
天池算法大赛项目:基于大规模日志的故障诊断亚军方案!
赛题描述
第三届阿里云磐久智维算法大赛:本次比赛要求选手基于故障工单与系统日志数据构建多分类模型,要求能够快速高效的定位出故障类型。
赛事官方地址:
https://tianchi.aliyun.com/competition/entrance/531947/information
项目代码开源地址:
https://github.com/yz-intelligence/AI-Competition/blob/main/3rd_PanJiu_AIOps_Competition/README.md
亚军方案答辩PPT和打包数据可在Datawhale公众号后台回复 黑桃 下载
评价指标
本次采用的评价指标是加权的F1-Score,对类别0和类别1赋予了更大的权重。

赛题数据
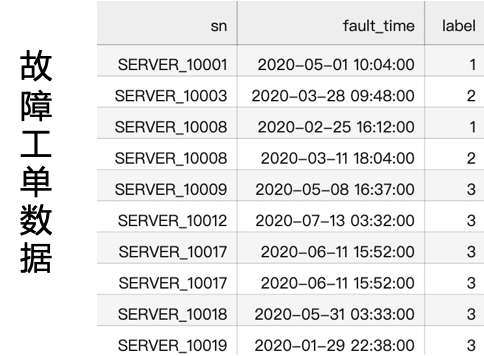
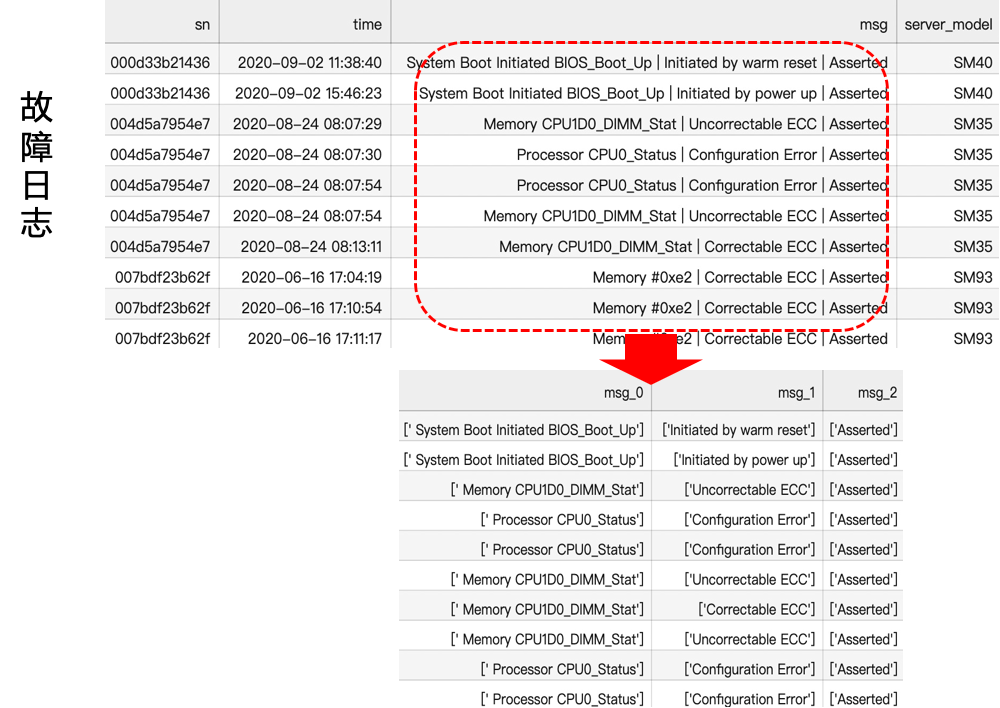
本赛题提供了故障工单与日志数据,具体数据如下图所示。通过初步分析msg的结构,根据|可以将其分解。根据实际的业务场景,我们认为在故障发生的前后5/10/15/30分钟或更久,所产生的日志信息,都可能与此故障有关。
数据分析
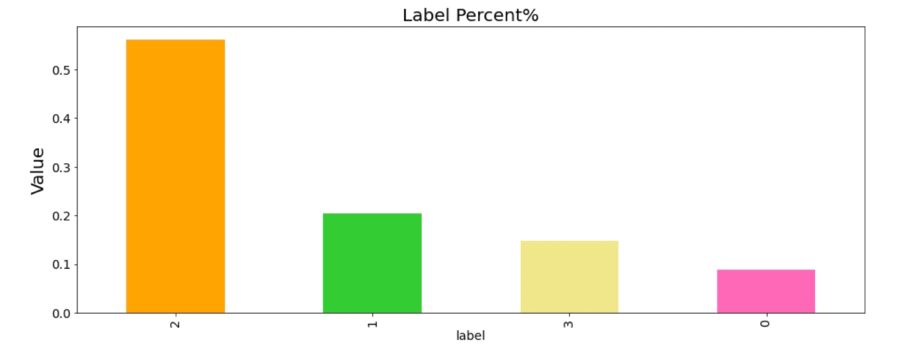
标签分布
通过分析标签分布,类别0和类别1表示CPU相关故障类别0占比最少,只有9%,类别2表示内存相关故障,占比最多,达到56%,类别3表示其他类型故障。
sn分布
sn代表服务器序列号,故障工单中共有13700+个sn。
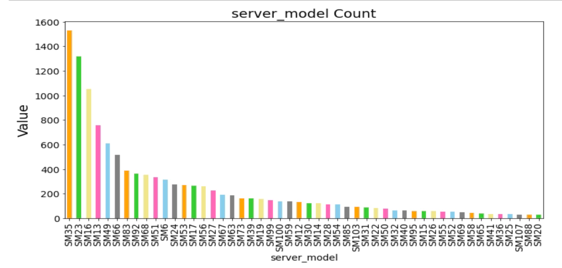
server_model分布
服务器型号server_model和服务器序列号sn是一对多的关系。
msg分析
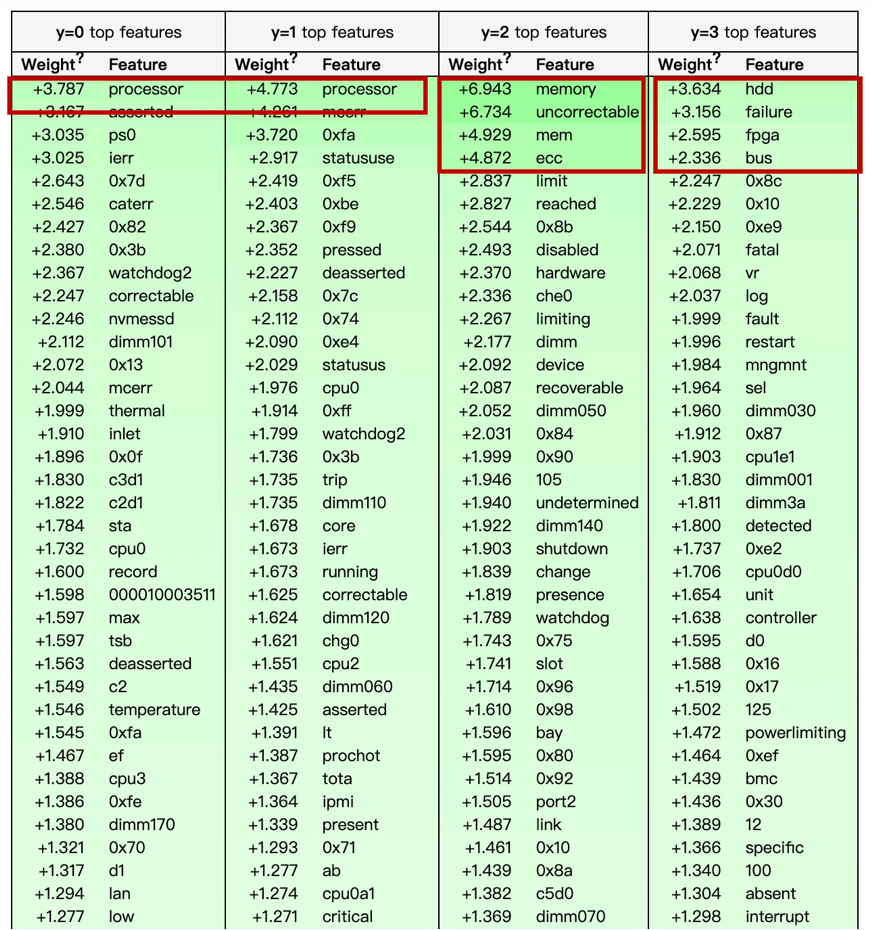
将msg经过TF-IDF编码,输入到线性模型中,使用eli5得出每个类别下,msg单词的贡献程度,权重越高表示区分该类别的贡献越大。
0类和1类表示CPU相关故障,processor的权重都是最高的,且区分度不是很高; 2类表示内存相关故障,权重较高的是memory、mem、ecc; 3类表示其他类型故障,权重较高的是hdd、fpga、bus,可能是和硬件相关的故障。
- 方案介绍
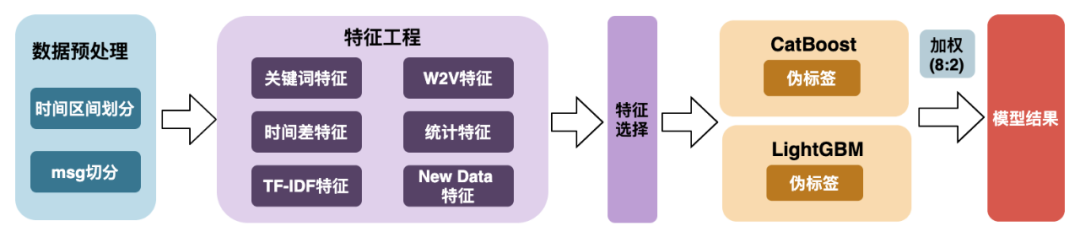
该方案主要基于智能运维场景,争取用更少的时间及资源达到最优效果,主要分为数据预处理,特征工程,特征选择,模型训练,模型融合。
数据预处理:按照距离故障发生时间的间隔,将日志分成不同的时间区间;msg根据特殊符号进行标准化。
特征工程:主要构建关键词特征、时间差特征、TF-IDF词频统计特征、W2V特征、统计特征、New Data特征。
特征选择:对抗验证进行特征选择,保证训练和测试集的一致性,提高模型在测试集的泛化能力。
模型训练:CatBoost与LightGBM使用伪标签技术进行模型训练。
模型融合:CatBoost与LightGBM的预测结果以8:2进行加权融合得到最终的模型预测结果。
数据预处理
根据实际业务场景,故障发生之前可能会有预警日志产生,故障发生之后可能会产生日志风暴,因此我们针对每一条故障工单数据,按照不同的时间切分构造新的日志数据,按照日志聚合之后构造统计特征。

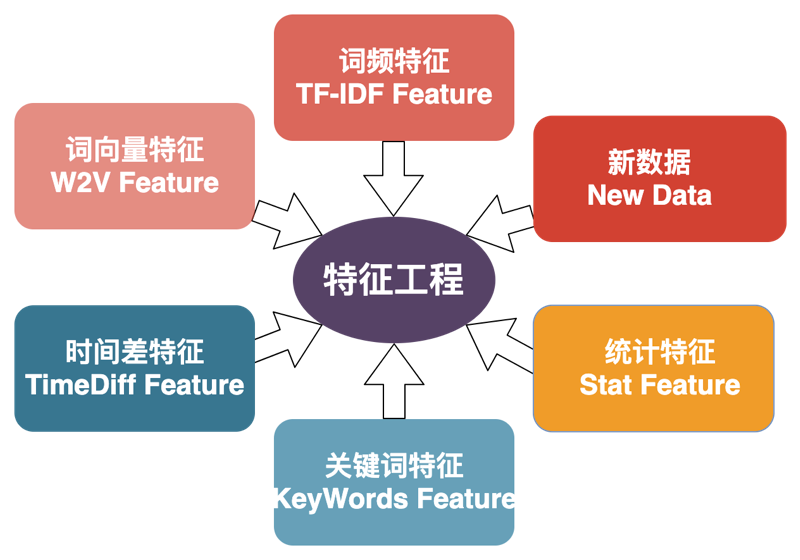
特征工程
本方案主要从以下几个层面构建特征。
时间差特征
主要反映故障日志与正常日志发生的间隔。特征构造方法:
获取日志时间和故障发生时间的时间差,并且结合
sn, server_model进行分组特征衍生。时间差的统计特征:
[max, min, median, std, var, skw, sum, mode]时间差的分位数特征:
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]时间差差分:
[max, min, median, std, var, skw, sum]
关键词特征
主要反映关键词对各个类别的影响。构造关键词特征首先要找到关键词,我们主要使用两种方法去定关键词:
方案1:将msg经过TF-IDF编码,输入到线性模型中,计算每个类别下关键词的权重,取每个类别的TOP20。 方案1:根据' | '对msg进行分词,统计每个类别的词频占比,取每个类别的TOP20。 方法1与方法2取并集,得到最终的关键词。 将每个关键词在msg中出现与否作为特征。
统计特征
根据类别特征分组构造统计特征,使类别特征隐藏的信息充分暴露出来。
根据
sn分组,server_mode统计特征:[count,nunique,freq,rank]根据
sn分组,日志统计特征:msg, msg_0, msg_1, msg_2:[count,nunique,freq,rank]
W2V特征
主要反映msg的语义信息
根据 sn分组,按照时间对msg进行排序,对于每一个sn,将排序好的msg作为一个序列,提取embedding特征。
TFIDF特征
根据fault_id(sn+fault_time)分组,对于每一个fault_id,将msg拼接作为一个序列,提取TF-IDF特征
venus、crashdump日志新数据特征构造
复赛阶段,主办方提供了新数据,通过分析发现fault_code与module_cause具有类似的结构,都是由键值对构成的,比如fault_code的键是cpu0,cpu1,cod1,cod2,每个键后面紧跟着它的值,下图是标准化之后的结果,基于此,我们构造了类别特征然后放入到模型进行训练,将预测出来的结果作为特征与其它特征一起训练。

特征选择
特征选择环节主要是使用对抗验证进行特征选择,将训练集与测试集删除label重新打标,训练集为1,测试集为0,数据集合并进行模型训练计算AUC,如果AUC大于设定好的阈值,那么将其特征重要性最高的特征删除,重新训练模型。直至AUC小于阈值。
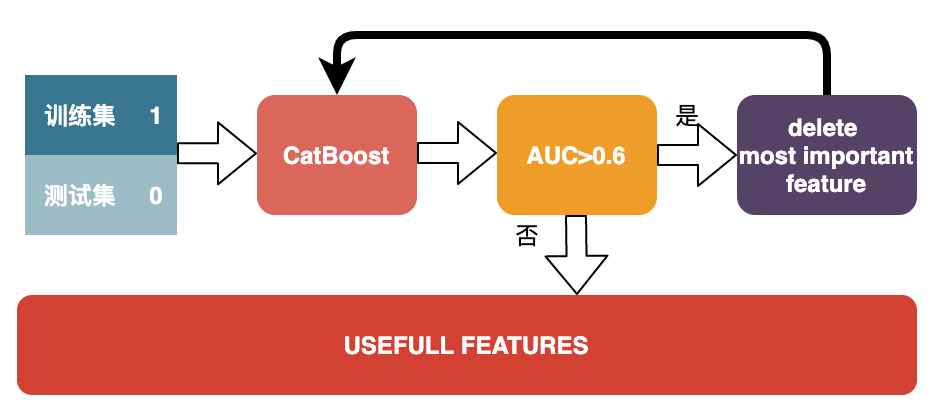
模型训练
我们对于CatBoost与LightGBM均进行五折交叉构造出5个模型,将预测出来的结果进行平均作为单模型最终结果,以保证模型的稳定性。最终 CatBoost 与 LightGBM 的预测结果以8:2进行加权得到最终的模型结果,下图是CatBoost的模型架构图,LightGBM采用的是同样的模型架构图。
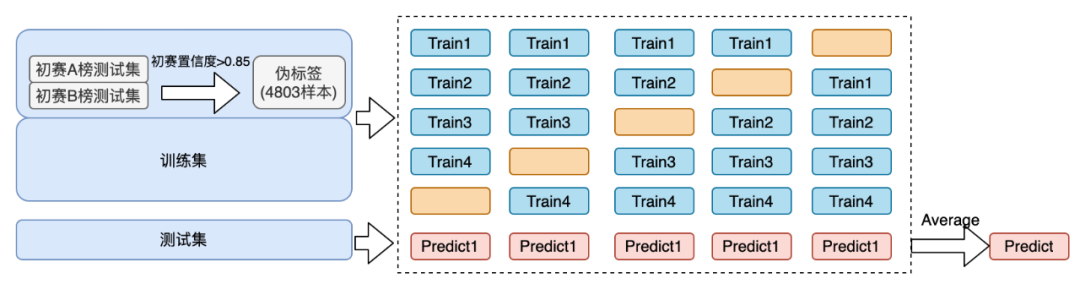
在模型训练的时候,我们还有用到伪标签技术,具体操作是将A、B榜测试集的预测结果,选取置信度>0.85的样本作为可信样本,加入到训练集中,达到增大样本量的目的。
总结
模型方案要考虑到落地情况。如智能运维场景下,计算资源一般不会太多,或没有GPU资源,部分场景要求高及时性,越快找到问题并解决,就能越快的恢复对应的业务线。 问题分析一定要考虑业务层面。与业务关联性越强的特征队模型的准确度提升越大。 使用对抗验证进行特征选择,保证训练集测试集的一致性,是提高模型准确性的关键。 对msg信息的充分挖掘,也使得模型在AB榜测试相对稳定。
整理不易,点赞三连↓