 极市平台
极市平台





极市导读
本文作者通过训练另一个深度神经网络解释器来生产显著图,以预测预先训练好的黑盒分类器的属性,只显示图像中与分类器相关的部分,并过滤掉其它无关的部分。论文中定性和定量的实验结果表明,与其他方法生成的显著图相比,论文中提出的方法生成了更清晰和更精确的显著图边界。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
引言
该论文是关于显著图分割和定位的论文。目前深度神经网络可解释性的一个直观的方法就是深度模型输出各个预测类别的显著图。大多数现有的方法要么使用激活和梯度,要么通过反复干扰输入来找到这种属性。
在该论文中,作者通过训练另一个深度神经网络解释器来生产显著图,以预测预先训练好的黑盒分类器的属性,只显示图像中与分类器相关的部分,并过滤掉其它无关的部分。论文中定性和定量的实验结果表明,与其他方法生成的显著图相比,论文中提出的方法生成了更清晰和更精确的显著图边界。

论文链接:https://arxiv.org/abs/2205.11266v1
代码链接:https://github.com/stevenstalder/NN-Explainer
方法概述
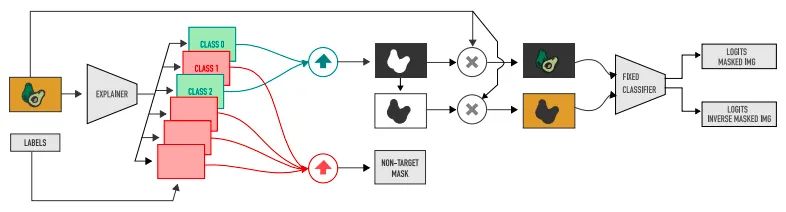
下图为论文作者提出的解释器方法框架,首先需要获得给定预训练分类器可解释性信息,并用该信息去推断语义对象类所依赖的图像区域。需要注意的一点是,论文中模型的训练不需要任何像素级的注释,它依赖于的训练数据集(包括标签)和模型。
将一批图像输入到解释器中并输出一组具有相同分辨率的图像,其中包含类的分割图像。的值通过激活函数函数在的范围内有界,其中表示预测的像素值。中的值或分别导致相应像素值的完全保留或删除,但需要注意的是其总和不必等于。
作者通过为每个像素位置取像素方向的最大值,将每个集合合并到单个中。目标图像用于定位与给定训练图像中包含的任何标签对应的区域,而无目标图像收集假阳性激活,用于确保一旦删除了图像中的目标对象后,则不会再处理相关任务。
训练损失函数
作者将损失函数表示为以下四项的组合,具体形式如下所示
其中表示的是图像上的二进制交叉熵损失函数,是用补码图像上的熵项,是一个正则化项,用于说明真阳性和假阳性的区域,是一个有利于平滑的正则化项。,和是损失函数的平衡系数。
分类损失函数:
模型应该能够仅使用图像的相关部分做出正确的决策,而忽略所有其它部分。在此假设下,作者将分类损失定义为二元交叉熵项的和,图像中的每一类对应一个交叉熵项。作者将解释器表示为和模型。作者定义为模型应用于图像的概率向量,其中由解释器生成的。
对于在训练数据集中所有类和目标类集合,具体公式如下所示
其中表示表示艾佛森括号,如果方括号内的条件满足时则为,不满足则为。这允许在训练图像中存在多个类别时训练,如在多标签分类问题中,其中多个可以同时处于激活状态,并且一些像素不属于任何(与使用交叉熵相反)。因此,该模型可以自由地学习不同类之间的依赖关系和共现性。损失函数促使解释器去学习近似,即,图像在经过(预)训练的解释器中尽可能正确地分类。
负熵损失函数:
这部分损失促使解释器提供补充不包含任何辨别性视觉线索的,即解释器可以使用部分图像来推断正确类别。换句话说,分类器分数应该提供尽可能一致的类概率,其中具体负熵损失函数表示为
其目标是为了图像背景熵尽可能高。
区域损失函数:
当只有这两项和损失函数时,解释器没有动机去生成一个隐藏图像区域的目标。很明显,到处都是的目标的使这些项最小化。为了确保隐藏背景,作者在损失中添加了两个项,对应于两个关键要求:应尽可能小,但如果目标有利于更大的区域,则最小和最大百分比之间的整个区域不应进一步受到惩罚。区域上的正则化简单地表示为值的平均值,计算为
其中是像素数。作者希望这个区域很小,但不是零。无目标的也需要相同的条件。给定一类语义的,作者将其拉平为一维向量,并对其值按照降序进行排列。令表示为向量化操作,表示为对向量化后进行排序。作者定义两个向量和,进而则有
为了约束类分割覆盖的最小和最大区域,计算区域边界度量由下式给出:
其中,第一项仅在最大值小于时惩罚,而第二项惩罚大于的最小值。作者的目标是让至少覆盖某个区域,而不受其最大尺寸的影响。最终区域正则化为:
其中,是根据给定训练标签在给定输入图像中存在的类的子集。
平滑度损失函数:
该损失函数是能够生成平滑且无伪影的图像;为此,作者使用的损失函数
其中一个二维矩阵,损失的平滑项与目标的和无目标的有关,如下所示:
这个平滑损失项鼓励图像属性在视觉上显得连贯一致。
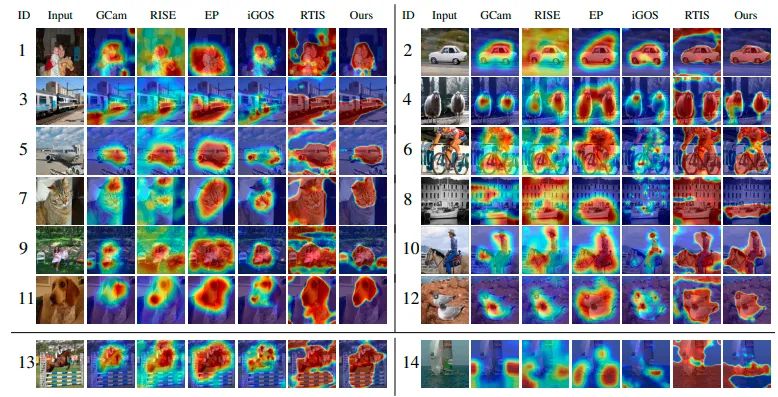
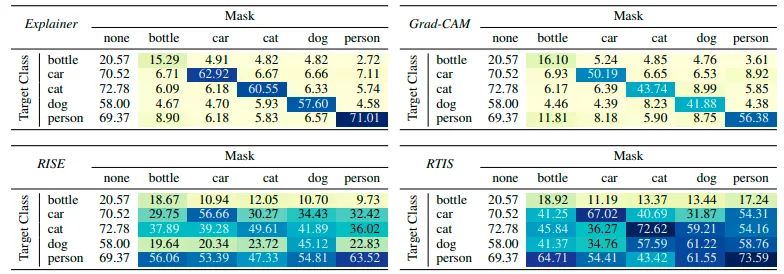
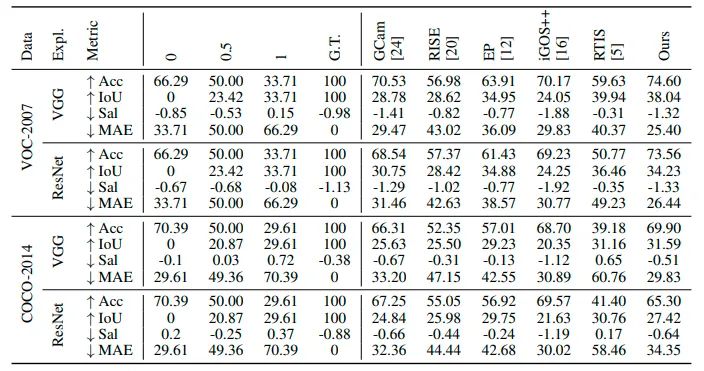
实验结果
公众号后台回复“项目实践”获取50+CV项目实践机会~

“
点击阅读原文进入CV社区
收获更多技术干货

