 AI人工智能初学者
AI人工智能初学者






在
DETR出现之后,端到端的目标检测得到了迅速的发展。DETR使用一组稀疏查询来替换大多数传统检测器中的密集候选框。相比之下,稀疏查询不能保证作为密集先验的高召回率。但是,在当前框架中,使查询变得密集并非易事。它不仅计算成本高,而且优化困难。由于稀疏查询和密集查询都不完美,那么端到端目标检测中的预期查询是什么?本文表明预期的查询应该是密集的不同查询(
DDQ)。具体来说,将密集先验引入框架以生成密集查询。对这些查询应用重复查询删除预处理,以便它们彼此区分开来。然后迭代处理密集的不同查询以获得最终的稀疏输出。实验展示了
DDQ更强大、更健壮且收敛更快。它在MS COCO检测数据集上仅用 12 个 epoch 就获得了 44.5 AP;在各种数据集上的目标检测和实例分割任务上都优于以前的方法。DDQ融合了传统密集先验和最近的端到端检测器的优势。作者希望它可以将DDQ作为一个新的Baseline,并激发研究人员重新审视传统方法和端到端检测器之间的互补性。
1简介
目标检测是计算机视觉中最基本的挑战之一,旨在用单个边界框定位每个目标。它带来了一个具有挑战性的问题,即准确的目标检测器既要检测所有目标又要避免预测重复的框。
为了解决这个问题,以前最先进的方法大多遵循标准范式,如图 1(a)所示,首先生成密集的候选框,然后将一个 GT 分配给许多候选框以实现高目标召回;然而,一对多的分配会导致冗余预测。由于在目标检测中每个目标应该只有一个预测,因此采用辅助后处理,例如非极大值抑制(NMS)来去除重复的预测。尽管多年来一直主导目标检测,但该 Pipeline 在不损害正确预测的情况下完美过滤掉了重复框。

但是这种范式被端到端目标检测框架 DETR 所打破。与传统范式相比,它丢弃了密集的目标候选框,但直接初始化一组稀疏目标查询。在训练时,这些查询由一对一匹配损失监督,以便优化目标与目标检测的定义一致,即为图像中的每个目标只预测一个边界框。在这种情况下,网络不再需要后处理来删除重复的预测。然而,DETR 的收敛速度很慢,这在各种工作中都有所探索。遵循这一范式的一项代表性工作是Sparse R-CNN。Sparse R-CNN 将每个查询与 RoIAlign 提取的局部区域特征进行交互,与 DETR 相比,收敛速度更快。
重新审视图1(b)所示的端到端目标检测器框架,只有数百个由一对一匹配损失监督的稀疏查询。在本文中揭示了这种设计会引发两难境地。一方面,数百个稀疏查询并不足以保证高召回率。另一方面,当通过直接增加查询数量来达到更高的召回率来引入密集查询时,不可避免地会带来很多相似的查询(图1(c))。这些相似的查询混淆了网络,因为不同的标签被分配给相似的查询。这种选择稀疏或密集查询的困境启发思考端到端目标检测中的期望查询是什么?
本文回答了定量研究的问题,最后观察到端到端目标检测中的预期查询应该是密集的不同查询(DDQ),这意味着查询应该密集分布以检测所有目标, 以及彼此不同,以促进一对一匹配损失的优化。
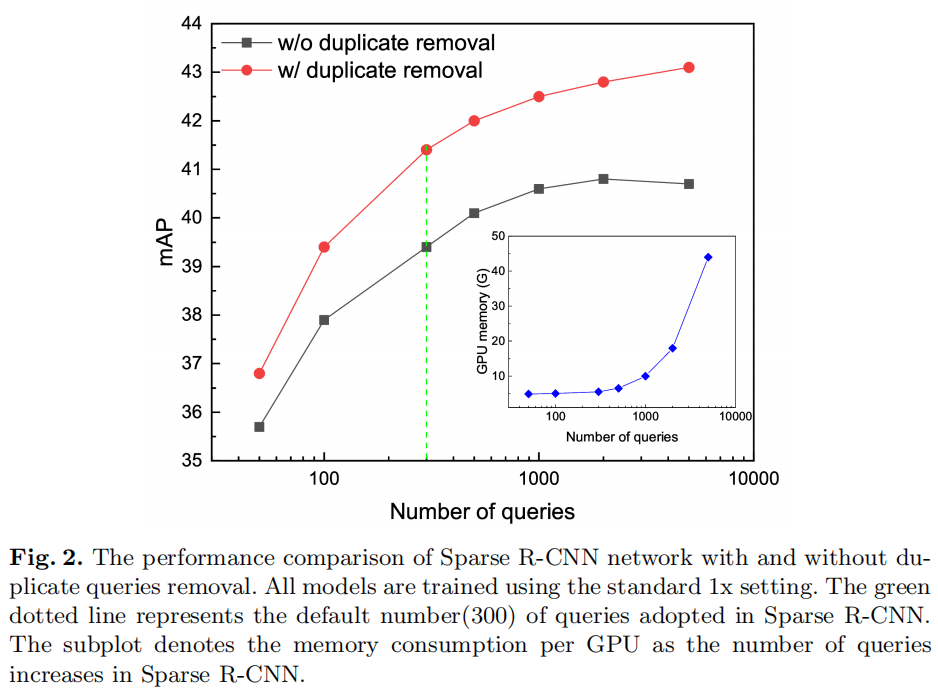
具体来说,如图 2 所示,增加了 Sparse R-CNN 中的查询数量。开始时性能会提高,但随着查询越密集,最终会趋于平稳甚至下降,因为随着查询越相似,训练变得更加困难。通过在迭代细化的每个阶段之前进行重复删除预处理以过滤掉相似的查询并获得不同的查询,性能得到了明显的提高。更令人惊讶的是,性能裕度随着查询的增加而不断增加。
受具有密集不同查询的 Sparse R-CNN 性能的启发,在大约 7000 个查询中没有达到稳定水平,作者建议在图像的每个位置上引入密集分布的查询,然后可以将其转换为密集的不同查询。这些密集分布的查询保证了足够高的召回率来覆盖所有潜在的目标对象。
然而,通过 Sparse R-CNN 的迭代细化直接处理密集分布的查询会导致无法承受的计算和 GPU 内存成本。
如图 2 所示,当有大约 7000 个查询时,Sparse R-CNN 需要大约 45G 的 GPU 内存,而图像特征图上可能有超过数万个像素。
因此,基于 Sparse-RCNN,本文提出了一个新的框架,Dense Distinct Queries(DDQ),为端到端的目标检测引入密集的不同查询,并克服了高计算成本。具体来说,DDQ 将每个特征图上的特征点作为密集分布的初始查询。代替繁重的 RoI refinement heads,轻量级的全卷积网络被应用于以滑动窗口方式处理所有查询,它与 Faster R-CNN 具有相似的架构。不同的是,DDQ 丢弃了 Anchor 设计,并应用二分匹配算法来自适应地确定正样本和负样本,从而在不同数据集上实现更高的召回率和鲁棒性。结果,密集查询被有效区分以生成具有合理计算成本的密集不同查询。此外,查询独特性增强机制进一步将这些密集的独特查询与其相应的 RoI 特征融合以增强其独特性。与需要 6 个迭代查询细化阶段的 Sparse R-CNN 不同,DDQ 只需 2 个细化阶段即可实现快速收敛和更高的性能。
实验结果评估了所提出方法的有效性和效率。DDQ 在多个目标检测数据集上都实现了超越SOTA的性能。例如,DDQ 使用 ResNet-50 在 MS-COCO 上进行正常 1x 训练就实现了 44.5 AP,这在很大程度上超过了当前最先进的检测器(包括基于 CNN 和基于 Transformer 的检测器)超出 2AP ,仅以极少的推理时间为代价。它还在 CrowdHuman 上以 93.2 AP 和 98.2 召回率。例如分割,DDQ 在 MS COCO 上的性能也显着优于 Cascade Mask R-CNN 3 和 LVIS v1.0 上的 3.7 。
2Dense Distinct Queries (DDQ)
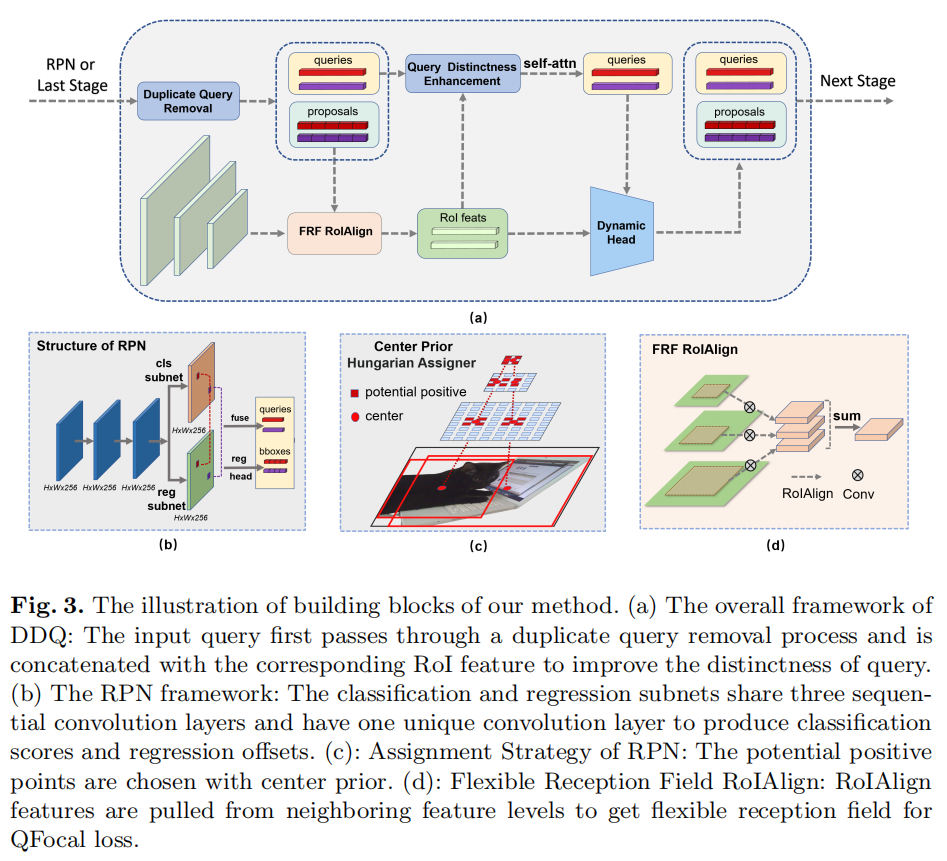
DDQ 是基于最近的端到端检测器设计具有快速收敛性的目标检测器的原理。因此,它能够推广到不同的架构。Pipeline 如图 3 所示。
2.1 致敬 Sparse R-CNN
Sparse R-CNN 主要遵循 DETR 的范式,由于其在解码过程中的显著改进,即使没有编码层也能获得更好的性能。Sparse R-CNN 利用动态实例交互来代替原来的交叉注意力解码部分。此外,Sparse R-CNN 中的每个目标查询只关注由 RoIAlign 算子提取的局部区域的特征,而不是像 DETR 中那样关注所有编码特征。
Sparse R-CNN 维护 N(N ∼300) 个独立查询,每个查询对应一个边界框。然后它使用边界框通过 RoIAlign 算子从特征金字塔中提取候选区域特征。然后使用每个查询嵌入来生成与 RoI 特征交互的卷积参数,以输出每个阶段的预测标签和边界框。
Sparse R-CNN 还应用集合预测损失,根据预定义的匹配成本利用二分匹配,为每个基本事实分配一个正查询。如上所述,稀疏查询集和重复查询是 Sparse R-CNN 的性能和收敛性的2个瓶颈。
2.2 Dense Queries
在前面描述了密集查询在很大程度上提高了召回率,同时也带来了不可接受的计算成本。在这项研究中,采用轻量级全卷积网络(RPN)以滑动窗口方式处理所有查询,由于 CNN 结构的参数共享特性,召回率大大提高,内存消耗大大减少。作为传统的 RPN 用于例如 Faster R-CNN 在召回率方面仍然滞后,并且由于其繁琐的Anchor设计和分配策略而存在泛化问题,作者提出了一种新的 RPN 结构,以使其更加高效和鲁棒。
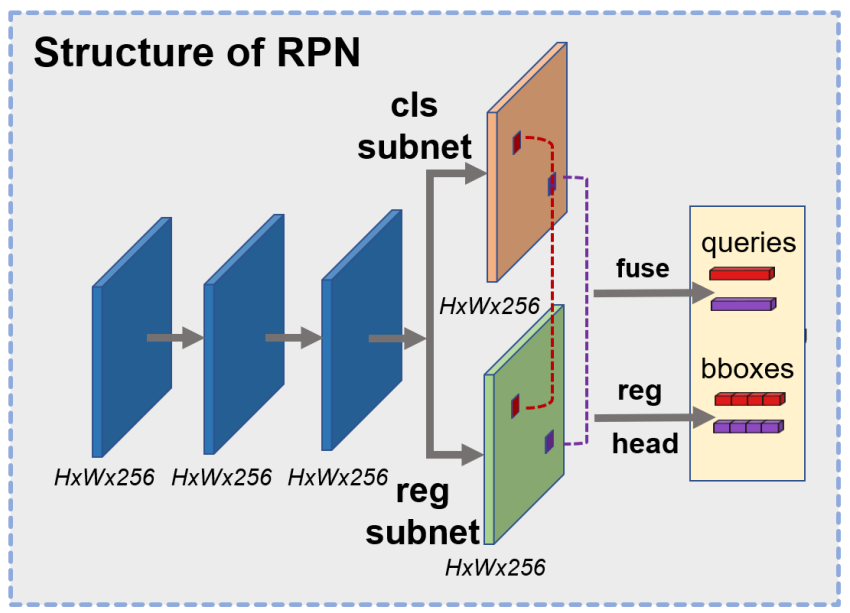
改进后的 RPN 结构如图3(b)所示。类似于 RetinaNet 等单阶段目标检测器,本研究中的 RPN 结构采用 P3 到 P7 特征,其中 表示从输入图像大小下采样 倍的特征图。它避免了在 Faster R-CNN 中使用 RPN 结构中的 P2 特征,以节省计算成本。
它有 3 个连续的 3×3 Conv-GN-ReLU 层作为共享Head结构,然后是一个 3×3 Conv-GN-ReLU 层的2个独立分支,用于分类和回归子任务。然后提取来自2个子网络的特征并将其连接以形成密集查询,从而将每个特征点视为一个查询。这样一来,查询的数量就变得更大了。例如,给定大小为 800 × 800 的图像,查询数达到 13343,这比 Sparse R-CNN 中的查询数大2个数量级,内存消耗仅略有增加。
改进后的 RPN 还丢弃了原始 RPN 中的 Anchor 设计和基于 IoU 的分配,并应用二分匹配算法来自适应地区分正负样本,以提高跨不同数据集的鲁棒性。值得注意的是,为了稳定训练,对二分匹配进行了轻微修改,仅从GT的中心特征点中选择正样本。具体而言,将每个level上最接近GT中心的top-K(本研究中的K=9)特征点视为潜在的正样本,如图3(b)所示。
2.3 Distinct Queries
首先要指出的是,在 Sparse R-CNN 等端到端训练方法中,非重复查询对于二分匹配的收敛非常重要。随着查询变得相似,训练更难以收敛。在存在2个相同查询的极端情况下,这是可以理解的。在这种情况下,二分匹配将前景标签分配给其中一个,而将背景标签分配给另一个。
不失一般性,采用二元交叉熵损失进行分类。因此,这2个查询的损失变为 ,其中 和 分别是正负查询的概率分数,并且满足 ,因为它们是相同的查询。相比之下,只有一个重复查询存在时的损失值是 。重复和非重复情况之间的正分数梯度的比率为α。
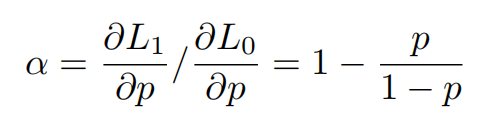
很明显,梯度在 0<p<0.5 时按比例缩小(α<1),甚至可能在 p>0.5 时导致负训练(α<0)。
1、Duplicate Query Removal
如示例所示,重复查询导致的梯度减小甚至负训练极大地抑制了收敛。因此,建议去除重复查询作为 Sparse R-CNN 中每个阶段的预处理,如图 3 所示。由于每个查询代表图像中的一个潜在实例,并且一个实例可以通过其在图像中的位置来唯一表示 ,自然而然地使用相应边界框的与类别无关的重叠率来检测相似查询。因此,在本研究中,重复删除是通过与类无关的非极大值抑制 (NMS) 来实现的。
需要注意的是,查询的预处理是为了减轻二分匹配的负担,这使得可以选择一个激进的IoU阈值(本文默认为0.7,性能在0.6到0.8变化时仅在0.3内波动) 在不同的数据集上是稳健的。这个预处理步骤保持了端到端检测器的优势,可以与检测定义保持一致。相比之下,传统的目标检测器在最终预测之后采用类感知 NMS 作为后处理,需要仔细调整 IoU 阈值。
2、Query Distinctness Enhancement
为了使查询特征更具判别力,使用提取的相应提议框的 RoI 特征来丰富它们。每个 RoI 特征首先平均池化到 1×1 的大小,然后与原始查询拼接,然后是一个恢复通道数的卷积层。由于与相应的查询相比,RoI 特征包含更多区分性的实例级信息,因此该组合进一步鼓励了不同查询之间的区别。然后将丰富的查询应用自注意力以推断相互关系,然后是动态Head模块以与 RoI 特征进行交互。这部分遵循 Sparse R-CNN 中的原始设计。
3、Light-weighted Iterative Refinement
与需要 6 个迭代查询细化阶段的 Sparse R-CNN 不同,DDQ 只需要 2 个细化阶段。实际上,Sparse R-CNN 中的长迭代阶段主要弥补了独立稀疏查询带来的缺点。一方面,初始稀疏查询的相应区域可能远离实例,因此需要长级联阶段来细化这些查询。另一方面,长细化还有助于区分相似查询以在每个位置输出 one-hot 预测。相比之下,来自 RPN 的密集查询和每个阶段之前的去重预处理解决了上述问题,因此可以在不降低性能的情况下显着减少迭代细化的次数。
2.4 其他改进
1、Quality Focal Loss
作者还遵循最近的一阶段方法采用 QFL,使边界框预测和 gt bboxes 之间的 IoU 作为分类目标。这种修改是为了更好地对齐每个查询的分类和回归子任务。置信度分数更好地反映了回归质量,因此有助于使用与类别无关的 NMS 进行重复删除过程。除了 QFL 分类,回归损失函数遵循 Sparse R-CNN 中的设计。
2、RoIAlign with Flexible Receptive Field
Sparse R-CNN 将每个查询限制为仅关注 RoIAligned 区域,这大大降低了计算开销,但带来了局部感受野。局部感受野使模型难以感知边界框的质量。

因此,设计了一个有效的 RoIAlign with Flexible Receptive Field (FRF),它结合了来自特征金字塔中相邻Level的额外 RoIAligned 特征,如图 3(d) 所示。在 FRF RoIAlign 的帮助下,每个查询都关注更广泛的特征,而无需像 AugFPN 那样引入繁重的计算。FRF 也是 QFL 的补充,因为 QFL 中分类和回归的对齐需要不同尺度的感受野来感知边界框的质量。
3实验
3.1 From Sparse R-CNN to DDQ
表 1 显示了本研究中从 Sparse R-CNN 到 DDQ 的逐步提升。使用 300 个查询的 Sparse R-CNN 使用标准的 1× 训练实现了 39.4 AP,这比使用 3× 训练时间和更重的增强低约 5.6 AP。训练时间短的性能显著下降已经暗示了 Sparse R-CNN 的收敛困难。
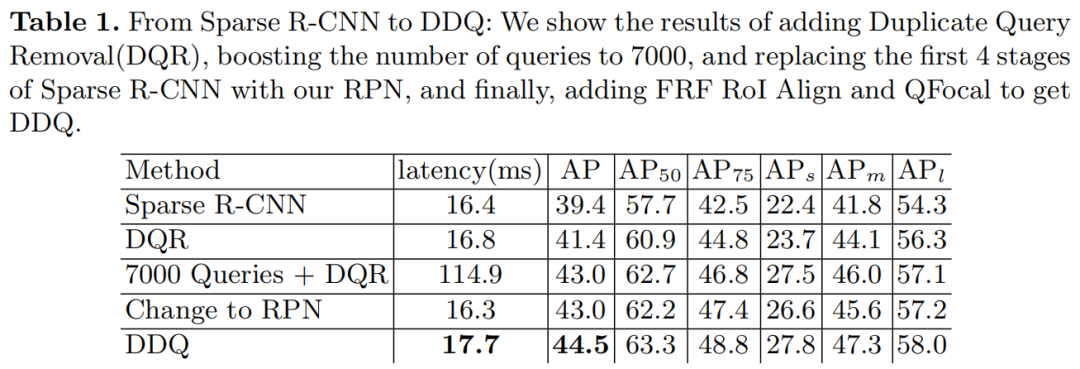
在每个阶段开始时对查询应用重复删除可将性能提高 2AP 至 41.4AP,而推理速度几乎没有牺牲。将查询数量进一步增加到 7000 也可以提高性能,但推理时间会很长。
用开发的 RPN 结构生成的特征替换独立查询并减少到 2 个细化阶段,保持使用 7000 个查询的性能,但在内存和推理时间上的成本显著降低。最后,DDQ 在延迟方面能够与 Sparse R-CNN 相媲美,但由于其他一些进一步的结构改进,例如 FRF RoIAlign 和 Query Distinctness Enhancement,它实现了 44.5 AP。这一性能领先于采用相同Backbone的最先进的目标检测器高 2个AP。巨大的改进证明了密集和不同查询作为设计目标检测器的指导原则的有效性。
请注意,
DDQ仅增加了Sparse R-CNN的边际推理延迟(17.7 ms vs 16.4 ms),这比其他竞争方法快得多。例如,Deformable DETR以 21.7 ms 的延迟实现 AP 43.8 AP,Cascade R-CNN以 19.4 ms 的延迟实现 40.3 AP。DDQ都比这些方法实现了更好的性能和更快的推理。
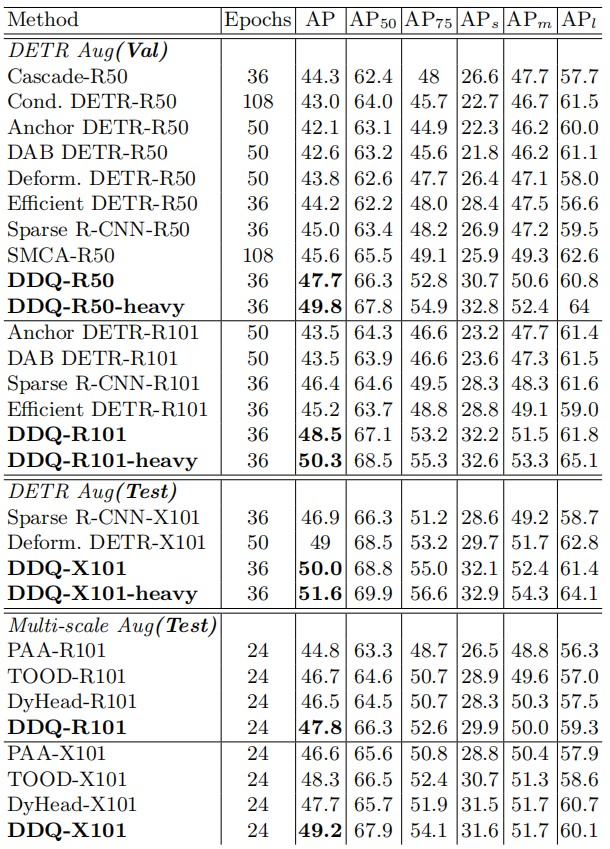
3.2 SOTA对比
4参考
[1].What Are Expected Queries in End-to-End Object Detection?
5推荐阅读
STDC升级 | STDC-MA 更轻更快更准,超越 STDC 与 BiSeNetv2
EfficientFormer | 苹果手机实时推理的Transformer模型,登顶轻量化Backbone之巅
LITv2来袭 | 使用HiLo Attention实现高精度、快速度的变形金刚,下游任务均实时
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题

声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!