
保姆级教程,用 PyTorch 和 BERT 进行文本分类
共 23296字,需浏览 47分钟
· 2022-06-21
在这篇文章中,我们将使用来自 Hugging Face 的预训练 BERT 模型进行文本分类任务。一般而言,文本分类任务中模型的主要目标是将文本分类为预定义的标签或标签之一。
本文中,我们使用 BBC 新闻分类数据集,使用预训练的 BERT 模型来分类新闻文章的文本是否可以分类为体育、政治、商业、娱乐或科技类别。
什么是 BERT
BERT 是 Bidirectional Encoder Representations from Transformers 的首字母缩写词。
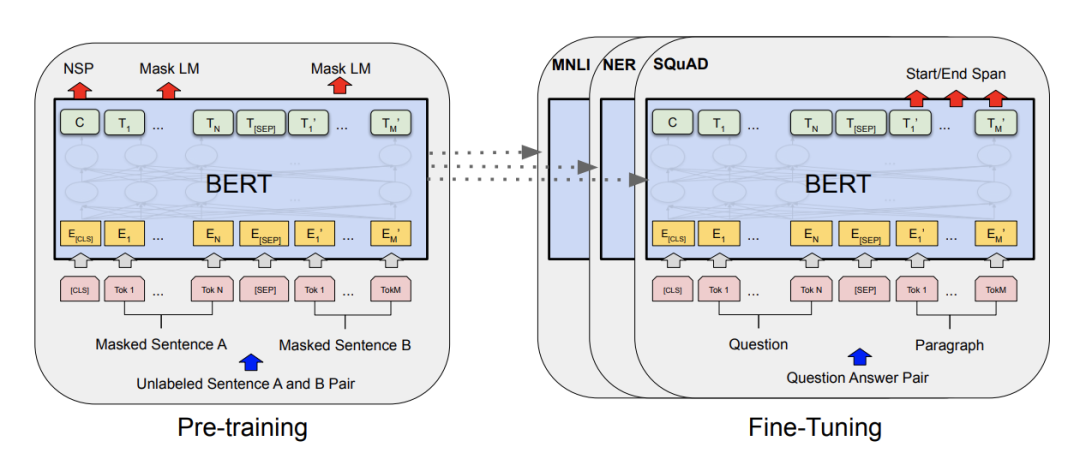
BERT 架构由多个堆叠在一起的 Transformer 编码器组成。每个 Transformer 编码器都封装了两个子层:一个自注意力层和一个前馈层。
有两种不同的 BERT 模型:
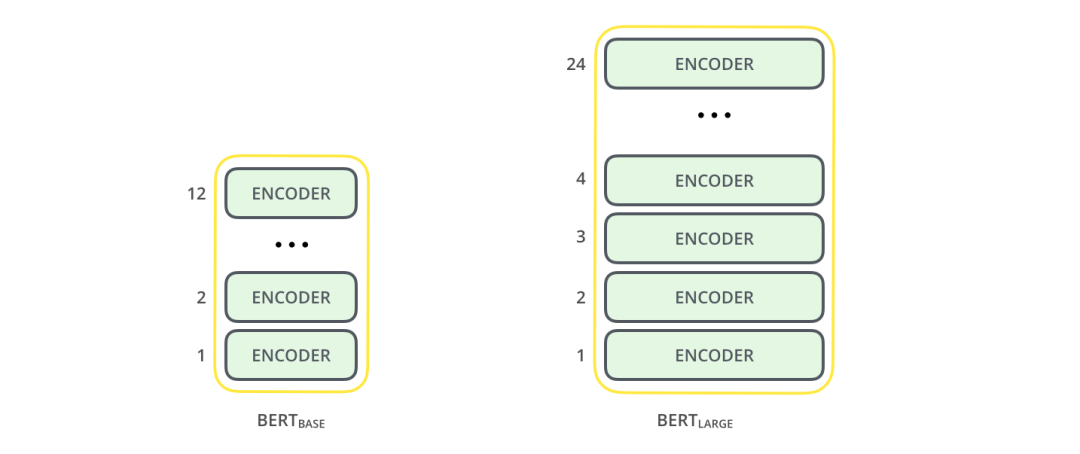
BERT base 模型,由 12 层 Transformer 编码器、12 个注意力头、768 个隐藏大小和 110M 参数组成。 BERT large 模型,由 24 层 Transformer 编码器、16 个注意力头、1024 个隐藏大小和 340M 个参数组成。
BERT 是一个强大的语言模型至少有两个原因:
它使用从 BooksCorpus (有 8 亿字)和 Wikipedia(有 25 亿字)中提取的未标记数据进行预训练。 顾名思义,它是通过利用编码器堆栈的双向特性进行预训练的。这意味着 BERT 不仅从左到右,而且从右到左从单词序列中学习信息。
论文
Transformer: Attention Is All You Need:https://arxiv.org/abs/1706.03762 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding:https://arxiv.org/abs/1810.04805
源码
Transformer Pytorch源码:https://github.com/jadore801120/attention-is-all-you-need-pytorch BERT Pytorch源码:https://github.com/hichenway/CodeShare/tree/master/bert_pytorch_source_code HuggingFace Transformers:https://github.com/huggingface/transformers
BERT 输入
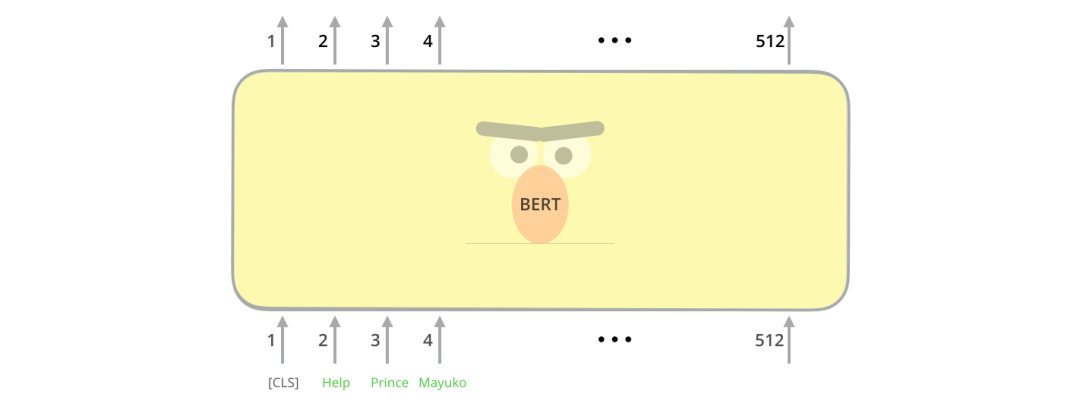
BERT 模型需要一系列 tokens (words) 作为输入。在每个token序列中,BERT 期望输入有两个特殊标记:
[CLS]:这是每个sequence的第一个token,代表分类token。[SEP]:这是让BERT知道哪个token属于哪个序列的token。这一特殊表征法主要用于下一个句子预测任务或问答任务。如果我们只有一个sequence,那么这个token将被附加到序列的末尾。
为什么选它们(
[CLS]/[SEP])呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。具体来说,self-attention 是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层,每次词的 Embedding 融合了所有词的信息,可以去更好的表示自己的语义。
而
[CLS]位本身没有语义,经过12层,得到的是attention后所有词的加权平均,相比其他正常词,可以更好的表征句子语义。
就像Transformer的普通编码器一样,BERT 将一系列单词作为输入,这些单词不断向上流动。每一层都应用自我注意,并将其结果通过前馈网络传递,然后将其传递给下一个编码器。
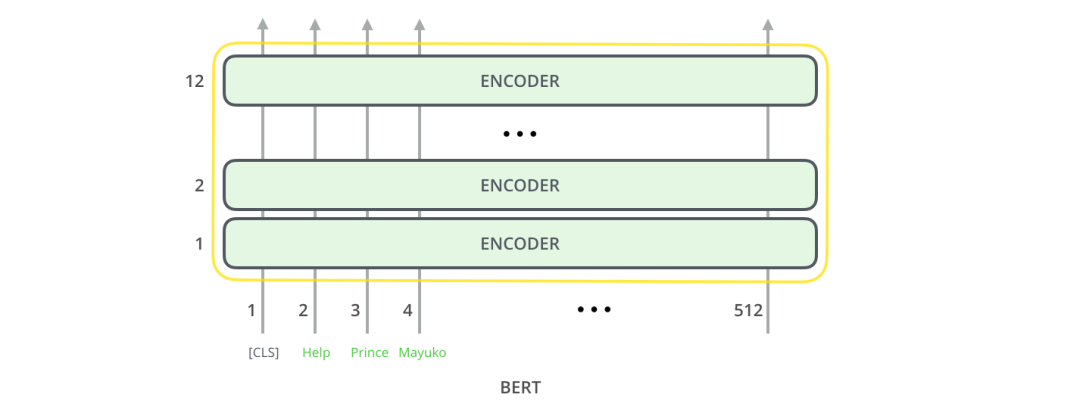
举个简单的例子以更清楚说明,假设我们有一个包含以下短句的文本:

第一步,需要将这个句子转换为一系列tokens (words) ,这个过程称为tokenization。
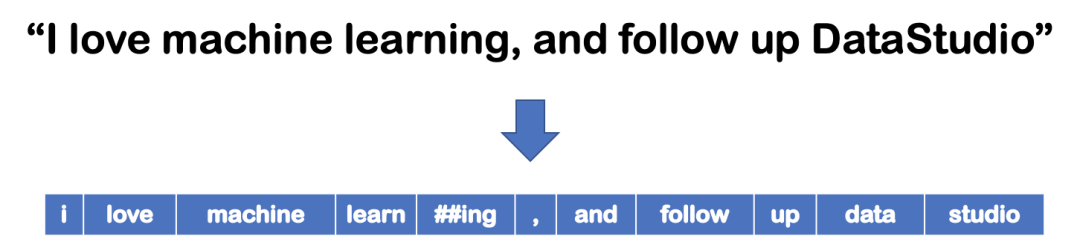
虽然已经对输入句子进行了标记,但还需要再做一步。在将其用作 BERT 模型的输入之前,我们需要通过添加 [CLS] 和 [SEP] 标记来对 tokens 的 sequence 重新编码。
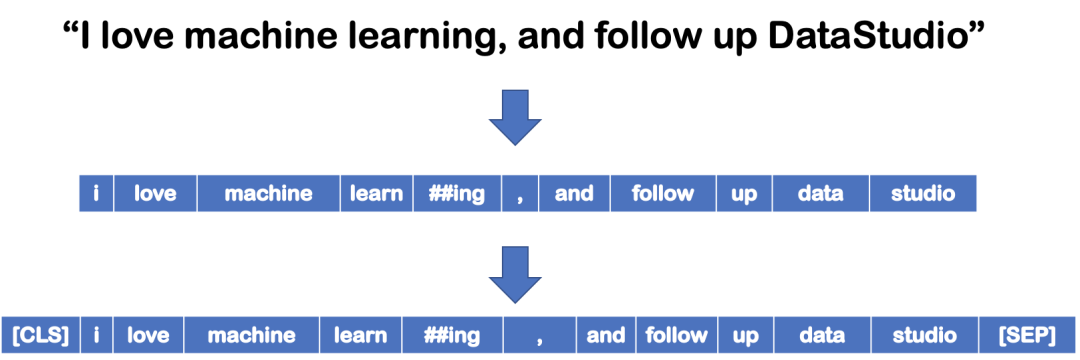
其实我们只需要一行代码(即使用BertTokenizer)就可以将输入句子转换为 BERT 所期望的tokens 序列。
还需要注意的是,可以输入 BERT 模型的最大tokens大小为 512。如果sequence中的tokens小于 512,我们可以使用填充来用 [PAD] 填充未使用的tokens。如果sequence中的tokens长于 512,那么需要进行截断。
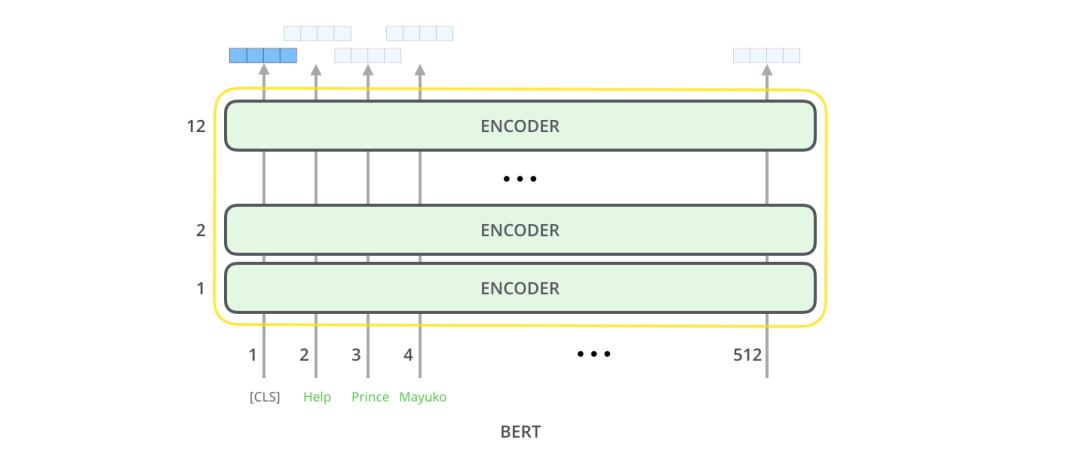
BERT 输出
每个位置输出一个大小为 hidden_ size的向量(BERT Base 中为 768)。对于我们在上面看到的句子分类示例,我们只关注第一个位置的输出(将特殊的 [CLS] token 传递到该位置)。
该向量现在可以用作我们选择的分类器的输入。该论文仅使用单层神经网络作为分类器就取得了很好的效果。
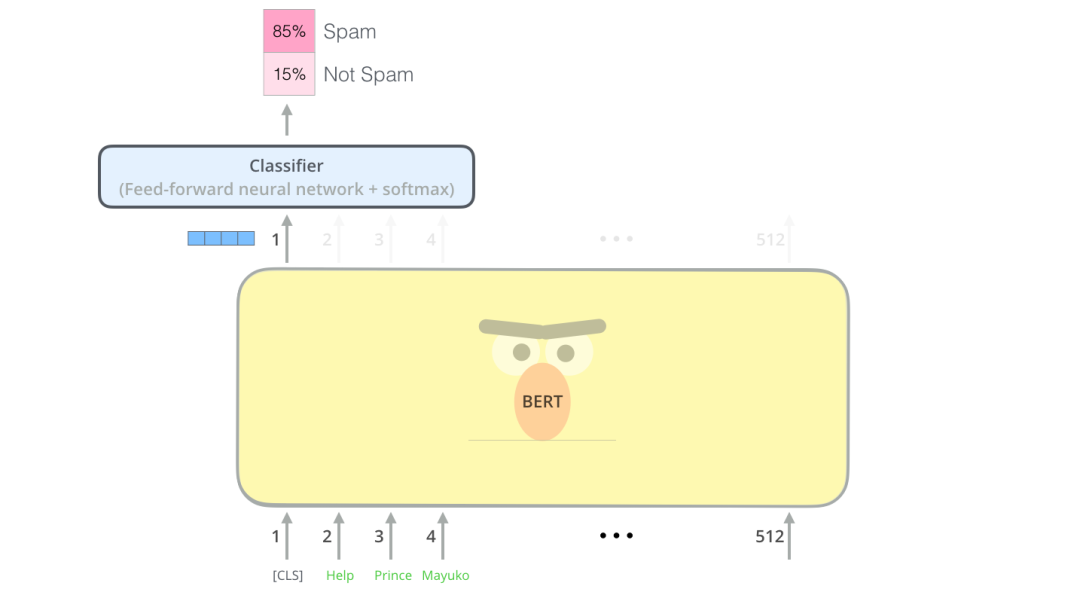
如果有更多标签,只需调整分类器网络以获得更多输出神经元然后通过softmax输出多标签分类。
使用 BERT 进行文本分类
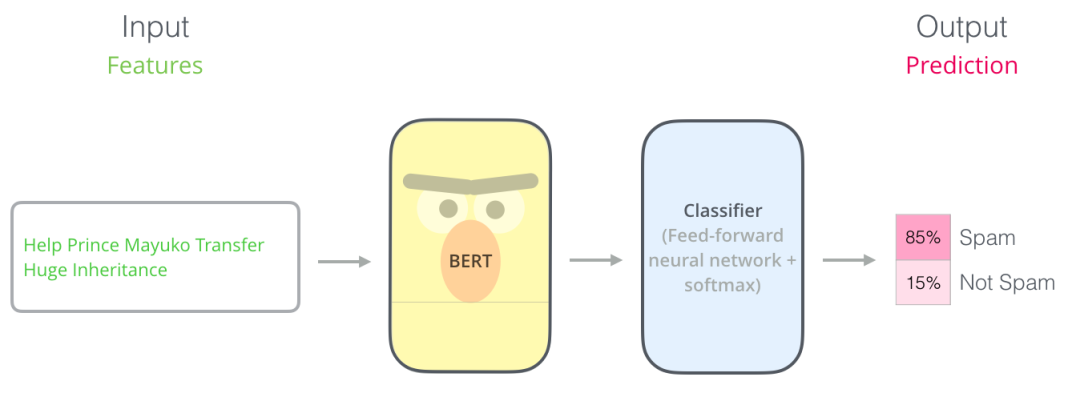
本文的主题是用 BERT 对文本进行分类。在这篇文章中,我们将使用kaggle上的BBC 新闻分类数据集。
数据集已经是 CSV 格式,它有 2126 个不同的文本,每个文本都标记在 5 个类别中的一个下:sport(体育),business(商业),politics(政治),tech(科技),entertainment(娱乐)。
看一下数据集的样子:

如上表所示,数据框只有两列,category 将作为标签,text 将作为 BERT 的输入数据。
预模型下载和使用
BERT 预训练模型的下载有许多方式,比如从github官网上下载(官网下载的是tensorflow版本的),还可以从源码中找到下载链接,然后手动下载,最后还可以从huggingface中下载。
从huggingface下载预训练模型的地址:https://huggingface.co/models
在搜索框搜索到你需要的模型。
来到下载页面:
注意,这里常用的几个预训练模型,bert-base-cased、bert-base-uncased及中文bert-base-chinese。其中前两个容易混淆。bert-base-cased是区分大小写,不需要事先lower-case;而bert-base-uncased不能区分大小写,因为词表只有小写,需要事先lower-case。
基本使用示例:
from transformers import BertModel,BertTokenizer
BERT_PATH = './bert-base-cased'
tokenizer = BertTokenizer.from_pretrained(BERT_PATH)
print(tokenizer.tokenize('I have a good time, thank you.'))
bert = BertModel.from_pretrained(BERT_PATH)
print('load bert model over')
['I', 'have', 'a', 'good', 'time',
',', 'thank', 'you', '.']
load bert model over
预处理数据
现在我们基本熟悉了 BERT 的基本使用,接下来为其准备输入数据。一般情况下,在训练模型前,都需要对手上的数据进行预处理,以满足模型需要。
前面已经介绍过了,模型输入数据中,需要通过添加 [CLS] 和 [SEP] 这两个特殊的token,将文本转换为 BERT 所期望的格式。
首先,需要通过 pip 安装 Transformers 库:
%%capture
!pip install transformers
为了更容易理解得到的输出tokenization,我们以一个简短的文本为例。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
example_text = 'I will watch Memento tonight'
bert_input = tokenizer(example_text,padding='max_length',
max_length = 10,
truncation=True,
return_tensors="pt")
# ------- bert_input ------
print(bert_input['input_ids'])
print(bert_input['token_type_ids'])
print(bert_input['attention_mask'])
tensor([[ 101, 146, 1209, 2824, 2508,
26173, 3568, 102, 0, 0]])
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0]])
下面是对上面BertTokenizer参数的解释:
padding:将每个sequence填充到指定的最大长度。max_length: 每个sequence的最大长度。本示例中我们使用 10,但对于本文实际数据集,我们将使用 512,这是 BERT 允许的sequence 的最大长度。truncation:如果为True,则每个序列中超过最大长度的标记将被截断。return_tensors:将返回的张量类型。由于我们使用的是 Pytorch,所以我们使用pt;如果你使用 Tensorflow,那么你需要使用tf。
从上面的变量中看到的输出bert_input,是用于稍后的 BERT 模型。但是这些输出是什么意思?
1. 第一行是 input_ids,它是每个 token 的 id 表示。实际上可以将这些输入 id 解码为实际的 token,如下所示:
example_text = tokenizer.decode(bert_input.input_ids[0])
print(example_text)
'[CLS] I will watch Memento tonight
[SEP] [PAD] [PAD]'
由上述结果所示,BertTokenizer负责输入文本的所有必要转换,为 BERT 模型的输入做好准备。它会自动添加 [CLS]、[SEP] 和 [PAD] token。由于我们指定最大长度为 10,所以最后只有两个 [PAD] token。
2. 第二行是 token_type_ids,它是一个 binary mask,用于标识 token 属于哪个 sequence。如果我们只有一个 sequence,那么所有的 token 类型 id 都将为 0。对于文本分类任务,token_type_ids是 BERT 模型的可选输入参数。
3. 第三行是 attention_mask,它是一个 binary mask,用于标识 token 是真实 word 还是只是由填充得到。如果 token 包含 [CLS]、[SEP] 或任何真实单词,则 mask 将为 1。如果 token 只是 [PAD] 填充,则 mask 将为 0。
注意到,我们使用了一个预训练BertTokenizer的bert-base-cased模型。如果数据集中的文本是英文的,这个预训练的分词器就可以很好地工作。
如果有来自不同语言的数据集,可能需要使用bert-base-multilingual-cased。具体来说,如果你的数据集是德语、荷兰语、中文、日语或芬兰语,则可能需要使用专门针对这些语言进行预训练的分词器。可以在此处查看相应的预训练标记器的名称[1]。特别地,如果数据集中的文本是中文的,需要使用bert-base-chinese 模型,以及其相应的BertTokenizer等。
数据集类
现在我们知道从BertTokenizer中获得什么样的输出,接下来为新闻数据集构建一个Dataset类,该类将作为一个类来将新闻数据转换成模型需要的数据格式。
上下滑动查看更多源码
import torch
import numpy as np
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
labels = {'business':0,
'entertainment':1,
'sport':2,
'tech':3,
'politics':4
}
class Dataset(torch.utils.data.Dataset):
def __init__(self, df):
self.labels = [labels[label] for label in df['category']]
self.texts = [tokenizer(text,
padding='max_length',
max_length = 512,
truncation=True,
return_tensors="pt")
for text in df['text']]
def classes(self):
return self.labels
def __len__(self):
return len(self.labels)
def get_batch_labels(self, idx):
# Fetch a batch of labels
return np.array(self.labels[idx])
def get_batch_texts(self, idx):
# Fetch a batch of inputs
return self.texts[idx]
def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y
在上面实现的代码中,我们定义了一个名为 labels的变量,它是一个字典,将DataFrame中的 category 映射到 labels的 id 表示。注意,上面的__init__函数中,还调用了BertTokenizer将输入文本转换为 BERT 期望的向量格式。
定义Dataset类后,将数据框拆分为训练集、验证集和测试集,比例为 80:10:10。
np.random.seed(112)
df_train, df_val, df_test = np.split(df.sample(frac=1, random_state=42),
[int(.8*len(df)), int(.9*len(df))])
print(len(df_train),len(df_val), len(df_test))
1780 222 223
构建模型
至此,我们已经成功构建了一个 Dataset 类来生成模型输入数据。现在使用具有 12 层 Transformer 编码器的预训练 BERT 基础模型构建实际模型。
如果数据集中的文本是中文的,需要使用bert-base-chinese 模型。
from torch import nn
from transformers import BertModel
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-cased')
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, 5)
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id, attention_mask=mask,return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer
从上面的代码可以看出,BERT 模型输出了两个变量:
在上面的代码中命名的第一个变量 _包含sequence中所有 token 的 Embedding 向量层。命名的第二个变量 pooled_output包含 [CLS] token 的 Embedding 向量。对于文本分类任务,使用这个 Embedding 作为分类器的输入就足够了。
然后将pooled_output变量传递到具有 ReLU 激活函数的线性层。在线性层中输出一个维度大小为 5 的向量,每个向量对应于标签类别(运动、商业、政治、 娱乐和科技)。
训练模型
接下来是训练模型。使用标准的 PyTorch 训练循环来训练模型。
上下滑动查看更多源码
from torch.optim import Adam
from tqdm import tqdm
def train(model, train_data, val_data, learning_rate, epochs):
# 通过Dataset类获取训练和验证集
train, val = Dataset(train_data), Dataset(val_data)
# DataLoader根据batch_size获取数据,训练时选择打乱样本
train_dataloader = torch.utils.data.DataLoader(train, batch_size=2, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2)
# 判断是否使用GPU
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
if use_cuda:
model = model.cuda()
criterion = criterion.cuda()
# 开始进入训练循环
for epoch_num in range(epochs):
# 定义两个变量,用于存储训练集的准确率和损失
total_acc_train = 0
total_loss_train = 0
# 进度条函数tqdm
for train_input, train_label in tqdm(train_dataloader):
train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
# 通过模型得到输出
output = model(input_id, mask)
# 计算损失
batch_loss = criterion(output, train_label)
total_loss_train += batch_loss.item()
# 计算精度
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
# 模型更新
model.zero_grad()
batch_loss.backward()
optimizer.step()
# ------ 验证模型 -----------
# 定义两个变量,用于存储验证集的准确率和损失
total_acc_val = 0
total_loss_val = 0
# 不需要计算梯度
with torch.no_grad():
# 循环获取数据集,并用训练好的模型进行验证
for val_input, val_label in val_dataloader:
# 如果有GPU,则使用GPU,接下来的操作同训练
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, val_label)
total_loss_val += batch_loss.item()
acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc
print(
f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train_data): .3f}
| Train Accuracy: {total_acc_train / len(train_data): .3f}
| Val Loss: {total_loss_val / len(val_data): .3f}
| Val Accuracy: {total_acc_val / len(val_data): .3f}''') 我们对模型进行了 5 个 epoch 的训练,我们使用 Adam 作为优化器,而学习率设置为1e-6。因为本案例中是处理多类分类问题,则使用分类交叉熵作为我们的损失函数。
建议使用 GPU 来训练模型,因为 BERT 基础模型包含 1.1 亿个参数。
EPOCHS = 5
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)
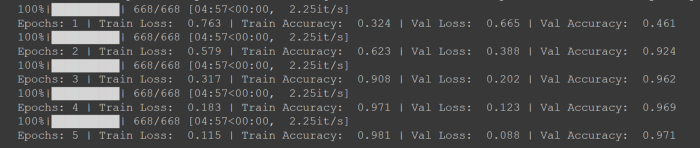
显然,由于训练过程的随机性,每次可能不会得到与上面截图类似的损失和准确率值。如果在 5 个 epoch 之后没有得到好的结果,可以尝试将 epoch 增加到 10 个,或者调整学习率。
在测试数据上评估模型
现在我们已经训练了模型,我们可以使用测试数据来评估模型在未见数据上的性能。下面是评估模型在测试集上的性能的函数。
def evaluate(model, test_data):
test = Dataset(test_data)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
if use_cuda:
model = model.cuda()
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_dataloader:
test_label = test_label.to(device)
mask = test_input['attention_mask'].to(device)
input_id = test_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(test_data): .3f}')
evaluate(model, df_test)
运行上面的代码后,我从测试数据中得到了 0.994 的准确率。由于训练过程中的随机性,将获得的准确度可能会与我的结果略有不同。
讨论两个问题
这里有个问题:使用BERT预训练模型为什么最多只能输入512个词,最多只能两个句子合成一句?
这是Google BERT预训练模型初始设置的原因,前者对应Position Embeddings,后者对应Segment Embeddings
在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的,pytorch代码中它们是这样的
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
而在BERT config中
"max_position_embeddings": 512
"type_vocab_size": 2
因此,在直接使用 Google 的 BERT 预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的 Embedding 。
当然,如果有足够的硬件资源自己重新训练 BERT,可以更改 BERT config,设置更大 max_position_embeddings 和 type_vocab_size 值去满足自己的需求。
此外还有人问 BERT的三个Embedding直接相加会对语义有影响吗?
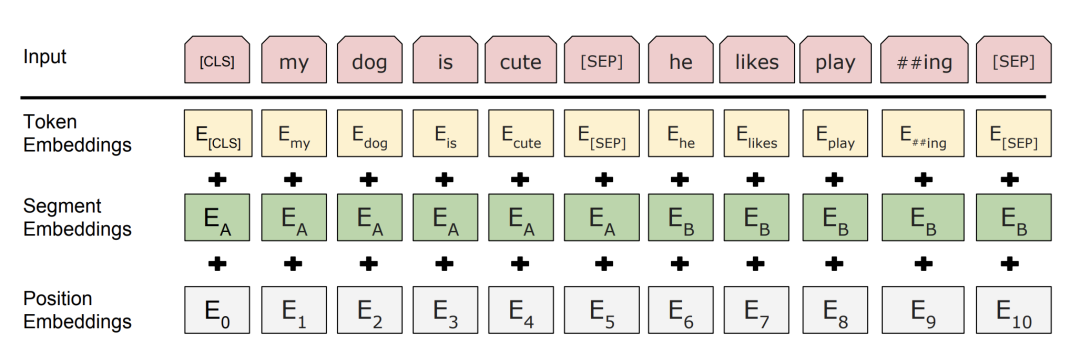
这是一个非常有意思的问题,苏剑林老师也给出了回答,真的很妙啊:
Embedding 的数学本质,就是以 one hot 为输入的单层全连接。也就是说,世界上本没什么 Embedding,有的只是one hot。
在这里想用一个例子再尝试解释一下:
假设 token Embedding 矩阵维度是 [4,768];position Embedding 矩阵维度是 [3,768];segment Embedding 矩阵维度是 [2,768]。
对于一个字,假设它的 token one-hot 是[1,0,0,0];它的 position one-hot 是[1,0,0];它的 segment one-hot 是[1,0]。
那这个字最后的 word Embedding,就是上面三种 Embedding 的加和。
如此得到的 word Embedding,和concat后的特征:[1,0,0,0,1,0,0,1,0],再过维度为 [4+3+2,768] = [9, 768] 的全连接层,得到的向量其实就是一样的。
再换一个角度理解:
直接将三个one-hot 特征 concat 起来得到的 [1,0,0,0,1,0,0,1,0] 不再是one-hot了,但可以把它映射到三个one-hot 组成的特征空间,空间维度是 432=24 ,那在新的特征空间,这个字的one-hot就是[1,0,0,0,0...] (23个0)。
此时,Embedding 矩阵维度就是 [24,768],最后得到的 word Embedding 依然是和上面的等效,但是三个小 Embedding 矩阵的大小会远小于新特征空间对应的 Embedding 矩阵大小。
当然,在相同初始化方法前提下,两种方式得到的 word Embedding 可能方差会有差别,但是,BERT还有Layer Norm,会把 Embedding 结果统一到相同的分布。
BERT的三个Embedding相加,本质可以看作一个特征的融合,强大如 BERT 应该可以学到融合后特征的语义信息的
这就是 BERT 期望的所有输入。
然后,BERT 模型将在每个token中输出一个大小为 768 的 Embedding 向量。我们可以将这些向量用作不同类型 NLP 任务的输入,无论是文本分类、本文生成、命名实体识别 (NER) 还是问答。
对于文本分类任务,我们将注意力集中在特殊 [CLS] token 的 embedding 向量输出上。这意味着我们将使用具有 [CLS] token 的大小为 768 的 embedding 向量作为分类器的输入,然后它将输出一个大小为分类任务中类别个数的向量。
写在最后
现在我们如学会了何利用 Hugging Face 的预训练 BERT 模型进行文本分类任务的步骤。我希望在你开始使用 BERT是,这篇文章能帮到你。我们不仅可以使用来自 BERT 的embedding向量来执行句子或文本分类任务,还可以执行更高级的 NLP 应用,例如问答、文本生成或命名实体识别 (NER)任务。
参考资料
预训练标记器的名称: https://huggingface.co/transformers/pretrained_models.html
[2]参考: https://zhuanlan.zhihu.com/p/132554155
[3]参考: https://jalammar.github.io/illustrated-bert/
精选文章
LIWC vs Python | 文本分析之词典统计法略讲(含代码)