Python副业500元,爬取美团外卖
共 15333字,需浏览 31分钟
· 2022-06-25
500元爬取美团外卖
标题党了一下,实际上并没有完整爬取,只是实现了部分爬取。具体情况是蚂蚁老师的学习群中发了一个500元的爬取美团店铺信息的爬虫单子,先是被人接单了,但没过多久,因为难度太大,而退单了。有难度的事情,咱们头铁,试试看能不能搞得定。
任务要求与难度评估
任务要求:
目标网站是美团外卖的H5页面https://h5.waimai.meituan.com 具体任务是爬取目标店铺的菜品、价格、图片等 目标店铺可以自定义
难度评估:
先尝试找了一下目标数据,发现数据还是相对容易查到并解析的,整个任务难点不在数据,而在于以下3处:
登录需要手机号、短信验证码,且有请求发送短信,需要通过滑动条验证码的验证; 登录后需要设置所在地,因为,所在地是影响搜索结果的,而如何设置所在地,有相当复杂的逻辑(并没有深入研究); 使用关键词搜索目标店铺、进入目标店铺、请求获取数据,等等有非常复杂的逻辑、参数极多,解析有大量的工作量。
方案确定
综合上述难点,坦率而言,500元的标价是不匹配的,且时效要求只有1天,几乎是不可能的任务(大神除外)。于是先找甲方沟通了一下,发现甲方的实际需求极为简单,时效紧是因为短时间内有5家店铺信息需要获取上线。
而后续即使有新增目标,也是少量的,陆陆续续产生的需求。其实只需要解决获取数据,下载图片(每个店铺可能对应100多个菜品,此处是繁琐的工作量),且不出错即可。
对于甲方来说,其需求量少,不可能投入大量的资源解决这么一个小问题,对于接单人来说,又不可能为了这么一点收获,投入大量精力,二者存在偏差。那么如何使二者达成一致呢?
于是,我提出了半自动爬虫的方案解决问题,也征得了甲方的同意。何谓半自动爬虫呢?即在需求的店铺数量有限的前提下,在部分获取数据环节上通过人工操作的方式解决,回避前面的3个难点;而爬虫专注于解决数据解析,以及下载图片的繁琐步骤。
达成一致后,那么就开始代码吧~~~
页面分析
登录、设置地址、查找目标店铺
这些步骤都人工操作了,就不需要分析页面了。唯一碰到的问题是,使用PC浏览器登录时,发送验证码的滚动条验证步骤无法通过,需要使用手机浏览器成功发送验证码后,将验证码填入PC端登录。
巨坑注意:虽然PC端无法通过滚动条验证步骤,但是该动作还是要做的,否则即使填入了手机获取到的验证码,是无法提交登录的。(与甲方共同测试时,在这个环节卡了好久)
目标店铺数据分析
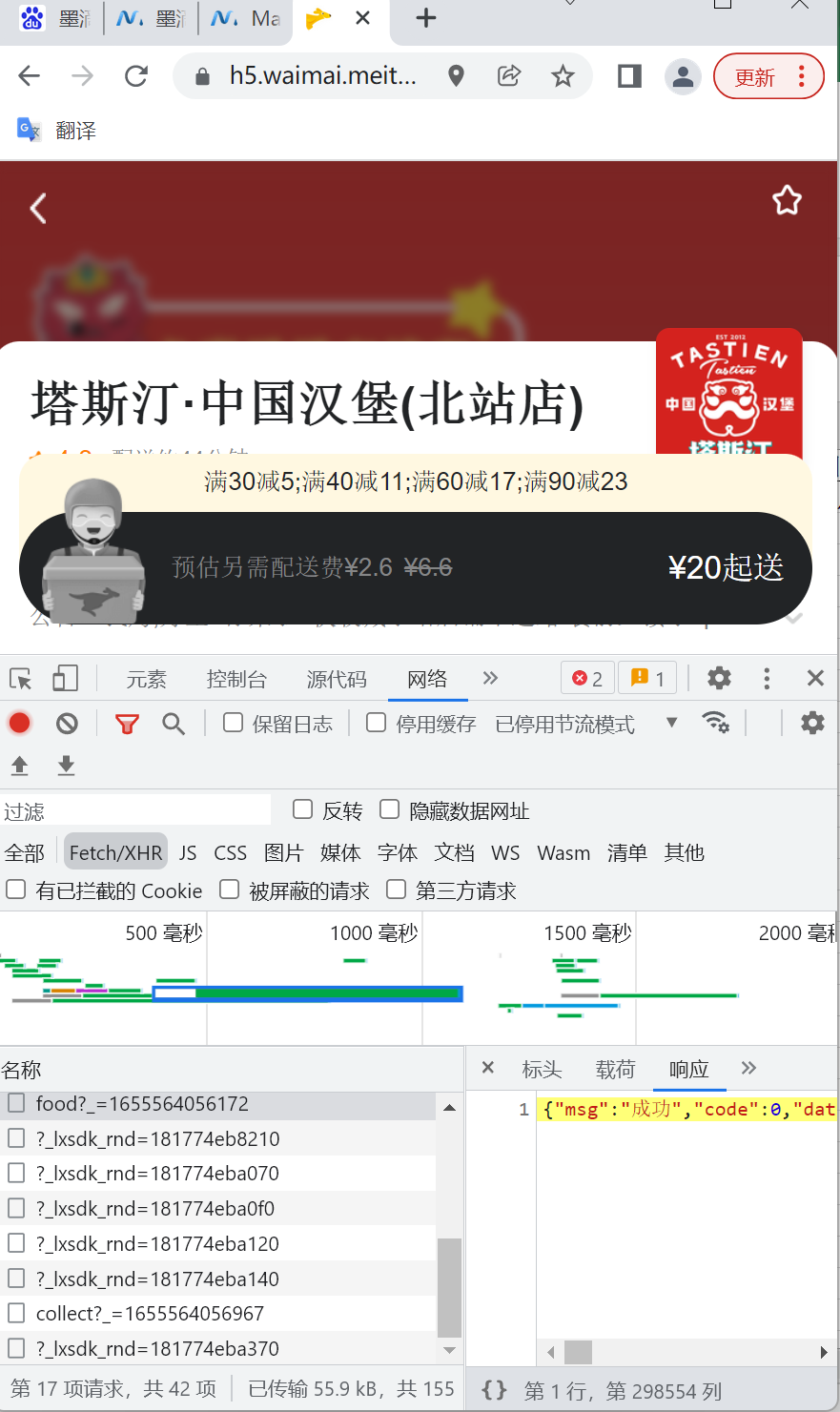
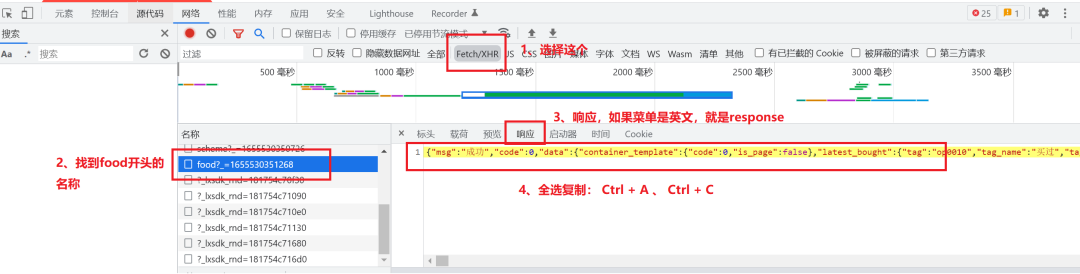
该步骤不难,F12打开chrome的开发者模式,进入店铺后,使用关键词搜索一下,就能发现,所有的菜品,都在一个food的response中
图片目标分析
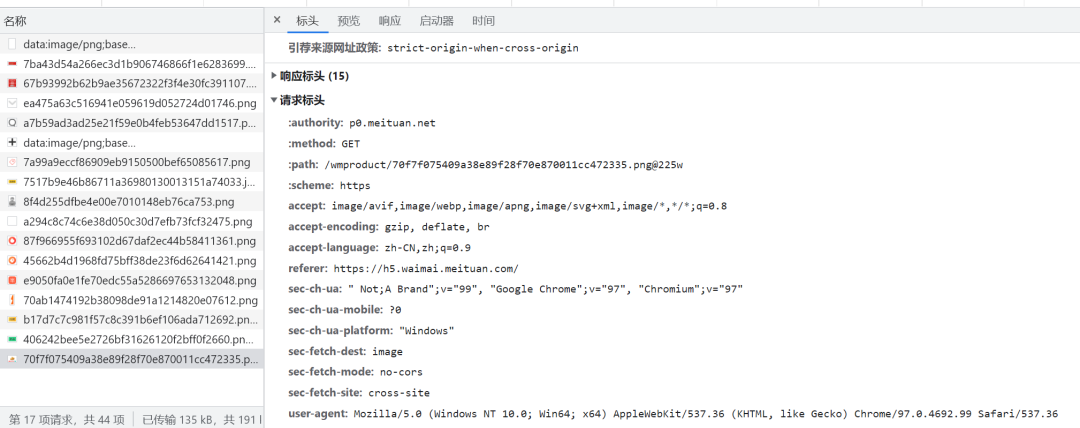
图片的请求则相当简单,只需要设置请求头,再使用GET请求图片网址即可,而图片网址在目标店铺的数据中,每个菜品都有对应的图片网址。
解决步骤与代码
将人工获取的店铺数据存入TXT文件,放在一个目录下,如下图:

有了数据之后,遍历、读取、加工数据、下载图片就都是基础的json、pandas与requests的操作了,具体详见代码注释吧。
# -*- coding: utf-8 -*-
# @author: Lin Wei
# @contact: 580813@qq.com
# @time: 2022/6/18 9:24
"""
本程序用于分析爬取美团外卖的店铺商品信息及图片
1、本程序不考虑登录美团、定位、查找店铺等操作,直接使用人工查找获得的信息进行解析,获取店铺信息
2、根据店铺信息中的图片地址,下载对应图片
"""
import time
import requests
import pandas as pd
import json
import pathlib as pl
from random import randint
class SpiderObj:
"""
爬虫对象
"""
def __init__(self):
"""
初始化对象
"""
self.file_path = pl.Path(input('请已保存的店铺数据文件路径:\n'))
def create_dir(self, shop_name: str) -> tuple:
"""
检查并创建文件夹
:param shop_name: 店铺名
:return:
"""
shop_dir = self.file_path / shop_name
pic_dir = shop_dir / '图片'
if not shop_dir.is_dir(): # 如果店铺文件夹不存在,则创建
shop_dir.mkdir()
if not pic_dir.is_dir(): # 如果图片文件夹不存在,则创建
pic_dir.mkdir()
return shop_dir, pic_dir
@classmethod
def get_origin_price(cls, ser: pd.Series) -> float:
"""
解析skus中的原价origin_price
:param ser: 数据行
:return:
"""
skus = ser['skus'][0]
origin_price = skus['origin_price']
return origin_price
@classmethod
def parse_data(cls, filename: pl.Path) -> tuple:
"""
解析获取到的美团店铺数据
:param filename: 存储数据的文件路径
:return:
"""
with open(filename, 'r', encoding='utf-8') as fin:
data = fin.read()
data = json.loads(data)
# 解析数据步骤
shop_name = data['data']['poi_info']['name']
data = data['data']['food_spu_tags']
df = pd.DataFrame()
for tag in data:
dfx = pd.DataFrame(tag['spus'])
dfx['分类'] = tag['name']
df = pd.concat([df, dfx])
df = df.loc[df['分类'].map(lambda x: x not in ['折扣', '热销', '推荐'])]
df['原价'] = df.apply(cls.get_origin_price, axis=1)
df.reset_index(inplace=True, drop=True)
return shop_name, df
@classmethod
def download_picture(cls, url: str, filename: pl.Path):
"""
下载图片的方法
:param url: 图片的地址
:param filename: 输出图片的路径(含文件名)
:return:
"""
# 初始化请求头
headers = {
"accept": "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"referer": "https://h5.waimai.meituan.com/",
"sec-ch-ua": "\" Not;A Brand\";v=\"99\", \"Google Chrome\";v=\"97\", \"Chromium\";v=\"97\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "image",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "cross-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
# 下载文件
file = requests.get(url, headers, stream=True)
with open(filename, "wb") as code:
for chunk in file.iter_content(chunk_size=1024): # 边下载边存硬盘
if chunk:
code.write(chunk)
@classmethod
def get_pictures(cls, shop_name: str, data: pd.DataFrame, pic_dir: pl.Path):
"""
批量获取图片数据的方法
:param shop_name: 店铺名
:param data: 数据
:param pic_dir: 图片存放的目录
:return:
"""
print(f'开始下载店铺:{shop_name} 的图片')
# 下载前按照菜品名称与图片地址进行去重处理,减少请求数量
download_data = data.copy()
download_data = download_data.drop_duplicates(['name', 'picture'], keep='last')
# 筛选去除图片地址为空的
download_data = download_data.loc[
(download_data['picture'].map(lambda x: pd.notnull(x))) |
(download_data['picture'] != '')
]
max_len = len(download_data)
for idx, food in enumerate(download_data.to_dict(orient='records')): # 遍历数据
pic_url = food['picture']
# 拆分获取图片扩展名
suffix = pl.Path(pic_url.split('/')[-1]).suffix
# 加工出图片的路径(包含名称)
name = food['name'].replace('\\', '_').replace('/', '_')
filename = pic_dir / f"{name}{suffix}"
# 使用下载方法下载
try:
cls.download_picture(pic_url, filename)
print(f'({idx+1}/{max_len})菜品:{food["name"]} 图片下载完成')
except Exception as e:
print(f'!!!({idx+1}/{max_len})菜品:{food["name"]} 图片下载失败,错误提示是: {e}')
# 随机暂停
time.sleep(randint(1, 3) / 10)
@classmethod
def write_data(cls, shop_name, data, shop_dir):
"""
将数据输出至excel文件
:param shop_name: 店铺名
:param data: 数据
:param shop_dir: 店铺存放的文件夹
:return:
"""
data.to_excel(shop_dir / f'{shop_name}.xlsx', index=False)
def run(self):
"""
运行程序
:return:
"""
try:
for filename in self.file_path.iterdir():
# 先解析人工取得的数据
shop_name, data = self.parse_data(filename)
# 再创建文件夹
shop_dir, pic_dir = self.create_dir(shop_name)
# 写入Excel文件
self.write_data(shop_name, data, shop_dir)
# 获取图片
self.get_pictures(shop_name, data, pic_dir)
print(f'店铺:{shop_name}的数据已解析下载完毕,数据存储在:“{shop_dir.absolute()}”路径下')
return True, None
except Exception as e:
return False, e
if __name__ == '__main__':
spider = SpiderObj()
res, err = spider.run()
if res:
input('程序已运行完毕,按回车键退出')
else:
input(f'程序运行出错,错误提示是: {err}')
程序运行

总结
不管全自动还是半自动,能解决问题的都是好爬虫。最后实现的爬虫实际上使用到的知识点都不是困难的:
读取文件,使用json、pandas解析数据输出Excel表格; 使用for循环,requests的get请求下载图片 创建文件夹,去重、try-except等
因此需求是要进行多沟通的,说不定沟通后有难度的会变成没有难度的...
至于回避的那三个难点留给某位大老板用Money激发我去攻克吧^_^
今晚来蚂蚁老师抖音直播间,Python带副业全套餐有优惠!!!