import cv2 from google.colab.patches import cv2_imshow import numpy as np import plotly.figure_factory as ff
# Check the distribution of red values red_values = [] for i in range(len(images)): red_value = np.mean(images[i][:, :, 0]) red_values.append(red_value)
# Check the distribution of green values green_values = [] for i in range(len(images)): green_value = np.mean(images[i][:, :, 1]) green_values.append(green_value)
# Check the distribution of blue values blue_values = [] for i in range(len(images)): blue_value = np.mean(images[i][:, :, 2]) blue_values.append(blue_value)
import cv2 from google.colab.patches import cv2_imshow
# Reading the original image image_spot = cv2.imread(image_file) cv2_imshow(image_spot)
# Converting it to HSV color space hsv_image_spot = cv2.cvtColor(image_spot, cv2.COLOR_BGR2HSV) cv2_imshow(hsv_image_spot)
# Setting the black pixel mask and perform bitwise_and to get only the black pixels mask = cv2.inRange(hsv_image_spot, (0, 0, 0), (180, 255, 40)) masked = cv2.bitwise_and(hsv_image_spot, hsv_image_spot, mask=mask) cv2_imshow(masked)
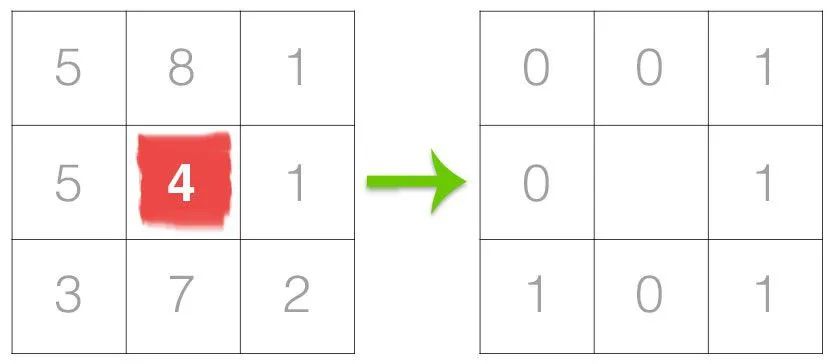
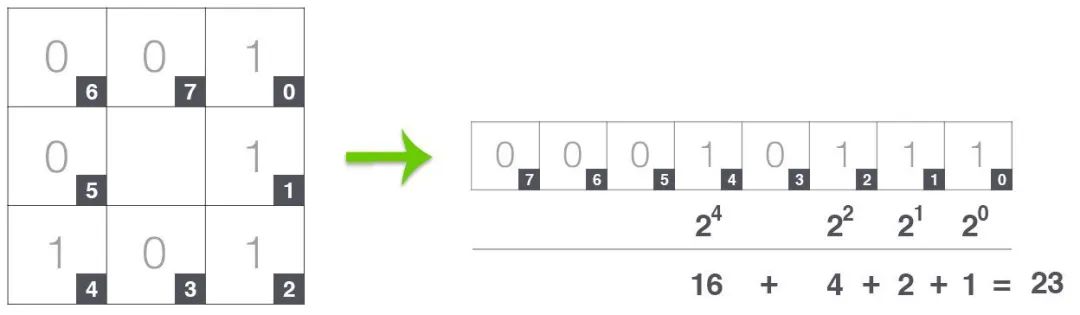
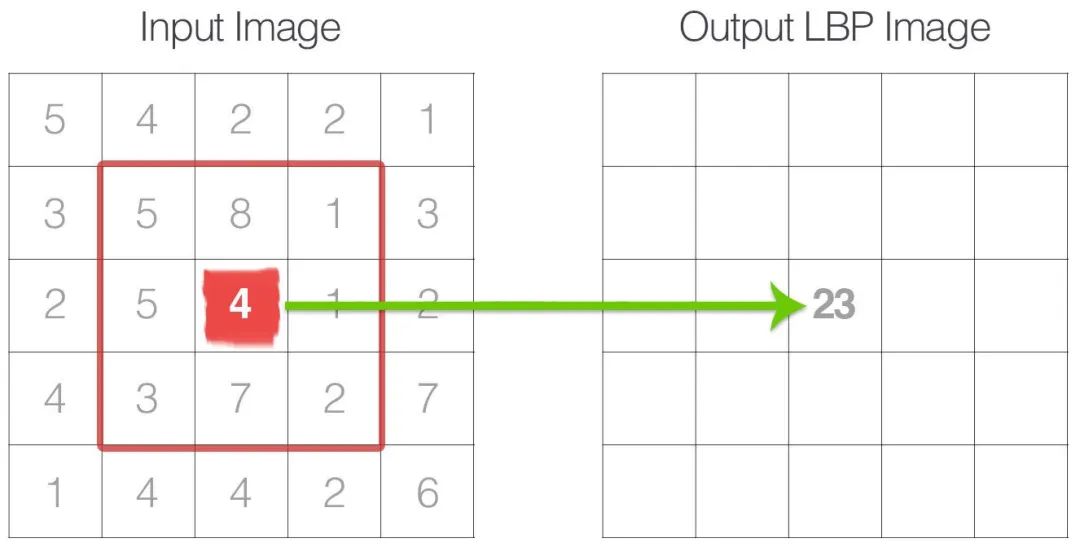
RGB vs HSV vs Masked 图像使用 cv2.inRange() 检索黑点有时,我们甚至可以使用*cv2.kmeans()来量化图像的颜色,从本质上将颜色减少到几个整洁的像素。根据我们的目标,我们可以使用cv2.inRange()*来检索目标像素。通常,这个函数在识别图像的重要部分时很有魅力,我总是会在继续使用其他颜色特征提取方法之前检查这个函数。
import cv2 from google.colab.patches import cv2_imshow
# convert to np.float32 Z = np.float32(image_spot_reshaped) # define criteria, number of clusters(K) and apply kmeans() criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0) K = 2 ret, label, center = cv2.kmeans(Z, K, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS) # Now convert back into uint8, and make original image center = np.uint8(center) res = center[label.flatten()] res2 = res.reshape((image_spot.shape))
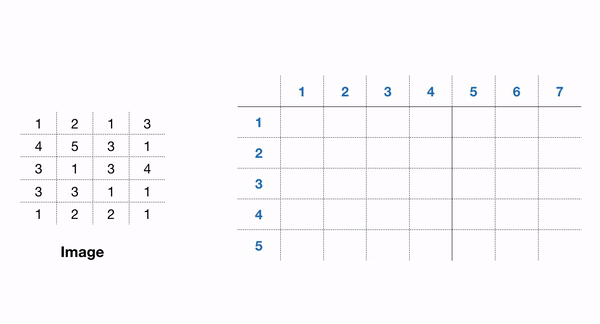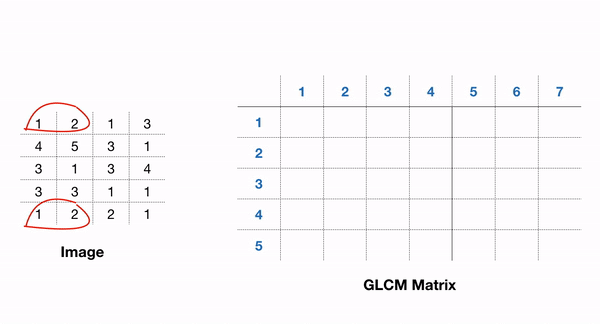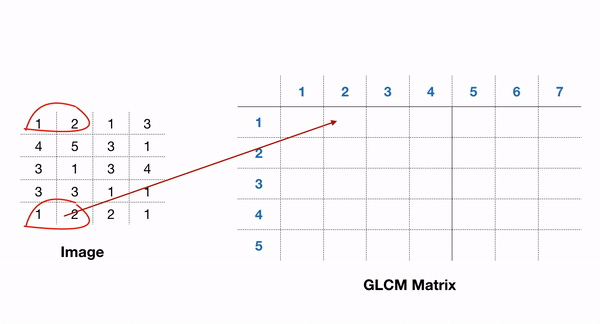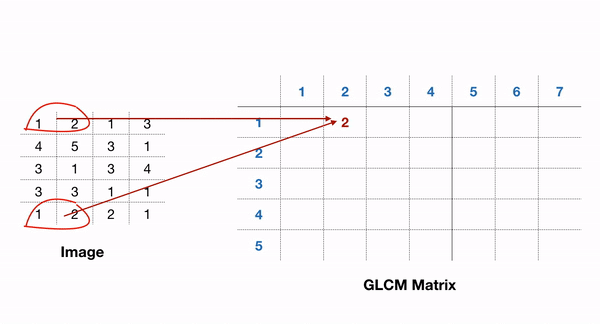
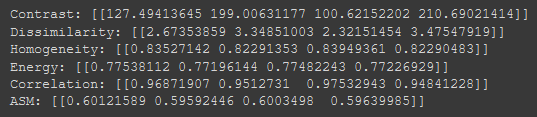
# Param: # source image # List of pixel pair distance offsets - here 1 in each direction # List of pixel pair angles in radians graycom = feature.greycomatrix(gray, [1], [0, np.pi/4, np.pi/2, 3*np.pi/4], levels=256)
 AI算法与图像处理
AI算法与图像处理