 大邓和他的Python
大邓和他的Python





主题分析与挖掘是当前NLP处理的一个典型范式,广泛应用于文本聚类、文本表示、文本分类等场景当中。
在实践环节,强大的主题建模工具Gensim: Topic modelling for humans更是提供了十分方便的调用接口,根据约定好的数据格式,进行分词、cbow转换、tfidf转换,然后送入模型,可以快速训练得到适配业务的主题模型。
在理论环节,LDA(Latent Dirichlet Allocation),是Blei等人于2003年提出的基于概率模型的主题模型算法,用来识别大规模文档集或语料库中的潜在隐藏的主题信息,该方法假设每个词是由背后的一个潜在隐藏的主题中抽取出来,每篇文章是由多个主题混合混合而成,并且每个主题可以由多个词的概率表征。
因此,对于我们看到的每篇文档,LDA 定义了如下生成过程:
首先,对每一篇文档,从主题分布中抽取一个主题;
其次,从上述被抽到的主题所对应的单词分布中抽取一个单词;
最后,重复上述过程直至遍历文档中的每一个单词;
通过吉布斯采样和狄利克雷分布,分别估计出文档-主题概率,主题-概率后,既可以产出多种有意义的结果。
而随着具体业务的变化,LDA后续陆续出现了变体应用类型,包括适用于作者主题分析的ATM模型(Author-Topic Model)、 加入时许的动态主题模型DTM(Dynamic Topic Models)等。
| 模型类型 | 功能含义 | 应用场景 |
|---|---|---|
| LDA模型(Latent Dirichlet Allocation) | 一般主题模型,用于主题分析 | 文章主题偏好、单词的主题偏好、主题内容展示、主题内容矩阵 |
| ATM模型(Author-Topic Model) | 加入监督的’作者’,每个作者对不同主题的偏好 | 作者主题偏好、词语主题偏好、相似作者推荐、可视化 |
| DTM模型(Dynamic Topic Models) | 加入时间因素,不同主题会随着时间变动 | 时间-主题词条矩阵、主题-时间词条矩阵、文档主题偏好、新文档预测、跨时间+主题属性的文档相似性 |
这是一个比较有意思的话题,在舆情监控领域使用较多,本文主要介绍LDA主题模型的几个典型的变体,并对其应用场景、具体功能、代码实现以及开源工具进行论述。
一、使用LDA进行文本主题建模与聚类
LDA(Latent Dirichlet Allocation),通过对文本进行分词,并进行LDA训练,可以得到指定k个主题下的文档聚类结果,产生文档的主题分布、词语的主题分布等概率统计数据,基于这些数据,可以支撑多种应用。
论文地址:https://www.researchgate.net/publication/2917336_Journal_of_Machine_Learning_Research_3_2003_993-1022_Submitted_202_Published_103_Latent_Dirichlet_Allocation
例如,下图展示了文献1在基于Sogou新闻语料的LDA实验结果,得到了20个主题下的词语分布。
1、应用场景
| 功能 | 代表例子 |
|---|---|
| 每个主题对应的主题词 | (0, '0.143*"苹果" + 0.077*"水果" + 0.070*"树上" + 0.058*"电脑" + 0.048*"叶子"') |
| 每个主题对应的文档集合 | [1234,456,756,4545,1245] |
| 某个词汇属于特定主题的几率 | [('水果', 0.03219079), ('公司', 0.056897775)] |
| 新旧文档主题类别,取概率最大主题 | [('水果', 0.80287796), ('公司', 0.19712202)] |
| 文档主题表示(维度大小为主题数目,值为对应概率),可额用于文本分类 | [0,12323, 0.4564565,0.45645,......] |
| 词语对应的主题embedding:Topic Word Embedding | 训练文档中每个词会分配一个主题,根据主题权重,生成向量,可以一定程度上解决一词多义问题。 |
针对需要建模的文本,进行分词、cbow转换、tfidf转换,设定需要聚类的主题数目,调用gensim提供的接口,即可完成训练。
from gensim import corpora, models
def train_ldamodel(num_topics, data):
train = data
dictionary = corpora.Dictionary(train)
corpus = [dictionary.doc2bow(text) for text in train]
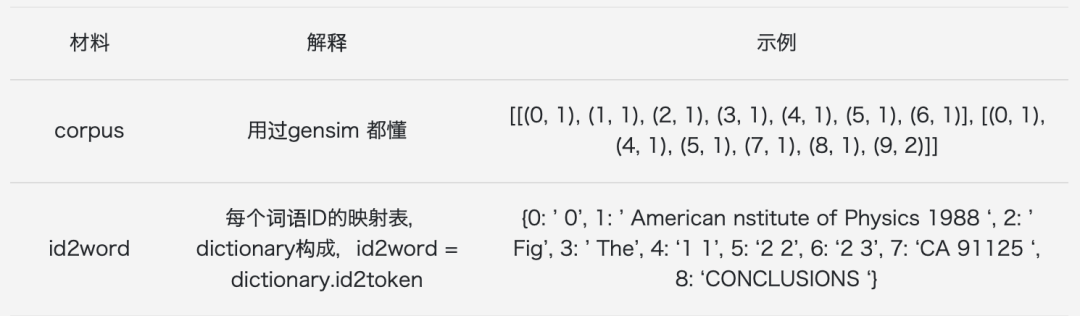
# corpus里面的存储格式(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1)
corpus_tfidf=models.TfidfModel(corpus)[corpus]
# corpus_tfidf将corpus表示为tfidf形式,可以有效提升性能;
lda = models.LdaModel(corpus=corpus_tfidf, id2word=dictionary, num_topics=num_topics, passes=10)
return lda, dictionary
二、使用ATM模型进行作者写作主题分析
ATM模型(author-topic model)是LDA主题模型(Latent Dirichlet Allocation )的拓展,能对某个语料库中作者的写作主题进行分析,找出某个作家的写作主题倾向,以及找到具有同样写作倾向的作家。
在传统LDA模型的基础上,加入author的概念。传统LDA模型,是描述文档和词(文档组成元素)之前的关系,这种关系用主题(topic)来衔接和描述。这篇文章加入author的概念,即一篇文章可能有多个author,一个author可能有多个文章,词是文章的组成元素,那么,ATM模型旧通过topic描述了author和词之间的关系。
论文原文:https://arxiv.org/abs/1207.4169
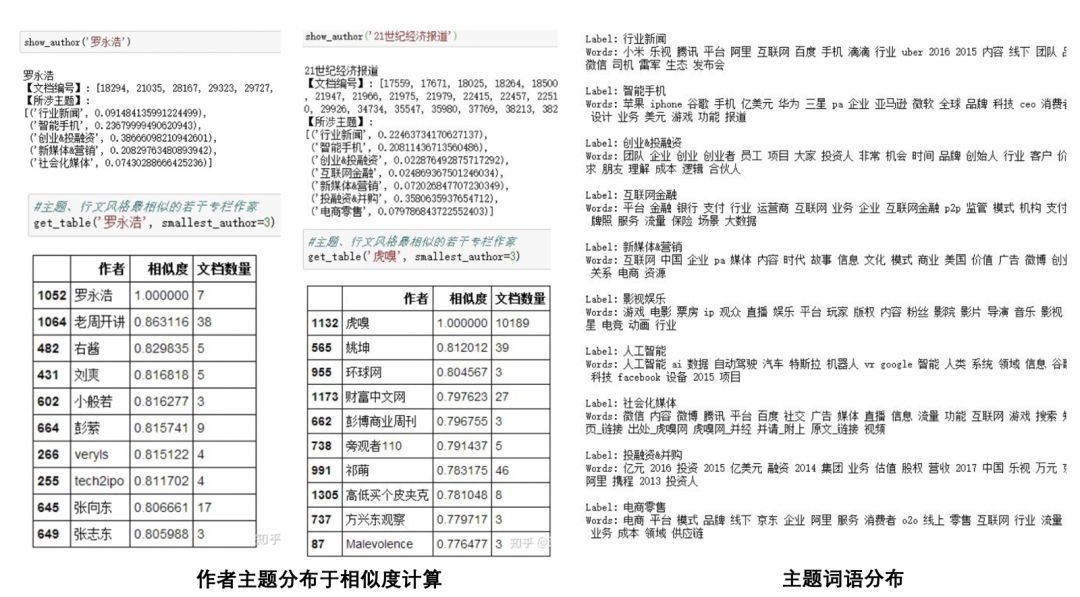
例如,下图展示了文献3中使用虎嗅网4W+文章得到的ATM建模结果。
1、应用场景
| 功能 | 代表例子 |
|---|---|
| 主题对应的主题词 | (0, '0.143*"苹果" + 0.077*"水果" + 0.070*"树上" + 0.058*"电脑" + 0.048*"叶子"') |
| 作者对应的主题分布 | [1234,456,756,4545,1245] |
| 作者最相似的作者集合 | [('水果', 0.03219079), ('公司', 0.056897775)] |
| 作者的向量表示 | [('水果', 0.80287796), ('公司', 0.19712202)] |
2、具体实现
1)关键输入
2)代码实现
def train_atmmodel(datas):
for data in datas:
author = data[0]
text = data[1]
wds = cut_text(text)
clean_txt = ' '.join(wds)
docs.add(clean_txt)
doc = clean_txt
if doc not in doc_url_dict:
doc_url_dict[doc] = [url]
else:
doc_url_dict[doc].append(url)
if author not in author_doc_dict:
author_doc_dict[author] = [clean_txt]
else:
author_doc_dict[author].append(clean_txt)
print("building dictionary......")
docs = list(docs)
doc_id_dict = {}
for idx, doc in enumerate(docs):
doc_id_dict[idx] = doc + '@' + ';'.join(doc_url_dict.get(doc))
## 构建dictionary
doc_wds = [doc.split(' ') for doc in docs]
dictionary = Dictionary(doc_wds)
print("building corpus......")
corpus = [dictionary.doc2bow(doc) for doc in doc_wds]
print("building author2doc......")
author2doc = dict()
doc_dict = {doc:i for i, doc in enumerate(docs)}
for author, docs in author_doc_dict.items():
author2doc[author] = [doc_dict.get(i) for i in docs]
corpus, dictionary, author2doc, doc_id_dict = prepare_data()
corpus_tfidf=models.TfidfModel(corpus)[corpus]
model = AuthorTopicModel(corpus=corpus_tfidf, num_topics=self.num_topics, id2word=dict(dictionary.items()), author2doc=author2doc, passes=10, eval_every=0, chunksize=1000, iterations=1, random_state=1)
return model
三、使用DTM模型进行主题时序演化分析
DTM模型,Dynamic Topic Model,来源于Blei于2006发表在第23届机器学习国际会议上的论文与先前的Latent Dirichlate Allocation(LDA)模型有所不同,DTM引入了时间因素,从而刻画语料库主题随时间的动态演化。
在LDA模型中,给定语料库中的所有文档,并无时间先后的差别,与词袋模型(bag-of-words)中的词无先后之分类似,在建模的过程中认为整个语料库中的K个主题是固定的,在DTM模型中,文档有了时间属性,具有先后之分。DTM认为,在不同时期,主题是随时间动态演化的。
论文原文:https://dl.acm.org/doi/10.1145/1143844.1143859
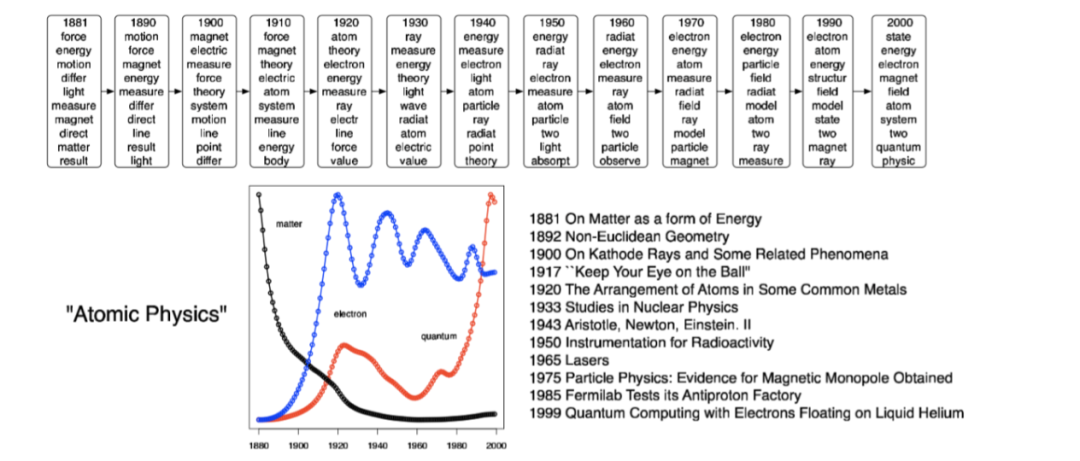
例如,通过分析由Ed Edi-son于1880年创立的Jour-nal Science的100多年的OCR文章来证明其适用性,在实现上,文章按年份分组,每年的艺术作品都来自于去年主题演变而来的一系列主题,如下图所示:
1、应用场景
| 功能 | 代表例子 |
|---|---|
| 不同时期的各个主题的情况 | (u'blair', 0.0062483544617615841),(u'labour', 0.0059223974769828398)] |
| 每个主题的各个时期主题重要词 | [(u'blair', 0.0061528696567048772), (u'labour', 0.0054905202853533239)] |
| 不同文档主题偏好 | [ 5.46298825e-05 2.18468637e-01 5.46298825e-05 5.46298825e-05 7.81367474e-01] |
| 新文档主题预测 | [ 0.00110497 0.00110497 0.00110497 0.00110497 0.99558011] |
| 跨时间+主题属性的文档相似性 | 先把文档dictionary.doc2bow矢量化,然后变成文档主题偏好向量(1*5),然后根据两个文档的主题偏好向量用hellinger距离进行求相似。 |
2、具体实现
1)关键输入:

2)代码实现:
def train_dtmmodel():
corpus, dictionary = prepare_data()
a = [i for i in range(len(corpus))]
## 每个均分为1000个文档,因为没有时间信息,调用time_slice方法进行处理
step = 1000
time_slice = [len(a[i:i+step]) for i in range(0,len(a),step)]
model = LdaSeqModel(corpus=corpus, time_slice=time_slice, num_topics=self.num_topics, chunksize=1)
return model
四、基于困惑度的最佳主题数确定
但我们看到最后,会发现,无论是LDA,还是ATM,都会遇到一个最佳主题数topic_number的设定问题。
例如,援引知乎中的一个问题:https://www.zhihu.com/question/32286630
怎么确定LDA的topic个数?面试时,由于之前用过LDA做推荐,面试官就问怎么确定LDA的topic个数,我就实话实说是自己拍的,面试官就一个劲问“你觉得合理吗?你难道就这么草率吗?”搞得我无所适从,请问有哪些方法确定LDA的topic个数呢?
困惑度perplexity是常用的一个手段。
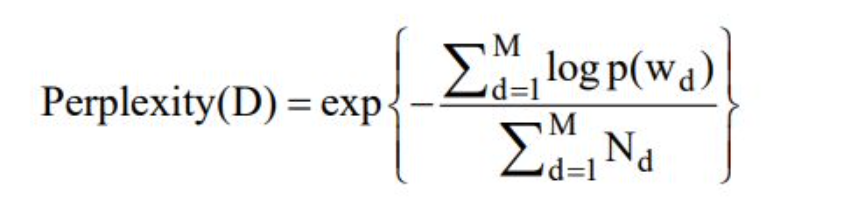
其中,D表示语料库中的测试集,M偏文档,Nd表示每篇文档d中的单词数,Wd表示文档d中的词,p(Wd)即文档中Wd的产生概率。
import math
def perplexity(ldamodel, testset, dictionary, size_dictionary, num_topics):
prep = 0.0
prob_doc_sum = 0.0
topic_word_list = []
for topic_id in range(num_topics):
topic_word = ldamodel.show_topic(topic_id, size_dictionary)
dic = {}
for word, probability in topic_word:
dic[word] = probability
topic_word_list.append(dic)
doc_topics_ist = []
for doc in testset:
doc_topics_ist.append(ldamodel.get_document_topics(doc, minimum_probability=0))
testset_word_num = 0
for i in range(len(testset)):
prob_doc = 0.0 # the probablity of the doc
doc = testset[i]
doc_word_num = 0
for word_id, num in dict(doc).items():
prob_word = 0.0
doc_word_num += num
word = dictionary[word_id]
for topic_id in range(num_topics):
# cal p(w) : p(w) = sumz(p(z)*p(w|z))
prob_topic = doc_topics_ist[i][topic_id][1]
prob_topic_word = topic_word_list[topic_id][word]
prob_word += prob_topic * prob_topic_word
prob_doc += math.log(prob_word) # p(d) = sum(log(p(w)))
prob_doc_sum += prob_doc
testset_word_num += doc_word_num
prep = math.exp(-prob_doc_sum / testset_word_num) # perplexity = exp(-sum(p(d)/sum(Nd))
return prep
五、开源主题模型可视化工具
实际上,主题结果与可视化工具进行搭配能够最大化的发挥出其效果,pyLDAvis是python中的一个对LDA主题模型进行交互可视化的库,可以将主题模型建模后的结果,制作成一个网页交互版的结果分析工具。
pyLDAvis在可视化呈现中以可视化的方式,逐步展示每个主题的意义、每个主题在总语料库的比重以及主题之间的关联信息。
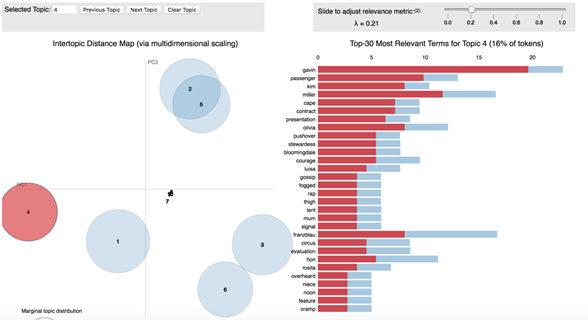
地址:https://github.com/bmabey/pyLDAvis
总结
本文主要介绍LDA主题模型的几个典型的变体,并对其应用场景、具体功能、代码实现以及开源工具进行论述。
lda最大的意义在于从统计的视角,给出了一个从文档、主题、词语之间的概率计算方法,从而为文本的表示、语义建模奠定了基础。正如文中所说的,可以支撑多种业务下的场景落地可能。
不过,主题数的确定、基于主题,再进行聚类、主题名称生成的工作依旧必不可少。
本文受到如下参考文献的启发,并做了参考,感谢前人的整理。
参考文献
1、https://www.cnblogs.com/chenbjin/p/5638904.html
2、https://www.heywhale.com/mw/project/621bb7c17e72dd00175e25e5
3、https://zhuanlan.zhihu.com/p/51556982
4、https://cloud.tencent.com/developer/article/1435976
5、https://blog.csdn.net/Lyric1/article/details/96331805
6、https://blog.csdn.net/xceman1997/article/details/50334853
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、NLP实践相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。


