
反爬篇 | 手把手教你处理 JS 逆向之 CSS 偏移

大家好,我是安果!
前面 2 篇文章分别讲解了应对图片伪装、字体反爬网站的常规解决方案
本篇文章将聊聊另外一种常见的反爬方案,即:「 CSS 偏移 」
CSS 偏移反爬是利用「 CSS 样式 」对网页元素进行一次自定义的排序,最后让网页以正确的数据展示出来
下面我们通过一个简单的实例,讲解应对 CSS 偏移网站常规解决方案
目标对象:
aHR0cDovL3d3dy5wb3J0ZXJzLnZpcC9jb25mdXNpb24vZmxpZ2h0Lmh0bWw=
1、分析一下
打开目标网站,在开发者工具面板中查看「 机票价格 」的网页元素组成方式
我们发现,机票价格由上、下两个区域的数据元素,通过一定的偏移量偏移,最后在页面上展示的
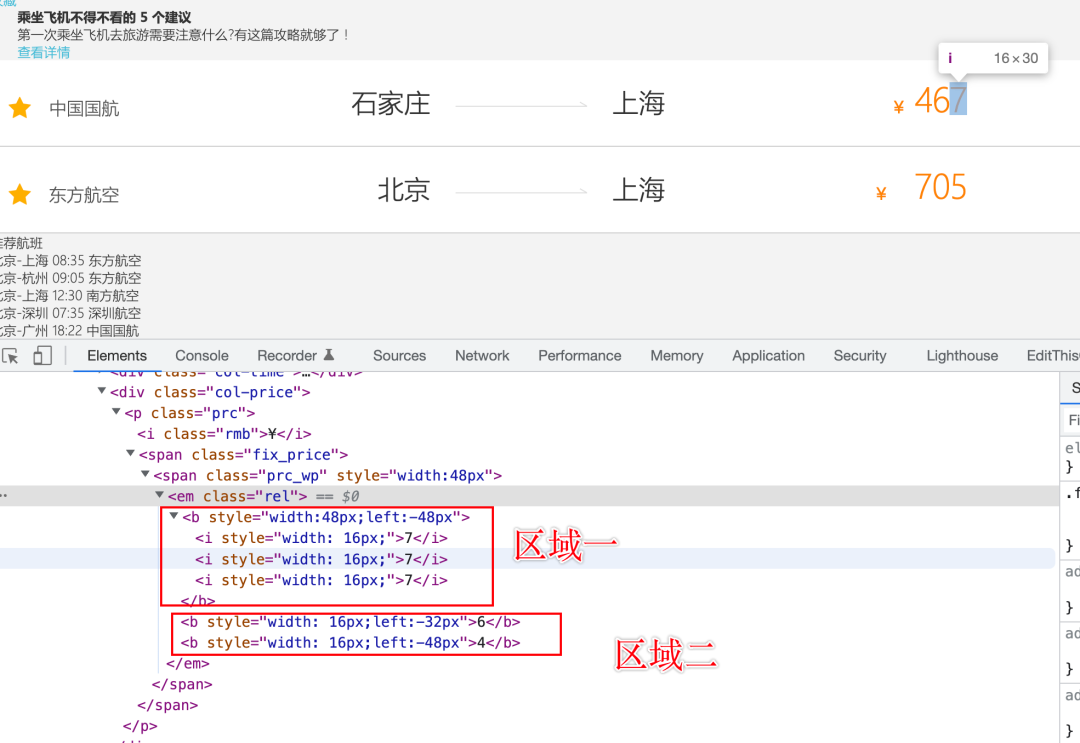
以第 1 条数据为例,机票实际价格为 467
区域一宽度设置为 48px,left 的值为 -48px 代表左边距向左偏移 48px
其内部的 i 标签宽度都为 16px,完全占满了父容器的宽度
即:如果区域二隐藏的话,机票价格应该为 777
我们继续看区域二的内容
第一个 b 标签,内容为 6,left 属性值为 -32px,宽度为 16px,会覆盖上面的第二个数字
第二个 b 标签,内容为 4,left 属性值为 -48px,宽度同样为 16px,会覆盖掉上面的第一个数字
因此,最后网页展示的机票价格就是 467
2、特殊处理
如果仔细观察网页元素,会发现 b 元素下的第三个 i 标签既然展示在第二个行,而不是和前面两个 i 标签在同一行展示
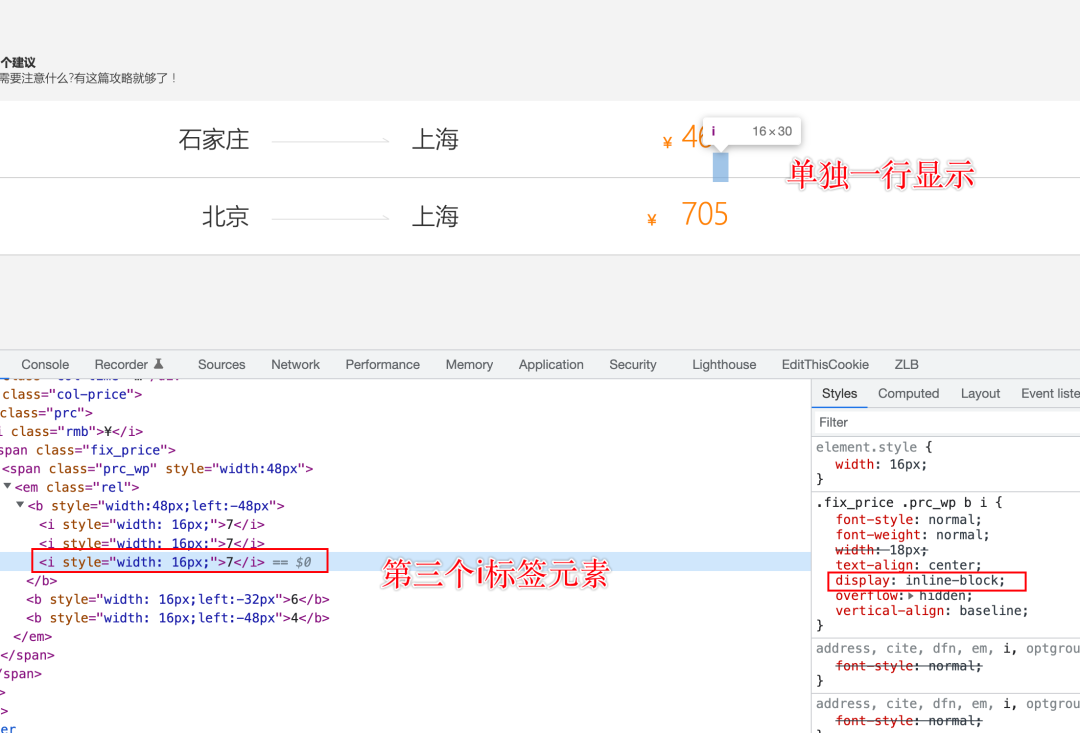
其实,这是因为 i 元素标签设置样式 display 为 inline-block
PS:inline-block 默认元素之间会存在一定的间隙
因此,为了正确解析出数据,我们需要针对网页源代码对部分控件样式进行二次更新
3、实战一下
首先,我们需要安装依赖包
# 依赖包
# bs4 用于对网页源码的元素样式进行二次更新
pip3 install beautifulsoup4
# lxml 用于爬取网页数据
pip3 install lxml
接下来,我们使用 bs4 解析网页源码,获取所有的 em 元素,修改它下面「 b 标签 」的 display 属性值为浮动「 flex 」,然后重新导出数据
import requests
from bs4 import BeautifulSoup
...
url = 'http://.../flight.html'
resp = requests.get(url).text
# 首次解析源码
soup = BeautifulSoup(resp, "lxml")
# 查询页面中的em元素
em_elements = soup.find_all("em", class_="rel")
# 对第一个b标签添加flex的属性
for em_element in em_elements:
first_b_element = em_element.find_all('b')[0]
# 添加flex属性
first_b_element['style'] = first_b_element['style'] + ';display:flex;'
# 重新导出进行数据解析
resp = soup.prettify()
...
# 写入到本地文件查看
# with open('temp.html', 'w', encoding='utf-8') as file:
# file.write(resp)
...紧接着,我们利用 xpath 语法获取所有航班 Item 元素控件
结合正则表达式拿到机票价格对应元素的 left 偏移量,通过这个偏移量可以计算出数据应该展示的位置索引
最后,根据索引将数据放置在列表的既定位置,组成真实的机票价格
import re
from lxml import etree
...
# 数据解析
html = etree.HTML(resp)
# 查询有几个航班数据
div_list = html.xpath('//div[@class="left col-md-9"]/div')
print('航班数据数目:', len(div_list))
for index in range(len(div_list)):
# 获取所有b标签
b_elements = div_list[index].xpath('.//em/b')
# 从第1个b标签下面的子标签数据 ,这样就可以获取价格的位数(3位、4位)
price_num_list = b_elements[0].xpath('./i/text()')
print("打底机票价格为:", ''.join([item.strip() for item in price_num_list]))
# 从第2个b标签开始,获取真实价格对应的数字
for index, b_element in enumerate(b_elements[1:]):
# 数据
price_num = int(b_element.xpath('./text()')[0])
# 获取b标签的style属性值
style = b_element.xpath('./@style')[0]
# 利用正则表达式,获取left属性值
left_value = re.findall('left:(.*?)px', style)[0]
# 根据left值,计算数据在真实价格中的索引位置(-1/-2/-3)
price_index = int(int(left_value) / 16)
# 替换源数组中的数据,按索引将数值设置进去
price_num_list[price_index] = price_num
# item都转成字符串,合成一个新的数组
price_num_list = [str(item).strip() for item in price_num_list]
# 组成价格
price = int(''.join(price_num_list))
print("机票价格:", price)
...以上是一个简单的 CSS 偏移实例,我已将文中所有源码上传到后台,回复关键字「 csspy 」获取文中所有源码及资源
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
END