 机器学习初学者
机器学习初学者




导读
本文提出了一种十分新颖的观点,即:输出知识蒸馏的潜力其实还没有得到完全开发。作者在本文中揭示出传统知识蒸馏方法会自然地抑制 NCKD 的作用,因此限制了知识蒸馏的潜力和灵活性。本文进一步将 TCKD 和 NCKD 进行解耦,通过独立的超参数控制二者的作用,得到的 DKD 蒸馏方法在一系列视觉任务上得到的明显的性能提升。
目录
1 解耦知识蒸馏 (CVPR 2022)
(来自旷视科技,早稻田大学,清华大学)
1 DKD 原理分析
1.1 DKD 设计动机
1.2 重新思考知识蒸馏
1.3 两部分的不同作用
1.4 解耦知识蒸馏
1.5 实验结果
论文名称:Decoupled Knowledge Distillation
论文地址:
https://arxiv.org/pdf/2203.08679.pdf
1 DKD 原理分析
1.1 DKD 设计动机
现代知识蒸馏方法大多数注重深层的中间特征层面的知识蒸馏 (feature distillation),而对于相对而言比较原始的输出层面的知识蒸馏 (logit distillation) 的研究,因为性能不如前者而相对被忽略。本文提出了一种十分新颖的观点,即:输出知识蒸馏的潜力其实还没有得到完全开发。在本文中作者把 logit distillation 的输出分为两个部分,即:目标类别知识蒸馏 (target class knowledge distillation, TCKD) 和非目标类别知识蒸馏 (non-target class knowledge distillation, NCKD)。顾名思义,这两个名词的含义分别是指:对于模型输出中目标类别的值和非目标类别的值分别进行蒸馏。作者在这篇文章中指出:TCKD 传授给 "学生" 模型的知识是当前训练样本的难度,而 NCKD 才是知识蒸馏 work 的最主要原因。但是文章同样指出:常规的 KD 方法会 "抑制" NCKD 的作用,并且限制这两个部分的灵活度。因此本文提出将这两个部分进行解耦,分别完成对应的知识蒸馏操作。
1.2 重新思考知识蒸馏
本部分将对知识蒸馏的表达式进行重新推导。对于任意的训练样本,假设其类别属于第 类,则其分类结果可以被写成: 。其中, 为样本的类别数, 为其属于第 个类别的概率,通过 softmax 函数最终得到:
其中, 代表第 个类别的 output logits。
作者接下来定义属于目标类别的可能性参数 ,其中:
同时,定义 为非目标类别的概率,就是在计算概率值时分母不包含第 个类别:
定义 和 分别为学生和教师模型,知识蒸馏使用 KL-Divergence 作为目标函数:
根据上式1和上式3,有 ,所以上式4可以被重写成:
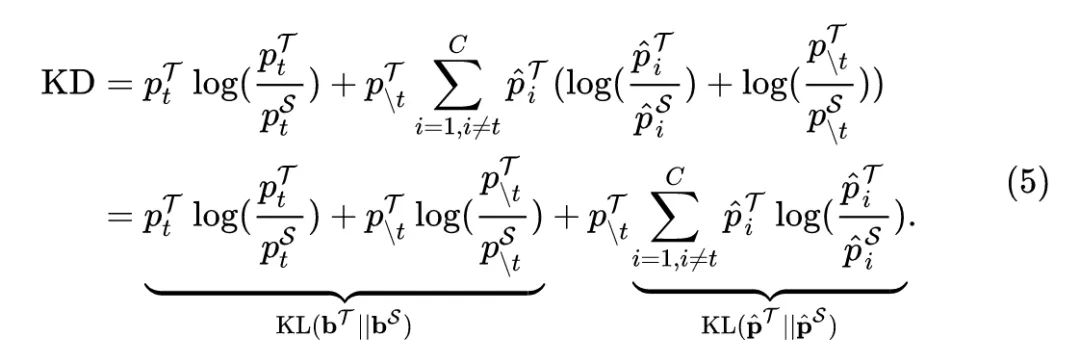
根据上式5可以看到,知识蒸馏损失函数可以视为是两部分 KL 散度之和:第1项是教师和学生模型关于目标类别二值概率的 KL 散度,称为目标类别知识蒸馏 (TCKD)。第2项是教师和学生模型关于非目标类别的 KL 散度,称为非目标类别知识蒸馏 (NCKD)。上式5可以被重写成:
1.3 两部分的不同作用
如下图1所示是几种不同的模型 (ResNet8×4,ShuffleNet-V1等) 使用不同的损失函数得到的精度。直观上,TCKD 注重获得与目标类别相关的知识,因为相应的损失函数只考虑二元概率。相反,NCKD 注重获得非目标类别相关的知识。
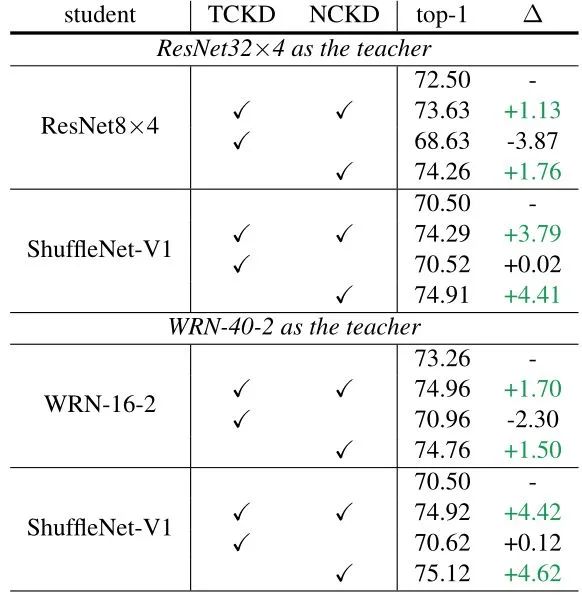
注意到仅仅使用 TCKD 对模型性能的提升没有帮助,甚至带来性能的下降。NCKD 的蒸馏性能与经典 KD 相当,甚至更好 (例如,在 ResNet8×4 上为1.76%对1.13%)。针对这一实验现象,作者给出了以下分析:
TCKD 传递关于训练样本 "难度" 的知识:
根据上式5的第1项,TCKD 通过二元知识蒸馏任务传递了一些 "dark knowledge",传递的知识是一个样本的目标类别的概率值的大小。比如,一个 的样本比另外一个 的样本更加 "容易"。当这个样本的目标类别的概率值更小时,TCKD 会更加有效。因为 CIFAR-100 训练集很容易拟合。因此,教师模型提供的 知识是没有信息量的。在这一部分,作者从三个角度进行了实验来验证:训练数据越困难,TCKD 提供的帮助越大。
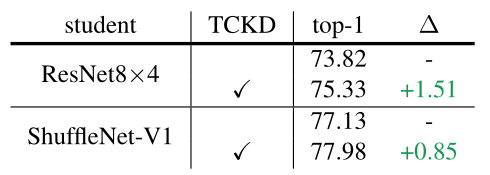
第一个角度是使用更强的数据增强手段。通过下图2的实验结果可以验证。
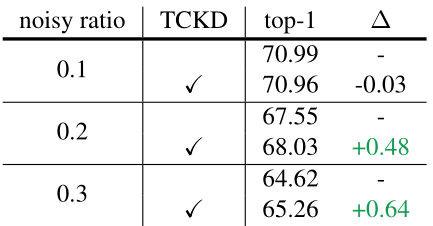
第二个角度是使用噪声标签。通过下图3的实验结果可以验证。
第二个角度是使用更有挑战性的数据集。通过下图4的实验结果可以验证。
作者通过实验各种策略来增加训练数据的难度,从而证明了 TCKD 在训练任务相对更困难时,使得蒸馏策略带来的帮助更大。
NCKD 是知识蒸馏起作用的最主要原因,但是它会被极大程度地抑制:
通过图1结果作者注意到,当仅应用 NCKD 时,实验的性能与经典 KD 相当甚至更好。这表明非目标类之间的知识至关重要,是 KD 方法 work 的主要原因。但是根据上式7可以发现,NCKD 这一项会乘以一项 ,这使得 NCKD 会被极大程度地抑制,从而无法充分发挥 KD 方法的性能。
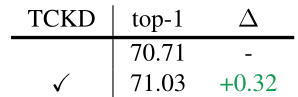
针对这一观点作者做了个对比实验:根据 的大小将训练样本分为两个子集,分别使用 NCKD 蒸馏在每个子集上进行训练,实验效果如下图所示。可以发现, 普遍较大 (0-50%) 时,NCKD 带来的性能增益就越多,证明 原本 NCKD 被抑制的程度越高。
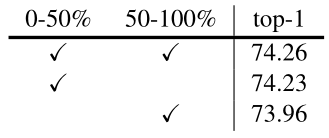
1.4 解耦知识蒸馏
到目前为止,作者已经将经典的 KD 损失转化为两个独立部分的加权和,并进一步验证了 TCKD 的有效性,揭示了 NCKD 部分在正常使用 KD Loss 时会受到抑制。因此作者提出将这两个部分进行解耦,具体方法如下图6所示,伪代码如下图7所示。
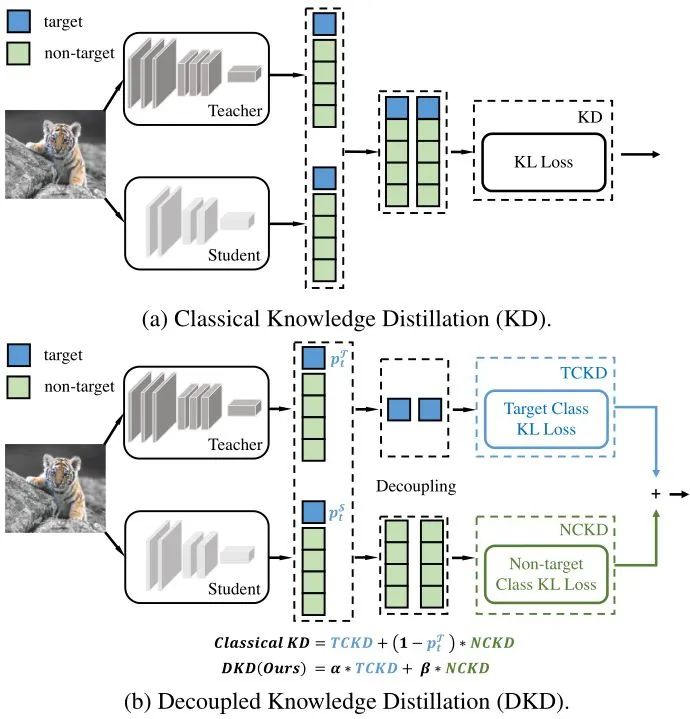
DKD 方法将 TCKD 和 NCKD 部分分开,分别乘以两个超参数 和 ,损失函数为:
通过调节超参数 和 ,可以减少 NCKD 被抑制的程度,从而更好地发掘 KD 的潜力。
DKD 方法伪代码为:

1.5 实验结果
作者在 CIFAR100 分类任务,ImageNet 分类任务,MS-COCO 目标检测任务上分别进行了实验。
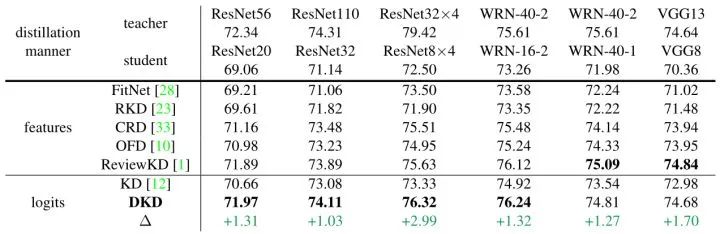
CIFAR100 的实验结果如下图8所示。对于所有的教师-学生模型对,DKD 方法都获得了性能的提升。此外,DKD实现了与基于特征的蒸馏方法相当甚至更好的性能,显著改善了蒸馏性能和训练效率之间的平衡。
ImageNet 的实验结果如下图9和图10所示。DKD 方法获得了显著的性能提升,并且超过了一些基于特征蒸馏的方法。


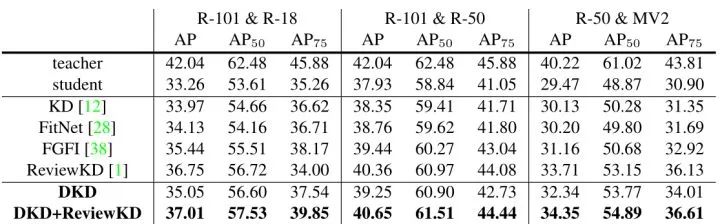
MS-COCO 目标检测任务的实验结果如下图11所示。目标检测任务的性能很大程度上取决于网络提取得到的深层特征的质量。检测模型特征模拟至关重要,因为逻辑输出不能为检测模型提供知识。如下图11所示,单独应用DKD 很难实现出色的性能,但有望超过经典的 KD。因此,作者引入基于特征的蒸馏方法 ReviewKD 以获得满意的结果。可以看出,即使 ReviewKD 的蒸馏性能相对较高,DKD 也可以进一步提高AP指标。总之,通过将 DKD 与基于特征的提取方法结合在目标检测任务,可以获得更加出色的结果。
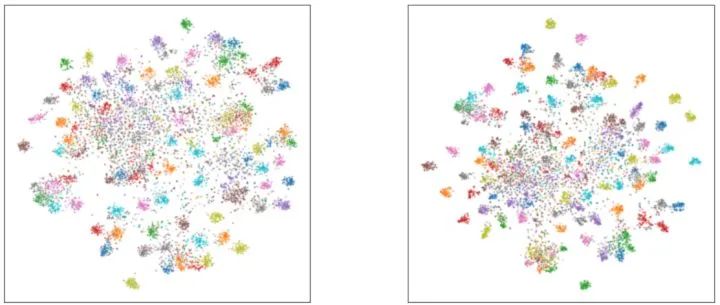
特征可视化
以 ResNet32x4 作为教师模型,ResNet8x4 作为学生模型,在 CIFAR100 数据集上的特征可视化结果如下图12所示。t-SNE 结果显示 DKD 的特征表示比 KD 更易区分,证明 DKD 有利于深层特征的可辨性。
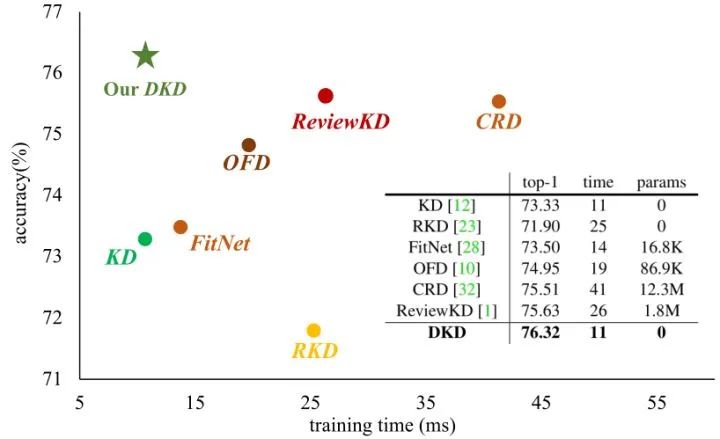
训练效率比较
如下图13所示为最先进的蒸馏方法的训练成本,证明了 DKD 的高训练效率。DKD 实现了模型性能和训练成本 (例如,训练时间和额外参数) 之间的最佳平衡。由于 DKD 是从经典的 KD 方法重新构造的,它只需要与 KD 几乎相同的计算复杂度,当然没有额外的参数。然而,基于特征的提取方法需要额外的提取中间层特征的训练时间,以及 GPU 的存储成本。
总结
本文提出了一种十分新颖的观点,即:输出知识蒸馏的潜力其实还没有得到完全开发。在本文中作者把 logit distillation 的输出分为两个部分,即:目标类别知识蒸馏 (target class knowledge distillation, TCKD) 和非目标类别知识蒸馏 (non-target class knowledge distillation, NCKD)。顾名思义,这两个名词的含义分别是指:对于模型输出中目标类别的值和非目标类别的值分别进行蒸馏。作者在本文中揭示出传统知识蒸馏方法会自然地抑制 NCKD 的作用,因此限制了知识蒸馏的潜力和灵活性。本文进一步将 TCKD 和 NCKD 进行解耦,通过独立的超参数控制二者的作用,得到的 DKD 蒸馏方法在一系列视觉任务上得到的明显的性能提升。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码



