
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了,腾讯游戏和西工大联合出品
视学算法专栏
作者:腾讯游戏知几AI团队,西北工业大学音频、语音与语言处理研究组(ASLP@NPU)
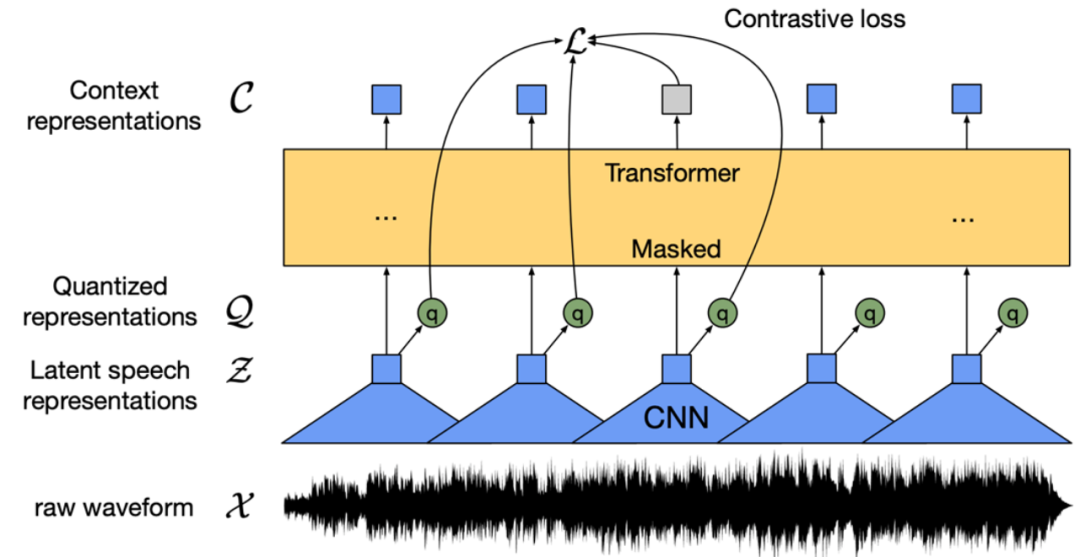
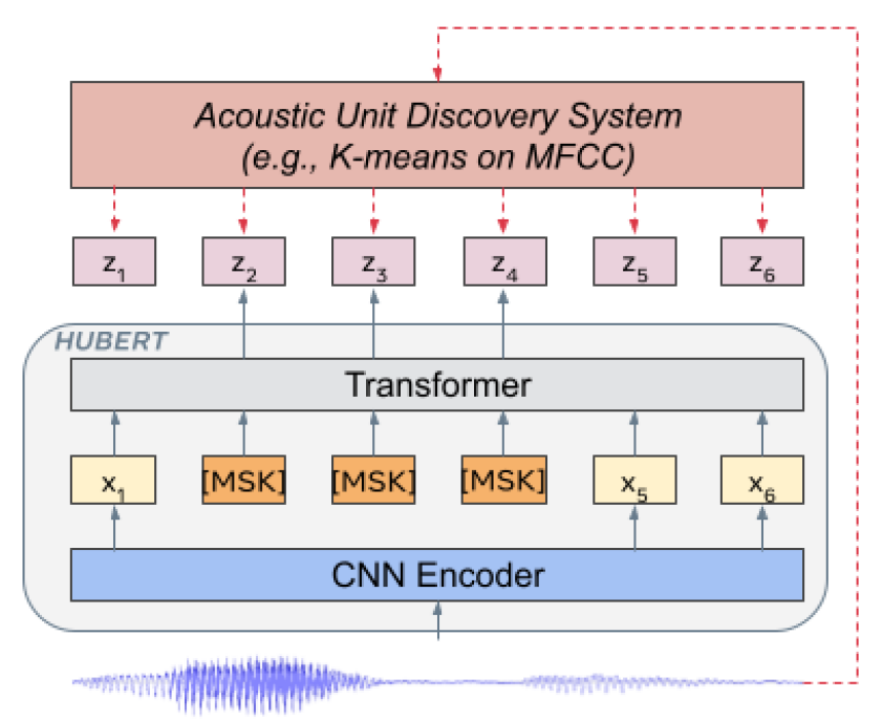
近日,腾讯游戏知几AI团队与西工大ASLP组联合发布了基于 WenetSpeech 1 万小时数据训练的中文版 Wav2vec 2.0 和 HuBERT 模型。
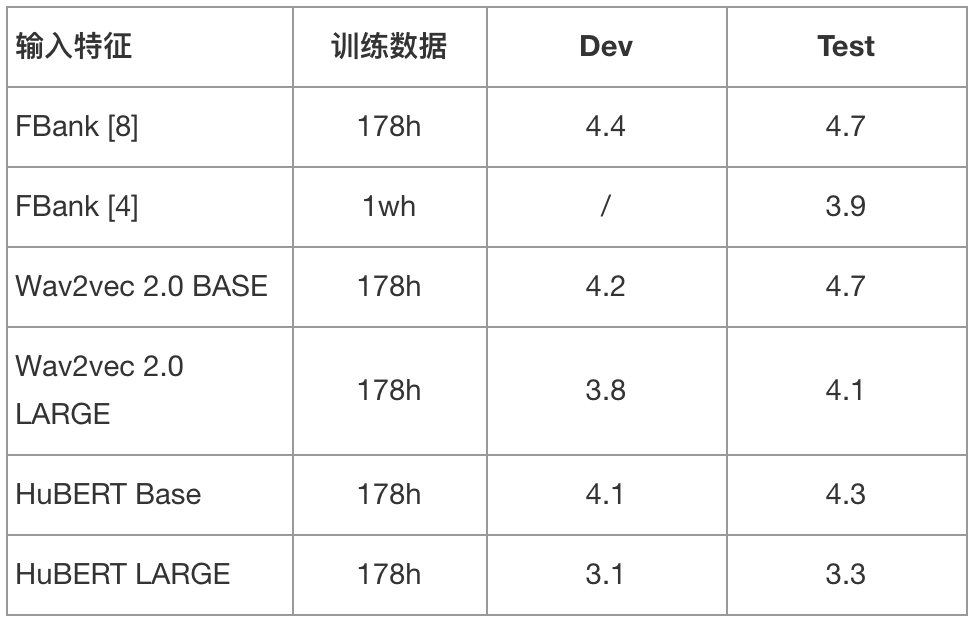
Aishell 数据集
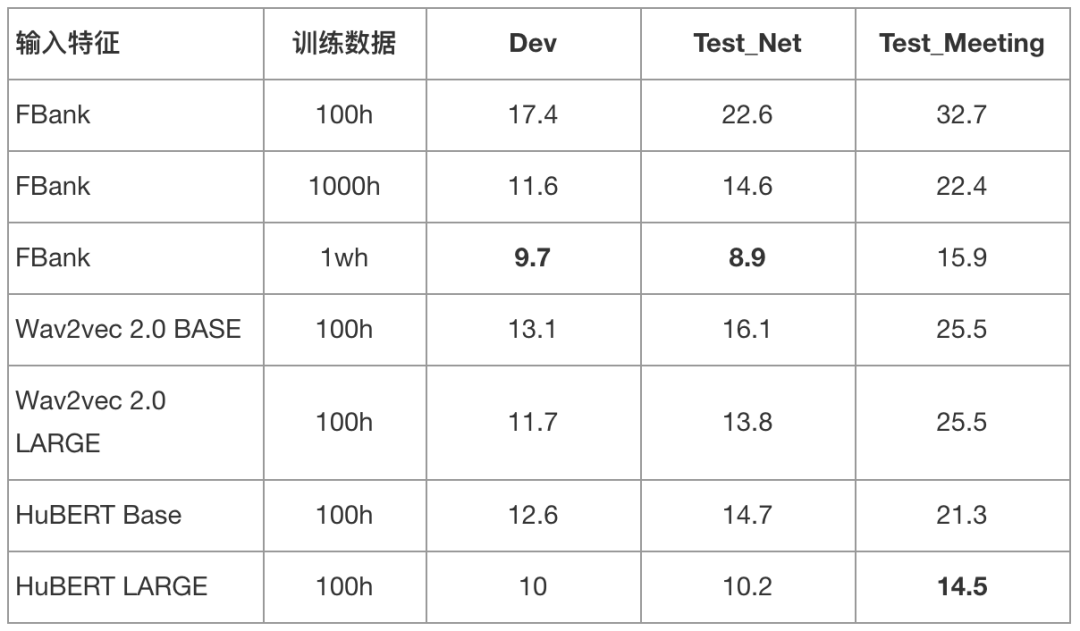
WenetSpeech 数据集
© THE END
转载请联系原公众号获得授权

点个在看 paper不断!
评论