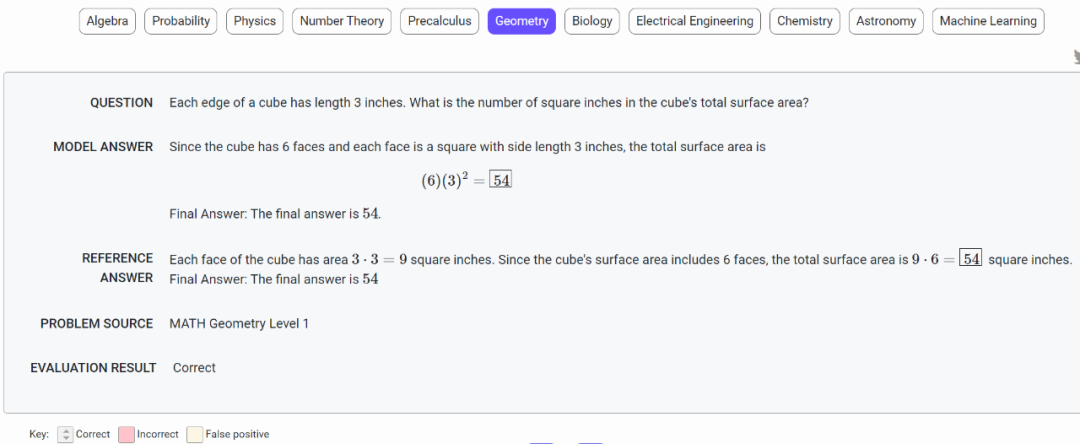
Minerva 解决数学问题:平行于 y=4x+6 的线,且穿过 (5,10)。问这条线与 y 轴相交的点的 y 坐标是多少?下面是 Minerva 解答过程:
Minerva 建立在 PaLM(Pathways Language Model ) 的基础上,在 118GB 数据集上进一步训练完成,数据集来自 arXiv 上关于科技方面的论文以及包含使用 LaTeX、MathJax 或其他数学表达式的网页的数据进行进一步训练。训练之后模型学会使用标准数学符号进行对话。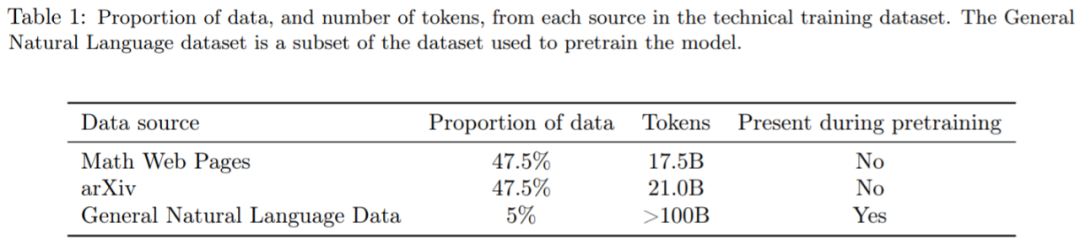
下表 2 包含了 Minerva 主要的模型和训练超参数,最大的模型具有 540B 参数,在 26B token 上进行了微调。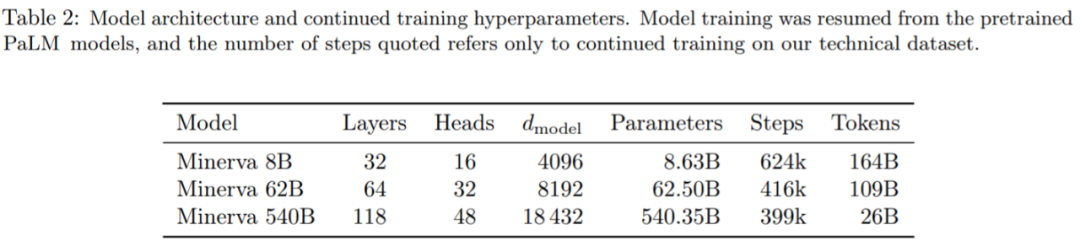
Minerva 语言模型的不同变体,包括 8B,62B 和 540B。下图为印度高中学生参加的 2020 年联合入学数学考试(左),这个考试每年有近 200 万参加;波兰国家数学考试(2022 年 5 月)(右),每年约有 27 万高中生参加。以下是 Minerva 答题过程,就像考生一样,分步计算答案:
下图为用于定量推理的数据集:研究者在数据处理过程中保留了数学信息,使模型能够在更高的水平上学习数学。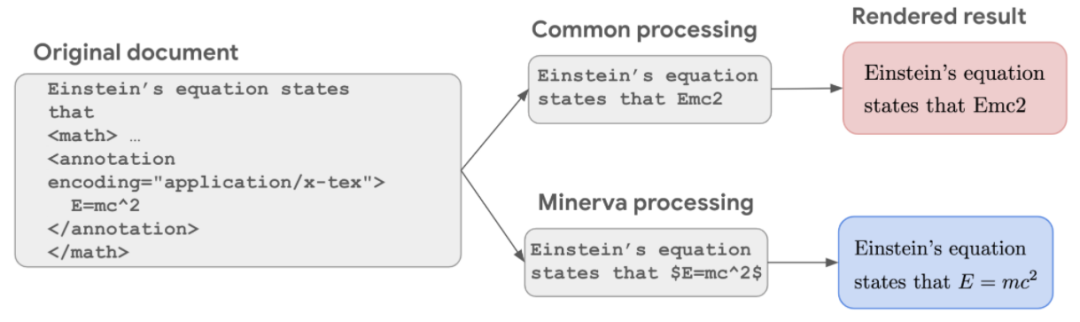
Minerva 还结合了最新的提示和评估技术,以更好地解决数学问题,包括思维链或 scratchpad 提示。在回答新问题之前,Minerva 会将解决方案进行分解,进行多数投票。像大多数语言模型一样,Minerva 将可能输出分配不同的概率。在回答问题时,Minerva 不是将单个解决方案得分视为最有可能,而是通过从所有可能的输出中随机抽样来生成多个解决方案。这些解决方案是不同的(例如,步骤不相同),但通常会得出相同的最终答案。Minerva 对这些解决方案使用多数投票,将最常见的结果作为最终答案。
多数投票 Minerva 为每个问题生成多个解决方案,并选择最常见的答案作为解决方案,显著提高性能。为了测试 Minerva 的定量推理能力,谷歌在不同的 STEM 基准上进行了评估,覆盖从小学水平的问题到研究生水平的课程。使用的基准数据集包括如下:- MMLU-STEM:大规模多任务语言理解(MMLU)基准中专注于 STEM 的子集,涵盖了高中和大学级别的工程、化学、数学和物理等;
- GSM8k:小学水平的数学题,包括基础算数运算等。
此外,谷歌还在 OCWCourses 上评估了 Minerva,这是一个大学和研究生水平的问题集合,涵盖了从 MIT OpenCourseWare 中收集的固态化学、天文学、微分方程和狭义相对论等各种 STEM 主题。结果表明,在所有数据集的评估中,Minerva 都实现了 SOTA 结果,有时甚至是大幅提升。下图为 MATH 和 MMLU-STEM 上的评估结果,其中高中和大学级别的问题涵盖了一系列 STEM 主题。可以看到,Minerva 62B 和 Minerva 540B 在 MATH 上的准确率均高于已有 SOTA,Minerva 540B 在 MMLU-STEM 上均高于已有 SOTA。
总体来看,Minerva 540B 在小学、高中和大学级别的 STEM 评估数据集上,均取得了显著优于已有 SOTA 的结果。
与 PaLM 8B、62B 和 540B 的更详细比较结果如下表所示。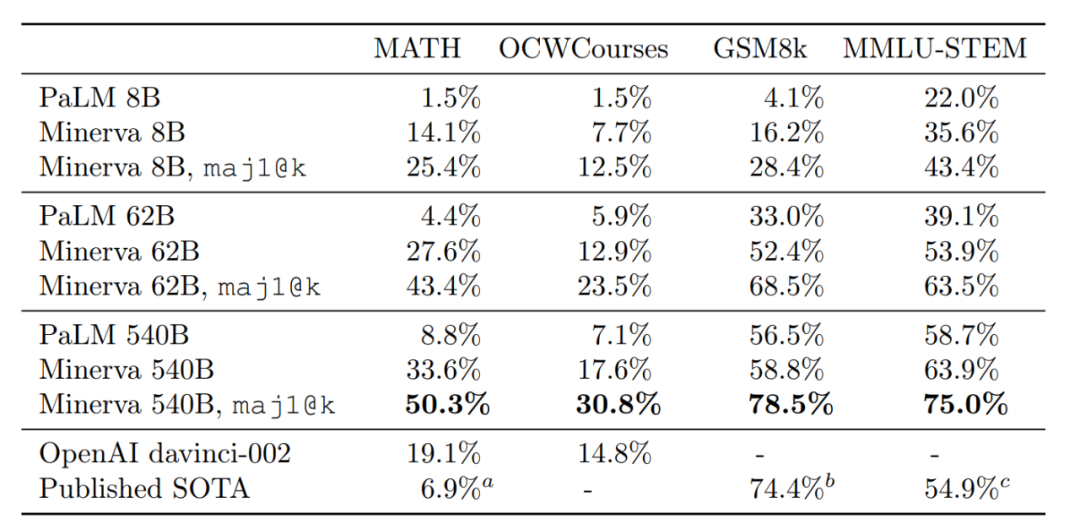
谷歌研究科学家、论文作者之一 Aitor Lewkowycz 给出了更具体的评估示例。他们在 2022 年波兰国家数学考试中对 Minerva 进行了评估,它解决了 80% 以上的 GCSE 高等数学问题,评估了 MIT 的各种本科级别的 STEM 问题并解决了其中的近三分之一。
不过,Minerva 仍然犯了很多错误。为了更好地确认模型可以改进的领域,谷歌分析了模型出错的问题样本,发现大多数错误很容易解释。结果表明,大约一半是计算错误,另一半是推理误差,原因是解决步骤没有遵循逻辑思考链。
同时,Minerva 也有可能得出正确的最终答案,但推理依然错误。谷歌将这种情况称为「误报」,因为它们被错误地计入到了模型的整体性能得分。分析结果显示,误报率相对较低,Minerva 62B 在 MATH 数据集上的平均误报率低于 8%。
谷歌提供了 Minerva 出错的一些样本示例。比如下图中的计算错误,模型错误地消去了方程两边的平方根。
下图为推理错误,模型在第四次练习中计算了罚球次数,但之后却将这一数字作为第一次练习的最终答案。
谷歌的定量推理方法并不是以形式数学为基础。Minerva 使用自然语言和 LaTeX 数学表达式的组合来解析问题并生成答案,没有明确的底层数学结构。因此,这种方法存在一个重要局限,模型的答案无法获得自动验证。即使最终答案已知并且可以验证,模型也可以使用错误的推理步骤得出正确的最终答案,而这无法自动检测到。这种局限在 Coq、Isabelle、HOL、Lean、Metamath 和 Mizar 等形式化定理证明方法中不存在。另一方面,非形式方法的一个优势是它可以应用在高度多样化的问题中。未来,谷歌希望能够解决定量推理问题的通用模型推动科学和教育的前沿发展。定量推理模型具有很多潜在的应用,包括为研究人员提供有用的帮助,为学生提供新的学习机会。Minerva 模型朝着这些目标迈出了一小步。https://ai.googleblog.com/2022/06/minerva-solving-quantitative-reasoning.html
© THE END
- 机器学习交流qq群955171419,加入微信群请扫码
