
研究与解读丨残差网络解决了什么,为什么有效?
共 5134字,需浏览 11分钟
· 2022-06-25

本文授权转载自知乎,作者丨LinT
1
动机: 深度神经网络的“两朵乌云”
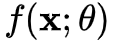 为例,定义一下神经网络。一个前馈神经网络,由若干层神经元组成,为了方便讨论,我们以非线性单元(若干层神经元组成的函数单元)为单位讨论神经网络,即神经网络由
为例,定义一下神经网络。一个前馈神经网络,由若干层神经元组成,为了方便讨论,我们以非线性单元(若干层神经元组成的函数单元)为单位讨论神经网络,即神经网络由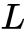 个非线性单元堆叠而成(后面将每个单元称为一层),令
个非线性单元堆叠而成(后面将每个单元称为一层),令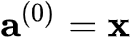 ,则神经网络第
,则神经网络第 层(
层(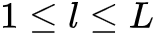 )的净输入
)的净输入 与输出
与输出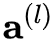 的计算由下式给出:
的计算由下式给出: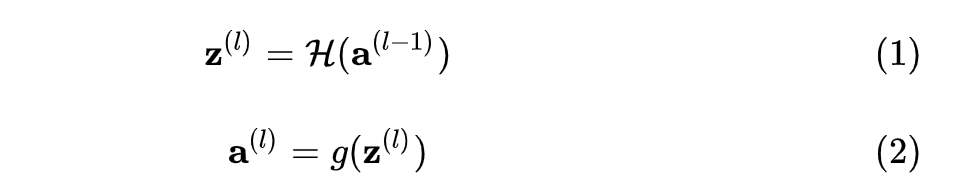
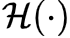 是该层的内部运算,依照网络类型有所不同;
是该层的内部运算,依照网络类型有所不同;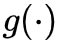 是第 层的输出激活函数。层的某参数更新需要计算损失
是第 层的输出激活函数。层的某参数更新需要计算损失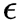 对其的梯度,该梯度依赖于该层的误差项
对其的梯度,该梯度依赖于该层的误差项  ,根据链式法则,
,根据链式法则,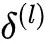 又依赖于后一层的误差项
又依赖于后一层的误差项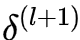 :
: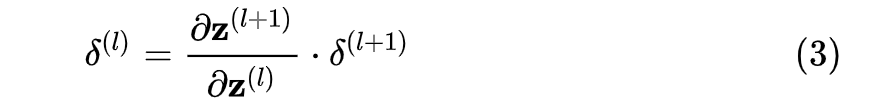
 ,则有
,则有
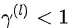 时,第 层的误差项较后一层减小,如果很多层的情况都是如此,就会导致反向传播中,梯度逐渐消失,底层的参数不能有效更新,这也就是梯度弥散(或梯度消失);当
时,第 层的误差项较后一层减小,如果很多层的情况都是如此,就会导致反向传播中,梯度逐渐消失,底层的参数不能有效更新,这也就是梯度弥散(或梯度消失);当 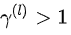 时,则会使得梯度以指数级速度增大,造成系统不稳定,也就是梯度爆炸问题。
时,则会使得梯度以指数级速度增大,造成系统不稳定,也就是梯度爆炸问题。 的大小,也很容易出现梯度弥散/爆炸。这是两朵乌云中的第一朵。
的大小,也很容易出现梯度弥散/爆炸。这是两朵乌云中的第一朵。
 层的网络
层的网络 是当前最优的网络,那么可以构造一个更深的网络,其最后几层仅是该网络 第层输出的恒等映射(Identity Mapping),就可以取得与一致的结果;也许还不是所谓“最佳层数”,那么更深的网络就可以取得更好的结果。总而言之,与浅层网络相比,更深的网络的表现不应该更差。因此,一个合理的猜测就是,对神经网络来说,恒等映射并不容易拟合。
是当前最优的网络,那么可以构造一个更深的网络,其最后几层仅是该网络 第层输出的恒等映射(Identity Mapping),就可以取得与一致的结果;也许还不是所谓“最佳层数”,那么更深的网络就可以取得更好的结果。总而言之,与浅层网络相比,更深的网络的表现不应该更差。因此,一个合理的猜测就是,对神经网络来说,恒等映射并不容易拟合。2
残差网络的形式化定义与实现
既然神经网络不容易拟合一个恒等映射,那么一种思路就是构造天然的恒等映射。假设神经网络非线性单元的输入和输出维度一致,可以将神经网络单元内要拟合的函数  拆分成两个部分,即:
拆分成两个部分,即:
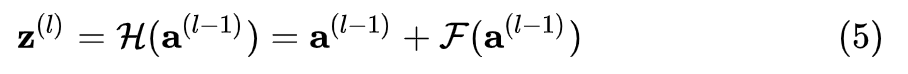
其中  是残差函数。在网络高层,学习一个恒等映射
是残差函数。在网络高层,学习一个恒等映射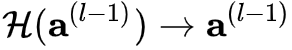
即等价于令残差部分趋近于0,即 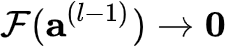 。
。
残差单元可以以跳层连接的形式实现,即将单元的输入直接与单元输出加在一起,然后再激活。因此残差网络可以轻松地用主流的自动微分深度学习框架实现,直接使用BP算法更新参数[1]。
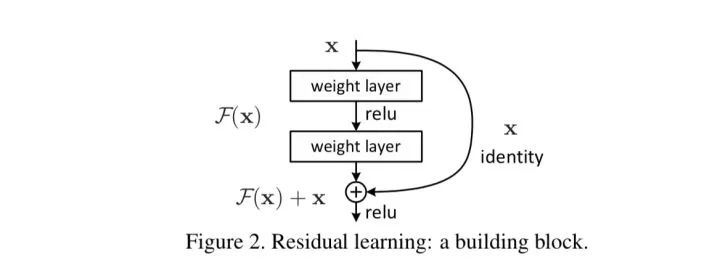
3
残差网络解决了什么,为什么有效?
残差网络在图像领域已然成为了一种主流模型,虽然这种网络范式的提出是为了解决网络退化问题,但是关于其作用的机制,还是多有争议。目前存在几种可能的解释,下面分别列举2016年的两篇文献和2018年的一篇文献中的内容。
3.1 从前后向信息传播的角度来看
何恺明等人从前后向信息传播的角度给出了残差网路的一种解释[3]。考虑式(5) 这样的残差块组成的前馈神经网络,为了讨论简便,暂且假设残差块不使用任何激活函数,即

考虑考虑任意两个层数  ,递归地展开(5) (6),
,递归地展开(5) (6),
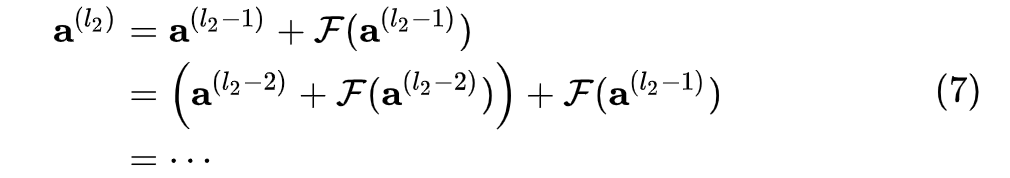
可以得到:
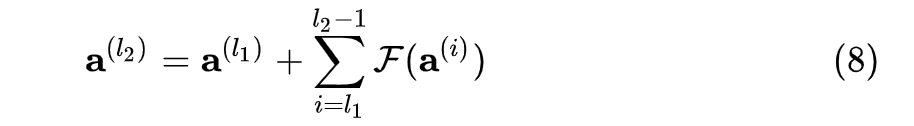
根据式  ,在前向传播时,输入信号可以从任意低层直接传播到高层。由于包含了一个天然的恒等映射,一定程度上可以解决网络退化问题。这样,最终的损失
,在前向传播时,输入信号可以从任意低层直接传播到高层。由于包含了一个天然的恒等映射,一定程度上可以解决网络退化问题。这样,最终的损失  对某低层输出的梯度可以展开为:
对某低层输出的梯度可以展开为:
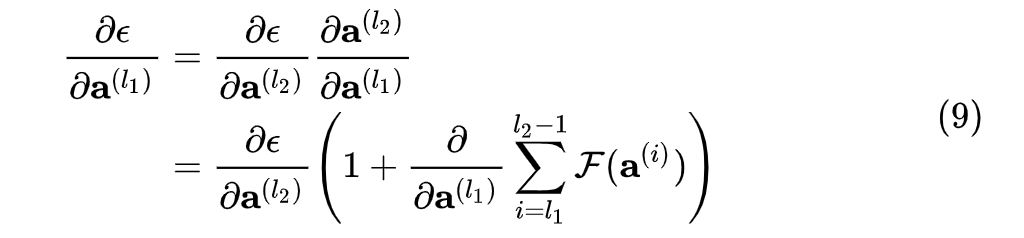
或展开写为
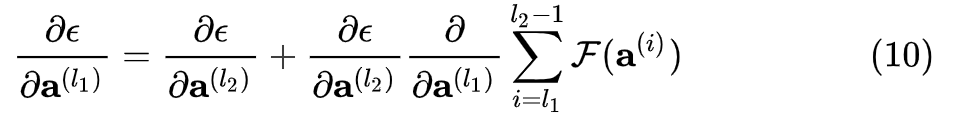
根据根据式  ,损失对某低层输出的梯度,被分解为了两项,前一项
,损失对某低层输出的梯度,被分解为了两项,前一项 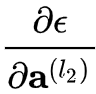 表明,反向传播时,错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度弥散问题(即便中间层矩阵权重很小,梯度也基本不会消失)。
表明,反向传播时,错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度弥散问题(即便中间层矩阵权重很小,梯度也基本不会消失)。
综上,可以认为残差连接使得信息前后向传播更加顺畅。
* 加入了激活函数的情况的讨论(实验论证)请参见[3]。
3.2 集成学习的角度
Andreas Veit等人提出了一种不同的视角[2]。他们将残差网络展开,以一个三层的ResNet为例,将得到下面的树形结构:
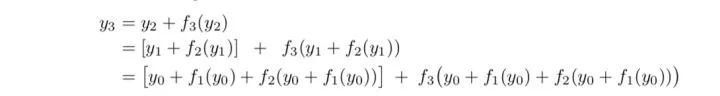
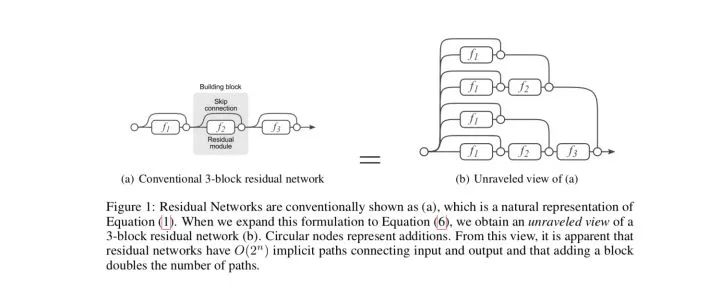
在标准前馈神经网络中,随着深度增加,梯度逐渐呈现为白噪声(white noise)。
 )发现,在浅层神经网络中,梯度呈现为棕色噪声(brown noise),深层神经网络的梯度呈现为白噪声。在标准前馈神经网络中,随着深度增加,神经元梯度的相关性(corelation)按指数级减少 (
)发现,在浅层神经网络中,梯度呈现为棕色噪声(brown noise),深层神经网络的梯度呈现为白噪声。在标准前馈神经网络中,随着深度增加,神经元梯度的相关性(corelation)按指数级减少 (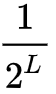 );同时,梯度的空间结构也随着深度增加被逐渐消除。这也就是梯度破碎现象。
);同时,梯度的空间结构也随着深度增加被逐渐消除。这也就是梯度破碎现象。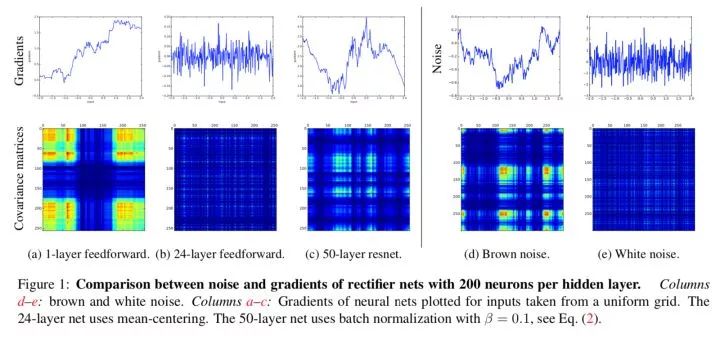
 ),深度残差网络中,神经元梯度介于棕色噪声与白噪声之间(参见上图中的c,d,e);残差连接可以极大地保留梯度的空间结构。残差结构缓解了梯度破碎问题。
),深度残差网络中,神经元梯度介于棕色噪声与白噪声之间(参见上图中的c,d,e);残差连接可以极大地保留梯度的空间结构。残差结构缓解了梯度破碎问题。4
自然语言处理中的残差结构
与图像领域不同的是,自然语言处理中的网络往往“宽而浅”,在这些网络中残差结构很难有用武之地。但是在谷歌提出了基于自注意力的Transformer架构[5],特别是BERT[6]出现以后,自然语言处理也拥有了“窄而深”的网络结构,因此当然也可以充分利用残差连接,来达到优化网络的目的。事实上,Transformer本身就包含了残差连接,其中编码器和解码器中的每一个子模块都包含了残差连接,并使用了Layer Normalization。
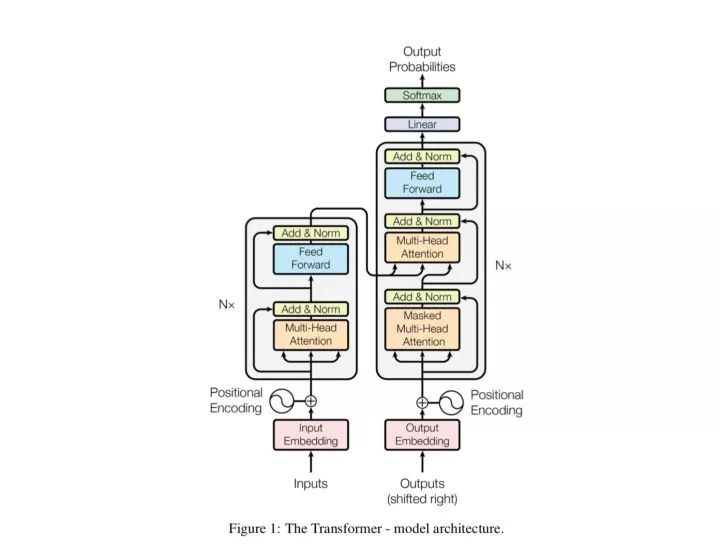
5
总结与扩展
残差网络真可谓是深度学习的一把利器,它的出现使得更深的网络训练成为可能。类似残差网络的结构还有Highway Network[7],与残差网络的差别在于加入了门控机制(注意它和ResNet是同时期的工作),文献[4]中也对Highway Network进行了讨论,值得一读;现在广泛使用的门控RNN,我认为与Highway Network有异曲同工之妙,可以认为是在时间维上引入了门控的残差连接;在残差网络中使用的跳层连接,在自然语言处理中也有相当多的应用,比如Bengio的神经语言模型[8]、文本匹配模型ESIM[9]等,区别在于这些工作中跳层连接仅仅将不同层次的特征拼接在一起(而不是相加),达到增加特征多样性、加快训练的目的。
P.S. 原本希望在这篇文章里面展开讲讲更多的细节,但是个人水平有限,加上知乎的文章篇幅限制,只能大概展开到这种程度。本文是笔者根据论文梳理的自己的理解,如果有谬误请指出。
参考资料:
9. Enhanced LSTM for Natural Language Inference
END
2019-07-18

2019-07-06

2018-07-04

2020-08-09
