
用香蕉驱动一个随机数生成器,靠谱吗?
数据派THU
共 4751字,需浏览 10分钟
· 2022-07-01

来源:大数据文摘 本文约3500字,建议阅读7分钟
香蕉的用途又增加了!

每个数字出现在列表中的概率必须与其他每个数字相同(取一个参考区间),也即均匀分布。 数字的序列必须是事先无法预测的。


#include <stdio.h>#include <assert.h>#include <stdlib.h>#include <stdint.h>int main(int argc, char const *argv[]) {FILE * lettura = fopen("textsample.txt", "r");assert(lettura != NULL);FILE * scrittura = fopen("sample.txt", "wb");assert(scrittura != NULL);uint16_t N = 0; //N is 16 byteschar bytes[2];char buffer[6]; // 5 char + terminatordo{fscanf(lettura,"%s",buffer); // put one line in the bufferN = atoi(buffer); // from char array to integerbytes[0] = (N >> 8); // take the 8 msbbytes[1] = (N & 0xFF); // take the 8 lsbfwrite(bytes, 1, sizeof(bytes), scrittura); // output raw msb and lsb}while (!feof(lettura));fclose(lettura);fclose(scrittura);return 0;}
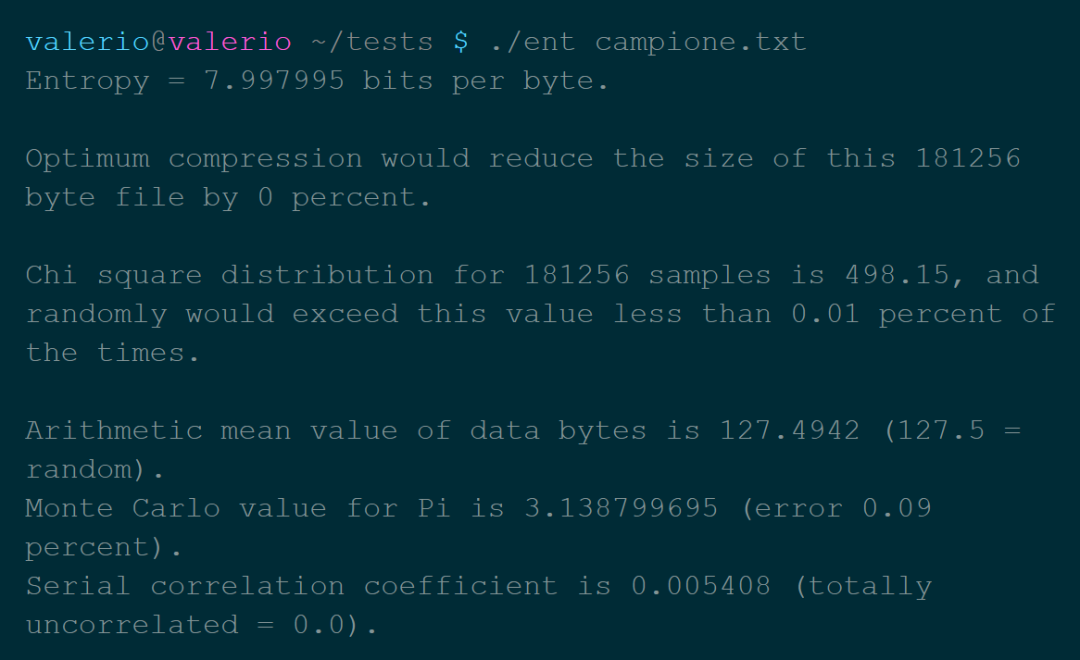
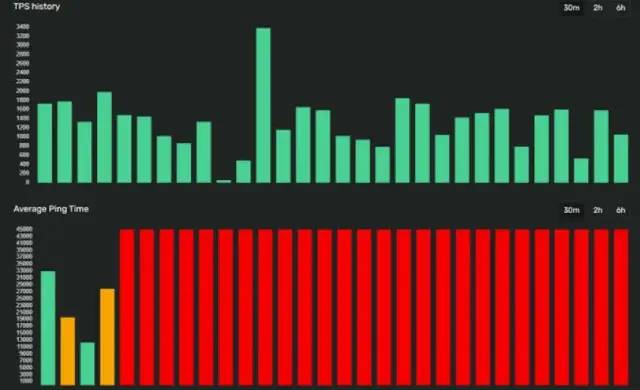
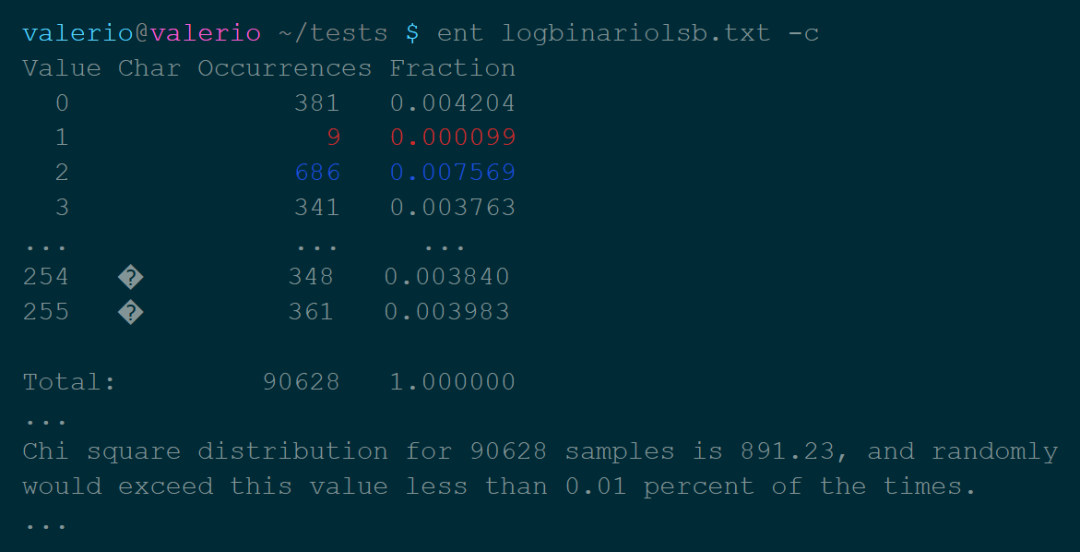
熵:熵是一部分信息中包含的“随机性”的数量。信息理论告诉我们,理论上可以通过压缩而不损失信息的最小尺寸,由熵值表示。 卡方分布:这个测试是用来了解我们的数值分布对理论分布的遵守程度。从ent手册来看,这个值应该尽可能地接近256,百分比值在10-90%之间。 算术平均值:比特的简单算术平均值。由于数值在0到255之间,所以它应该大约等于127。 用蒙特卡洛方法计算π的值:在这里更多的是一个漂亮的数据,而不是一个有用的方法。 自相关:表示系列值之间的依赖性,在最佳情况下必须等于零。
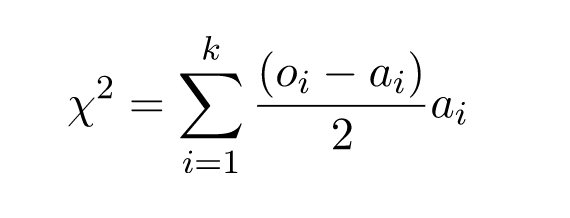
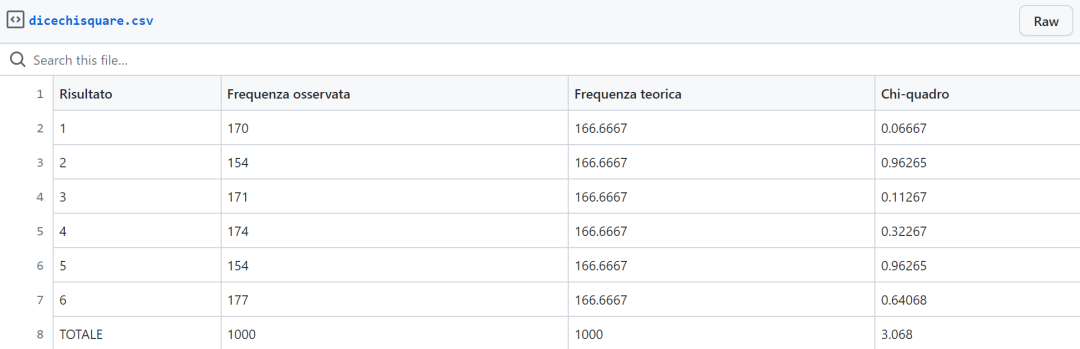
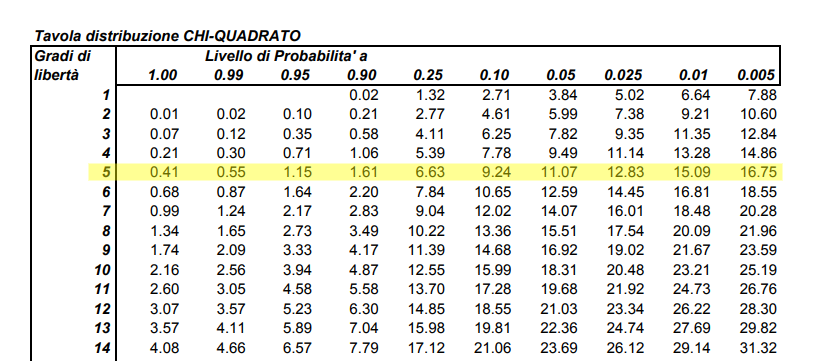
表中的行代表系统的自由度,在模具案例中,有5个自由度。列代表计算值大于表格中的值的概率水平。也有一些表格表示计算值小于的概率,这些表格被称为左尾表,上面显示的表格是右尾表。这是因为在一种情况下考虑的是图形的右边,而在另一种情况下考虑的是左边。案例中chi^2=3.068,这介于90%和25%的情况之间。这足以说明,从我们可以归类为随机的行为来看,没有过度的变化。
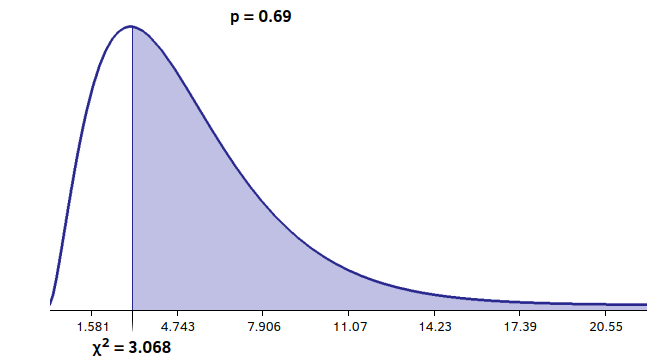
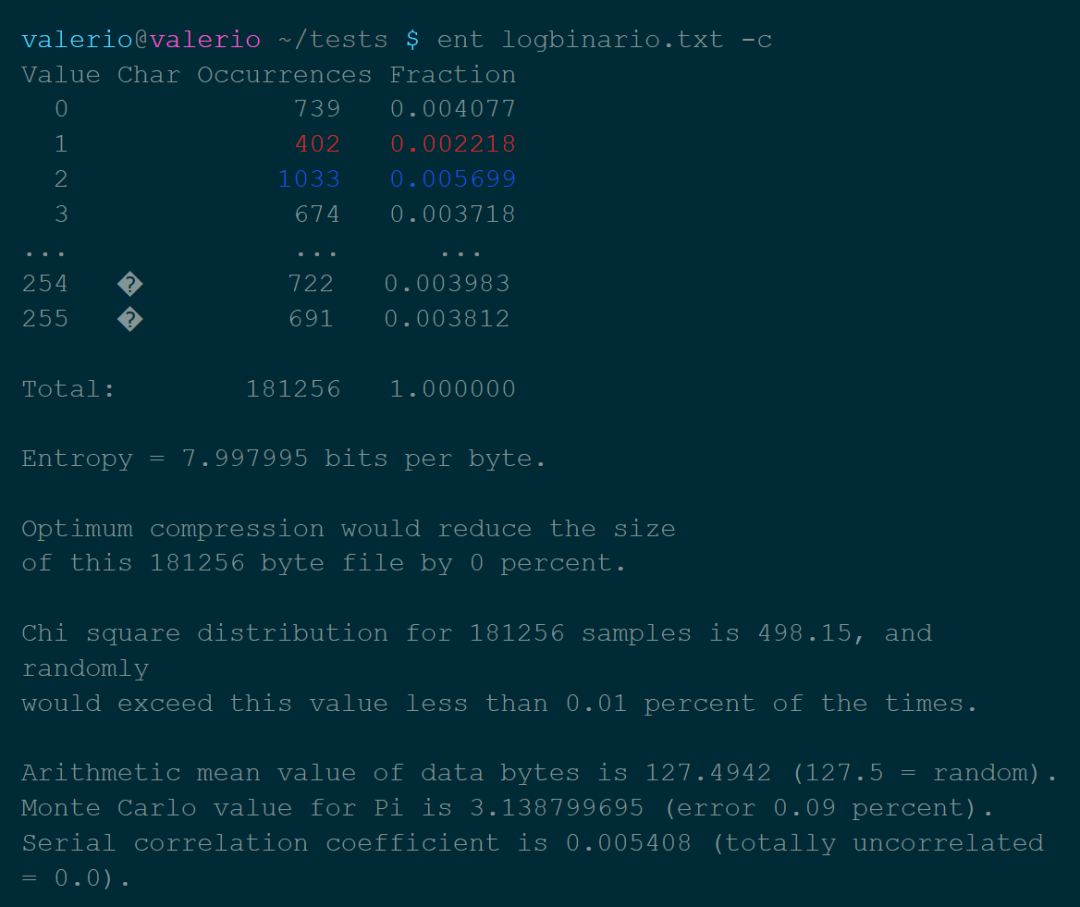
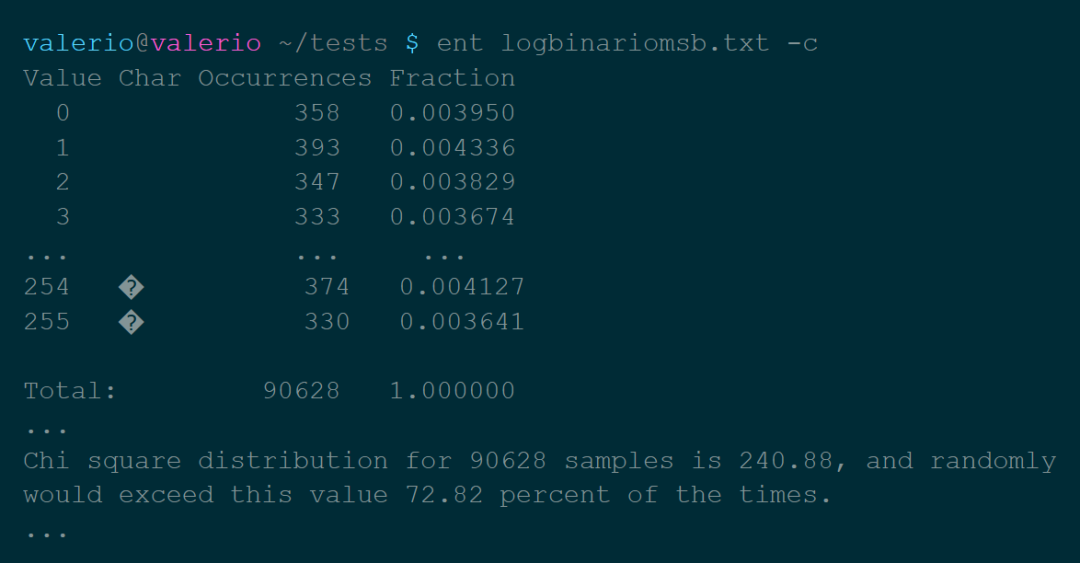


https://www.valerionappi.it/brng-en/
编辑:于腾凯
校对:林亦霖
评论
用 Linux 办公和开发到底靠谱吗?
昨天分享了“政府机构 5000 万台电脑将替换为国产 Linux”一文,有读者质疑Linux系统是否可以胜任办公需求。因此这里转载一篇不错的文章,介绍Linux下对于我们程序员来说,日常工作需求是否可以满足。 以下内容转载自...
公众号程序猿DD
0
互联网软件技术培训,靠谱吗?
点击上方蓝色字体,关注我们之前一直有很多朋友问我,技术人要怎样制定学习规划?要不要报个培训班来深造?......关于如何制定学习规划这件事情,太宽泛,也因人而异,暂时没想到该怎样合适表述自己的看法,至于互联...
美男子玩编程
0
人工智能外呼机器人靠谱吗?
智能外呼机器人是一种模拟人工语音实现电话服务的产品,随着科技与技术的不断发展,人工智能外呼机器人的功能已经逐步完善,人工智能也在不断为人们创造新的商业价值,未来肯定会有更多的实用型机器人服务于人类。
容联七陌AICall智能语音机器人基于深度学习的算法应用(ASR、TTS、NLP),可以精准识别用户意图,实现自动应答、自助办理等业务场景,支持打断、多轮会话,毫秒级响应极速反馈,实现机器人与客户的无障碍交流,高拟人度自然音色,无限趋近真人流畅的聊天体验,提高企业运营效率、降低人工成本。
感兴趣的朋友可以到我们的官网免费注册试用下~
AICall | 容联七陌
容联七陌
0
AI智能外呼机器人靠谱吗?
必须机器人好用啊。
机器人一天打1000电话,两个真人一天不一定能打1000。
机器人周末不休,真人不能不休。
机器人不会请假,真人说不定还要请假。
机器人不用入保险,真人销售还得给他入保险。
机器人工资低,真人一个月保底就要3k+的薪资。
您要说,机器人打电话效果不如真人?
那您就错了,声音跟真人是一样的。
您要说,逻辑上蹩脚?
如果我们不给它施加太多的逻辑期望,我们就让它干最简单的活儿!
就简单问一句:您好,我们是****的,请问您需要吗?
就是别对方一句,需要、不需要。
这活儿,它能干吧?
您现在让真人打电销,一百个电话里,90个不需要,那效果跟机器人一样的呀。您要说,真人能挽回大多数不感兴趣的人群,
讯飞企服fusion
0