
Meta再放大招!VR新模型登CVPR Oral:像人一样「读」懂语音
新智元
共 3884字,需浏览 8分钟
· 2022-07-04

新智元报道
新智元报道
编辑:David Joey 如願
【新智元导读】畅游元宇宙,连音画不匹配那还算VR?Meta最近就盯上了这个问题。|人工智能企业在找落地场景?——智能技术企业科技信用评级共识体系发布会7月2日给你解答!

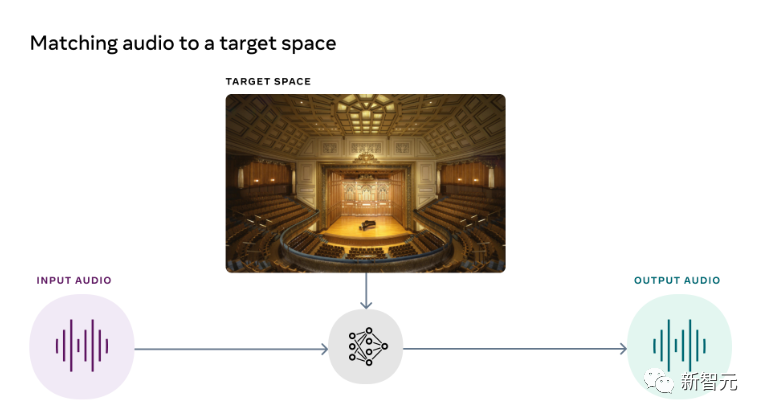
视觉和声音的完美盛宴
视觉和声音的完美盛宴




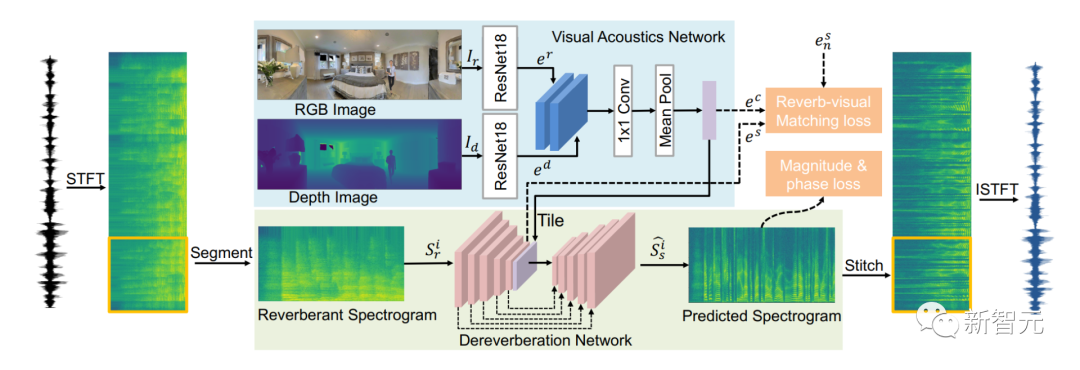
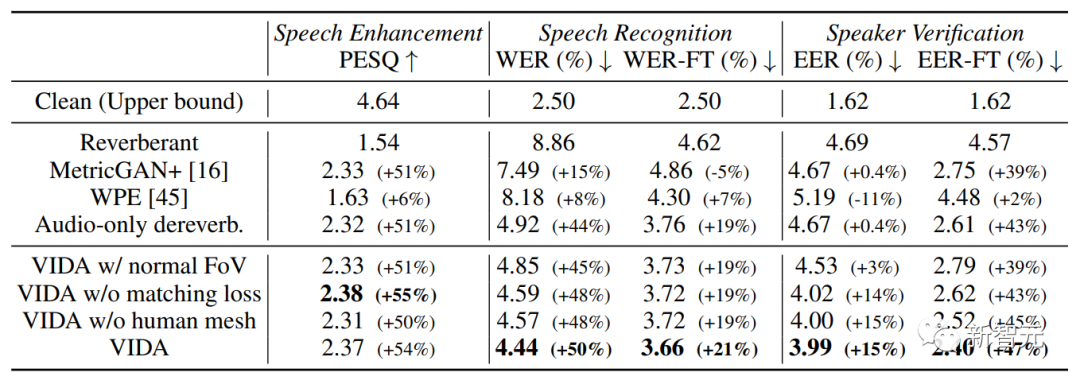
利用视觉信息,去除混响
利用视觉信息,去除混响

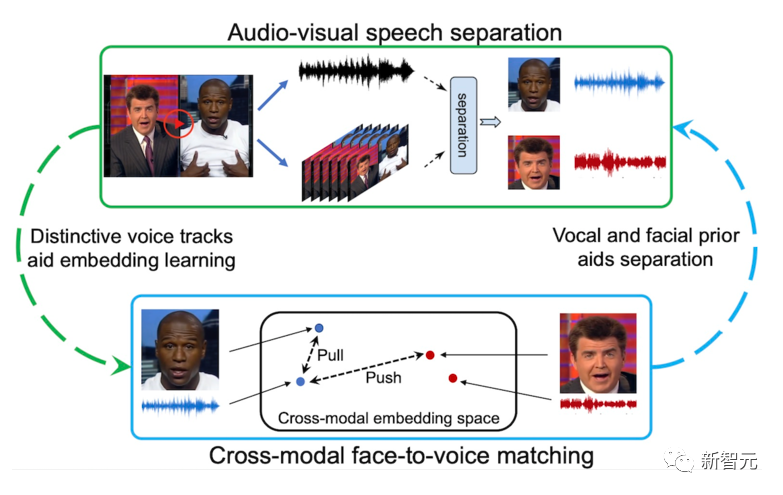
VisualVoice:通过看和听,理解语音
VisualVoice:通过看和听,理解语音


评论