
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二十四)

极市导读
本文重新审视现有的 Transformer 模型,认为业界很多 Transformer 模型在实际硬件上的效率甚至不如 Kaiming 当年原版的 ResNet。作者认为这是由于目前衡量计算效率的标准不够精细化所致。作者在本文中设计了一系列面向 TensorRT 的视觉 Transformer 模型 TRT-ViT,它们在图像分类的精度-延迟权衡方面优于现有的 ConvNet 和 Transformer 模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
44 面向 TensorRT 的视觉 Transformer
(来自字节跳动)
44.1 TRT-ViT 原理分析
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
本文重新审视现有的 Transformer 模型,认为业界很多 Transformer 模型在实际硬件上的效率甚至不如 Kaiming 当年原版的 ResNet。作者认为这是由于目前衡量计算效率的标准不够精细化所致,比如目前普遍使用参数量和计算量 (FLOPs) 来衡量计算的效率,但是这样的指标是比较片面的,次优的,且对于某些特定的硬件不敏感。因此,本文想要在设计 Transformer 模型时,直接将特定硬件上的 TensorRT 延迟视为效率指标,这提供了涉及计算能力、内存成本和带宽的更全面的反馈。
44 面向 TensorRT 的视觉 Transformer
论文名称:TRT-ViT: TensorRT-oriented Vision Transformer
论文地址:
https://arxiv.org/pdf/2205.09579.pdf
44.1 TRT-ViT 原理分析:
Vision Transformer 虽然已经在各种计算机视觉任务 (如图像分类、语义分割和目标检测等) 中取得了超越 CNN 的性能,但是从实景部署的角度来看,CNN 在实际业务中仍然主导着视觉架构。作者认为 Vision Transformer 极高的计算代价是制约它们在端侧设备部署的障碍之一。当前也已经有一系列的工作致力于改善 Transformer 模型的计算成本,比如:Swin Transformer[1],PVT[2],Twins[3],CoAtNet[4] 和 MobileViT[5]。但是,这些工作普遍使用一些间接的指标来衡量计算的效率,比如参数量和计算量 (FLOPs)。但是这样的指标是比较片面的,次优的,且对于某些特定的硬件不敏感。这些间接的指标不能真正反映我们真正关心的直接指标,如速度或延迟。
本文作者认为,Transformer 模型应该能够处理部署过程中的环境不确定性,涉及到硬件感知特性,如内存访问成本和 I/O 吞吐量。因此,本文想要在设计 Transformer 模型时,直接将特定硬件上的 TensorRT 延迟视为效率指标,这提供了涉及计算能力、内存成本和带宽的更全面的反馈。TensorRT 已经成为实际场景中的一个通用且易于部署的解决方案,它有助于提供令人信服的面向硬件的指导。
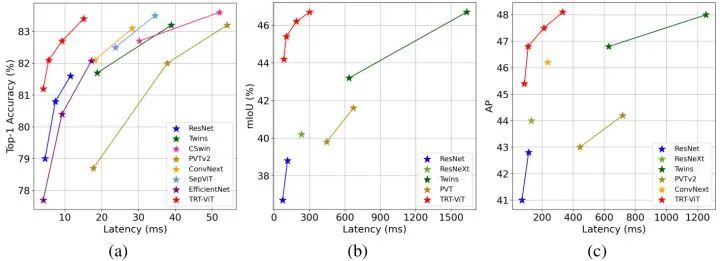
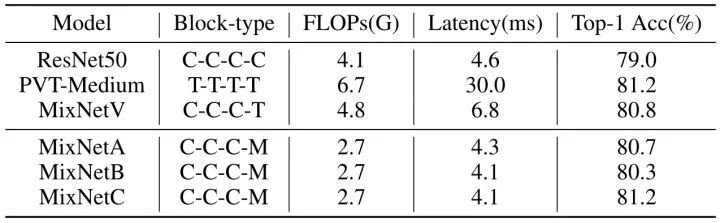
有了 TensorRT 这个直接的指导思路,作者在图4中重新绘制了几个现有模型的精度-效率权衡图。从这张图里面可以看出来 Transformer 的优点是性能好,而 CNN 的成功之处在于效率高。ResNet 在精度-延迟权衡下,仍然是最好的架构。例如,ResNet 使用11.7毫秒 (batch size= 8) 实现了 81.7% 的准确率。虽然 twins-pcpvt-s 实现了 83.4% 的准确率,但要达到这个目标需要39.8毫秒。这些观察促使作者提出一个问题:如何设计一个同时具备了 Transformer 精度,ResNet 效率的视觉模型?
作者在本文中探讨了一些设计方案,本文遵循 stage-to-block 的分层路线来设计视觉 Transformer 的架构。通过大量实验,作者总结了在 TensorRT 上设计高效混合模型的四个实用准则:
Stage-level: 后面的 stage 使用 Transformer 模块可以最大化性能-效率的权衡。 Stage-level: 后期 Stage 模型做深一些,即 Block 数更多,前期 Stage 模型做浅一些,即 Block 数更少,这样有助于提升性能。 Block-level: 一个 block 里面使用 Transformer 和 BottleNeck 的混合架构比仅使用 Transformer 更高效。 Block-level: 一个 block 里面先关注全局信息再关注局部信息有助于提升性能。
基于这四条原则,作者在本文中设计了一系列面向 TensorRT 的视觉 Transformer 模型 TRT-ViT,它们在图像分类的精度-延迟权衡方面优于现有的 ConvNet 和 Transformer 模型。比如在 82.7% 的 ImageNet-1k Top-1 准确率下,TRT-ViT 比 CSWin 快2.7倍,比 Twins 快2.0倍。
TensorRT 高效网络设计实用指南
作者的研究从在行业中非常流行的 ResNet 和 ViT 这两个模型开始。本文作者遵循 RepLKNet[6],使用计算密度 (Tera FLoating-point Operations Per Second, TeraFLOPS) 来量化其在硬件上的效率:

为了实现这一目标,作者在本文中提出了以下四点准则:
准则1:Transformer Block 在后期使用能够最大化精度-效率的权衡
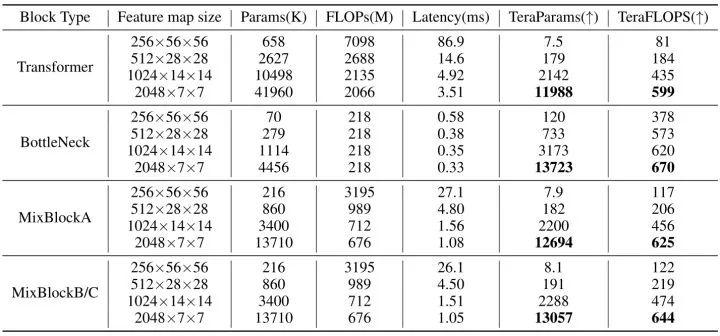
从上图5可以看得出来,BottleNeck 模块效率 (TeraFLOPS) 更高,而 Transformer 模块在 ImageNet 上具有更高的精度。但是当输入特征的尺寸逐渐减小时,二者的 TeraFLOPS 之间的差距在逐渐缩小。具体而言,当输入分辨率为 56×56 时,Transformer 的 TeraFLOPS 值仅为81,而 Bottleneck 的 TeraFLOPS 值则为378。但当分辨率降低到 7×7 时,Transformer 和 BottleNeck 的 TeraFLOPS 值几乎相等,分别为599和670。
以上结论意味着在整个模型的后期 (即特征分辨率较小的时期) 使用 Transformer Block 可以在提升性能的同时尽量带来更好的 TeraFLOPS。
遵循准则1的解决方案在图5中称为 MixNetV (MixNet Vanilla)。可以看到 MixNetV 比 ViT 更快,比 ResNet 更准确。
准则2:后期 Stage 模型做深一些,即 Block 数更多,前期 Stage 模型做浅一些,即 Block 数更少,这样有助于提升性能
人们普遍认为,参数越多,模型容量越高。人们希望开发出具有更多参数和更高效率的模型,作者定义参数密度如下式所示:
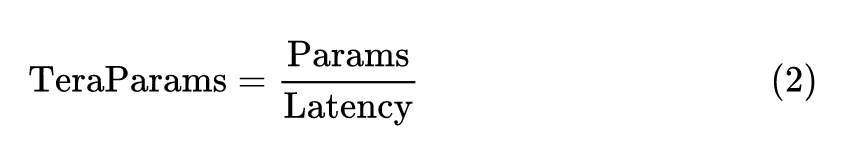
上式代表单位延迟下的参数量,这个值越大也就意味着模型参数的增加对于延迟的增加越不敏感,也是我们希望看到的。如上图5所示,各种模型的后期 Stage (特征分辨率较小) 这个值要比前期 Stage (特征分辨率较大) 大得多,比如 BottleNeck 在后期的 TeraParams 可以达到13723,但是前期却只有120,这就启发我们在模型的 Stage 的后期多堆叠一些块,在模型的 Stage 的前期少堆叠一些块。这样的方式能够在尽量不增加延迟的同时给模型带来更多的参数量,以提高其性能。
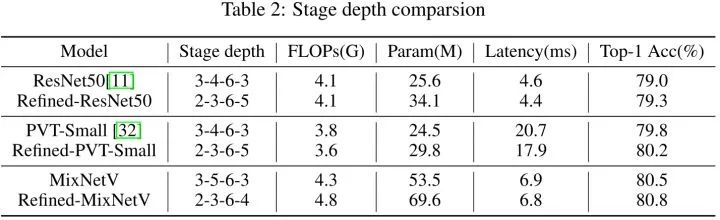
为了验证这一点,作者对 ResNet50 进行了相应的修改,并在下图6中调节各个 Stage 的深度之后 (Refined) 得到了性能和延迟的对比以及提供了实验结果。作者将 Stage1 和 Stage2 的深度分别从 3,4 减少到 2,3 ,同时将 Stage4 的阶段深度从3增加到5。可以看到 Refined-ResNet50 在ImageNet-1k 上以 0.3% 的最高精度优于 ResNet50,同时在 TensorRT 上略快。
以上实验说明后期 Stage 模型做深一些,即 Block 数更多,前期 Stage 模型做浅一些,即 Block 数更少,这样有助于在增加模型参数提升性能的同时不增加模型的延迟。
准则3:一个 block 里面使用 Transformer 和 BottleNeck 的混合架构比仅使用 Transformer 更高效
根据上述准则1和2,Refined-MixNetV 在效率上无法超越 ResNet。作者希望借助 BottleNeck 和 Transformer 模型各自的优势来提升模型的效率。设计了3种 Block 结构,如下图7所示。TRT-ViT Block 用在整个模型的最后一个 Stage 里面。
首先采用 Avg-Pool 进行下采样,再通过 1×1 卷积变换通道数。以 MixBlockA 为例,通过 Channel Split 把特征分为两部分并分别通过 Transformer 和 BottleNeck 层。MixBlockB 的 BottleNeck 和 Transformer 模块是顺序执行的,只是有残差进行 Concat 操作。如图5所示,与 Transformer 模块相比,MixBlock 的 TeraFLOPS 都显著增加,表明混合模块比 Transformer 模块更高效。此外,MixBlock 的 TeraParams 也更好,这表明它们有可能实现更好的性能。
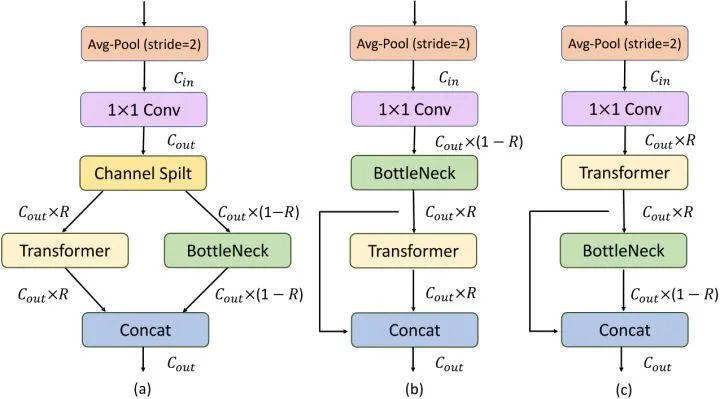
MixBlockA,MixblockB,以及其他相关模型的性能-效率对比如下图8所示。图中 C,T,M 分别代表卷积,Transformer 和 MixBlock。使用了 MixBlockA 和 MixblockB 的 MixNetA 和 B 都没超过 MixNetV 的性能。
准则4:一个 block 里面先关注全局信息再关注局部信息有助于提升性能
作者认为在 MixBlock 里面先使用 Transformer 模块提取全局信息再使用 BottleNeck 模块提取局部信息有助于提升性能。因此设计了 MixBlockC,切换 Transformer 模块和 BottleNeck 模块的顺序。如上图7所示。 值可以在 [0, 1] 之间调节。MixNetC 在准确性和 TRT 延迟方面都超过了 MixNetV,因此本文最终使用 MixNetC 作为最终结构,认为它实现了精度-效率权衡。
如下图9所示为最终的 TRT-ViT 模型架构,整个架构分为五个 Stage,只在最后一个 Stage 使用 MixBlockC,前期使用正常的卷积层。此外,TRT-ViT 采用了先浅后深的 Stage 模式,与 ResNet 中的 Stage 模式相比,前期 Stage 较浅,后期 Stage 较深。
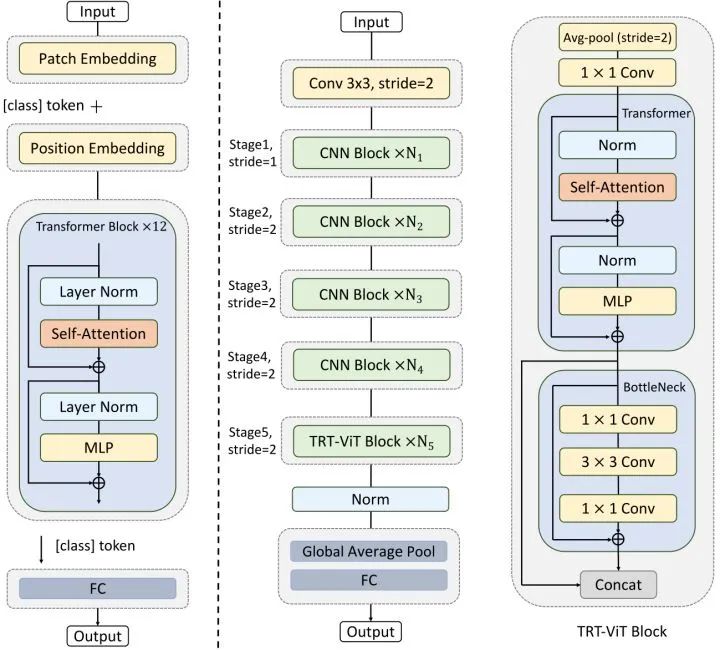
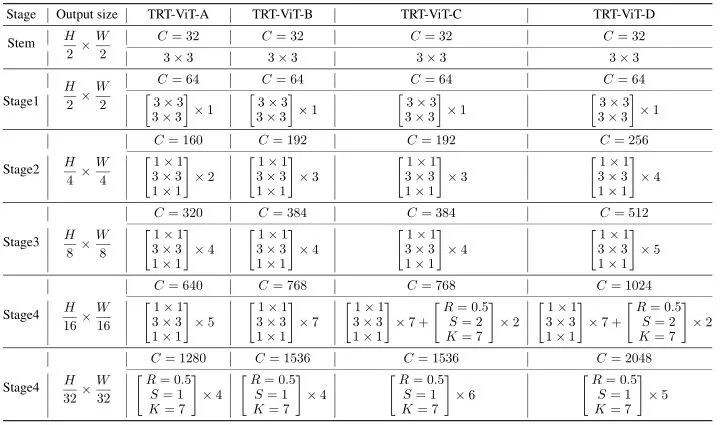
作者提供了4种 TRT-ViT 的变体,如下图10所示。 代表 MixBlockC 里面 BottleNeck 的 Kernel Size 大小, 代表缩减率。TRT-ViT-A/B/C/D 不同 Stage 的深度分别是 2-4-5-4, 3-4-7-4, 3-4-9-6, 4-5-9-5。对于归一化层和激活函数,BottleNeck Block 使用 BN 和 ReLU,而 Transformer Block 使用 LN 和 GeLU。
实验结果
ImageNet-1k 图像分类
实验设置: 300 Epoch,Batch size = 1024,优化器使用 AdamW,weight decay = 0.05,初始学习率 0.001,cosine 学习率衰减,linear warm-up strategy 30 Epoch。
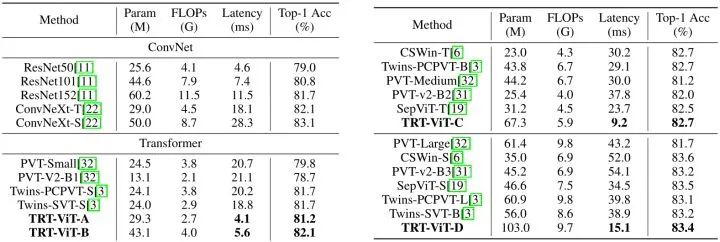
实验结果如下图11所示。TRT-ViT 在精度-延迟方面实现了最佳的权衡。比如 TRT-ViT-A 实现了 81.2% 的 Top-1 Accuracy,比 ResNet50 高 2.2%,延迟低约 10%。TRT-ViT-C 比 PVT-Medium 快 1.5%,速度快2.2倍。
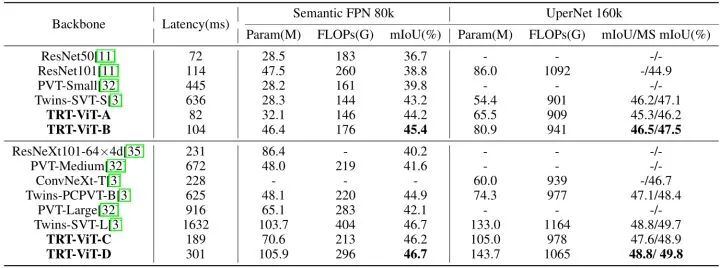
ADE20K 语义分割实验结果
使用 Semantic FPN 和 UperNet 的框架,骨干模型在 ImageNet-1k 上做预训练,并在 ADE20K 上微调。Semantic FPN 框架优化器使用 AdamW,weight decay 和 初始学习率都设为 0.0001,训练整个网络 80K iterations ,batch size 为16。UperNet 框架优化器使用 AdamW,初始学习率设为 0.00006,weight decay 设置为0.01,训练整个网络 80K iterations ,batch size 为16。如下图所示为实验结果,基于 Semantic FPN 框架,TRT-ViT-B 比 Twins-SVT-S 高出 2.2%,延迟降低约 83%。对于 UperNet 框架,TRT-ViT-C 比 ConvNeXt-T 实现了高 2.2% 的 MS mIoU,而推理时间减少了 17%。
COCO 目标检测任务实验结果
目标检测实验采用 Mask R-CNN 的框架,12 epochs (1×) 实验配置:优化器使用 AdamW,weight decay 为0.01,500 iterations warm-up,学习率分别在8和11 Epoch 处减半。36 epochs (3×) 实验配置:优化器使用 AdamW,weight decay 为0.05,学习率分别在27和33 Epoch 处减半。
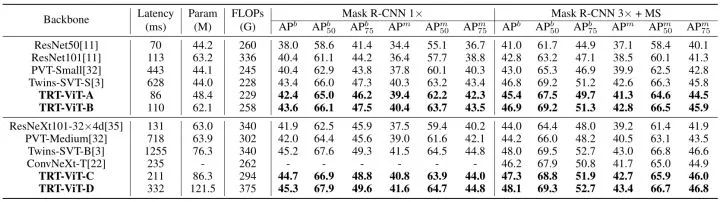
结果显示,在 1× schedule 的设置下,TRT-ViT-B 达到了与 Twins SVT-S 相当的性能,而推理速度提高了 4.7倍。在 3× schedule 的设置下,TRT-ViT-C 实现了 47.3 AP,比 ConvNeXt-T 高1.1,但延迟更低。
另外一个值得注意的现象是:当迁移到下游任务时,Transformer Backbone 比 CNN Backbone 更加耗时。例如,当从图像分类转移到目标检测时,Twins-SVT-B 的推理延迟增加了32倍 (从 38.9ms 增加到 1255ms),而ResNet101 的推理延迟只增加了15倍 (从 7.4ms 增加到 113ms)。而 TRT-ViT 在迁移到下游任务时仍然表现出类似 ResNet 的效率,这意味着 TRT-ViT 可以弥补 Transformer 和 CNN Backbone 之间的差距。
总结
本文研究在设计 Transformer 模型时,直接将特定硬件上的 TensorRT 延迟视为效率指标,这提供了涉及计算能力、内存成本和带宽的更全面的反馈。作者在本文中探讨了一些设计方案,本文遵循 stage-to-block 的分层路线来设计视觉 Transformer 的架构。通过大量实验,作者总结了在 TensorRT 上设计高效混合模型的四个实用准则。该研究为科学研究走向工业部署指出了一条可行的道路,大大缩小了实验室研究成果与真实场景部署模型之间的差距。
参考
^Swin transformer: Hierarchical vision transformer using shifted windows ^Pyramid vision transformer: A versatile backbone for dense prediction without convolutions ^Twins: Revisiting the design of spatial attention in vision transformers ^Coatnet: Marrying convolution and attention for all data sizes ^Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer ^Scaling up your kernels to 31x31: Revisiting large kernel design in cnns
公众号后台回复“数据集”获取90+深度学习数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选
