
RocketMQ 消息消费流程
共 6187字,需浏览 13分钟
· 2022-05-30
记得点击 "欢少的成长之路", 设为星标⭐
后台点击【联系我】,申请加入优质技术学习社群

大家好,我是Leo。
今天聊一下RocketMQ消息消费,消费方式,消费模式,传送方式,过滤模式,负载均衡,重分配机制,消息拉取,并发消费与顺序消费
消息消费
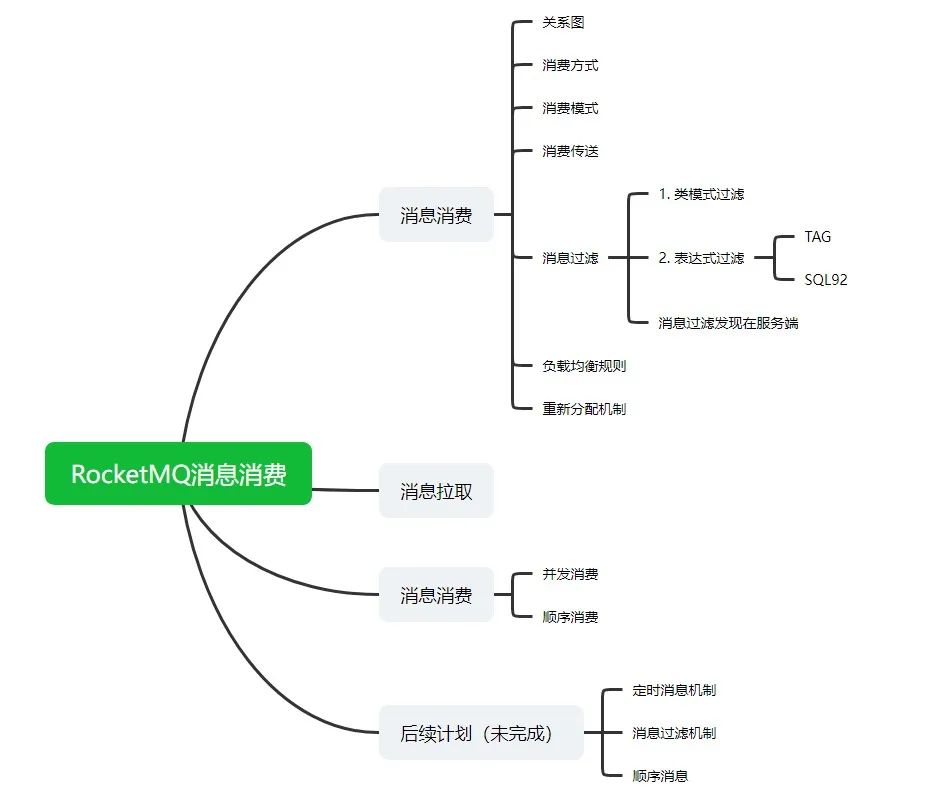
关系图
首先放一下Broker Cluster,Broker,Topic,Queue的关系图。因为下文主要会沿着这四块进行梳理
消费方式
消息消费主要有两种方式 并发消费 和 顺序消费。
并发消费,一个队列中的消息可同时被消费者的多个线程并发消费 顺序消费,一个队列中的消息同一时间只能被一个消费者的一个线程消费,通过这种方式达到顺序消费的效果
消费模式

源码
/**
* Message model
* 消息模式
*/
public enum MessageModel {
/**
* broadcast
* 广播
*/
BROADCASTING("BROADCASTING"),
/**
* clustering
* 集群
*/
CLUSTERING("CLUSTERING");
private String modeCN;
MessageModel(String modeCN) {
this.modeCN = modeCN;
}
public String getModeCN() {
return modeCN;
}
}
消费传送方式

消息过滤模式
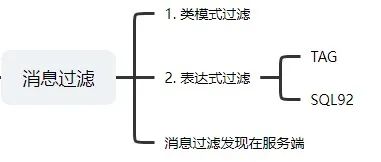
RocketMQ支持两种消息过滤模式
表达式(TAG、SQL92) 类过滤模式
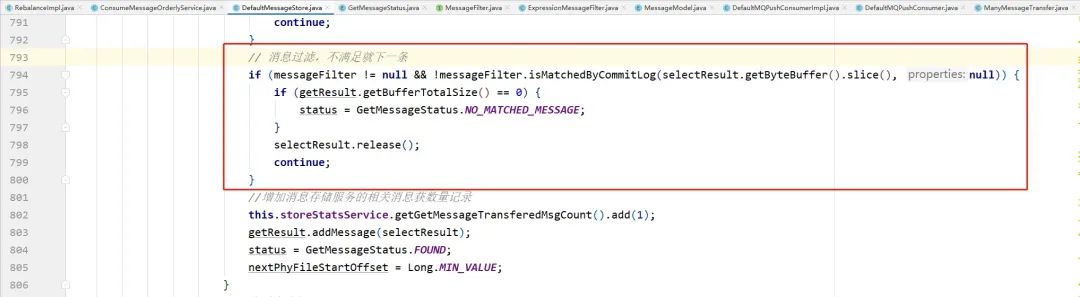
RocketMQ的消息过滤都是发生在 服务端 的,可以从下列代码得知。
负载均衡规则
RocketMQ提供了丰富的queue均衡规则 一共6种,目前只实现了四种
AllocateMessageQueueAveragely:默认均衡规则
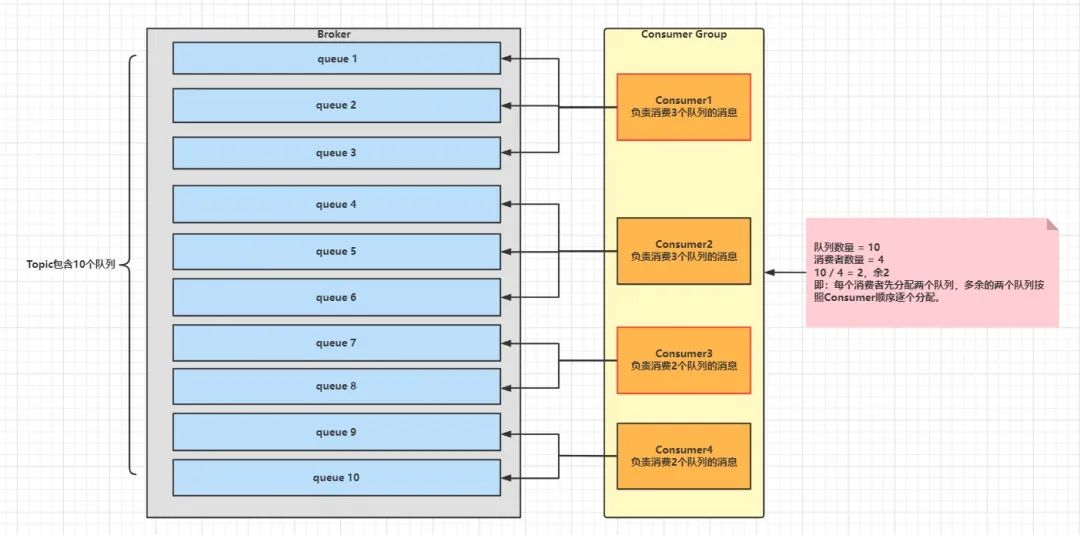
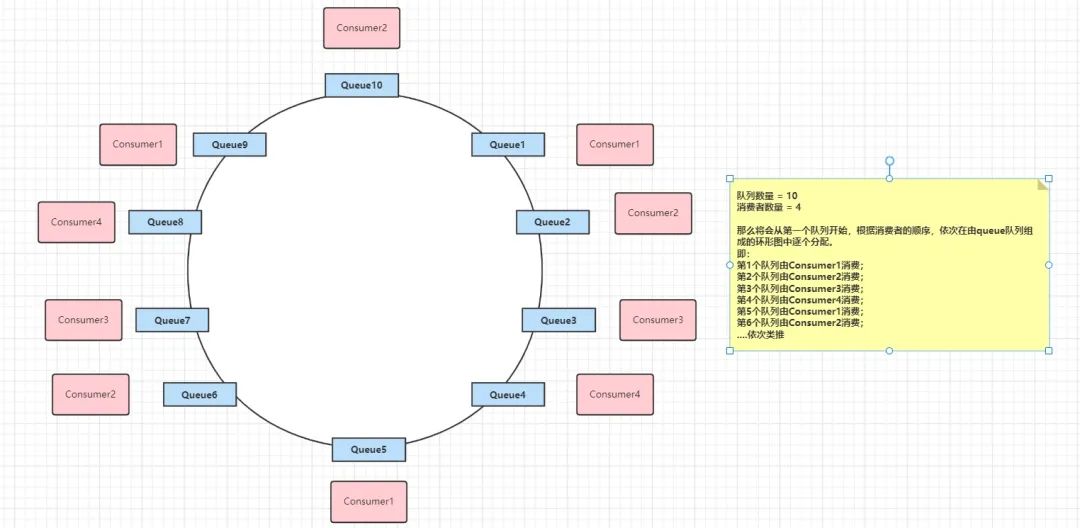
AllocateMessageQueueAveragelyByCircle:循环平均分配。是第1种方式的变种。针对queue数量多余Consumer数量的情况下,使用循环分配规则。如有3个Consumer、5个queue,则Consumer0消费queue0和queue3、Consumer1消费queue1和queue4、Consumer2消费queue2。
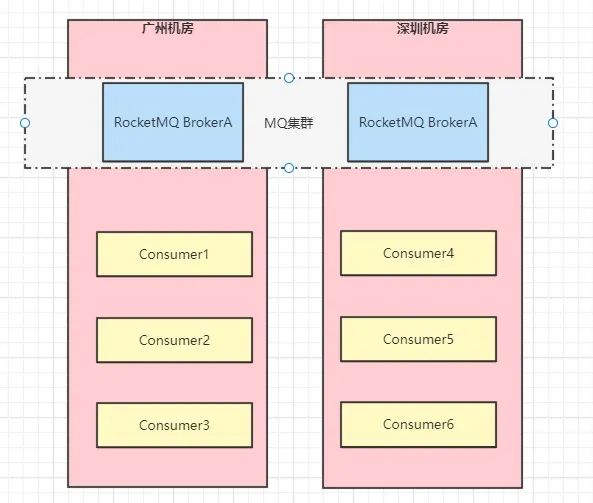
AllocateMessageQueueByMachineRoom:机房分配策略 。
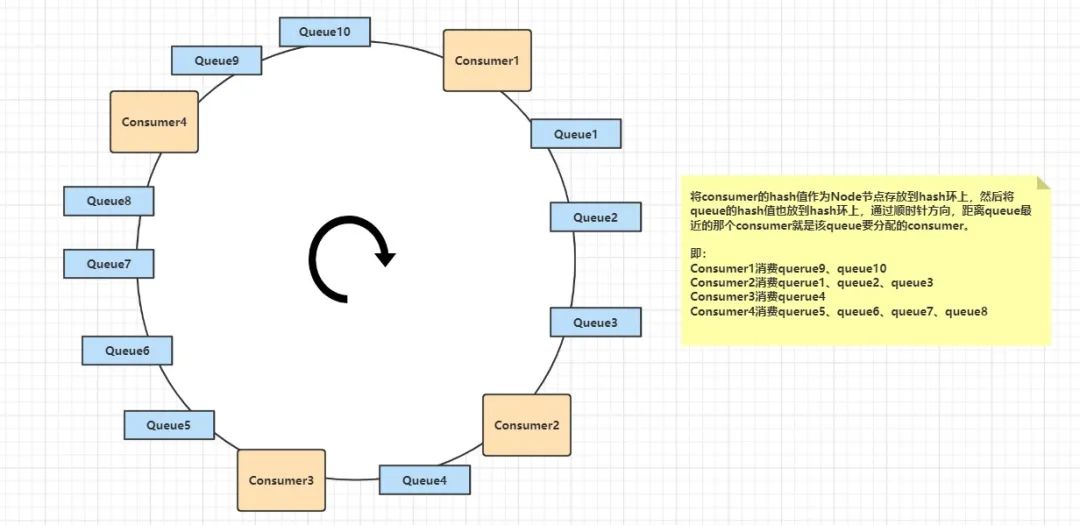
AllocateMessageQueueConsistentHash:一致性Hash方式分配。
AllocateMessageQueueByConfig:根据配置进行分配。未实现。
AllocateMachineRoomNearby:根据Consumer与Broker的距离远近进行分配,从源码看,该策略未完整实现。
重新分配机制
集群消费模式下,RocketMQ会把所有的messageQueue按一定的负载均衡策略分配给不同的消费者实例来消费。
也就是当负载均衡完成后,一个messageQueue只能被一个消费者实例消费,一个消费者实例可以消费一个或多个messageQueue,这取决于两者的数量,如图:
Rebalance的触发时机
消费者启动时主动进行一次Rebalance 消费者启动后设置定时进行Rebalance,20s/次 消费者组实例数量发生变化时,broker通知消费者进行Rebalance 所订阅的topic的messageQueue数量发生变化时、订阅关系变化时,broker通知消费者进行Rebalance
Rebalance的触发场景
消费者启动 消费者扩缩容 消费者宕机 broker扩缩容 messageQueue数量调整 网络问题导致客户端 broker连接断开
Rebalance带来的问题
消费暂停:只有一个Consumer时,该Consumer负责消费所有队列。若新增Consumer,则会触发Rebalance,原Consumer就需要暂停部分队列的消费。等到这些队列分配给新的Consumer,暂停的队列才能继续被消费。
重复消费:Consumer在消费新分配给自己的队列时,必须接着之前的Consumer提交的消费进度的offset继续消费。默认情况下,offset是异步提交的,就会导致提交到Broker的offset与Consumer实际消费的信息不一致。就可能导致重复消费。
消息突刺:由于Rebalance可能导致重复消费,如果重复消费的消息过多,或者因为Rebalance暂停时间过长而导致积压了部分消息。name有可能会导致在Rebalance结束后需要瞬间消费很多消息。
同步提交和异步提交
同步提交:consumer提交了其消费完毕的一批消息的offset给broker后,需要等待broker的成功ACK,收到ACK后,consumer才会继续获取并消费下一批消息。在等待ACK期间,consumer是阻塞的。 异步提交:consumer提交了消费完毕的一批消息的offset后,不需要等待不容二科的成功ack,consumer可以直接获取并消费下一批消息 对于一次读取消息的数量,需要根据具体业务场景选择一个相对均衡是很有必要的。数量过的大,产生重复的消息可能会增加。数量过小,系统性能会下降。
队列分配流程
获取指定 Topic 下的消息队列集合 如果是广播模式,则不需要进行负载均衡,消费者直接负责所有消息队列 集群模式则需要获取指定 Topic 的所有消费者集合,根据负载均衡算法将消息队列分配给消费者 消息队列分配完毕后,则需要为每个消息队列创建对应的任务队列,即 ProcessQueue 为每个任务队列创建对应的消息拉取任务,后续消息拉取服务会定时扫描任务池进行消息拉取操作
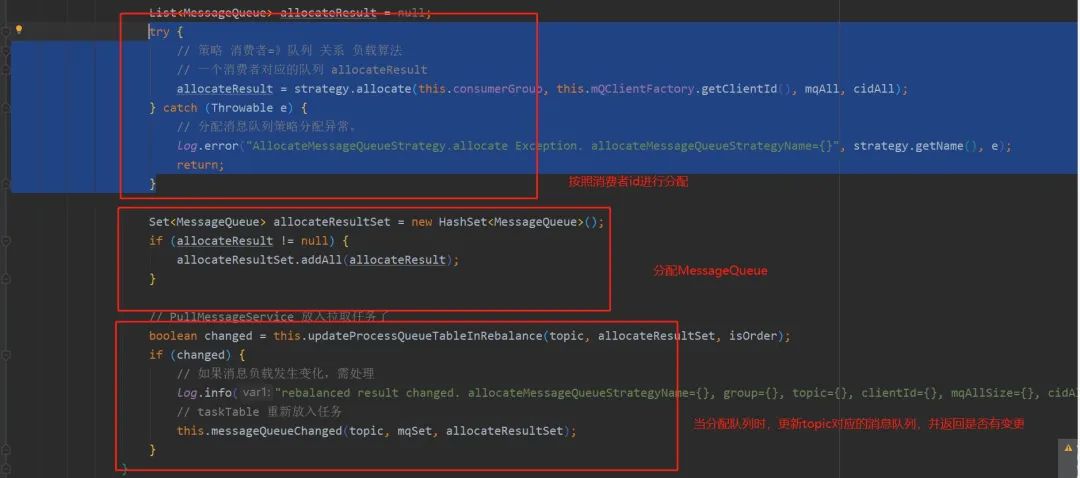
队列分配目的在于指定消费者负责的队列集合,分配前需要明确几点:
该 Topic 存在多少队列 该 Topic 存在多少消费者 队列如何分配给消费者,即负载均衡算法(默认是平均分配的算法)
消息拉取
消息拉取流程
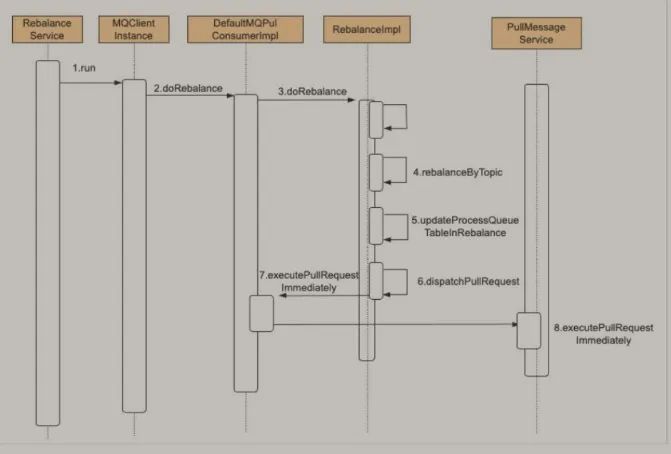
RocketMQ的消息拉取 由 PullMessageService处理。
消费者启动后,因集成了ServiceThread,ServiceThread又实现了 Runnable接口。他首先会启动run线程。每执行一次业务逻辑检测一下其运行状态,可以通过其他线程将stopped设置为true从而停止该线程。 pullRequestQueue是一个阻塞队列,只会在有消息之后,才会去拉取,拉取最顶部的对象,其他对象一并移出。拿到 PullRequest之后,根据拉取请求的消费组反查该消费者的拉取规则。拿到了拉取规则后通过 pullMessage函数获取processQueue队列消费快照,并且检查是否被dropped,修改最后拉取时间,检查服务是否正常,消费者是否暂停等执行流控,判断缓存消息数量是否超过阈值,缓存消息大小是否超过阈值,缓存消息跨度是否超过阈值 获取 processQueue锁,判断broker是否上锁,上了就拉,没上就等待。通过 pullRequest 的 messageQueue计算拉取偏移量,判断当前偏移量是否小于拉请求的下一个坐标,如果偏移量大于拉请求的下标就代表broker繁忙。对之前加锁并且初始化拉请求的最新下标再根据拉请求中的消息队列,取消息队列中的主题信息,根据 RebalanceImpl实现类并且按照用户的负载均衡规则去查询订阅数据。在 PullCallback回调中,根据状态进行相应的处理(状态可以从下方代码中查看 PullStatus)构建消息拉取系统标记(标记可以从下方代码中查看PullSysFlag) 最后调用PullAPIWrapper.pullKernelImpl方法后与服务端交互
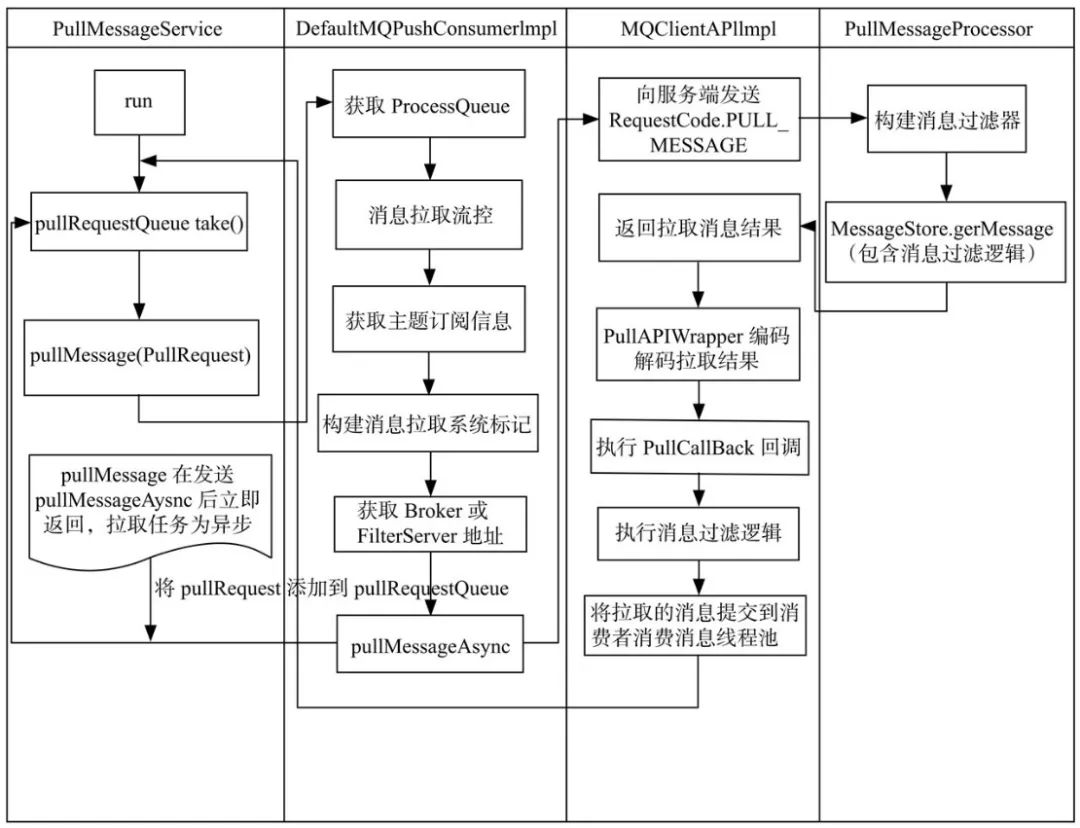
PullRequestQueue:阻塞队列,存放的是拉请求 PullRequest
ProcessQueue:消费进度,消息总数量等一些核心的数据都在这里
PullRequest:拉请求,封装了消费者,消息队列,队列消费快照,下一个下标,以前锁定等
第八步中 如果为空,结束本次消息拉取,关于该队列的下一次拉取任务延迟3s。
消息拉取回调
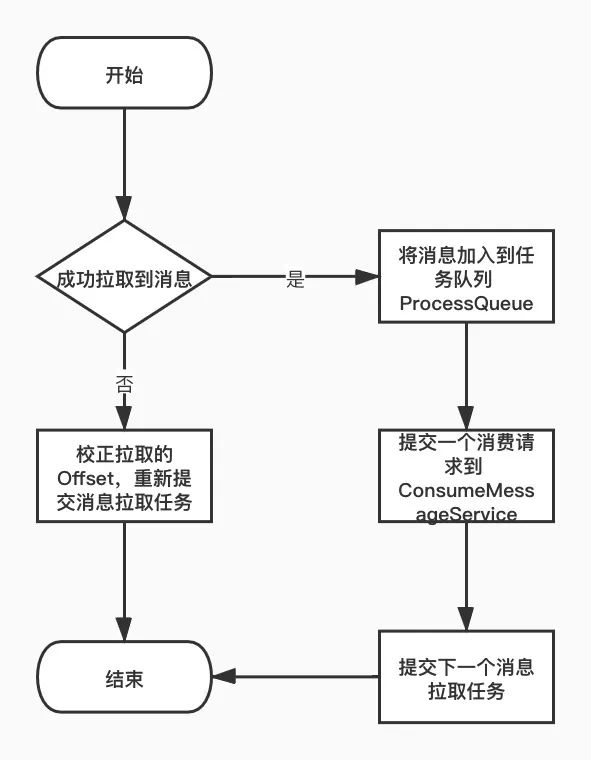
消息拉取完毕的后续处理逻辑:
如果成功拉取到消息,则将消息加入到待处理任务队列 ProcessQueue,并提交一个消费请求给 ConsumeMessageService,提交下一次消息拉取任务 如果没有成功拉取到消息,则根据服务端返回的 Offset 进行校正处理,重新提交消息拉取任务
PullRequest
在RocketMQ根据PullRequest拉取任务执行完一次消息拉取任务后,又将PullRequest对象放入到pullRequestQueue 在RebalancceImpl中创建。RebalanceImpl就是消息队列负载机制,也就是PullRequest对象真正创建的地方
ProcessQueue
ProcessQueue是MessageQueue在消费端的重现、快照。PullMessageService从消息服务器默认每次拉取32条消息,按消息的队列偏移量顺序存放在ProcessQueue中,PullMessageService然后将消息提交到消费者消费线程池,消息成功消费后从ProcessQueue中移除
pullKernelImpl
下列参数详解
MessageQueue mq:从哪个消息消费队列拉取消息。 String subExpression:消息过滤表达式。 String expressionType:消息表达式类型,分为TAG、SQL92。 long offset:消息拉取偏移量。 int maxNums:本次拉取最大消息条数,默认32条。 int sysFlag:拉取系统标记。 long commitOffset:当前MessageQueue的消费进度(内存中)。 long brokerSuspendMaxTimeMillis:消息拉取过程中允许Broker挂起时间,默认15s。 long timeoutMillis:消息拉取超时时间。 CommunicationMode communicationMode:消息拉取模式,默认为异步拉取。 PullCallback pullCallback:从Broker拉取到消息后的回调方法。
执行流程如下
根据brokerName、BrokerId从MQClientInstance中获取Broker地址, 如果消息过滤模式为类过滤,则需要根据主题名称、broker地址找到注册在Broker上的FilterServer地址,从FilterServer上拉取消息,否则从Broker上拉取消息。 通过MQClientAPIImpl#pullMessageAsync方法异步向Broker拉取消息。
在整个RocketMQ Broker的部署结构中,相同名称的Broker构成主从结构,其BrokerId会不一样,在每次拉取消息后,会给出一个建议,下次拉取从主节点还是从节点拉取
源码
// PullMessageService 启动后的 run 函数
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
//使用BlockingQueue阻塞队列,当提交了消息拉取请求后,马上执行
// take 移除所有队列,返回最顶部 队列中的对象(拉请求)
PullRequest pullRequest = this.pullRequestQueue.take();
this.pullMessage(pullRequest);
} catch (InterruptedException ignored) {
} catch (Exception e) {
log.error("Pull Message Service Run Method exception", e);
}
}
log.info(this.getServiceName() + " service end");
}
// stopped 为true的函数
public void shutdown(final boolean interrupt) {
log.info("Try to shutdown service thread:{} started:{} lastThread:{}", getServiceName(), started.get(), thread);
if (!started.compareAndSet(true, false)) {
return;
}
this.stopped = true;
log.info("shutdown thread " + this.getServiceName() + " interrupt " + interrupt);
if (hasNotified.compareAndSet(false, true)) {
// 此函数将递减(减一)锁存器的计数,如果计数到达零,则释放所有等待的线程
waitPoint.countDown(); // notify
}
}
/**
* 拉取状态
*/
public enum PullStatus {
/**
* Founded
* 建立
*/
FOUND,
/**
* No new message can be pull
* 无法拉取任何新消息
*/
NO_NEW_MSG,
/**
* Filtering results can not match
* 过滤结果不匹配
*/
NO_MATCHED_MSG,
/**
* Illegal offset,may be too big or too small
* 非法偏移,可能太大或太小
*/
OFFSET_ILLEGAL
}
/**
* 消息拉取系统标记
*/
public class PullSysFlag {
/**
* 表示从内存中读取的消费进度大于0,则设置该标记位。
*/
private final static int FLAG_COMMIT_OFFSET = 0x1;
/**
* 表示消息拉取时支持挂起。
*/
private final static int FLAG_SUSPEND = 0x1 << 1;
/**
* 消息过滤机制为表达式,则设置该标记位。
*/
private final static int FLAG_SUBSCRIPTION = 0x1 << 2;
/**
* 消息过滤机制为类过滤模式
*/
private final static int FLAG_CLASS_FILTER = 0x1 << 3;
private final static int FLAG_LITE_PULL_MESSAGE = 0x1 << 4;
}
消息消费
消息消费的大概流程
消息生产者把消息发送并存储到 Rocket MQ 的 broker 上,NameServer 用来发现和更新 broker。 消费者启动时会启动 PullMessageService 线程,PullMessageService 线程不断地从内部的队列中取 PullRequest,然后使用 PullRequest 作为请求去拉取消息。 PullRequest 中的消息处理队列 ProcessQueue 是 MessageQueue 在消费端的重现、快照。PullMessageService 使用消费者(DefaultMQPushConsumerImpl)从消息服务器默认每次拉取 32 条消息,按消息的队列偏移量存放在 ProcessQueue 中,然后消费者再将消息提交到消息消费线程池中(提交 ConsumeRequest),消息成功消费后从 ProcessQueue 中移除。
第二步中
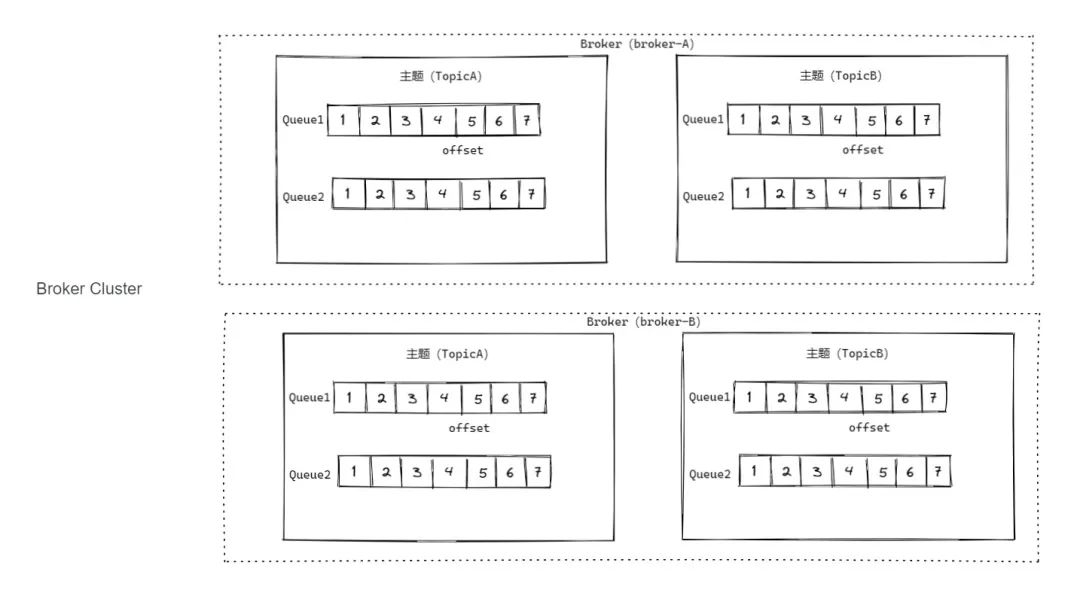
拿到消费请求后,消费请求里面肯定带着topic ,queueId, offset,取多少个这四个重要信息,然后获取到对应topic对应queueId的consumeQueue,然后定位到offset位置处,往下取出你要个数的信息。这里举个例子,比如说有一个topic是xxx,然后有2个queue,这个时候我们消息消费者 发起消费请求,要消费topic是xxx,queueId是0 ,然后offset =3开始拉取,拉取大小maxMsgNums=2,就是下图这个样子
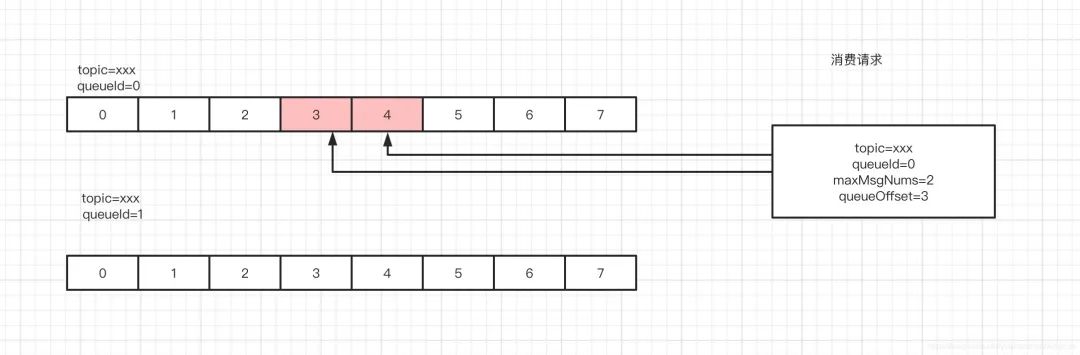
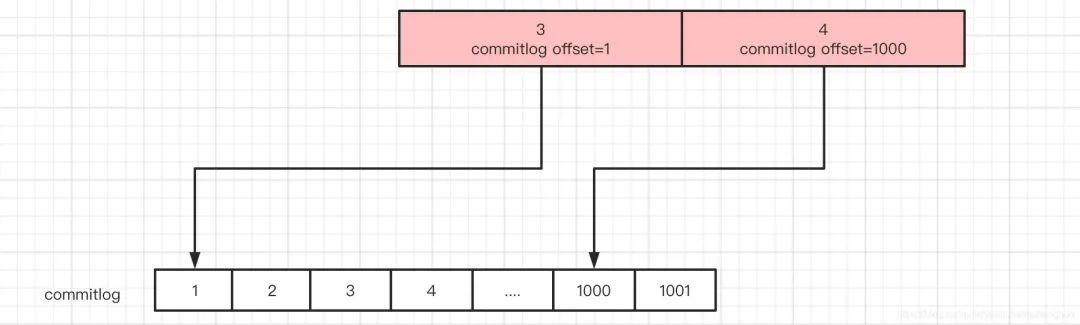
接着获取到3,4这两个之后,遍历,根据它们里面的commitlog offset 再去commitlog获取到对应真实的消息。
消息拉取完之后,会提交一个消费任务给 ConsumeMessageService 进行处理。ConsumeMessageService 有两个实现类:
并发处理,对应实现类为 ConsumeMessageConcurrentlyService 顺序处理,对应实现类为 ConsumeMessageOrderlyService
并发消费
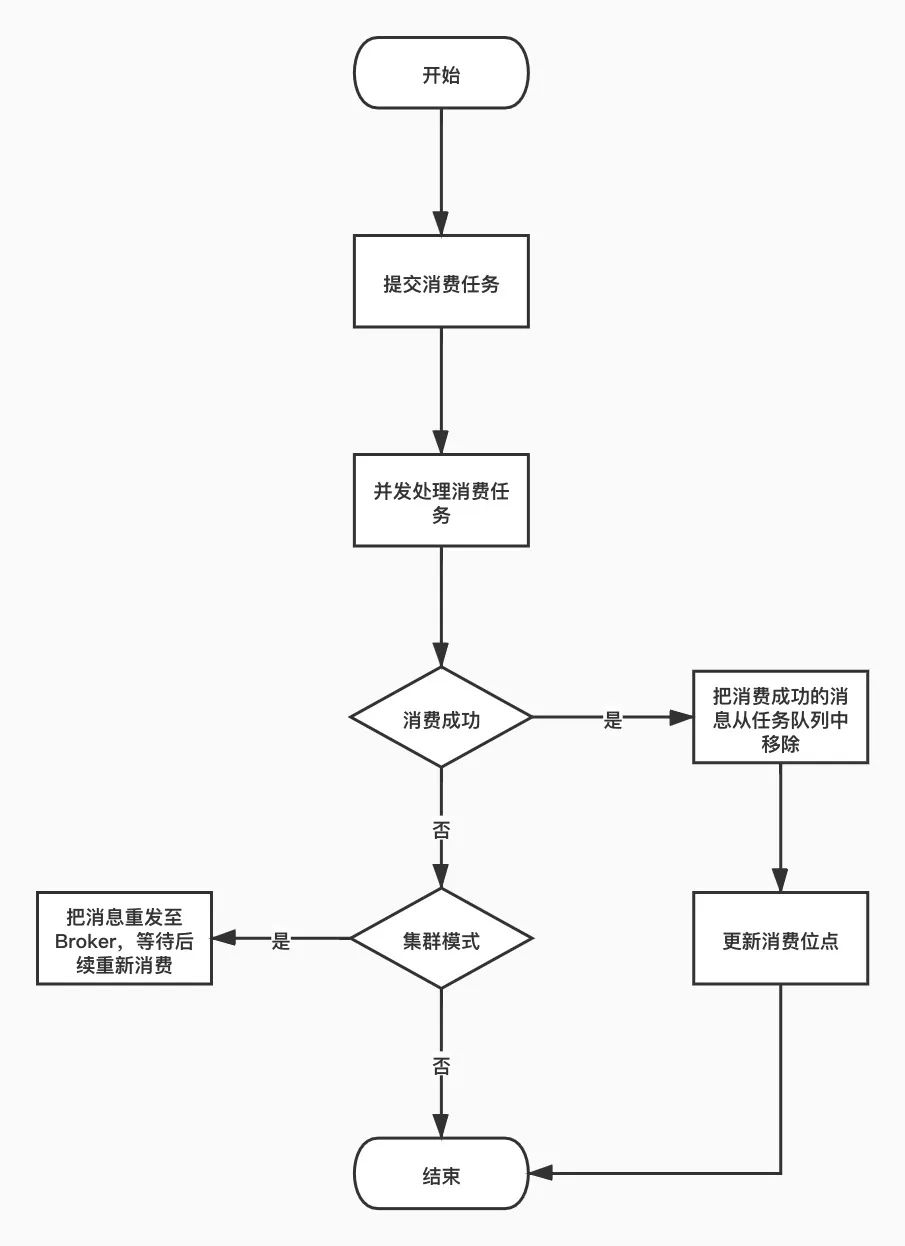
并发消费的主要方法是 submitConsumeRequest 逻辑如下
consumeMessageBatchMaxSize,消息批次,在这里看来也就是一次消息消费任务ConsumeRequest中包含的消息条数,默认为1, msgs.size()默认最多为32条,受DefaultMQPushConsumer.pullBatchSize属性控制,如果msgs.size()小于consume Message-BatchMaxSize,则直接将拉取到的消息放入到ConsumeRequest中,然后将consumeRequest提交到消息消费者线程池中,如果提交过程中出现拒绝提交异常则延迟5s再提交,这里其实是给出一种标准的拒绝提交实现方式,实际过程中由于消费者线程池使用的任务队列为LinkedBlockingQueue无界队列,故不会出现拒绝提交异常。 如果拉取的消息条数大于consumeMessageBatchMaxSize,则对拉取消息进行分页,每页consumeMessageBatchMaxSize条消息,创建多个ConsumeRequest任务并提交到消费线程池。ConsumeRequest的run方法封装了具体消息消费逻辑。
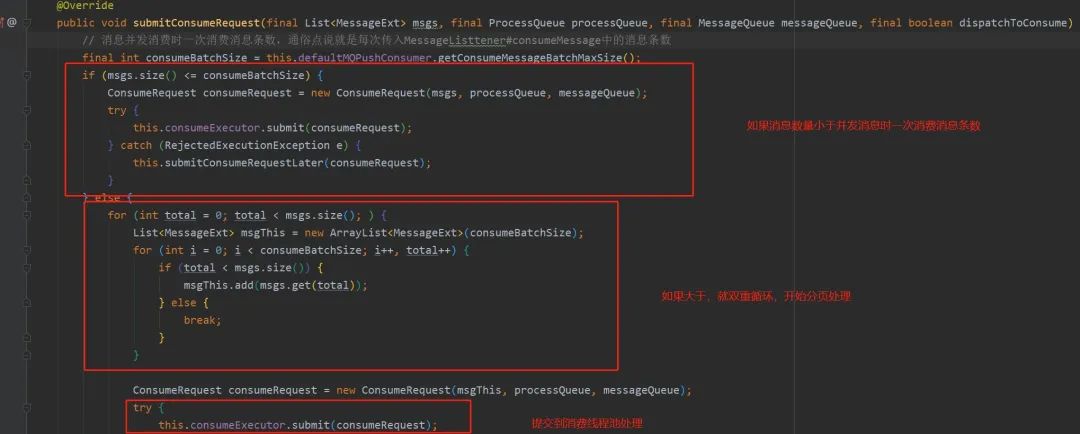
进入具体消息消费时会先检查processQueue的dropped,如果设置为true,则停止该队列的消费,在进行消息重新负载时如果该消息队列被分配给消费组内其他消费者后,需要droped设置为true,阻止消费者继续消费不属于自己的消息队列。 执行消息消费钩子函数ConsumeMessageHook#consumeMessageBefore函数,通过consumer.getDefaultMQPushConsumerImpl().registerConsumeMessageHook(hook),方法消息消费执行钩子函数。 恢复重试消息主题名。这是为什么呢?这是由消息重试机制决定的,RocketMQ将消息存入commitlog文件时,如果发现消息的延时级别delayTimeLevel大于0,会首先将重试主题存入在消息的属性中,然后设置主题名称为SCHEDULE_TOPIC,以便时间到后重新参与消息消费。 执行具体的消息消费,调用应用程序消息监听器的consumeMessage方法,进入到具体的消息消费业务逻辑,返回该批消息的消费结果。最终将返回CONSUME_SUCCESS(消费成功)或RECONSUME_LATER(需要重新消费)。 执行消息消费钩子函数ConsumeMessageHook#consumeMessageAfter函数 执行业务消息消费后,在处理结果前再次验证一下ProcessQueue的isDroped状态值,如果设置为true,将不对结果进行处理,也就是说如果在消息消费过程中进入到第四步时,如果由于由新的消费者加入或原先的消费者出现宕机导致原先分给消费者的队列在负载之后分配给别的消费者,那么在应用程序的角度来看的话,消息会被重复消费。 根据消息监听器返回的结果,计算ackIndex,如果返回CONSUME_SUCCESS, ackIndex设置为msgs.size() - 1,如果返回RECONSUME_LATER, ackIndex=-1,这是为下文发送msg back(ACK)消息做准备的。 如果是集群模式,业务方返回RECONSUME_LATER,消息并不会重新被消费,只是以警告级别输出到日志文件。如果是集群模式,消息消费成功,由于ackIndex=consumeRequest.getMsgs().size()-1,故i=ackIndex+1等于consumeRequest.getMsgs().size(),并不会执行sendMessageBack。只有在业务方返回RECONSUME_LATER时,该批消息都需要发ACK消息,如果消息发送ACK失败,则直接将本批ACK消费发送失败的消息再次封装为ConsumeRequest,然后延迟5s后重新消费。如果ACK消息发送成功,则该消息会延迟消费。 从ProcessQueue中移除这批消息,这里返回的偏移量是移除该批消息后最小的偏移量,然后用该偏移量更新消息消费进度,以便在消费者重启后能从上一次的消费进度开始消费,避免消息重复消费。值得重点注意的是当消息监听器返回RECONSUME_LATER,消息消费进度也会向前推进,用ProcessQueue中最小的队列偏移量调用消息消费进度存储器OffsetStore更新消费进度,这是因为当返回RECONSUME_LATER, RocketMQ会创建一条与原先消息属性相同的消息,拥有一个唯一的新msgId,并存储原消息ID,该消息会存入到commitlog文件中,与原先的消息没有任何关联,那该消息当然也会进入到ConsuemeQueue队列中,将拥有一个全新的队列偏移量。
在段落最后,会附上消费成功后提交消费进度的过程,重置消费进度的过程
顺序消费
RocketMQ 实现顺序消费的思路比较简单,在默认的情况下消息发送会采取Round Robin轮询方式把消息发送到不同的queue(分区队列);而消费消息的时候从多个queue上拉取消息,这种情况发送和消费是不能保证顺序。但是如果控制发送的顺序消息只依次发送到同一个queue中,消费的时候只从这个queue上依次拉取,则就保证了顺序。当发送和消费参与的queue只有一个,则是全局有序;如果多个queue参与,则为分区有序,即相对每个queue,消息都是有序的。
下面列举两种无法保证顺序消费的场景:
消费者A正在消费队列A的消息,此时消费者B发生了队列的负载均衡,也分配到了队列A,在同一时间相当于有两个消费者可以同时消费一个队列的消息 当前队列A由一个消费者A负责,但消费者A内部可以进行并发消费,即多个消费线程同时消费队列A的消息
因此还需要结合锁的机制来实现顺序消费:
同一时间一个队列只能分配给一个消费者,通过给 Broker 端队列上锁实现 同一时间一个队列只能有一个消费线程进行消费,通过给本地队列上锁实现
在队列负载均衡阶段,如果是顺序消费,会向 Broker 发起队列加锁请求,如果加锁成功则创建对应的任务队列及消息拉取请求,反之不创建。
ConsumeMessageOrderlyService 在启动后会定时向 Broker 发送队列加锁的请求,目的是续期锁。
具体的加锁操作如下:
获取消费者负责的消息队列集合 HashMap 依次对每个 Broker 下的消息队列进行加锁操作,Broker 会响应加锁成功的消息队列集合 如果消息队列加锁成功,则将本地对应的任务队列设置为加锁成功的状态;反之则设置成加锁失败状态
消费的过程中则通过对本地队列加锁来实现同一时间一个队列只能有一个消费线程进行消费。
看到消费任务 ConsumeRequest 的定义, 它是 ConsumeMessageOrderlyService 的内部类,不同于之前并发消费的任务,可以看到主要区别在于消费时增加了本地队列的加锁操作,以及锁状态的校验。
顺序消费时如果消费失败,会直接将消息放回任务队列中等待重新消费,且重试次数默认是 Integer.MAX_VALUE
提交进度
消费成功后提交消费进度的过程
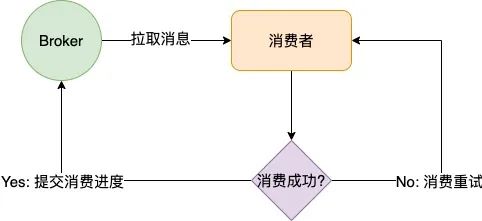
重置消费进度的过程
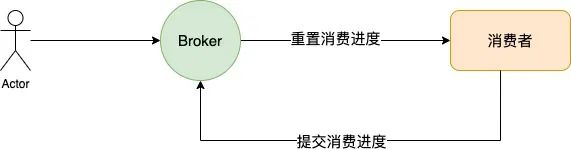
二者共同点:
• 都是由Broker统一管理消费者的消费进度
• 都需要由消费者“主动上报”最新的消费进度
二者的差异点:
• 正常消费时提交消费进度,一般消费进度是向前推进
• 重置消费进度时提交消费进度,消费进度可能向前推进,也可能向后回溯
往期推荐
Redis事务机制ACID的实现,Redis主从同步的实战细节问题
缓存预热,Redis单线程为什么那么快,过期策略,过期机制,缓存一致性
Redis数据结构,rehash,渐进式rehash,AOF,RDB实现原理
为什么需要消息队列?应用场景?MQ的技术选型分析?主题和队列的实现原理与流程
结尾
非常欢迎大家加我个人微信有关后端方面的问题我们在群内一起讨论! 我们下期再见!
分析不对的地方,还请指出一起修补
负载均衡规则部分图片参考博主:CSDN每天都要进步一点点
资料参考:RocketMQ官方源码,《RocketMQ技术内幕》
欢迎『点赞』、『在看』、『转发』三连支持一下,下次见~