AI算法与图像处理
AI算法与图像处理




来源:机器之心
作者:香港大学、腾讯ARC Lab
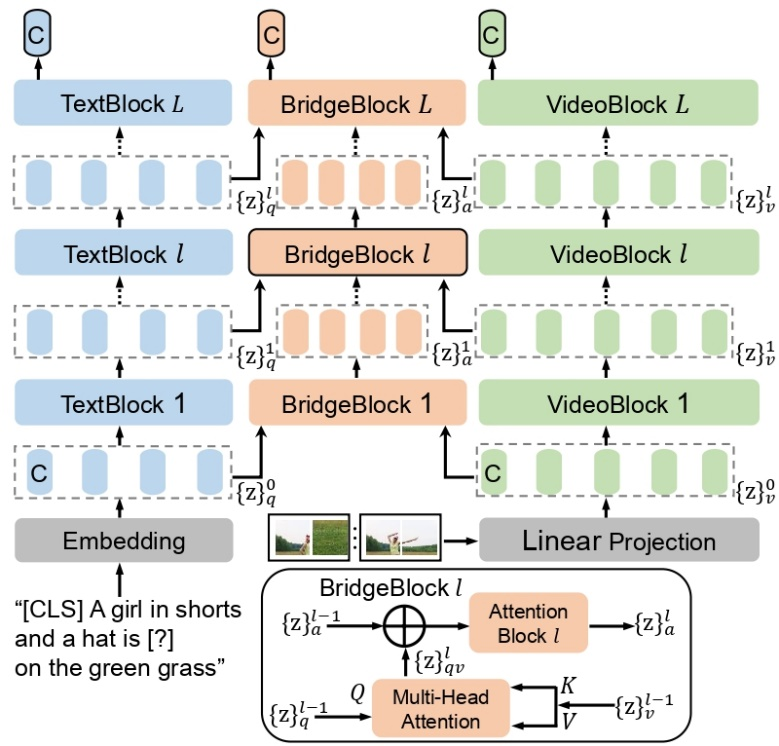
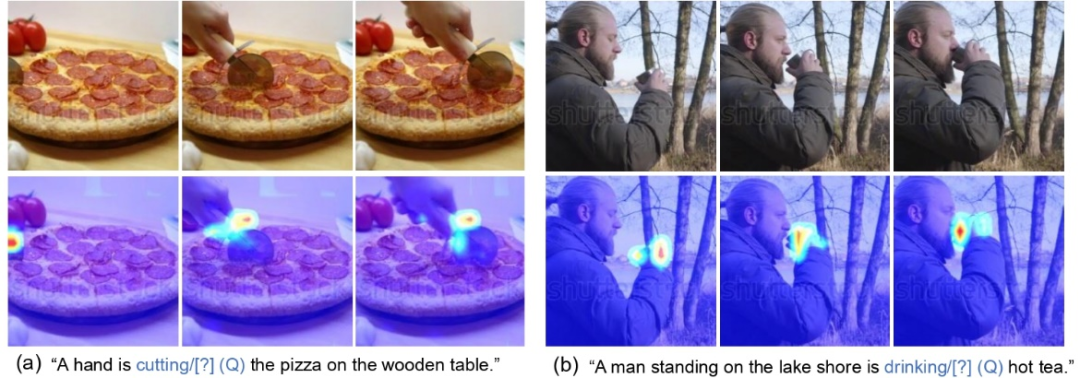
本文提出了一个全新的借口任务用于视频文本预训练,叫做多项选择题(MCQ)。通过训练辅助的BridgeFormer根据视频内容回答文本构成的选择题,来学习细粒度的视频和文本特征,并实现下游高效的检索。该研究已被 CVPR 2022 收录为 Oral。

论文地址:https://arxiv.org/abs/2201.04850
代码地址:https://github.com/TencentARC/MCQ
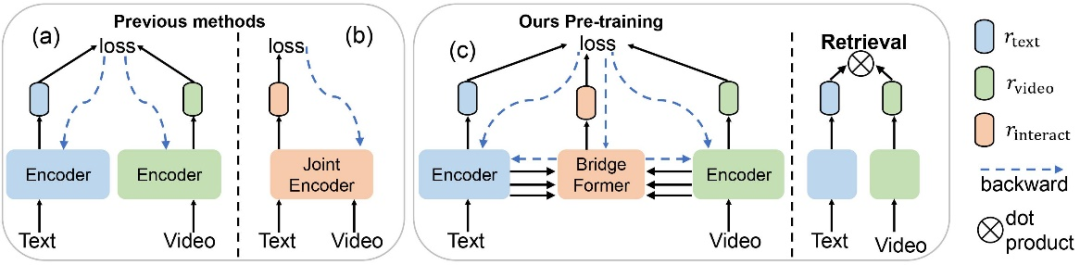
第一类 “双流” 法如下图(a)所示,训练两个单独的编码器来分别获取视频级别和语句级别的特征,利用对比学习(contrastive learning)来优化特征。这一方法可以实现高效的下游检索,因为在检索时只需要用点积来计算视频和文本特征的相似度。但这种方法因为仅仅约束两个模态的最终特征,忽略了每个模态自身的局部信息,以及视频和文本之间细粒度的关联。
第二类 “单流法” 如下图(b)所示,将视频和文本联结作为联合编码器的输入来进行模态间的融合,并训练一个分类器来判别视频和文本是否匹配。这一做法可以在局部的视频和文本特征之间建立关联,但是它在下游检索时非常低效,因为文本和每一个候选视频,都需要被联结送入模型来获取相似度。
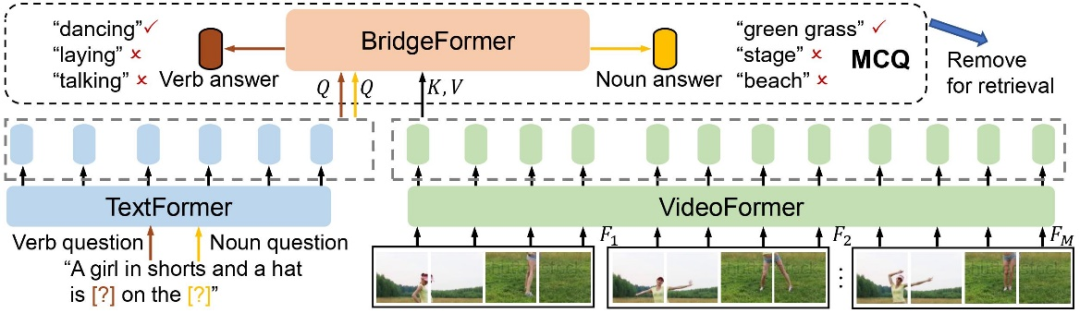
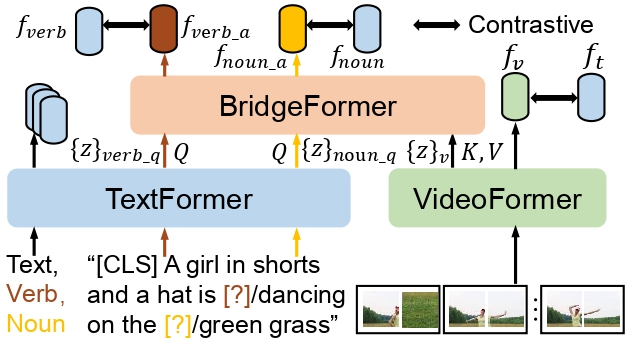
传统的 “masked word prediction” 约束模型预测出被 mask 的单词,会使得模型专注于解码 low-level 的单词本身,破坏了对模态间 high-level 的特征表达的学习。相比之下,该研究的 MCQ 以对比学习的形式拉近 BridgeFormer 输出的回答特征和 TextFormer 输出的答案特征间的距离,从而使模型专注于学习模态间 high-level 的语义信息。
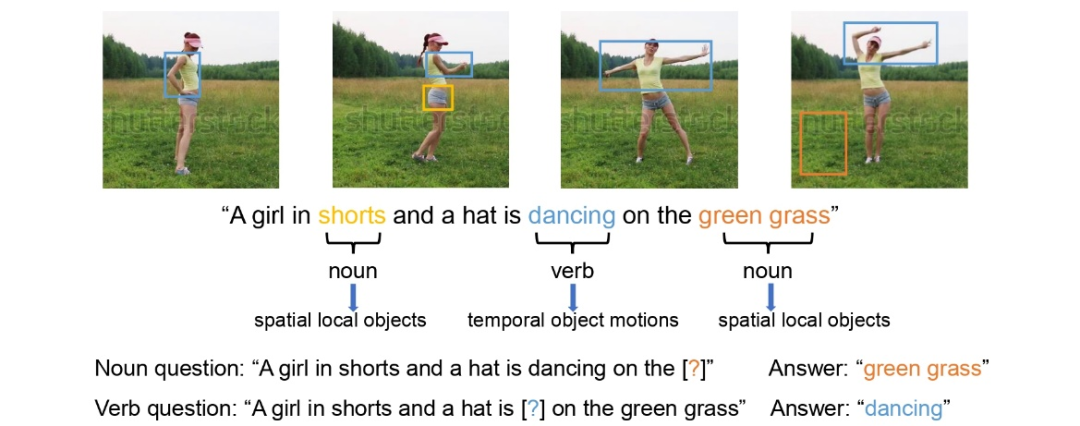
该研究抹除文本里包含明确语义信息的动词和名词短语来构造有意义的问题,而传统的方法只是随机 mask 一些可能没有任何语义信息的单词。
由于问题的特征和答案的特征都是由 TextFormer 得到,这一做法可以视为对文本的 data augmentation,从而增强 TextFormer 对自然语言的语义理解能力。
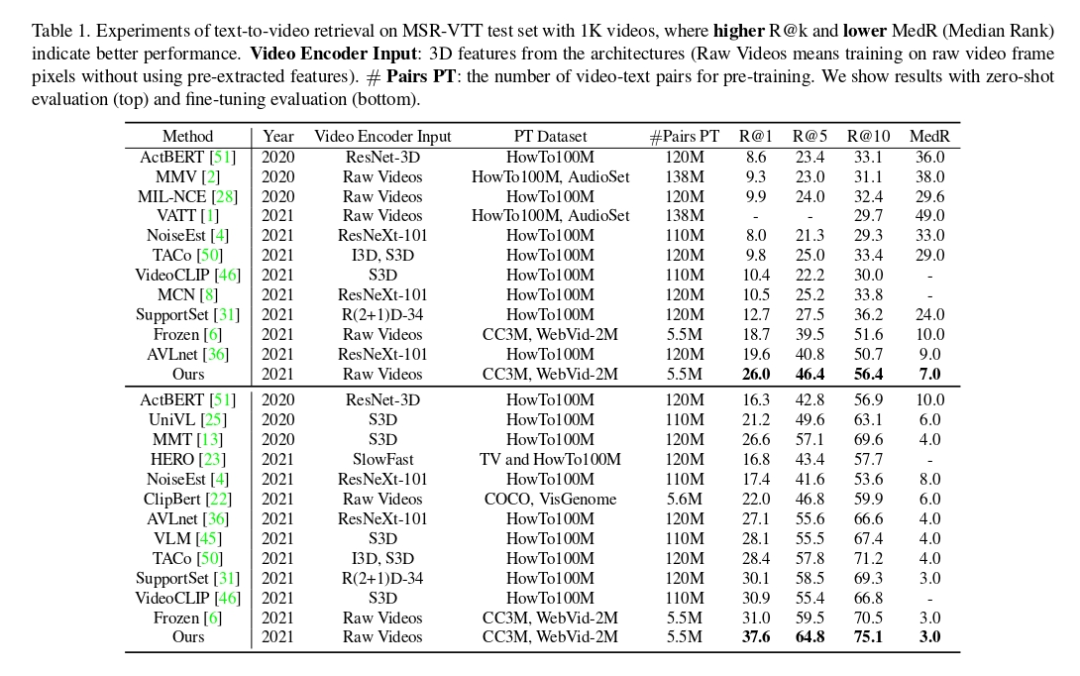
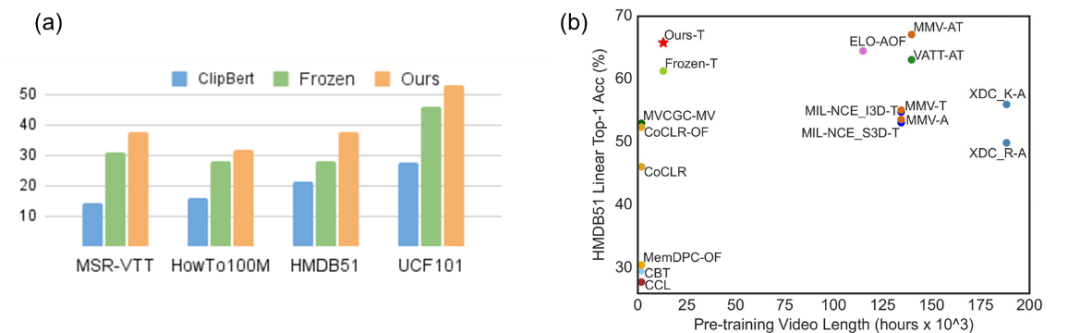
消融实验也显示,相比于传统的“masked word prediction”,该研究的对比学习形式的借口任务 MCQ 在下游测评取得了更好的实验结果。