 腾讯云数据库
腾讯云数据库




万字长文,详细讲述PCG功能开发一组如何优化改造QQ小世界Feed云系统及腾讯MongoDB团队如何对小世界MongoDB集群进行性能优化,对比看看您的小世界是否面临同样的问题呢,建议收藏学习!
本文结构速览奉上:
一、业务背景
二、小世界Feed云系统面临的问题及挑战
2.1 老Feed系统主要问题
2.2 新场景下Feed云的问题
三、数据库存储选型
四、小世界Feed云系统改造及优化过程
4.1 Feed云优化改造及成果收益
4.1.1 Feed云优化改造-UFO
4.1.2 Feed云优化改造-更新中心被动加速
4.1.3 Feed云优化改造-成果收益
4.2 Feed云多地容灾及成果收益
4.2.1 Feed云多地容灾-方案思考
4.2.2 多地容灾-三地容灾方案
4.2.3 多地容灾-三地同步加速
4.2.4 多地容灾-通用可重入机制
4.2.5 多地容灾-成果收益
4.3 应对高增长
4.3.1 应对高增长-应对突增流量的方法论
4.3.2 应对高增长-具体策略
五、 小世界MongoDB业务用法及内核性能优化
5.1 MongoDB表设计
5.1.1 Feed表及索引设计
5.1.2 评论回复表及索引设计
5.2 片建选择及分片方式
5.3 低峰期滑动窗口设置
5.4 MongoDB内核优化
5.5 MongoDB集群监控信息统计
业务背景
QQ小世界最主要的四个Feed场景有:基于推荐流的广场页、个人主页,被动消息列表以及基于关注流的关注页。
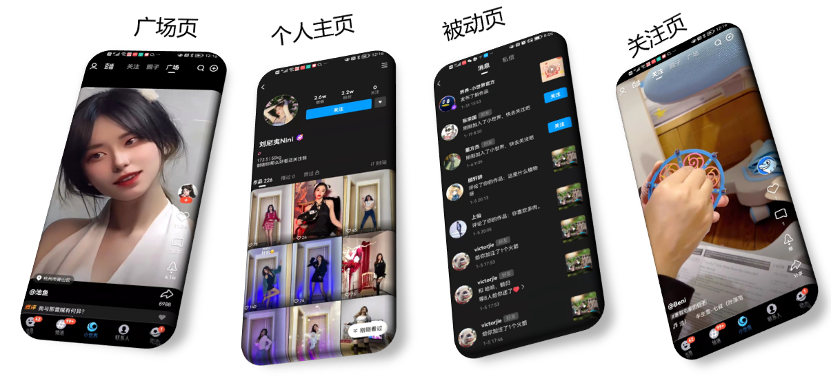
图:QQ小世界Feed场景
最新feed云架构由老Feed云重构而来,老Feed云存在如下问题:
性能问题
老系统读写性能差,团队通过调研测试确认MongoDB读写性能更好,并且支持更多查询功能。同时,老系统无法像MongoDB一样支持字段过滤(feed权限过滤等),字段排序(个人主页赞排序等),事务等。
数据一致性问题
老系统采用了ckv+tssd为tlist做一层缓存,系统依赖多款存储服务,容易形成数据不一致的问题。
同步组件维护性问题
老系统采用同步中心组件作为服务间的连接桥梁,同步中心组件缺失运维维护,因此采用kafka作为中间件作为异步处理。
存储组件维护成本高
老系统Feed底层tlist、tssd扩容、监控信息等服务能力相对不足。
服务冗余问题
老系统设计不合理,评论、回复、赞、转等互动服务冗杂在Feed服务中,缺乏功能拆分,存在服务过滤逻辑冗杂,协议设计不规范等问题。
MongoDB优势
除了读写性能,通过调研及测试确认MongoDB拥有高性能、低时延、分布式、高压缩比、天然高可用、多种读写分离访问策略、快速DDL操作等优势,可以方便QQ系统业务快速迭代开发。
新的Feed云架构,也就是UFO(UGC Feed all in One)系统,通过一些列的业务侧架构优化,存储服务迁移MongoDB后,最终获得了极大收益,主要收益如下:
维护成本降低
业务性能提升
用户体验更好
存储成本更少
业务迭代开发效率提升
Feed命中率显著提升,几乎100%
问题与挑战
通过Feed云系统改造,研发全新的UFO系统替换掉之前老的Feed云系统,实现了小世界的性能提升、三地多活容灾;同时针对小世界特性,对新Feed云系统做了削峰策略优化,极大的提升了用户体验。
2.1 老Feed系统主要问题
改造优化前面临的问题主要是:
写性能差
QQ小世界是开放关系链的社交,时有出现热key写入;
性能不足的问题,比如被动落地慢,Feed发表、写评论吞吐量低等。
机房不稳定
之前小世界所有服务都是单地域部署,机房出现问题就会引起整个服务不可用,单点问题比较突出。
业务增长快,系统负载高
小世界业务目前DAU涨的很快,有时候会出现新用户蜂拥进入小世界的情况,对后台的负载造成压力。
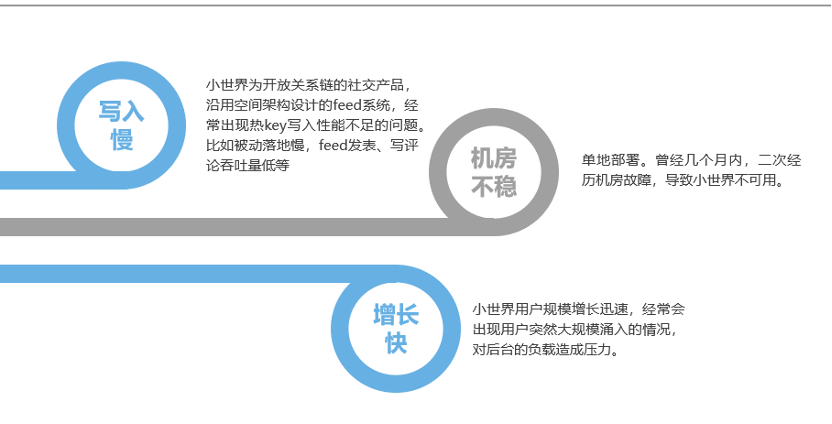
图:老Feed系统存在的主要问题
下面举一个慢的例子:
|
|


图:举例-号段拥堵
小世界的一个大UP主常常会获得大量的评论和点赞,从而产生大量的被动消息。面对大量消息写入到单个uin下,就会造成一个号段的拥堵。就如上面左图所示,这个是我们的被动消息队列的处理延时告警。从图中可以看到可以看到该号段延时了704秒,也就是说落在该号段的用户,因为是大up主,收到被动的时间整体延后11分钟。

图:QQ小世界架构
上面是小世界的大致的一个架构,从上层到下层的处理流程主要如下:
1. 最上面是手机QQ的sso接入层,然后是网关层,负责命令字分发以及做一些统一安全鉴权,alpha号鉴定等操作。
2. 接着是commreader,负责Feed流的组装和渲染。以众推页为例,他会先拉推荐系统,获取具体的Feedid,然后从Feed云里拉取具体的Feed。最后在拉取统一计数图片适配这些服务,做具体的Feed渲染。写链路也是从sso到网关。
3. 再下面是commwriter,负责处理小世界的所有写操作业务逻辑。对于发表、评论点赞这些基础操作,首先他会调用Feed云,将具体动作落地。然后再把写入成功的消息写入流水总线,供其他系统消费。
Feed云系统实际上负责了所有写操作落地的细节操作,之前说的写入慢的问题实际上说的就是Feed云写入慢。
2.2 新场景下Feed云的问题
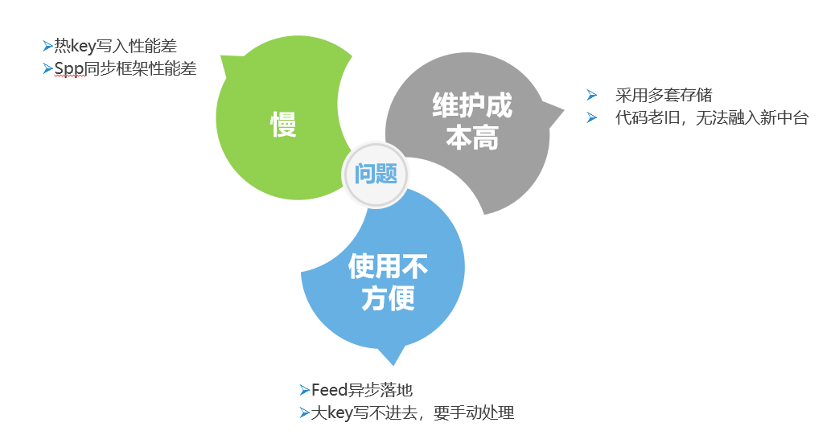
图:新场景下Feed云存在的问题
Feed云是从QQ空间系统里抽出来的一套通用Feed系统,支持Feed发表,评论,回复,点赞等基础的UGC操作。同时支持关系链、时间序拉取Feed,按id拉取Feed等,小世界就是基于这套Feed云系统搭起来的。
但在小世界场景下,Feed云还是有很多问题。我们分析Feed云主要存在三个问题。首先是之前提到的慢的问题,主要体现在热key写入性能差,ssp同步框架性能差。其次一个问题是维护成本高,因为他采用了多套存储,同时代码比较老旧,很难融入新的中台。另外还有使用不方便问题,主要体现在一个是Feed异步落地,也就是发表一个Feed,跟上层返回是已经发表成功,但实际上还可能没有在Feed系统最终落地。再一个是大key有时候写不进去,需要手动处理。
新场景下Feed云架构如下:

图:新场景下Feed云架构
这是Feed云的框架,分了UGC系统以及Feed系统的。最上面是UGC系统,一个Feed先在UGC服务处理,存储到tlist1中。然后在通过MQ1传给feed系统。Feed系统通过更新中心分发出各种各样的Feed,再写入到MQ2中,最终通过写server落地Feed。读侧也是一样,UGC提供这条Feed以及评论的完整信息读取。Feed系统提供Feed混排读取以及各种Feed列表的读取。这种分法在空间体系下是很合理的,因为本身空间就有很多UGC类型、说说、相册、日志、分享这些。
但是,该架构对小世界业务场景不太使用,主要是因为该系统存在上图中罗列的一系列问题。
数据库存储选型
下面就是对数据库存储进行选型,首先我们要细化对存储的要求,按照我们的目标DAU,候选存储需要满足以下要求:
高并发读写
方便快捷的DDL操作
分布式、支持实时快捷扩缩容
读写分离支持
海量表数据,新增字段业务无感知
目前大致符合需求的存储主要是MongoDB和Tendis,团队对两者做了对比,下表里面列了一些详细的情况。4C8G低规格MongoDB实例性能数据对比结果如下:

图:MongoDB与Tendis在小世界场景下性能对比
包括大key的支持,高并发读的性能,单热key写入性能,局部读能力等等。发现在大key支持方面,Tendis不能满足我们业务需求,主要是大value和redis的key是不降冷的,永久占用内存。
所以我们选择了MongoDB作为最终存储。
下图就是具体的存储设计,可行的方案主要是两种,主要的区别是是否使用多文档实现单个uin下的Feed。结合业务,分别从个人档拉取实现复杂度,查询单条feed速度,插入单条feed速度,个人档存储上限,操作原子性,可重入性等特性做了对比。一个uin一个文档的方案有个明显缺陷,个人档存储最大上限16M,和我们的2G相差甚远。所以最终我们采用uin多文档的方式去存。
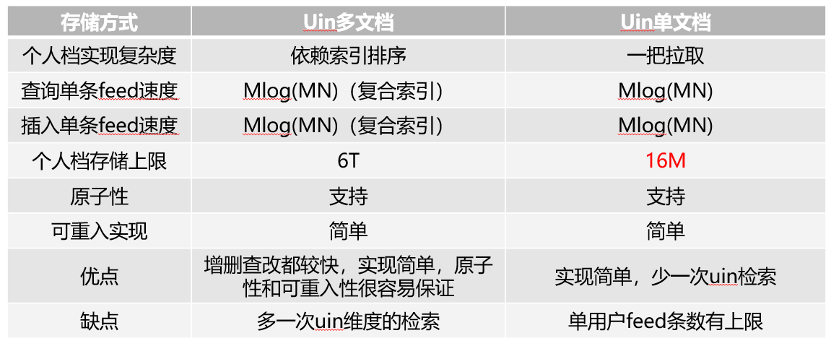
图:存储设计可行性方案对比
小世界Feed云系统改造及优化过程

图:小世界Feed云系统优化思考
为了解决前面Feed云系统面临的调整及问题,我们主要做了一下几个方面的业务架构调整及优化:
数据库存储统一
首先第一个是能否简化系统,并仅使用一套存储。小世界多UGC场景的需求较少,不需要单独的UGC系统,所以合并UGC系统和Feed系统问题不大。
如果使用一套存储的话,首先要解决之前提到的热key问题,需要支持高并发热key写。其次合并UGC系统和Feed系统的话,需要读取的时候支持数据的局部拉取,因为UGC存的是全量数据,Feed是摘要数据,读侧要同时支持。
最后通过选型调研(参考后面章节),确认MongoDB具有海量数据存储能力,同时支持高并发的读写,完全可以替代老Feed系统中的ckv+tlist存储场景。
MQ2路由优化
采用opuin作为MQ的路由key,打散热key的请求,就必然存在时序问题。由于是被动消息的操作,实际上只有插入、更新和删除,因此如果每次操作都有全量数据,做全量覆盖,再配合简单的版本号机制,就能解决时序问题引起的写错乱。这样的话,全量数据要同步生成,同时至多产生一次Feed拉取,代价可控。
通过MQ进行路由key打散操作,最终解决热key请求问题。
同步落地
合并UGC系统和Feed系统后,自然而然的要同步落地动作。至于被动Feed,可以异步进行,更新中心可以放到旁路。
4.1 Feed云优化改造及成果收益
4.1.1 Feed云优化改造-UFO(UGC Feed all in One)
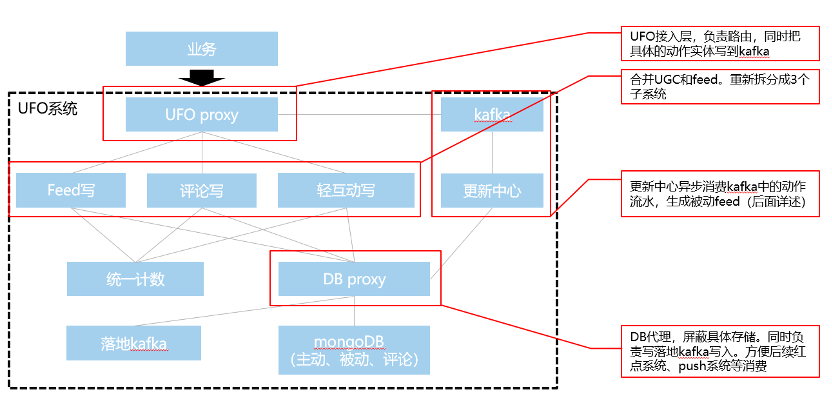
图:UFO系统架构
最后UGC和Feed合并后的最终UFO系统架构如上图所示,新系统最上层是UFO proxy。他是接入层,负责路由,同时在发表后,把具体的发表动作实体写到kafka中,重新细化拆分为feed系统、评论系统、轻互动系统三个子系统。
更新中心异步消费kafka中的动作流水,生成被动,这块的加速问题后面详述,三个系统可以共用一套存储体系。DB proxy用来屏蔽具体存储,同时负责落地kafka的写入、后续红点系统、push系统等消费。
4.1.2 Feed云优化改造-更新中心被动加速
图:举例-点赞场景
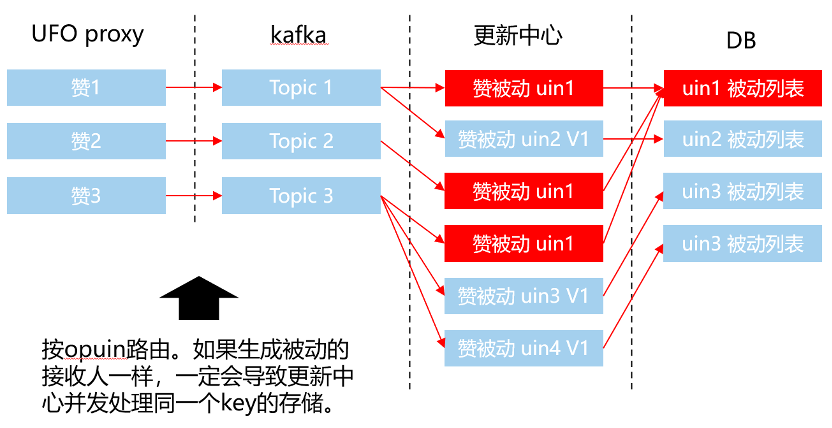
图:更新中心工作原理图
我们可以采用opuin作为路由key,将热门Feed的被动打散。就像图中这样,三个赞,分别写入kafka的三个topic,并行进行操作。不过因此也会产生时序的问题,像这里的uin1的赞被动,因为三个topic时序不可控,最终uin1的这条赞被动的最终结果也是不确定的。
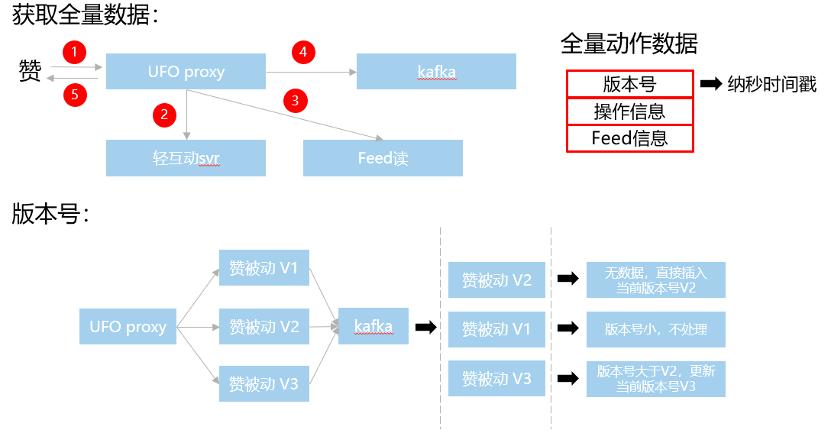
图:全量数据+版本号方案流程图
采用全量数据+版本号的方案去解决上面说的问题的。具体获取全量数据的流程就是这个图里展示的这样,一个赞过来,首先是通知轻互动svr落地具体的赞动作。然后proxy这层去拉Feed,组成完整的动作数据,在写入kafka,完成后通知上层赞成功,这样kafka里的数据每次都是一次全量的数据。
然后我们再proxy这一层去对每个赞动作去生成一个版本号。就像下面这个图这样,到了kafka里,即使他的时序是乱的,我也能够通过版本号保证最终落地的是最新的那条。
4.1.3 Feed云优化改造-成果收益
单机及全链路压测结果如下:

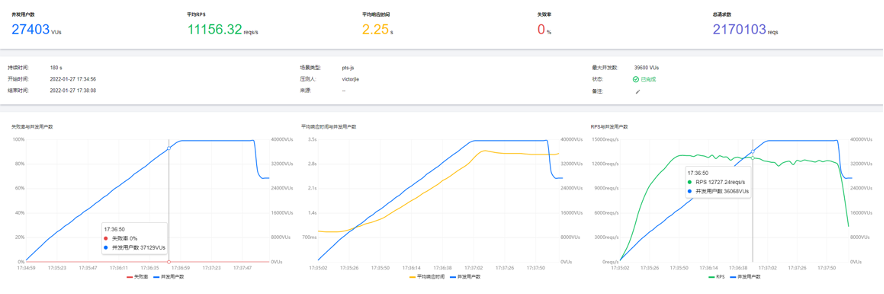
图:单机及全链路压测结果
被动处理性能如下:
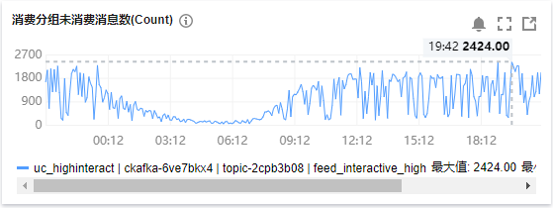
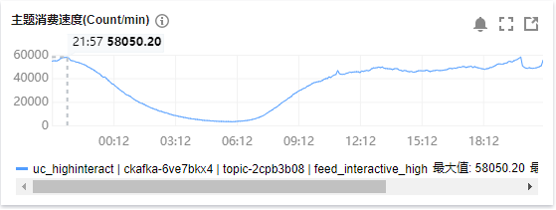
图:被动处理性能
主被动Feed存储优化前后存储成本对比:
优化前:
tlist(78G*2+1.76T)+ckv(80G) = 1.996T
优化后:
MongoDB(268G+1.48T) = 1.748T
压测总结:
这里贴了一些核心服务的压测性能,其中db接入这个性能相对比较差,原因是他是有一个6倍扩散的。然后是全链路的压测,从广场页是5W/S,最后到UFO DB和MongoDB的性能。再就是被动处理性能,从第一个图中能看到每分钟未消费的数量大致是2000以内,算下来延时最多2秒。
4.2 Feed云多地容灾及成果收益
小世界Feed云最终采用三地读、一地写的伪三地策略,实现多地容灾,后续逐步进行真三地改造。

图:不采用真三地的原因
不采用真三地的原因主要是有三个方面:
第一个是存储层不支持异地多主写入,小世界主要用的redis和MongoDB都不具有这个能力。这样的话,要实现真三地就需要业务自己做多地写,需要整个链路全部进行改造,但是这么做代价是很高的,尤其是解决地域跳变用户的写操作问题。再一个是三地上线时间比较紧迫,当时几个月中出现过两次机房故障,导致小世界不可用,所以需要在短时间内实现三地化。
4.2.1 Feed云多地容灾-方案思考
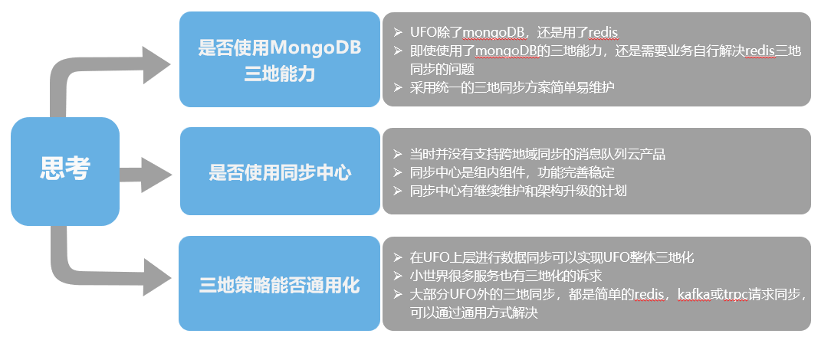
图:Feed云多地容灾的思考
对于三地读一地写的多地容灾,主要是进行了以下几点思考:
第一个是否使用MongoDB的三地能力,UFO除了使用MongoDB外,还有用到redis、kafka等其他组件。虽然MongoDB具备三地容灾能力,还是需要业务自行解决redis的三地同步问题。所以放弃MongoDB自身的三地机制,统一使用一套三地方案,方便维护。
再一个思考是是否使用同步中心,当时并没有跨地域同步的消息队列云产品,同步中心本身又是组内维护的,功能也比较全。同时也有架构升级的计划,所以这里我们还是采用同步中心去实现三地同步。
第三个思考是能否做到通用化方案。一个是UFO内部的评论系统,Feed系统以及互动系统,都需要进行三地化。在UFO上层进行数据同步可以实现UFO整体三地化,小世界其他的一些服务也需要三地。大部分都是简单的redis,kafka或者trpc请求的同步,我们可以通过通用的方式去解决。
4.2.2 多地容灾-三地容灾方案
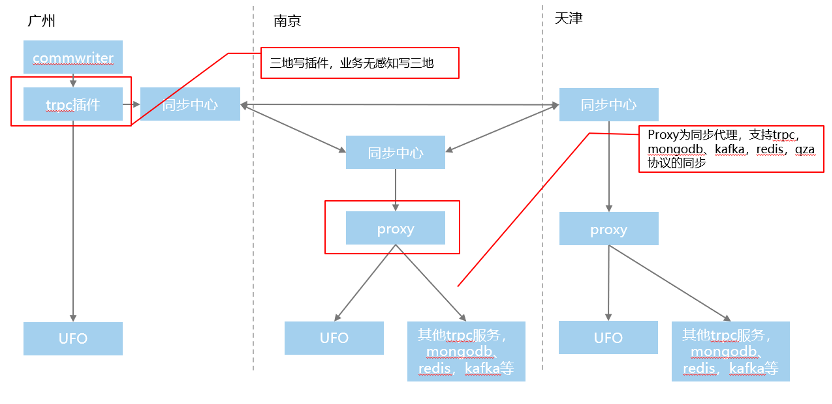
图:最终Feed云的三地容灾方案
上图就是最终的三地容灾方案:Commwriter写UFO时,直接调用一个我们写好的trpc插件,这个插件先写UFO成功后,再去写入同步中心。
在南京和天津两地的同步中心下面,接入一个通用的proxy服务,这个服务支持trpc、MongoDB、kafka、redis以及qza协议的同步。
4.2.3 多地容灾-三地同步加速
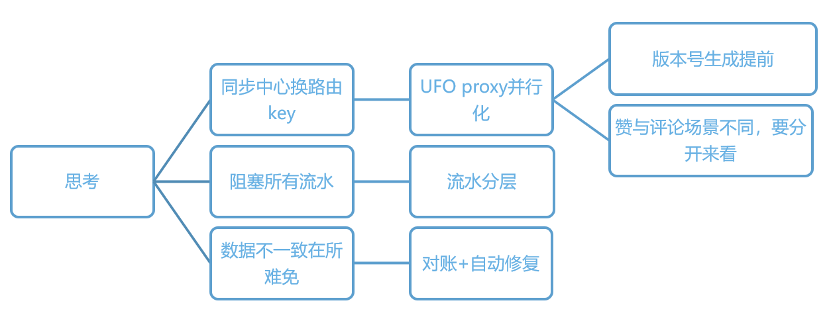
图:多地容灾难点思考
对于UFO多地容灾也是有几个难点的,首先一个是三地同步加速问题。三地写同步中心依然存在之前提到的热key写入瓶颈。主要表现为:大UP主热Feed互动流水会堵塞一个号段上的所有同步流水。
针对这个问题,可以从几个方面进行了思考:
同步中心换路由KEY
这样会导致UFO proxy层并行化处理同一个Feed的相关内容,之前说的版本号的生成需要提前。同时,对于这里的并行化,需要按不同动作分开来看,赞和评论业务逻辑不同,需要分别处理。
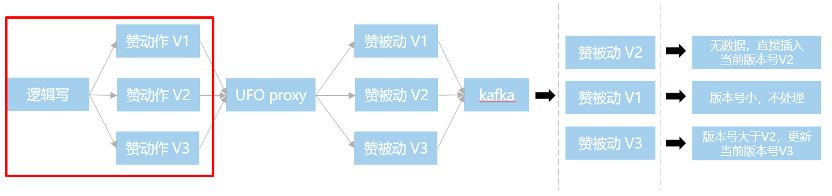
图:同步中心换路由KEY逻辑
首先应该把版本号生成提前,在逻辑层生成版本号。对于赞来说,我们直接按opuin路由没有问题,逻辑很简单。
但是评论存在时序问题,比如评论和回复,评论和安全打击等,这里我们就需要按照评论id进行路由,所有该评论相关的操作串行进行
阻塞所有流水
流水分层,我们按照重要程度和频繁程度,分出来三个topic,Feed相关的一个,互动相关的一个,运营通知被动相关的一个。
数据一致性
三地数据不一致的问题肯定还是存在的,需要进行对账和自动修复。
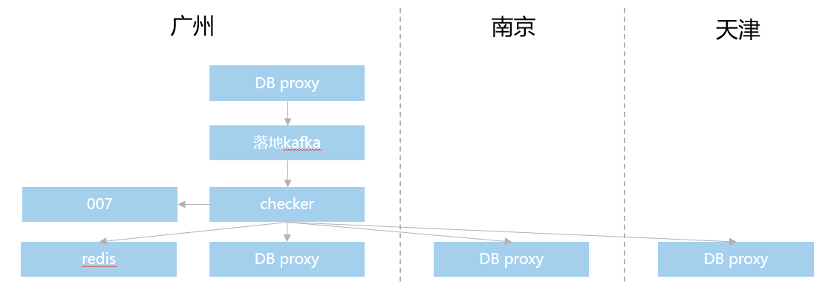
图:确保数据一致性方案
数据一致性保证方面,采取的是实时对账机制+每天全量对账的机制。首先在落地kafka后面接入一个checker服务,专门用于对账,他会延时10分钟消费实时流水。读取三地数据进行比对,上报007,同时把当天涉及的Feedid存入redis。
然后每天凌晨2:30开始,对前一天的所有有改动的feedid进行全量对账,同时进行数据修复。
4.2.4 多地容灾-通用可重入机制
为了避免重跑流水带来的数据问题,三地同步机制统一支持请求可重入,使用方无感知。具体方案如下:
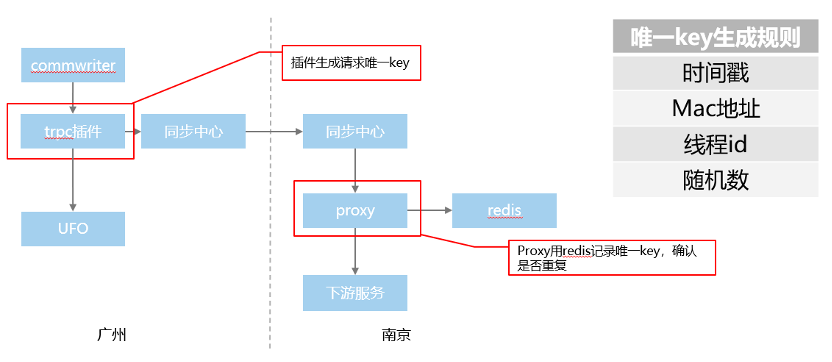
图:可重入机制
如何实现通用的可重入机制?同步中心后面的服务,都应该可重入,防止哪天重跑流水导致数据异常,这里也是通过我们的通用插件完成的。
请求使用插件的时候,我们会对每个请求生成一个唯一key,具体的规则是根据时间戳+mac地址+线程id+随机数生成的。在通用的proxy层,我们用redis记录处理过的唯一key,如果重复直接跳过。
4.2.5 多地容灾-成果收益
实时对账成果
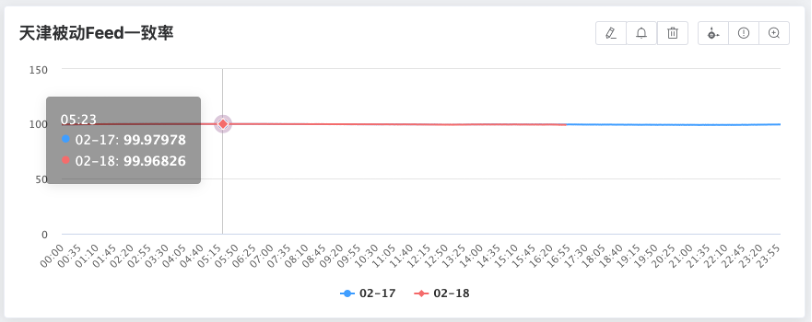
图:实时对账成果
全量对账成果
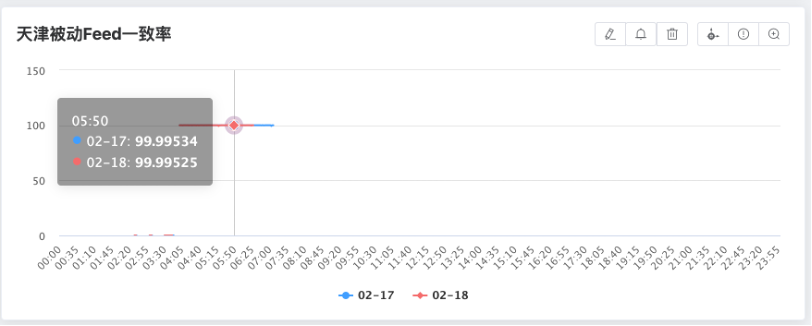
图:全量对账成果
上图是我们实时对账和全量对账的结果,实时对账一致性一般在2个9到3个9这个范围,全量对账一致性在4个9以上。
4.3 应对高增长
4.3.1 应对高增长-应对突增流量的方法论
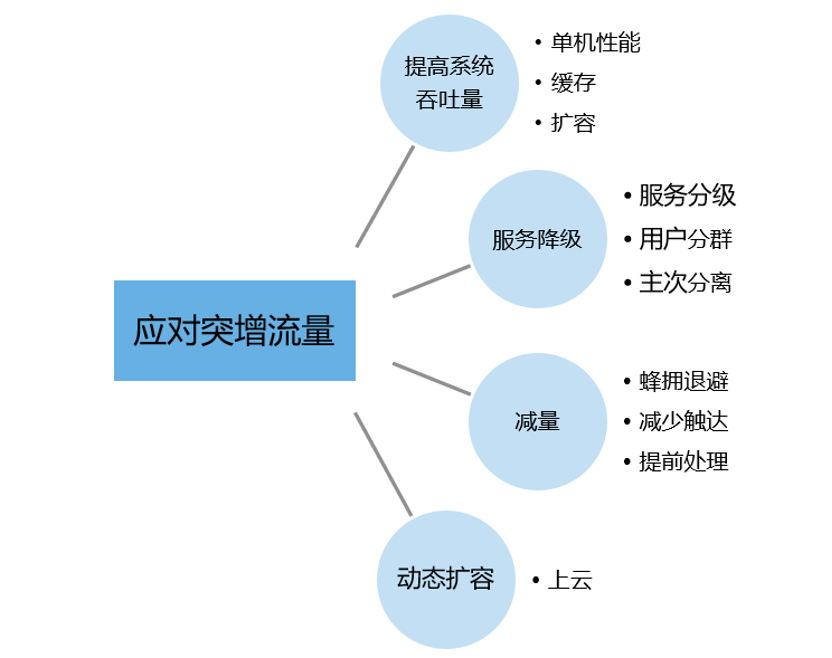
图:应对突增流量的方法论
最后一个问题是应对高增长,首先这个是小世界和空间项目中总结的一些应对突增流量的方法论,主要分四个方向:
提高系统吞吐量方向,包括提升单机性能,加缓存或者扩容;
服务降级方向,包括服务分级,用户分群以及主次分离等;
减量的方向,主要包括蜂拥退避,减少触达,提前处理;
动态扩容方向,主要是上云。
4.3.2 应对高增长-具体策略
针对QQ小世界场景,我们当前做的一些柔性策略,也是应用了刚才的一些理念,对应具体策略及收益总结如下:
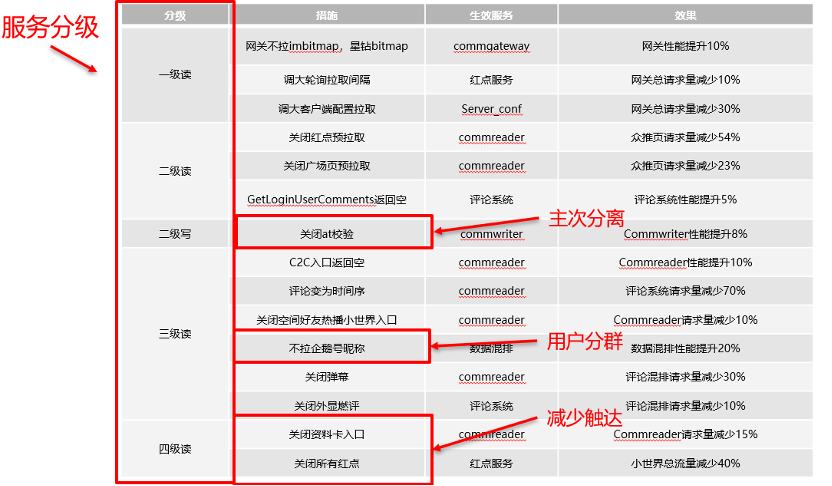
图:应对高增长的策略-对应收益
小世界MongoDB业务用法及内核性能优化
5.1 MongoDB表设计
5.1.1 Feed表及索引设计
InnerFeed表
InnerFeed 为整个主动被动Feed结构,主要设计Feed核心信息,设计Feed主人、唯一ID、Feed权限:
message InnerFeed{string feedID = 1; //id,存储层使用,唯一标识一条feedstring feedOwner = 2; //Feeds主人trpc.feedcloud.ufobase.SingleFeed feedData = 3; //feed详情数据uint32 feedMask = 4; //信息中心内部使用的//feed 权限flag标志,参考 ENUM_UGCFLAGtrpc.feedcloud.ufougcright.ENUM_UGCFLAG feedRightFlag = 5;};
SingleFeed表
SingleFeed 为Feed基本信息,Feed类型,主动、评论被动、回复被动、Feed生成时间以及Feed详情:
message SingleFeed {int32 feedType = 4; //Feed类型,主动、评论被动、回复被动。。。uint32 feedTime = 5;FeedsSummary summary = 7; //FeedsSummarymap<string, string> ext = 14; //拓展信息...};
FeedsSummary表
FeedsSummary为Feed详情,其中UgcData为原贴主贴数据,UgcData.content负责存储业务自定义的二进制数据,OpratorInfo为Feed操作详情,携带对应操作的操作人、时间、修改数据等信息:
//FeedsSummarymessage FeedsSummary{UgcData ugcData = 1; //内容详情OpratorInfo opInfo = 2; //操作信息};// UgcData 详情message UgcData{string userID = 1 [(validate.rules).string.tsecstr = true]uint32 cTime = 2;bytes content = 5; //透传数据,二进制buffer...};message OpratorInfo{uint32 action = 1; //操作类型,如评论、回复等,见FC_API_ACTION//操作人uinstring userID = 2 [(validate.rules).string.tsecstr = true];uint32 cTime = 3; //操作时间//如果是评论或者回复,当前评论或者回复详情放这里,其它回复内容是全部。T2Body t2body = 4;uint32 modifyFlag = 11; //ENUM_FEEDS_MODIFY_DEFINE...};
Feed索引设计
(1) Feed主要涉及个人主页Feed拉取、关注页个人Feed聚合:
"key" : {"feedOwner" : -1,"feedData.feedKey" : -1}
(2) 根据FeedID拉取指定的Feed详情:
"key" : {"feedOwner" : -1,"feedData.feedTime" : -1}
5.1.2 评论回复表及索引设计
InnerT2Body表
InnerT2Body 为整个评论结构,回复作为内嵌数组内嵌评论中,结构如下:
message InnerT2Body{string feedID = 1;//如果是评论或者回复,当前评论或者回复详情放这里,其它回复内容是全部。trpc.feedcloud.ufobase.T2Body t2body = 2;};
T2Body 表
T2Body 为评论信息,涉及评论ID、时间、内容等基本信息:
message T2Body //comment(评论){string userID = 1; //评论uinuint32 cTime = 2; //评论时间string ID = 3; //ugc中的seq//评论内容,二进制结构,可包含文字、图片等,业务自定义string content = 5;uint32 respNum = 6; //回复数repeated T3Body vt3Body = 7; //回复列表...};
T3Body 表
T3Body 为回复信息,涉及回复ID、时间、内容、被回复人的ID等基本信息:
message T3Body //reply(回复){string userID = 1; //回复人uint32 cTime = 2; //回复时间int32 modifyFlag = 3; //见COMM_REPLY_MODIFYFLAGstring ID = 4; //ugc中的seqstring targetUID = 5; //被回复人//回复内容,二进制结构,可包含文字、图片等,业务自定义string content = 6;};
评论索引设计
(1) 评论主要涉及评论时间序排序:
"key" : {"feedID" : -1,"t2body.cTime" : -1}
(2) 根据评论ID拉取指定的评论详情:
"key" : {"feedID" : -1,"t2body.ID" : -1}
5.2 片建选择及分片方式
以Feed表为例,QQ小世界主要查询都带有feedowner,并且该字段唯一,因此选择码id作为片建,这样可以最大化提升查询性能,索引查询都可以通过同一个分片获取数据。此外,为了避免分片间数据不均衡引起的moveChunk操作,因此选择hashed分片方式,同时提前进行预分片,MongoDB默认支持hashed预分片,预分片方式如下:
use feedsh.enableSharding("feed")//n为实际分片数sh.shardCollection("feed.feed", {"feedowner": "hashed"}, false,{numInitialChunks:8192*n})
5.3 低峰期滑动窗口设置
当分片间chunks数据不均衡的情况下,会触发自动balance均衡,对于低规格实例,balance过程存在如下问题:
CPU消耗过高,迁移过程甚至消耗90%左右CPU
业务访问抖动,耗时增加
慢日志增加
异常告警增多
以上问题都是由于balance过程进行moveChunk数据搬迁过程引起,为了快速实现数据从一个分片迁移到另一个分片,MongoDB内部会不停的把数据从一个分片挪动到另一个分片,这时候就会消耗大量CPU,从而引起业务抖动。
MongoDB内核也考虑到了balance过程对业务有一定影响,因此默认支持了balance窗口设置,这样就可以把balance过程和业务高峰期进行错峰,这样来最大化规避数据迁移引起的业务抖动。例如设置凌晨0-6点低峰期进行balance窗口设置,对应命令如下:
use configdb.settings.update({"_id":"balancer"},{"$set":{"activeWindow":{"start":"00:00","stop":"06:00"}}},true)
5.4 MongoDB内核优化
内核认证随机数生成优化
MongoDB在认证过程中会读取 /dev/urandom用来生成随机字符串来返回给客户端,目的是为了保证每次认证都有个不同的Auth变量,以防止被重放攻击。当同时有大量连接进来时,会导致多个线程同时读取该文件,而出于安全性考虑,避免多并发读返回相同的字符串(虽然概率极小),在该文件上加一把spinlock锁(很早期的时候并没有这把锁,所以也没有性能问题),导致CPU大部分消耗在spinlock,这导致在多并发情况下随机数的读取性能较差,而设计者的初衷也不是为了速度。
MongoDB内核随机数优化方法:新版本内核已做相关优化,mongos启动的时候读/dev/urandom获取随机字符串作为种子,传给伪随机数算法,后续的随机字符串由算法实现,不去内核态获取。
优化前后测试对比验证方法:通过python脚本模拟不断建链断链场景,1000个子进程并发写入,连接池参数设置socketTimeoutMS=100,maxPoolSize=100,其中socketTimeoutMS超时时间设置较短,模拟超时后不断重试直到成功写入数据的场景(最多100次)。
测试主要代码如下:
def insert(num,retry):print("insert:",num)if retry <= 0:print("unable to write to database")returndb_client = pymongo.MongoClient(MONGO_URI,maxPoolSize=100,socketTimeoutMS=100)db = db_client['test']posts = db['tb3']try:saveData = []for i in range(0, num):saveData.append({'task_id':i,})posts.insert({'task_id':i})except Exception as e:retry -= 1insert(num,retry)print("Exception:",e)def main(process_num,num,retry):pool = multiprocessing.Pool(processes=process_num)for i in xrange(num):pool.apply_async(insert, (100,retry, ))pool.close()pool.join()print "Sub-processes done."if __name__ == "__main__":main(1000,1000,100)
优化结果如下:
优化前:CPU 峰值消耗60核左右,重试次数 1710,而且整体测试耗时要更长,差不多增加2 倍。
优化后:CPU 峰值: 7核左右,重试次数 1272,整体性能更好。
mongos连接池优化
通过调整MinSize和MaxSize,将连接数固定,避免非必要的连接过期断开重建,防止请求波动期间造成大量连接的新建和断开,能够很好的缓解毛刺。优化方法如下:
ShardingTaskExecutorPoolMaxSize: 70ShardingTaskExecutorPoolMinSize: 35
如下图所示,17:30调整的,慢查询少了 2 个数量级:
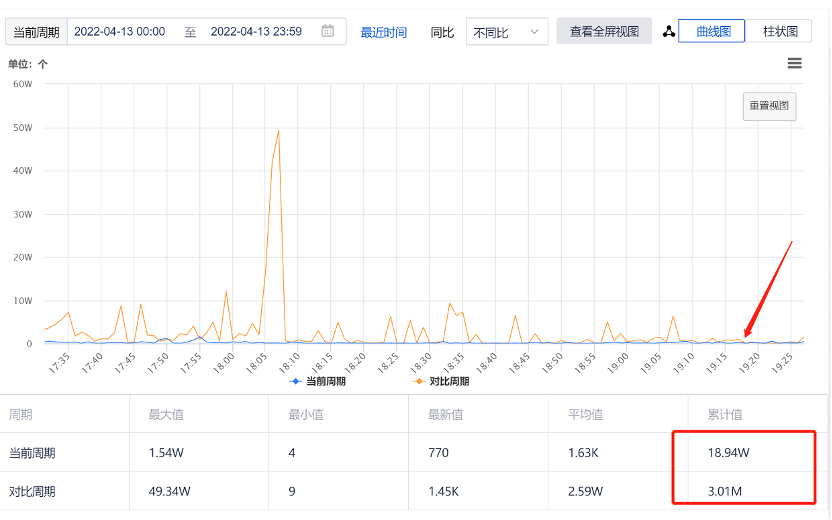
图:mongos连接池优化性能
5.4 MongoDB集群监控信息统计
如下图所示,整个QQ小世界数据库存储迁移至MongoDB后,平均响应时延控制在5ms以内,整体性能良好。

图:MongoDB集群监控信息统计
关于作者
腾讯PCG功能开发一组团队:
徐磊:功能开发一组组长,开源项目feed云组件负责人
揭啸宇:高级工程师,开源项目feed云组件核心开发人员
李泽鑫:开源项目feed云组件核心开发人员
腾讯MongoDB团队:
腾讯MongoDB当前服务于游戏、电商、社交、教育、新闻资讯、金融、物联网、软件服务等多个行业;MongoDB团队(简称CMongo)致力于对开源MongoDB内核进行深度研究及持续性优化(如百万库表、物理备份、免密、审计等),为用户提供高性能、低成本、高可用性的安全数据库存储服务。后续持续分享MongoDB在腾讯内部及外部的典型应用场景、踩坑案例、性能优化、内核模块化分析。
看到这里的小伙伴,点个大赞和在看吧!
﹀
﹀
﹀

亿级月活全民K歌Feed业务在腾讯云MongoDB中的应用及优化实践

叮咚买菜自建MangoDB上腾讯云实践

