 大数据那些事
大数据那些事




本手册配套参考视频地址:https://www.bilibili.com/video/BV15S4y1h7Kt
Doris使用手册——上篇可点击图片查看

第5章 查询
5.1 查询设置
5.1.1 增大内存
一个查询任务,在单个 BE 节点上默认使用不超过 2GB 内存,内存不够时, 查询可能会出现‘Memory limit exceeded’。
SHOW VARIABLES LIKE "%mem_limit%";
exec_mem_limit 的单位是 byte,可以通过 SET 命令改变 exec_mem_limit 的值。如改为 8GB。
SET exec_mem_limit = 8589934592;
上述设置仅仅在当前session有效, 如果想永久有效, 需要添加 global 参数。
SET GLOBAL exec_mem_limit = 8589934592;
5.1.2 修改超时时间
doris默认最长查询时间为300s, 如果仍然未完成, 会被cancel掉,查看配置:
SHOW VARIABLES LIKE "%query_timeout%";
可以修改为60s
SET query_timeout = 60;
同样, 如果需要全局生效需要添加参数global。
set global query_timeout = 60;
当前超时的检查间隔为 5 秒,所以小于 5 秒的超时不会太准确。
5.1.3 查询重试和高可用
当部署多个 FE 节点时,用户可以在多个 FE 之上部署负载均衡层来实现 Doris 的高可用。
5.1.3.1 代码方式
自己在应用层代码进行重试和负载均衡。比如发现一个连接挂掉,就自动在其他连接上进行重试。应用层代码重试需要应用自己配置多个doris前端节点地址。
5.1.3.2 JDBC Connector
如果使用mysql jdbc connector来连接Doris,可以使用jdbc的自动重试机制:
jdbc:mysql://[host1][:port1],[host2][:port2][,[host3][:port3]]...[/[database]][?propertyName1=propertyValue1[&propertyName2=propertyValue2]...]
5.1.3.3 ProxySQL 方式
ProxySQL是灵活强大的MySQL代理层, 是一个能实实在在用在生产环境的MySQL中间件,可以实现读写分离,支持Query 路由功能,支持动态指定某个SQL进行cache,支持动态加载配置、故障切换和一些SQL的过滤功能。
Doris的FE进程负责接收用户连接和查询请求,其本身是可以横向扩展且高可用的,但是需要用户在多个FE上架设一层proxy,来实现自动的连接负载均衡。
安装ProxySQL (yum方式)
配置yum源
# vim /etc/yum.repos.d/proxysql.repo
[proxysql_repo]
name= ProxySQL YUM repository
baseurl=http://repo.proxysql.com/ProxySQL/proxysql-1.4.x/centos/\$releasever
gpgcheck=1
gpgkey=http://repo.proxysql.com/ProxySQL/repo_pub_key
执行安装
# yum clean all
# yum makecache
# yum -y install proxysql
查看版本
# proxysql --version
设置开机自启动
# systemctl enable proxysql
# systemctl start proxysql
# systemctl status proxysql
启动后会监听两个端口, 默认为6032和6033。6032端口是ProxySQL的管理端口,6033是ProxySQL对外提供服务的端口 (即连接到转发后端的真正数据库的转发端口)。
# netstat -tunlpProxySQL配置
ProxySQL有配置文件
/etc/proxysql.cnf和配置数据库文件/var/lib/proxysql/proxysql.db。这里需要特别注意:如果存在如果存在"proxysql.db"文件(在/var/lib/proxysql目录下),则 ProxySQL 服务只有在第一次启动时才会去读取proxysql.cnf文件并解析;后面启动会就不会读取proxysql.cnf文件了!如果想要让proxysql.cnf 文件里的配置在重启 proxysql 服务后生效(即想要让 proxysql 重启时读取并解析 proxysql.cnf配置文件),则需要先删除 /var/lib/proxysql/proxysql.db数据库文件,然后再重启 proxysql 服务。这样就相当于初始化启动 proxysql 服务了,会再次生产一个纯净的 proxysql.db 数据库文件(如果之前配置了 proxysql 相关路由规则等,则就会被抹掉)查看及修改配置文件:主要是几个参数,在下面已经注释出来了,可以根据自己的需要进行修改
# vim /etc/proxysql.cnf
datadir="/var/lib/proxysql" #数据目录
admin_variables=
{
admin_credentials="admin:admin" #连接管理端的用户名与密码
mysql_ifaces="0.0.0.0:6032" #管理端口,用来连接proxysql的管理数据库
}
mysql_variables=
{
threads=4 #指定转发端口开启的线程数量
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033" #指定转发端口,用于连接后端mysql数据库的,相当于代理作用
default_schema="information_schema"
stacksize=1048576
server_version="5.7.28" #指定后端mysql的版本
connect_timeout_server=3000
monitor_username="monitor"
monitor_password="monitor"
monitor_history=600000
monitor_connect_interval=60000
monitor_ping_interval=10000
monitor_read_only_interval=1500
monitor_read_only_timeout=500
ping_interval_server_msec=120000
ping_timeout_server=500
commands_stats=true
sessions_sort=true
connect_retries_on_failure=10
}
mysql_servers =
(
)
mysql_users:
(
)
mysql_query_rules:
(
)
scheduler=
(
)
mysql_replication_hostgroups=
(
)连接ProxySQL管理端口测试
# mysql -h 127.0.0.1 -P 6032 -u admin -p
查看main库(默认登陆后即在此库)的global_variables表信息
show databases;
use main;
show tables;ProxySQL 配置后端 Doris FE
使用 insert 语句添加主机到 mysql_servers 表中,其中:hostgroup_id 为10表示写组,为20表示读组,我们这里不需要读写分离,无所谓随便设置哪一个都可以。
mysql -u admin -p admin -P 6032 -h 127.0.0.1
insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.8.101',9030);
insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.8.102',9030);
insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.8.103',9030);
如果在插入过程中,出现报错:
ERROR 1045 (#2800): UNIQUE constraint failed: mysql_servers.hostgroup_id, mysql_servers.hostname, mysql_servers.port
说明可能之前就已经定义了其他配置,可以清空这张表 或者 删除对应host的配置
select * from mysql_servers;
delete from mysql_servers;
查看这3个节点是否插入成功,以及它们的状态。
select * from mysql_servers\G;
如上修改后,加载到RUNTIME,并保存到disk,下面两步非常重要,不然退出以后配置信息就没了,必须保存
load mysql servers to runtime;
save mysql servers to disk;监控Doris FE节点配置
添doris fe 节点之后,还需要监控这些后端节点。对于后端多个FE高可用负载均衡环境来说,这是必须的,因为 ProxySQL 需要通过每个节点的 read_only 值来自动调整它们是属于读组还是写组。
首先在后端master主数据节点上创建一个用于监控的用户名。
在doris fe master主数据库节点行执行:
# mysql -h hadoop1 -P 9030 -u root -p
create user monitor@'192.168.8.%' identified by 'monitor';
grant ADMIN_PRIV on *.* to monitor@'192.168.8.%';
然后回到mysql-proxy代理层节点上配置监控
# mysql -uadmin -padmin -P6032 -h127.0.0.1
set mysql-monitor_username='monitor';
set mysql-monitor_password='monitor';
修改后,加载到RUNTIME,并保存到disk
load mysql variables to runtime;
save mysql variables to disk;
验证监控结果:ProxySQL监控模块的指标都保存在monitor库的log表中。
以下是连接是否正常的监控(对connect指标的监控):
注意:可能会有很多connect_error,这是因为没有配置监控信息时的错误,配置后如果connect_error的结果为NULL则表示正常。
select * from mysql_server_connect_log;
查看心跳信息的监控(对ping指标的监控)
select * from mysql_server_ping_log;
查看read_only日志此时也为空(正常来说,新环境配置时,这个只读日志是为空的)
select * from mysql_server_read_only_log;
load mysql servers to runtime;
save mysql servers to disk;
查看结果
select hostgroup_id,hostname,port,status,weight from mysql_servers;配置Doris用户
上面的所有配置都是关于后端 Doris FE节点的,现在可以配置关于SQL语句的,包括:发送SQL语句的用户、SQL语句的路由规则、SQL查询的缓存、SQL语句的重写等等。
本小节是SQL请求所使用的用户配置,例如root用户。这要求我们需要先在后端Doris FE节点添加好相关用户。这里以root和doris两个用户名为例。
首先,在Doris FE master主数据库节点上执行:
# mysql -h hadoop1 -P 9030 -u root -p
root用户已经存在,直接创建doris用户:
create user doris@'%' identified by 'doris';
grant ADMIN_PRIV on *.* to doris@'%';
回到mysql-proxy代理层节点,配置mysql_users表,将刚才的两个用户添加到该表中。
insert into mysql_users(username,password,default_hostgroup) values('root','000000',10);
insert into mysql_users(username,password,default_hostgroup) values('doris','doris',10);
加载用户到运行环境中,并将用户信息保存到磁盘
load mysql users to runtime;
save mysql users to disk;
select * from mysql_users\G
只有active=1的用户才是有效的用户。确保transaction_persistent为1:
update mysql_users set transaction_persistent=1 where username='root';
update mysql_users set transaction_persistent=1 where username='doris';
load mysql users to runtime;
save mysql users to disk;
这里不需要读写分离,将这两个参数设为true:
UPDATE global_variables SET variable_value='true' WHERE variable_name='mysql-forward_autocommit';
UPDATE global_variables SET variable_value='true' WHERE variable_name='mysql-autocommit_false_is_transaction';
LOAD MYSQL VARIABLES TO RUNTIME;
SAVE MYSQL VARIABLES TO DISK;这样就可以通过sql客户端,使用doris的用户名密码去连接了ProxySQL了
通过 ProxySQL 连接 Doris 进行测试
分别使用 root 用户和 doris 用户测试下它们是否能路由到默认的
hostgroup_id=10(它是一个写组)读数据。下面是通过转发端口6033连接的,连接的是转发到后端真正的数据库。mysql -udoris -pdoris -P6033 -h hadoop1 -e "show databases;"到此就结束了,可以用MySQL客户端,JDBC等任何连接MySQL的方式连接ProxySQL 去操作doris了。
验证:将hadoop1的fe停止,再执行
mysql -udoris -pdoris -P6033 -h hadoop1 -e "show databases;"能够正常使用。
5.2 简单查询
简单查询
SELECT * FROM example_site_visit LIMIT 3;
SELECT * FROM example_site_visit ORDER BY user_id;Join
SELECT SUM(example_site_visit.cost) FROM example_site_visit
JOIN example_site_visit2
WHERE example_site_visit.user_id = example_site_visit2.user_id;
select
example_site_visit.user_id,
sum(example_site_visit.cost)
from example_site_visit join example_site_visit2
where example_site_visit.user_id = example_site_visit2.user_id
group by example_site_visit.user_id;子查询
SELECT SUM(cost) FROM example_site_visit2 WHERE user_id IN (SELECT user_id FROM example_site_visit WHERE user_id > 10003);
5.3 Join查询
5.3.1 Broadcast Join
系统默认实现Join的方式,是将小表进行条件过滤后,将其广播到大表所在的各个节点上,形成一个内存Hash表,然后流式读出大表的数据进行Hash Join。
Doris会自动尝试进行 Broadcast Join,如果预估小表过大则会自动切换至 Shuffle Join。注意,如果此时显式指定了 Broadcast Join 也会自动切换至 Shuffle Join。
默认使用Broadcast Join:
EXPLAIN SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN example_site_visit2
WHERE example_site_visit.city = example_site_visit2.city;显式使用Broadcast Join:
EXPLAIN SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN [broadcast] example_site_visit2
WHERE example_site_visit.city = example_site_visit2.city;
5.3.2 Shuffle Join(Partitioned Join)
如果当小表过滤后的数据量无法放入内存的话,此时 Join 将无法完成,通常的报错应该是首先造成内存超限。可以显式指定 Shuffle Join,也被称作 Partitioned Join。即将小表和大表都按照 Join 的 key 进行 Hash,然后进行分布式的 Join。这个对内存的消耗就会分摊到集群的所有计算节点上。
SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN [shuffle] example_site_visit2
WHERE example_site_visit.city = example_site_visit2.city;
5.3.3 Colocation Join
Colocation Join是在Doris0.9版本引入的功能,旨在为Join查询提供本性优化,来减少数据在节点上的传输耗时,加速查询。
5.3.3.1 原理
Colocation Join功能,是将一组拥有CGS 的表组成一个CG。保证这些表对应的数据分片会落在同一个be节点上,那么使得两表再进行join的时候,可以通过本地数据进行直接join,减少数据在节点之间的网络传输时间。
Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。在同一个 Group 内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布。
Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息。包括分桶列类型,分桶数以及副本数等。
一个表的数据,最终会根据分桶列值 Hash、对桶数取模的后落在某一个分桶内。假设一个 Table 的分桶数为 8,则共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 个分桶(Bucket),我们称这样一个序列为一个 BucketsSequence。每个 Bucket 内会有一个或多个数据分片(Tablet)。当表为单分区表时,一个 Bucket 内仅有一个 Tablet。如果是多分区表,则会有多个。
使用限制:
建表时两张表的分桶列的类型和数量需要完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
5.3.3.2 使用
建两张表,分桶列都为int类型,且桶的个数都是8个。副本数都为默认副本数。
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);编写查询语句,并查看执行计划
explain SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);HASH JOIN处colocate 显示为true,代表优化成功。
查看Group
SHOW PROC '/colocation_group';当Group中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过 DROP TABLE命令删除后,会在回收站默认停留一天的时间后,再删除),该Group也会被自动删除。
修改表 Colocate Group属性
ALTER TABLE tbl SET ("colocate_with" = "group2");如果该表之前没有指定过Group,则该命令检查Schema,并将该表加入到该Group(Group不存在则会创建)。
如果该表之前有指定其他Group,则该命令会先将该表从原有Group中移除,并加入新 Group(Group不存在则会创建)。
删除表的Colocation属性
ALTER TABLE tbl SET ("colocate_with" = "");其他操作
当对一个具有Colocation属性的表进行增加分区(ADD PARTITION)、修改副本数时,Doris 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝。
5.3.4 Bucket Shuffle Join
Bucket Shuffle Join是在 Doris 0.14 版本中正式加入的新功能。旨在为某些Join查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询。
5.3.4.1 原理
Doris支持的常规分布式Join方式包括了shuffle join和broadcast join。这两种join都会导致不小的网络开销:
举个例子,当前存在A表与B表的Join查询,它的Join方式为HashJoin,不同Join类型的开销如下:
Broadcast Join: 如果根据数据分布,查询规划出A表有3个执行的HashJoinNode,那么需要将B表全量的发送到3个HashJoinNode,那么它的网络开销是3B,它的内存开销也是3B。
Shuffle Join: Shuffle Join会将A,B两张表的数据根据哈希计算分散到集群的节点之中,所以它的网络开销为 A + B,内存开销为B。
在FE之中保存了Doris每个表的数据分布信息,如果join语句命中了表的数据分布列,使用数据分布信息来减少join语句的网络与内存开销,这就是Bucket Shuffle Join,原理如下图:
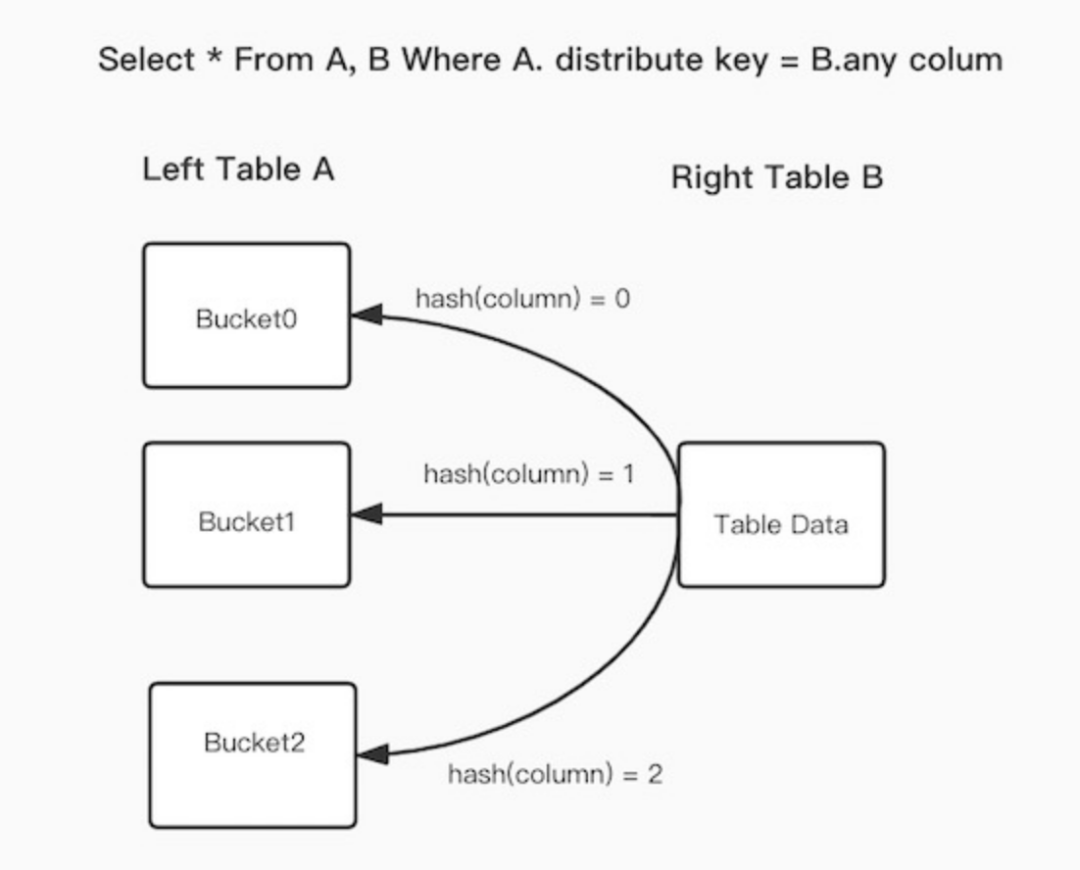
SQL语句为 A表 join B表,并且join的等值表达式命中了A的数据分布列。而Bucket Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储计算节点。Bucket Shuffle Join开销如下:
网络开销:B < min(3B, A + B)
内存开销:B <= min(3B, B)
可见,相比于Broadcast Join与Shuffle Join, Bucket Shuffle Join有着较为明显的性能优势。减少数据在节点间的传输耗时和Join时的内存开销。相对于Doris原有的Join方式,它有着下面的优点:
首先,Bucket-Shuffle-Join降低了网络与内存开销,使一些Join查询具有了更好的性能。尤其是当FE能够执行左表的分区裁剪与桶裁剪时。
其次,同时与Colocate Join不同,它对于表的数据分布方式并没有侵入性,这对于用户来说是透明的。对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题。
最后,它可以为Join Reorder提供更多可能的优化空间。
5.3.4.2 使用
设置Session变量,从0.14版本开始默认为true
show variables like '%bucket_shuffle_join%';
set enable_bucket_shuffle_join = true;在FE进行分布式查询规划时,优先选择的顺序为 Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。但是如果用户显式hint了Join的类型,如:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;则上述的选择优先顺序则不生效。
通过explain查看join类型
EXPLAIN SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN example_site_visit2
ON example_site_visit.user_id = example_site_visit2.user_id;在Join类型之中会指明使用的Join方式为:BUCKET_SHUFFLE。
5.3.4.3 注意事项
Bucket Shuffle Join只生效于Join条件为等值的场景,原因与Colocate Join类似,它们都依赖hash来计算确定的数据分布。
在等值Join条件之中包含两张表的分桶列,当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join。
由于不同的数据类型的hash值计算结果不同,所以Bucket Shuffle Join要求左表的分桶列的类型与右表等值join列的类型需要保持一致,否则无法进行对应的规划。
Bucket Shuffle Join只作用于Doris原生的OLAP表,对于ODBC,MySQL,ES等外表,当其作为左表时是无法规划生效的。
对于分区表,由于每一个分区的数据分布规则可能不同,所以Bucket Shuffle Join只能保证左表为单分区时生效。所以在SQL执行之中,需要尽量使用where条件使分区裁剪的策略能够生效。
假如左表为Colocate的表,那么它每个分区的数据分布规则是确定的,Bucket Shuffle Join能在Colocate表上表现更好。
5.3.5 Runtime Filter
Runtime Filter 是在 Doris 0.15 版本中正式加入的新功能。旨在为某些 Join 查询在运行时动态生成过滤条件,来减少扫描的数据量,避免不必要的I/O和网络传输,从而加速查询。
5.3.5.1 原理
Runtime Filter在查询规划时生成,在HashJoinNode中构建,在ScanNode中应用。
举个例子,当前存在T1表与T2表的Join查询,它的Join方式为HashJoin,T1是一张事实表,数据行数为100000,T2是一张维度表,数据行数为2000,Doris join的实际情况是:
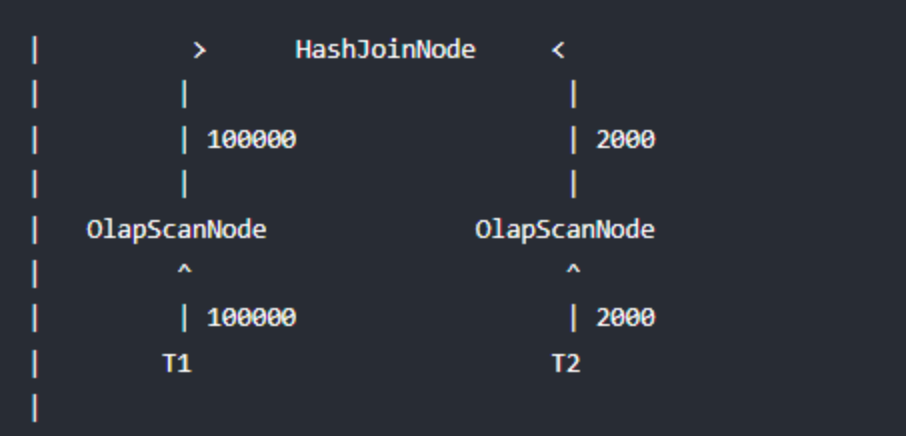
显而易见对T2扫描数据要远远快于T1,如果我们主动等待一段时间再扫描T1,等T2将扫描的数据记录交给HashJoinNode后,HashJoinNode根据T2的数据计算出一个过滤条件,比如T2数据的最大和最小值,或者构建一个Bloom Filter,接着将这个过滤条件发给等待扫描T1的ScanNode,后者应用这个过滤条件,将过滤后的数据交给HashJoinNode,从而减少probe hash table的次数和网络开销,这个过滤条件就是Runtime Filter,效果如下:

如果能将过滤条件(Runtime Filter)下推到存储引擎,则某些情况下可以利用索引来直接减少扫描的数据量,从而大大减少扫描耗时,效果如下:
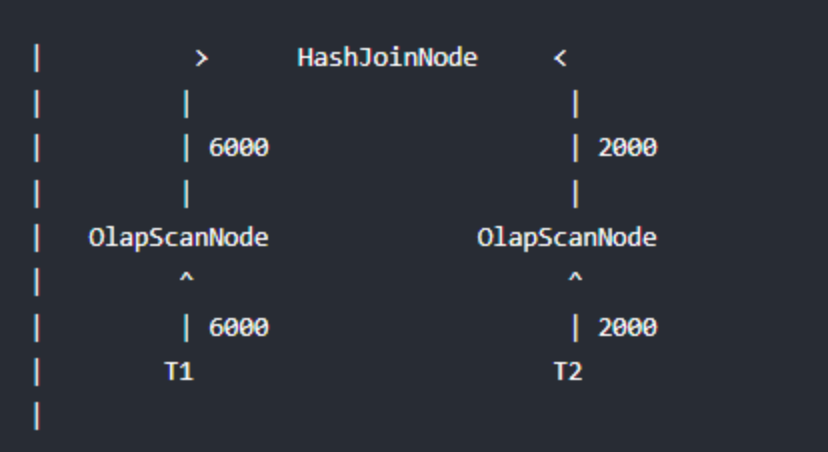
可见,和谓词下推、分区裁剪不同,Runtime Filter是在运行时动态生成的过滤条件,即在查询运行时解析join on clause确定过滤表达式,并将表达式广播给正在读取左表的ScanNode,从而减少扫描的数据量,进而减少probe hash table的次数,避免不必要的I/O和网络传输。
Runtime Filter主要用于优化针对大表的join,如果左表的数据量太小,或者右表的数据量太大,则Runtime Filter可能不会取得预期效果。
5.3.5.2 使用
指定RuntimeFilter类型
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";建表
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2 PROPERTIES("replication_num" = "1");
INSERT INTO test VALUES (1), (2), (3), (4);
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2 PROPERTIES("replication_num" = "1");
INSERT INTO test2 VALUES (3), (4), (5);查看执行计划
EXPLAIN SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;可以看到:
HASH JOIN生成了ID为RF000的IN predicate,其中
test2.t2的key values仅在运行时可知,在OlapScanNode使用了该IN predicate用于在读取test.t1时过滤不必要的数据。通过profile查看效果
set enable_profile=true;
SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;查看对应fe节点的webui,可以查看查询内部工作的详细信息:
http://hadoop1:8030/QueryProfile/
可以看到每个Runtime Filter是否下推、等待耗时、以及OLAP_SCAN_NODE从prepare到接收到Runtime Filter的总时长。
RuntimeFilter:in:
- HasPushDownToEngine: true
- AWaitTimeCost: 0ns
- EffectTimeCost: 2.76ms在profile的OLAP_SCAN_NODE中可以查看Runtime Filter下推后的过滤效果和耗时。
- RowsVectorPredFiltered: 9.320008M (9320008)
- VectorPredEvalTime: 364.39ms
5.3.5.3 具体参数说明
大多数情况下,只需要调整runtime_filter_type选项,其他选项保持默认即可:
包括BLOOM_FILTER、IN、MIN_MAX(也可以通过数字设置),默认会使用IN,部分情况下同时使用Bloom Filter、MinMax Filter、IN predicate时性能更高,每个类型含义如下:
默认只有右表数据行数少于1024才会下推(可通过session变量中的runtime_filter_max_in_num调整)。
目前IN predicate已实现合并方法。
当同时指定In predicate和其他filter,并且in的过滤数值没达到runtime_filter_max_in_num时,会尝试把其他filter去除掉。原因是In predicate是精确的过滤条件,即使没有其他filter也可以高效过滤,如果同时使用则其他filter会做无用功。目前仅在Runtime filter的生产者和消费者处于同一个fragment时才会有去除非in filter的逻辑。
当join on clause中Key列的类型为int/bigint/double等时,极端情况下,如果左右表的最大最小值相同则没有效果,反之右表最大值小于左表最小值,或右表最小值大于左表最大值,则效果最好。
当join on clause中Key列的类型为varchar等时,应用MinMax Filter往往会导致性能降低。
Bloom Filter构建和应用的开销较高,所以当过滤率较低时,或者左表数据量较少时,Bloom Filter可能会导致性能降低。
目前只有左表的Key列应用Bloom Filter才能下推到存储引擎,而测试结果显示Bloom Filter不下推到存储引擎时往往会导致性能降低。
目前Bloom Filter仅在ScanNode上使用表达式过滤时有短路(short-circuit)逻辑,即当假阳性率(实际是假但误辨为真的情况)过高时,不继续使用Bloom Filter,但当Bloom Filter下推到存储引擎后没有短路逻辑,所以当过滤率较低时可能导致性能降低。
Bloom Filter: 有一定的误判率,导致过滤的数据比预期少一点,但不会导致最终结果不准确,在大部分情况下Bloom Filter都可以提升性能或对性能没有显著影响,但在部分情况下会导致性能降低。
MinMax Filter: 包含最大值和最小值,从而过滤小于最小值和大于最大值的数据,MinMax Filter的过滤效果与join on clause中Key列的类型和左右表数据分布有关。
IN predicate: 根据join on clause中Key列在右表上的所有值构建IN predicate,使用构建的IN predicate在左表上过滤,相比Bloom Filter构建和应用的开销更低,在右表数据量较少时往往性能更高。
其他查询选项通常仅在某些特定场景下,才需进一步调整以达到最优效果。通常只在性能测试后,针对资源密集型、运行耗时足够长且频率足够高的查询进行优化。
runtime_filter_mode: 用于调整Runtime Filter的下推策略,包括OFF、LOCAL、GLOBAL三种策略,默认设置为GLOBAL策略runtime_filter_wait_time_ms: 左表的ScanNode等待每个Runtime Filter的时间,默认1000msruntime_filters_max_num: 每个查询可应用的Runtime Filter中Bloom Filter的最大数量,默认10runtime_bloom_filter_min_size: Runtime Filter中Bloom Filter的最小长度,默认1048576(1M)runtime_bloom_filter_max_size: Runtime Filter中Bloom Filter的最大长度,默认16777216(16M)runtime_bloom_filter_size: Runtime Filter中Bloom Filter的默认长度,默认2097152(2M)runtime_filter_max_in_num: 如果join右表数据行数大于这个值,我们将不生成IN predicate,默认1024
5.3.5.4 注意事项
只支持对join on clause中的等值条件生成Runtime Filter,不包括Null-safe条件,因为其可能会过滤掉join左表的null值。
不支持将Runtime Filter下推到left outer、full outer、anti join的左表;
不支持src expr或target expr是常量;
不支持src expr和target expr相等;
不支持src expr的类型等于HLL或者BITMAP;
目前仅支持将Runtime Filter下推给OlapScanNode;
不支持target expr包含NULL-checking表达式,比如COALESCE/IFNULL/CASE,因为当outer join上层其他join的join on clause包含NULL-checking表达式并生成Runtime Filter时,将这个Runtime Filter下推到outer join的左表时可能导致结果不正确;
不支持target expr中的列(slot)无法在原始表中找到某个等价列;
不支持列传导,这包含两种情况:
一是例如join on clause包含A.k = B.k and B.k = C.k时,目前C.k只可以下推给B.k,而不可以下推给A.k;
二是例如join on clause包含A.a + B.b = C.c,如果A.a可以列传导到B.a,即A.a和B.a是等价的列,那么可以用B.a替换A.a,然后可以尝试将Runtime Filter下推给B(如果A.a和B.a不是等价列,则不能下推给B,因为target expr必须与唯一一个join左表绑定);
Target expr和src expr的类型必须相等,因为Bloom Filter基于hash,若类型不等则会尝试将target expr的类型转换为src expr的类型;
不支持PlanNode.Conjuncts生成的Runtime Filter下推,与HashJoinNode的eqJoinConjuncts和otherJoinConjuncts不同,PlanNode.Conjuncts生成的Runtime Filter在测试中发现可能会导致错误的结果,例如IN子查询转换为join时,自动生成的join on clause将保存在PlanNode.Conjuncts中,此时应用Runtime Filter可能会导致结果缺少一些行。
5.4 SQL函数
查看函数名:
show builtin functions in test_db;查看函数具体信息,比如查看year函数具体信息
show full builtin functions in test_db like 'year';官网
https://doris.apache.org/zh-CN/sql-reference/sql-functions/date-time-functions/convert_tz.html
第6章 集成其他系统
准备表和数据
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
insert into table1 values
(1,1,'jim',2),
(2,1,'grace',2),
(3,2,'tom',2),
(4,3,'bush',3),
(5,3,'helen',3);
6.1 Spark读写Doris
6.1.1 准备Spark环境
创建maven工程,编写pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.doris</groupId>
<artifactId>spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.0.0</spark.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- Spark的依赖引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<scope>provided</scope>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<scope>provided</scope>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<scope>provided</scope>
<version>${spark.version}</version>
</dependency>
<!-- 引入Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<!--spark-doris-connector-->
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>spark-doris-connector-3.1_2.12</artifactId>
<!--<artifactId>spark-doris-connector-2.3_2.11</artifactId>-->
<version>1.0.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--编译scala所需插件-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.1</version>
<executions>
<execution>
<id>compile-scala</id>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- assembly打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<!-- <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<!– 所有的编译都依照JDK1.8 –>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>-->
</plugins>
</build>
</project>
6.1.2 使用Spark Doris Connector
Spark Doris Connector 可以支持通过 Spark 读取 Doris 中存储的数据,也支持通过Spark写入数据到Doris。
6.1.2.1 SQL方式读写数据
package com.atuigu.doris.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* TODO
*
* @version 1.0
* @author cjp
*/
object SQLDemo {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("SQLDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
sparkSession.sql(
"""
|CREATE TEMPORARY VIEW spark_doris
|USING doris
|OPTIONS(
| "table.identifier"="test_db.table1",
| "fenodes"="hadoop1:8030",
| "user"="test",
| "password"="test"
|);
""".stripMargin)
//读取数据
// sparkSession.sql("select * from spark_doris").show()
//写入数据
sparkSession.sql("insert into spark_doris values(99,99,'haha',5)")
}
}
6.1.2.2 DataFrame方式读写数据(batch)
package com.atuigu.doris.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* TODO
*
* @version 1.0
* @author cjp
*/
object DataFrameDemo {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("DataFrameDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 读取数据
// val dorisSparkDF = sparkSession.read.format("doris")
// .option("doris.table.identifier", "test_db.table1")
// .option("doris.fenodes", "hadoop1:8030")
// .option("user", "test")
// .option("password", "test")
// .load()
// dorisSparkDF.show()
// 写入数据
import sparkSession.implicits._
val mockDataDF = List(
(11,23, "haha", 8),
(11, 3, "hehe", 9),
(11, 3, "heihei", 10)
).toDF("siteid", "citycode", "username","pv")
mockDataDF.show(5)
mockDataDF.write.format("doris")
.option("doris.table.identifier", "test_db.table1")
.option("doris.fenodes", "hadoop1:8030")
.option("user", "test")
.option("password", "test")
//指定你要写入的字段
// .option("doris.write.fields", "user")
.save()
}
}
6.1.2.3 RDD方式读取数据
package com.atuigu.doris.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
/**
* TODO
*
* @version 1.0
* @author cjp
*/
object RDDDemo {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("RDDDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sc = new SparkContext(sparkConf)
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("test_db.table1"),
cfg = Some(Map(
"doris.fenodes" -> "hadoop1:8030",
"doris.request.auth.user" -> "test",
"doris.request.auth.password" -> "test"
))
)
dorisSparkRDD.collect().foreach(println)
}
}
6.1.2.4 配置和字段类型映射
通用配置项
Key Default Value Comment doris.fenodes -- Doris FE http 地址,支持多个地址,使用逗号分隔 doris.table.identifier -- Doris 表名,如:db1.tbl1 doris.request.retries 3 向Doris发送请求的重试次数 doris.request.connect.timeout.ms 30000 向Doris发送请求的连接超时时间 doris.request.read.timeout.ms 30000 向Doris发送请求的读取超时时间 doris.request.query.timeout.s 3600 查询doris的超时时间,默认值为1小时,-1表示无超时限制 doris.request.tablet.size Integer.MAX_VALUE 一个RDD Partition对应的Doris Tablet个数。此数值设置越小,则会生成越多的Partition。从而提升Spark侧的并行度,但同时会对Doris造成更大的压力。 doris.batch.size 1024 一次从BE读取数据的最大行数。增大此数值可减少Spark与Doris之间建立连接的次数。从而减轻网络延迟所带来的的额外时间开销。 doris.exec.mem.limit 2147483648 单个查询的内存限制。默认为 2GB,单位为字节 doris.deserialize.arrow.async false 是否支持异步转换Arrow格式到spark-doris-connector迭代所需的RowBatch doris.deserialize.queue.size 64 异步转换Arrow格式的内部处理队列,当doris.deserialize.arrow.async为true时生效 doris.write.fields -- 指定写入Doris表的字段或者字段顺序,多列之间使用逗号分隔。默认写入时要按照Doris表字段顺序写入全部字段。 sink.batch.size 10000 单次写BE的最大行数 sink.max-retries 1 写BE失败之后的重试次数 SQL 和 Dataframe 专有配置
Key Default Value Comment user -- 访问Doris的用户名 password -- 访问Doris的密码 doris.filter.query.in.max.count 100 谓词下推中,in表达式value列表元素最大数量。超过此数量,则in表达式条件过滤在Spark侧处理。 RDD 专有配置
Key Default Value Comment doris.request.auth.user -- 访问Doris的用户名 doris.request.auth.password -- 访问Doris的密码 doris.read.field -- 读取Doris表的列名列表,多列之间使用逗号分隔 doris.filter.query -- 过滤读取数据的表达式,此表达式透传给Doris。Doris使用此表达式完成源端数据过滤。 Doris 和 Spark 列类型映射关系:
Doris Type Spark Type NULL_TYPE DataTypes.NullType BOOLEAN DataTypes.BooleanType TINYINT DataTypes.ByteType SMALLINT DataTypes.ShortType INT DataTypes.IntegerType BIGINT DataTypes.LongType FLOAT DataTypes.FloatType DOUBLE DataTypes.DoubleType DATE DataTypes.StringType1 DATETIME DataTypes.StringType1 BINARY DataTypes.BinaryType DECIMAL DecimalType CHAR DataTypes.StringType LARGEINT DataTypes.StringType VARCHAR DataTypes.StringType DECIMALV2 DecimalType TIME DataTypes.DoubleType HLL Unsupported datatype 注:Connector中,将DATE和DATETIME映射为String。由于Doris底层存储引擎处理逻辑,直接使用时间类型时,覆盖的时间范围无法满足需求。所以使用 String 类型直接返回对应的时间可读文本。
6.1.3 使用JDBC的方式(不推荐)
这种方式是早期写法,Spark无法感知Doris的数据分布,会导致打到Doris的查询压力非常大。
package com.atuigu.doris.spark
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object JDBCDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("JDBCDemo").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 读取数据
// val df=sparkSession.read.format("jdbc")
// .option("url","jdbc:mysql://hadoop1:9030/test_db")
// .option("user","test")
// .option("password","test")
// .option("dbtable","table1")
// .load()
//
// df.show()
// 写入数据
import sparkSession.implicits._
val mockDataDF = List(
(11,23, "haha", 8),
(11, 3, "hehe", 9),
(11, 3, "heihei", 10)
).toDF("siteid", "citycode", "username","pv")
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
df.write.mode(SaveMode.Append)
.jdbc("jdbc:mysql://hadoop1:9030/test_db", "table1", prop)
}
}
6.2 Flink Doris Connector
Flink Doris Connector 可以支持通过 Flink 操作(读取、插入、修改、删除) Doris 中存储的数据。
Flink Doris Connector Sink的内部实现是通过 Stream load 服务向Doris写入数据, 同时也支持 Stream load 请求参数的配置设定。
版本兼容如下:
| Connector | Flink | Doris | Java | Scala |
|---|---|---|---|---|
| 1.11.6-2.12-xx | 1.11.x | 0.13+ | 8 | 2.12 |
| 1.12.7-2.12-xx | 1.12.x | 0.13.+ | 8 | 2.12 |
| 1.13.5-2.12-xx | 1.13.x | 0.13.+ | 8 | 2.12 |
| 1.14.4-2.12-xx | 1.14.x | 0.13.+ | 8 | 2.12 |
6.2.1 准备Flink环境
创建maven工程,编写pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.doris</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.13.1</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope> <!--不会打包到依赖中,只参与编译,不参与运行 -->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!---->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sequence-file</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<!--flink-doris-connector-->
<dependency>
<groupId>org.apache.doris</groupId>
<!--<artifactId>flink-doris-connector-1.14_2.12</artifactId>-->
<artifactId>flink-doris-connector-1.13_2.12</artifactId>
<!--<artifactId>flink-doris-connector-1.12_2.12</artifactId>-->
<!--<artifactId>flink-doris-connector-1.11_2.12</artifactId>-->
<version>1.0.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
<exclude>org.apache.hadoop:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
6.2.2 SQL方式读写
package com.atuigu.doris.flink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class SQLDemo {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE flink_doris (\n" +
" siteid INT,\n" +
" citycode SMALLINT,\n" +
" username STRING,\n" +
" pv BIGINT\n" +
" ) \n" +
" WITH (\n" +
" 'connector' = 'doris',\n" +
" 'fenodes' = 'hadoop1:8030',\n" +
" 'table.identifier' = 'test_db.table1',\n" +
" 'username' = 'test',\n" +
" 'password' = 'test'\n" +
")\n");
// 读取数据
// tableEnv.executeSql("select * from flink_doris").print();
// 写入数据
tableEnv.executeSql("insert into flink_doris(siteid,username,pv) values(22,'wuyanzu',3)");
}
}
6.2.3 DataStream读写
6.2.3.1 Source
package com.atuigu.doris.flink;
import org.apache.doris.flink.cfg.DorisStreamOptions;
import org.apache.doris.flink.datastream.DorisSourceFunction;
import org.apache.doris.flink.deserialization.SimpleListDeserializationSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Properties;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class DataStreamSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("fenodes","hadoop1:8030");
properties.put("username","test");
properties.put("password","test");
properties.put("table.identifier","test_db.table1");
env.addSource(new DorisSourceFunction(
new DorisStreamOptions(properties),
new SimpleListDeserializationSchema()
)
).print();
env.execute();
}
}
6.2.3.2 Sink
Json数据流写法一
package com.atuigu.doris.flink;
import org.apache.doris.flink.cfg.*;
import org.apache.doris.flink.datastream.DorisSourceFunction;
import org.apache.doris.flink.deserialization.SimpleListDeserializationSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Properties;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class DataStreamJsonSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties pro = new Properties();
pro.setProperty("format", "json");
pro.setProperty("strip_outer_array", "true");
env
.fromElements(
"{\"longitude\": \"116.405419\", \"city\": \"北京\", \"latitude\": \"39.916927\"}"
)
.addSink(
DorisSink.sink(
DorisReadOptions.builder().build(),
DorisExecutionOptions.builder()
.setBatchSize(3)
.setBatchIntervalMs(0L)
.setMaxRetries(3)
.setStreamLoadProp(pro).build(),
DorisOptions.builder()
.setFenodes("FE_IP:8030")
.setTableIdentifier("db.table")
.setUsername("root")
.setPassword("").build()
));
// .addSink(
// DorisSink.sink(
// DorisOptions.builder()
// .setFenodes("FE_IP:8030")
// .setTableIdentifier("db.table")
// .setUsername("root")
// .setPassword("").build()
// ));
env.execute();
}
}RowData数据流
package com.atuigu.doris.flink;
import org.apache.doris.flink.cfg.DorisExecutionOptions;
import org.apache.doris.flink.cfg.DorisOptions;
import org.apache.doris.flink.cfg.DorisReadOptions;
import org.apache.doris.flink.cfg.DorisSink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.flink.table.types.logical.*;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class DataStreamRowDataSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<RowData> source = env.fromElements("")
.map(new MapFunction<String, RowData>() {
@Override
public RowData map(String value) throws Exception {
GenericRowData genericRowData = new GenericRowData(4);
genericRowData.setField(0, 33);
genericRowData.setField(1, new Short("3"));
genericRowData.setField(2, StringData.fromString("flink-stream"));
genericRowData.setField(3, 3L);
return genericRowData;
}
});
LogicalType[] types = {new IntType(), new SmallIntType(), new VarCharType(32), new BigIntType()};
String[] fields = {"siteid", "citycode", "username", "pv"};
source.addSink(
DorisSink.sink(
fields,
types,
DorisReadOptions.builder().build(),
DorisExecutionOptions.builder()
.setBatchSize(3)
.setBatchIntervalMs(0L)
.setMaxRetries(3)
.build(),
DorisOptions.builder()
.setFenodes("hadoop1:8030")
.setTableIdentifier("test_db.table1")
.setUsername("test")
.setPassword("test").build()
));
env.execute();
}
}
6.2.4 通用配置项和字段类型映射
通用配置项:
Key Default Value Comment fenodes -- Doris FE http 地址 table.identifier -- Doris 表名,如:db1.tbl1 username -- 访问Doris的用户名 password -- 访问Doris的密码 doris.request.retries 3 向Doris发送请求的重试次数 doris.request.connect.timeout.ms 30000 向Doris发送请求的连接超时时间 doris.request.read.timeout.ms 30000 向Doris发送请求的读取超时时间 doris.request.query.timeout.s 3600 查询doris的超时时间,默认值为1小时,-1表示无超时限制 doris.request.tablet.size Integer. MAX_VALUE 一个Partition对应的Doris Tablet个数。此数值设置越小,则会生成越多的Partition。从而提升Flink侧的并行度,但同时会对Doris造成更大的压力。 doris.batch.size 1024 一次从BE读取数据的最大行数。增大此数值可减少flink与Doris之间建立连接的次数。从而减轻网络延迟所带来的的额外时间开销。 doris.exec.mem.limit 2147483648 单个查询的内存限制。默认为 2GB,单位为字节 doris.deserialize.arrow.async false 是否支持异步转换Arrow格式到flink-doris-connector迭代所需的RowBatch doris.deserialize.queue.size 64 异步转换Arrow格式的内部处理队列,当doris.deserialize.arrow.async为true时生效 doris.read.field -- 读取Doris表的列名列表,多列之间使用逗号分隔 doris.filter.query -- 过滤读取数据的表达式,此表达式透传给Doris。Doris使用此表达式完成源端数据过滤。 sink.batch.size 10000 单次写BE的最大行数 sink.max-retries 1 写BE失败之后的重试次数 sink.batch.interval 10s flush 间隔时间,超过该时间后异步线程将 缓存中数据写入BE。默认值为10秒,支持时间单位ms、s、min、h和d。设置为0表示关闭定期写入。 sink.properties.* -- Stream load 的导入参数 例如: 'sink.properties.column_separator' = ', ' 定义列分隔符 'sink.properties.escape_delimiters' = 'true' 特殊字符作为分隔符,'\x01'会被转换为二进制的0x01 'sink.properties.format' = 'json' 'sink.properties.strip_outer_array' = 'true' JSON格式导入 sink.enable-delete true 是否启用删除。此选项需要Doris表开启批量删除功能(0.15+版本默认开启),只支持Uniq模型。 sink.batch.bytes 10485760 单次写BE的最大数据量,当每个 batch 中记录的数据量超过该阈值时,会将缓存数据写入 BE。默认值为 10MB Doris 和 Flink 列类型映射关系:
Doris Type Flink Type NULL_TYPE NULL BOOLEAN BOOLEAN TINYINT TINYINT SMALLINT SMALLINT INT INT BIGINT BIGINT FLOAT FLOAT DOUBLE DOUBLE DATE STRING DATETIME STRING DECIMAL DECIMAL CHAR STRING LARGEINT STRING VARCHAR STRING DECIMALV2 DECIMAL TIME DOUBLE HLL Unsupported datatype
6.3 DataX doriswriter
DorisWriter支持将大批量数据写入Doris中。DorisWriter 通过Doris原生支持Stream load方式导入数据, DorisWriter会将reader读取的数据进行缓存在内存中,拼接成Json文本,然后批量导入至Doris。
6.3.1 编译
可以自己编译,也可以直接使用我们编译好的包。
进入之前的容器环境
docker run -it \
-v /opt/software/.m2:/root/.m2 \
-v /opt/software/apache-doris-0.15.0-incubating-src/:/root/apache-doris-0.15.0-incubating-src/ \
apache/incubator-doris:build-env-for-0.15.0运行 init-env.sh
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX
sh init-env.sh手动上传依赖
上传alibaba-datax-maven-m2-20210928.tar.gz,解压:
tar -zxvf alibaba-datax-maven-m2-20210928.tar.gz -C /opt/software拷贝解压后的文件到maven仓库
sudo cp -r /opt/software/alibaba/datax/ /opt/software/.m2/repository/com/alibaba/编译 doriswriter:
单独编译 doriswriter 插件:
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX/DataX
mvn clean install -pl plugin-rdbms-util,doriswriter -DskipTests编译整个 DataX 项目:
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX/DataX
mvn package assembly:assembly -Dmaven.test.skip=true产出在target/datax/datax/.
hdfsreader, hdfswriter and oscarwriter 这三个插件需要额外的jar包。如果你并不需要这些插件,可以在 DataX/pom.xml 中删除这些插件的模块。
拷贝编译好的插件到DataX
Sudo cp -r /opt/software/apache-doris-0.15.0-incubating-src/extension/DataX/doriswriter/target/datax/plugin/writer/doriswriter /opt/module/datax/plugin/writer
6.3.2 使用
准备测试表
MySQL建表、插入测试数据
CREATE TABLE `sensor` (
`id` varchar(255) NOT NULL,
`ts` bigint(255) DEFAULT NULL,
`vc` int(255) DEFAULT NULL,
PRIMARY KEY (`id`)
)
insert into sensor values('s_2',3,3),('s_9',9,9);
Doris建表
CREATE TABLE `sensor` (
`id` varchar(255) NOT NULL,
`ts` bigint(255) DEFAULT NULL,
`vc` int(255) DEFAULT NULL
)
DISTRIBUTED BY HASH(`id`) BUCKETS 10;编写json文件
vim mysql2doris.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"ts",
"vc"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop1:3306/test"
],
"table": [
"sensor"
]
}
],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"feLoadUrl": ["hadoop1:8030", "hadoop2:8030", "hadoop3:8030"],
"beLoadUrl": ["hadoop1:8040", "hadoop2:8040", "hadoop3:8040"],
"jdbcUrl": "jdbc:mysql://hadoop1:9030/",
"database": "test_db",
"table": "sensor",
"column": ["id", "ts", "vc"],
"username": "test",
"password": "test",
"postSql": [],
"preSql": [],
"loadProps": {
},
"maxBatchRows" : 500000,
"maxBatchByteSize" : 104857600,
"labelPrefix": "my_prefix",
"lineDelimiter": "\n"
}
}
}
]
}
}运行datax任务
bin/datax.py job/mysql2doris.json
6.3.3 参数说明
jdbcUrl
描述:Doris 的 JDBC 连接串,用户执行 preSql 或 postSQL。
必选:是
默认值:无
feLoadUrl
描述:和 beLoadUrl 二选一。作为 Stream Load 的连接目标。格式为 "ip:port"。其中 IP 是 FE 节点 IP,port 是 FE 节点的 http_port。可以填写多个,doriswriter 将以轮询的方式访问。
必选:否
默认值:无
beLoadUrl
描述:和 feLoadUrl 二选一。作为 Stream Load 的连接目标。格式为 "ip:port"。其中 IP 是 BE 节点 IP,port 是 BE 节点的 webserver_port。可以填写多个,doriswriter 将以轮询的方式访问。
必选:否
默认值:无
username
描述:访问Doris数据库的用户名
必选:是
默认值:无
password
描述:访问Doris数据库的密码
必选:否
默认值:空
database
描述:需要写入的Doris数据库名称。
必选:是
默认值:无
table
描述:需要写入的Doris表名称。
必选:是
默认值:无
column
描述:目的表需要写入数据的字段,这些字段将作为生成的 Json 数据的字段名。字段之间用英文逗号分隔。例如: "column": ["id","name","age"]。
必选:是
默认值:否
preSql
描述:写入数据到目的表前,会先执行这里的标准语句。
必选:否
默认值:无
postSql
描述:写入数据到目的表后,会执行这里的标准语句。
必选:否
默认值:无
maxBatchRows
描述:每批次导入数据的最大行数。和 maxBatchByteSize 共同控制每批次的导入数量。每批次数据达到两个阈值之一,即开始导入这一批次的数据。
必选:否
默认值:500000
maxBatchByteSize
描述:每批次导入数据的最大数据量。和 ** maxBatchRows** 共同控制每批次的导入数量。每批次数据达到两个阈值之一,即开始导入这一批次的数据。
必选:否
默认值:104857600
labelPrefix
描述:每批次导入任务的 label 前缀。最终的 label 将有 labelPrefix + UUID + 序号 组成
必选:否
默认值:datax_doris_writer_
lineDelimiter
描述:每批次数据包含多行,每行为 Json 格式,每行的的分隔符即为 lineDelimiter。支持多个字节, 例如'\x02\x03'。
必选:否
默认值:\n
loadProps
描述:StreamLoad 的请求参数,详情参照StreamLoad介绍页面。
必选:否
默认值:无
connectTimeout
描述:StreamLoad单次请求的超时时间, 单位毫秒(ms)。
必选:否
默认值:-1
6.4 ODBC外部表
ODBC External Table Of Doris 提供了Doris通过数据库访问的标准接口(ODBC)来访问外部表,外部表省去了繁琐的数据导入工作,让Doris可以具有了访问各式数据库的能力,并借助Doris本身的OLAP的能力来解决外部表的数据分析问题:
支持各种数据源接入Doris
支持Doris与各种数据源中的表联合查询,进行更加复杂的分析操作
通过insert into将Doris执行的查询结果写入外部的数据源
6.4.1 使用方式
6.4.1.1 Doris中创建ODBC的外表
方式一:不使用Resource创建ODBC的外表。
CREATE EXTERNAL TABLE `baseall_oracle` (
`k1` decimal(9, 3) NOT NULL COMMENT "",
`k2` char(10) NOT NULL COMMENT "",
`k3` datetime NOT NULL COMMENT "",
`k5` varchar(20) NOT NULL COMMENT "",
`k6` double NOT NULL COMMENT ""
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"host" = "192.168.0.1",
"port" = "8086",
"user" = "test",
"password" = "test",
"database" = "test",
"table" = "baseall",
"driver" = "Oracle 19 ODBC driver",
"odbc_type" = "oracle"
);方式二:通过ODBC_Resource来创建ODBC外表(推荐使用的方式)。
CREATE EXTERNAL RESOURCE `oracle_odbc`
PROPERTIES (
"type" = "odbc_catalog",
"host" = "192.168.0.1",
"port" = "8086",
"user" = "test",
"password" = "test",
"database" = "test",
"odbc_type" = "oracle",
"driver" = "Oracle 19 ODBC driver"
);
CREATE EXTERNAL TABLE `baseall_oracle` (
`k1` decimal(9, 3) NOT NULL COMMENT "",
`k2` char(10) NOT NULL COMMENT "",
`k3` datetime NOT NULL COMMENT "",
`k5` varchar(20) NOT NULL COMMENT "",
`k6` double NOT NULL COMMENT ""
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"odbc_catalog_resource" = "oracle_odbc",
"database" = "test",
"table" = "baseall"
);参数说明:
参数 说明 hosts 外表数据库的IP地址 driver ODBC外表Driver名,需要和be/conf/odbcinst.ini中的Driver名一致。 odbc_type 外表数据库的类型,当前支持oracle, mysql, postgresql user 外表数据库的用户名 password 对应用户的密码信息
6.4.1.2 ODBC Driver的安装和配置
各大主流数据库都会提供ODBC的访问Driver,用户可以执行参照各数据库官方推荐的方式安装对应的ODBC Driver LiB库。
安装完成之后,查找对应的数据库的Driver Lib库的路径,并且修改be/conf/odbcinst.ini的配置:
[MySQL Driver]
Description = ODBC for MySQL
Driver = /usr/lib64/libmyodbc8w.so
FileUsage = 1
上述配置[]里的对应的是Driver名,在建立外部表时需要保持外部表的Driver名和配置文件之中的一致。
Driver= 这个要根据实际BE安装Driver的路径来填写,本质上就是一个动态库的路径,这里需要保证该动态库的前置依赖都被满足。
切记,这里要求所有的BE节点都安装上相同的Driver,并且安装路径相同,同时有相同的be/conf/odbcinst.ini的配置。
6.4.2 使用ODBC的MySQL外表
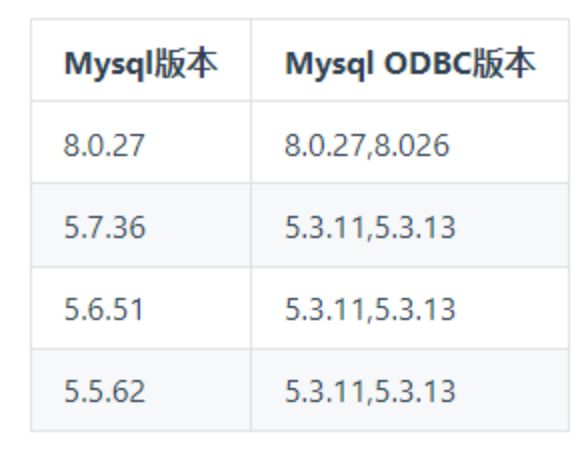
CentOS数据库ODBC版本对应关系:
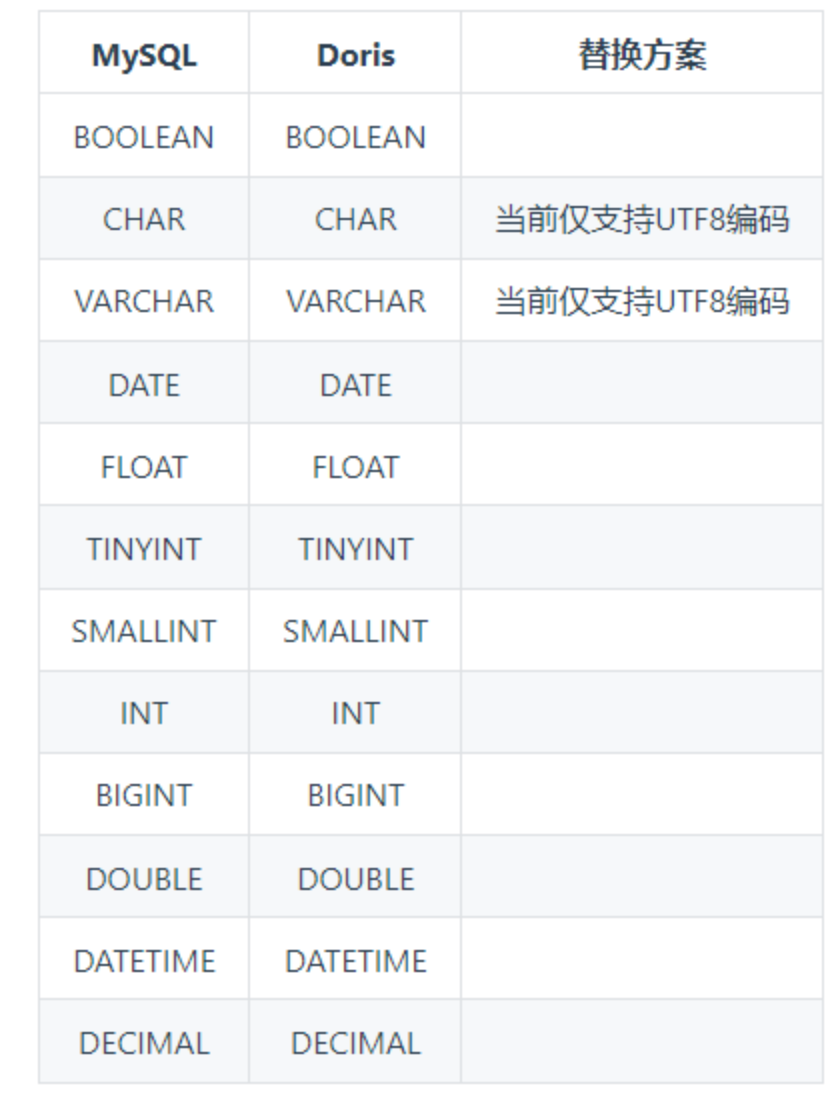
MySQL与Doris的数据类型匹配:
安装unixODBC
安装
yum install -y unixODBC unixODBC-devel libtool-ltdl libtool-ltdl-devel
查看是否安装成功
odbcinst -j安装MySQL对应版本的ODBC(每个BE节点都要)
下载
wget https://downloads.mysql.com/archives/get/p/10/file/mysql-connector-odbc-5.3.11-1.el7.x86_64.rpm
安装
yum install -y mysql-connector-odbc-5.3.11-1.el7.x86_64.rpm
查看是否安装成功
myodbc-installer -d -l配置unixODBC,验证通过ODBC访问Mysql
编辑ODBC配置文件
vim /etc/odbc.ini
[mysql]
Description = Data source MySQL
Driver = MySQL ODBC 5.3 Unicode Driver
Server = hadoop1
Host = hadoop1
Database = test
Port = 3306
User = root
Password = 000000
测试链接
isql -v mysql准备MySQL表
CREATE TABLE `test_cdc` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=91234 DEFAULT CHARSET=utf8mb4;
INSERT INTO `test_cdc` VALUES (123, 'this is a update');
INSERT INTO `test_cdc` VALUES (1212, '测试flink CDC');
INSERT INTO `test_cdc` VALUES (1234, '这是测试');
INSERT INTO `test_cdc` VALUES (11233, 'zhangfeng_1');
INSERT INTO `test_cdc` VALUES (21233, 'zhangfeng_2');
INSERT INTO `test_cdc` VALUES (31233, 'zhangfeng_3');
INSERT INTO `test_cdc` VALUES (41233, 'zhangfeng_4');
INSERT INTO `test_cdc` VALUES (51233, 'zhangfeng_5');
INSERT INTO `test_cdc` VALUES (61233, 'zhangfeng_6');
INSERT INTO `test_cdc` VALUES (71233, 'zhangfeng_7');
INSERT INTO `test_cdc` VALUES (81233, 'zhangfeng_8');
INSERT INTO `test_cdc` VALUES (91233, 'zhangfeng_9');修改Doris的配置文件(每个BE节点都要,不用重启BE)
在BE节点的conf/odbcinst.ini,添加我们的刚才注册的的ODBC驱动([MySQL ODBC 5.3.11]这部分)。
# Driver from the postgresql-odbc package
# Setup from the unixODBC package
[PostgreSQL]
Description = ODBC for PostgreSQL
Driver = /usr/lib/psqlodbc.so
Setup = /usr/lib/libodbcpsqlS.so
FileUsage = 1
# Driver from the mysql-connector-odbc package
# Setup from the unixODBC package
[MySQL ODBC 5.3.11]
Description = ODBC for MySQL
Driver= /usr/lib64/libmyodbc5w.so
FileUsage = 1
# Driver from the oracle-connector-odbc package
# Setup from the unixODBC package
[Oracle 19 ODBC driver]
Description=Oracle ODBC driver for Oracle 19
Driver=/usr/lib/libsqora.so.19.1Doris建Resource
通过ODBC_Resource来创建ODBC外表,这是推荐的方式,这样resource可以复用。
CREATE EXTERNAL RESOURCE `mysql_5_3_11`
PROPERTIES (
"host" = "hadoop1",
"port" = "3306",
"user" = "root",
"password" = "000000",
"database" = "test",
"table" = "test_cdc",
"driver" = "MySQL ODBC 5.3.11", --名称要和上面[]里的名称一致
"odbc_type" = "mysql",
"type" = "odbc_catalog")基于Resource创建Doris外表
CREATE EXTERNAL TABLE `test_odbc_5_3_11` (
`id` int NOT NULL ,
`name` varchar(255) null
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"odbc_catalog_resource" = "mysql_5_3_11", --名称就是resource的名称
"database" = "test",
"table" = "test_cdc"
);查询Doris外表
select * from `test_odbc_5_3_11`;
6.4.3 使用ODBC的Oracle外表
CentOS数据库ODBC版本对应关系:

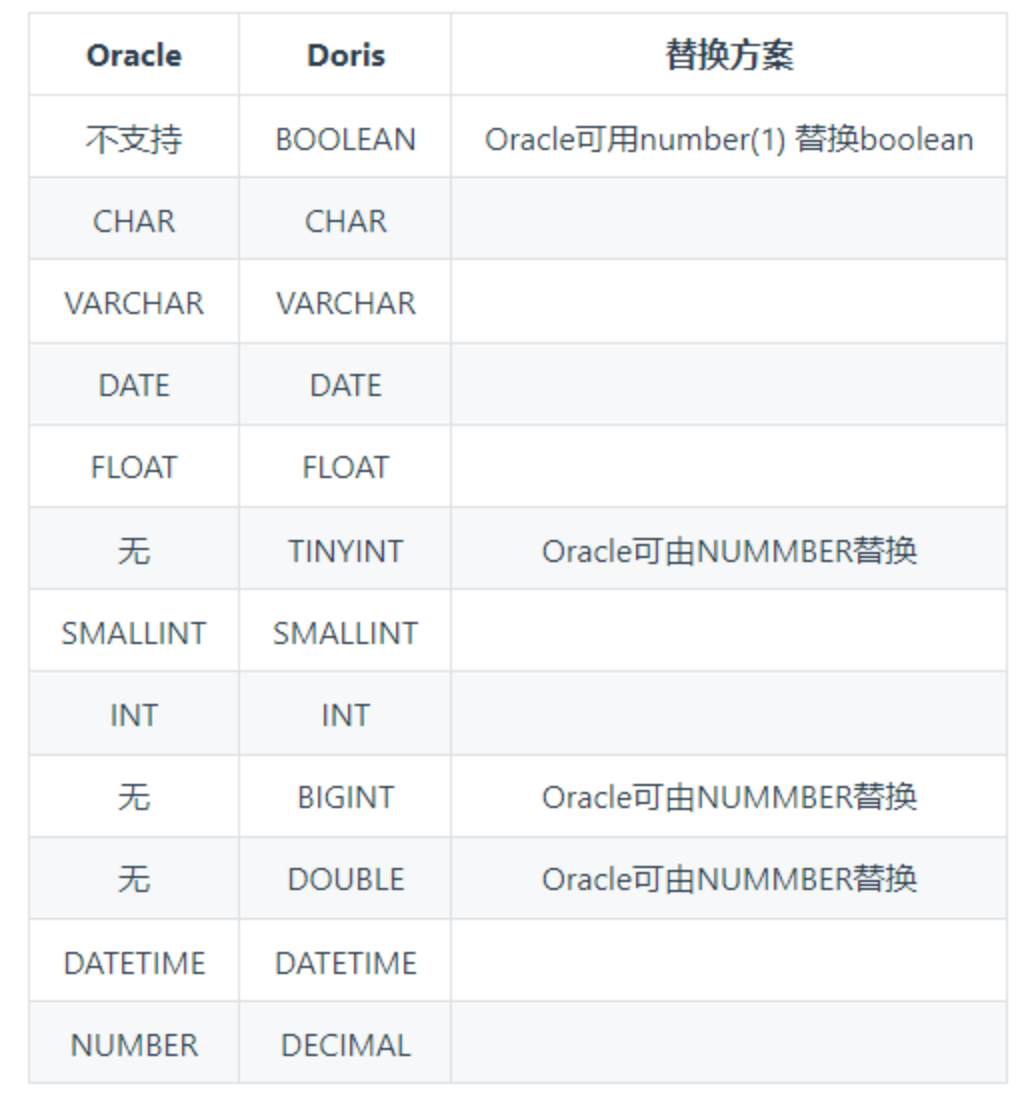
与Doris的数据类型匹配:
安装unixODBC
安装
yum install -y unixODBC unixODBC-devel libtool-ltdl libtool-ltdl-devel
查看是否安装成功
odbcinst -j安装Oracle对应版本的ODBC(每个BE节点都要)
下载4个安装包
wget https://download.oracle.com/otn_software/linux/instantclient/1913000/oracle-instantclient19.13-sqlplus-19.13.0.0.0-2.x86_64.rpm
wget https://download.oracle.com/otn_software/linux/instantclient/1913000/oracle-instantclient19.13-devel-19.13.0.0.0-2.x86_64.rpm
wget https://download.oracle.com/otn_software/linux/instantclient/1913000/oracle-instantclient19.13-odbc-19.13.0.0.0-2.x86_64.rpm
wget https://download.oracle.com/otn_software/linux/instantclient/1913000/oracle-instantclient19.13-basic-19.13.0.0.0-2.x86_64.rpm
安装4个安装包
rpm -ivh oracle-instantclient19.13-basic-19.13.0.0.0-2.x86_64.rpm
rpm -ivh oracle-instantclient19.13-devel-19.13.0.0.0-2.x86_64.rpm
rpm -ivh oracle-instantclient19.13-odbc-19.13.0.0.0-2.x86_64.rpm
rpm -ivh oracle-instantclient19.13-sqlplus-19.13.0.0.0-2.x86_64.rpm验证ODBC驱动动态链接库是否正确
ldd /usr/lib/oracle/19.13/client64/lib/libsqora.so.19.1配置unixODBC,验证通过ODBC连接Oracle
vim /etc/odbcinst.ini
添加如下内容:
[Oracle 19 ODBC driver]
Description = Oracle ODBC driver for Oracle 19
Driver = /usr/lib/oracle/19.13/client64/lib/libsqora.so.19.1
vim /etc/odbc.ini
添加如下内容:
[oracle]
Driver = Oracle 19 ODBC driver ---名称是上面oracle部分用[]括起来的内容
ServerName =hadoop2:1521/orcl --oracle数据ip地址,端口及SID
UserID = atguigu
Password = 000000
验证
isql oracle修改Doris的配置(每个BE节点都要,不用重启)
修改BE节点conf/odbcinst.ini文件,加入刚才/etc/odbcinst.ini添加的一样内容,并删除原先的Oracle配置。
[Oracle 19 ODBC driver]
Description = Oracle ODBC driver for Oracle 19
Driver = /usr/lib/oracle/19.13/client64/lib/libsqora.so.19.1创建Resource
CREATE EXTERNAL RESOURCE `oracle_19`
PROPERTIES (
"host" = "hadoop2",
"port" = "1521",
"user" = "atguigu",
"password" = "000000",
"database" = "orcl", --数据库示例名称,也就是ORACLE_SID
"driver" = "Oracle 19 ODBC driver", --名称一定和be odbcinst.ini里的oracle部分的[]里的内容一样
"odbc_type" = "oracle",
"type" = "odbc_catalog"
);基于Resource创建Doris外表
CREATE EXTERNAL TABLE `oracle_odbc` (
id int,
name VARCHAR(20) NOT NULL
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"odbc_catalog_resource" = "oracle_19",
"database" = "orcl",
"table" = "student"
);查询Doris外表
select * from oracle_odbc;
6.5 Doris On ES
Doris-On-ES将Doris的分布式查询规划能力和ES(Elasticsearch)的全文检索能力相结合,提供更完善的OLAP分析场景解决方案:
ES中的多index分布式Join查询 Doris和ES中的表联合查询,更复杂的全文检索过滤
6.5.1 原理
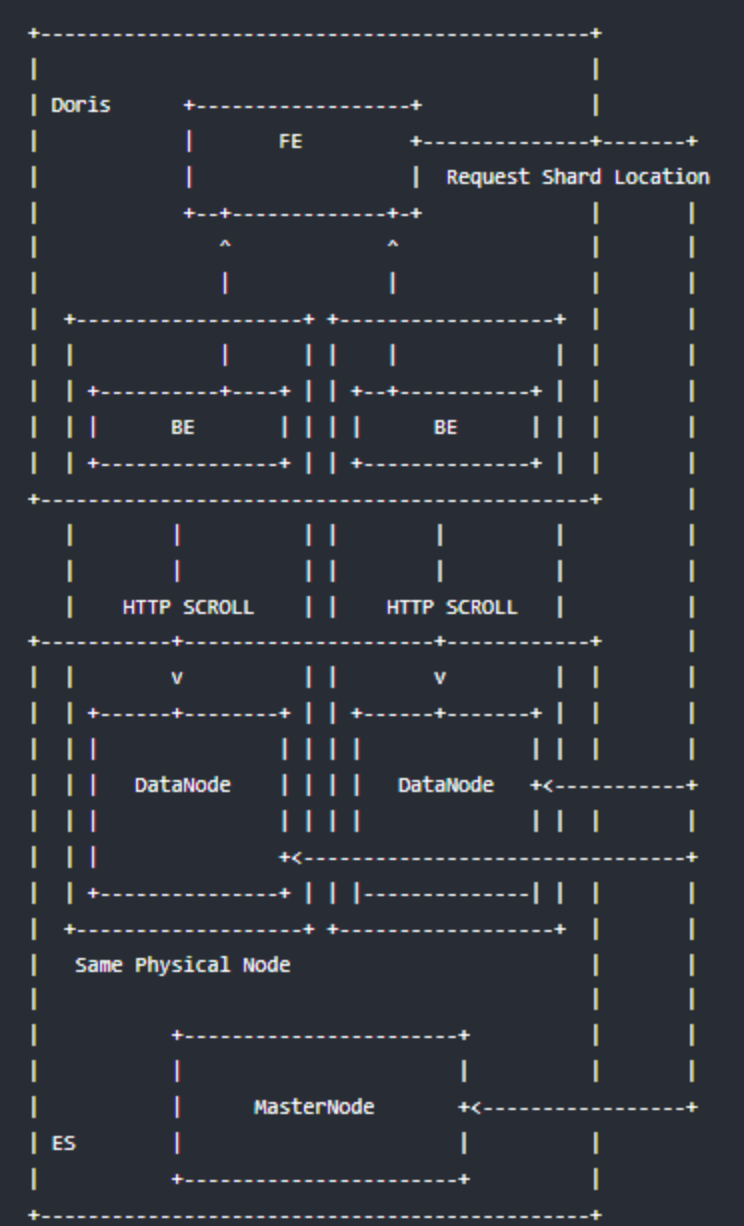
创建ES外表后,FE会请求建表指定的主机,获取所有节点的HTTP端口信息以及index的shard分布信息等,如果请求失败会顺序遍历host列表直至成功或完全失败
查询时会根据FE得到的一些节点信息和index的元数据信息,生成查询计划并发给对应的BE节点
BE节点会根据就近原则即优先请求本地部署的ES节点,BE通过HTTP Scroll方式流式的从ES index的每个分片中并发的从_source或docvalue中获取数据
Doris计算完结果后,返回给用户
6.5.2 使用方式
6.5.2.1 Doris中创建ES外表
创建ES索引
PUT test
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"doc": { // ES 7.x版本之后创建索引时不需要指定type,会有一个默认且唯一的`_doc` type
"properties": {
"k1": {
"type": "long"
},
"k2": {
"type": "date"
},
"k3": {
"type": "keyword"
},
"k4": {
"type": "text",
"analyzer": "standard"
},
"k5": {
"type": "float"
}
}
}
}
}ES索引导入数据
POST /_bulk
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Trying out Elasticsearch", "k4": "Trying out Elasticsearch", "k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Trying out Doris", "k4": "Trying out Doris", "k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Doris On ES", "k4": "Doris On ES", "k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Doris", "k4": "Doris", "k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "ES", "k4": "ES", "k5": 10.0}Doris中创建ES外表
CREATE EXTERNAL TABLE `es_test` (
`k1` bigint(20) COMMENT "",
`k2` datetime COMMENT "",
`k3` varchar(20) COMMENT "",
`k4` varchar(100) COMMENT "",
`k5` float COMMENT ""
) ENGINE=ELASTICSEARCH // ENGINE必须是Elasticsearch
PROPERTIES (
"hosts" = "http://hadoop1:9200,http://hadoop2:9200,http://hadoop3:9200",
"index" = "test",
"type" = "doc",
"user" = "",
"password" = ""
);参数说明:
参数 说明 hosts ES集群地址,可以是一个或多个,也可以是ES前端的负载均衡地址 index 对应的ES的index名字,支持alias,如果使用doc_value,需要使用真实的名称 type index的type,不指定的情况会使用_doc user ES集群用户名 password 对应用户的密码信息 Doris On ES一个重要的功能就是过滤条件的下推: 过滤条件下推给ES,这样只有真正满足条件的数据才会被返回,能够显著的提高查询性能和降低Doris和Elasticsearch的CPU、memory、IO使用量
下面的操作符(Operators)会被优化成如下ES Query:
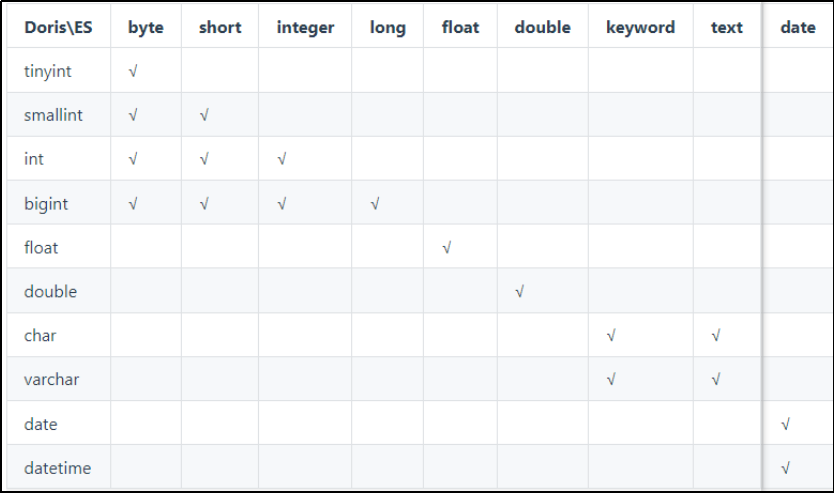
SQL syntax ES 5.x+ syntax = term query in terms query > , < , >= , ⇐ range query and bool.filter or bool.should not bool.must_not not in bool.must_not + terms query is_not_null exists query is_null bool.must_not + exists query esquery ES原生json形式的QueryDSL 数据类型映射:
ES 7.x之前的集群请注意在建表的时候选择正确的索引类型type
认证方式目前仅支持Http Basic认证,并且需要确保该用户有访问: /_cluster/state/、_nodes/http等路径和index的读权限; 集群未开启安全认证,用户名和密码不需要设置
Doris表中的列名需要和ES中的字段名完全匹配,字段类型应该保持一致
ENGINE必须是 Elasticsearch
6.5.2.2 启用列式扫描优化查询速度
"enable_docvalue_scan" = "true"
参数说明
是否开启通过ES/Lucene列式存储获取查询字段的值,默认为false。开启后Doris从ES中获取数据会遵循以下两个原则:
尽力而为: 自动探测要读取的字段是否开启列式存储(doc_value: true),如果获取的字段全部有列存,Doris会从列式存储中获取所有字段的值 自动降级: 如果要获取的字段只要有一个字段没有列存,所有字段的值都会从行存_source中解析获 优势:
默认情况下,Doris On ES会从行存也就是_source中获取所需的所有列,_source的存储采用的行式+json的形式存储,在批量读取性能上要劣于列式存储,尤其在只需要少数列的情况下尤为明显,只获取少数列的情况下,docvalue的性能大约是_source性能的十几倍。
注意
text类型的字段在ES中是没有列式存储,因此如果要获取的字段值有text类型字段会自动降级为从_source中获取.
在获取的字段数量过多的情况下(>= 25),从docvalue中获取字段值的性能会和从_source中获取字段值基本一样。
6.5.2.3 探测keyword类型字段
"enable_keyword_sniff" = "true"
参数说明:
是否对ES中字符串类型分词类型(text) fields 进行探测,获取额外的未分词(keyword)字段名(multi-fields机制)
在ES中可以不建立index直接进行数据导入,这时候ES会自动创建一个新的索引,针对字符串类型的字段ES会创建一个既有text类型的字段又有keyword类型的字段,这就是ES的multi fields特性,mapping如下:
"k4": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
对k4进行条件过滤时比如=,Doris On ES会将查询转换为ES的TermQuery。
SQL过滤条件:
k4 = "Doris On ES"
转换成ES的query DSL为:
"term" : {
"k4": "Doris On ES"
}
因为k4的第一字段类型为text,在数据导入的时候就会根据k4设置的分词器(如果没有设置,就是standard分词器)进行分词处理得到doris、on、es三个Term,如下ES analyze API分析:
POST /_analyze
{
"analyzer": "standard",
"text": "Doris On ES"
}
分词的结果是:
{
"tokens": [
{
"token": "doris",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "on",
"start_offset": 6,
"end_offset": 8,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "es",
"start_offset": 9,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
}
]
}
查询时使用的是:
"term" : {
"k4": "Doris On ES"
}
Doris On ES这个term匹配不到词典中的任何term,不会返回任何结果,而启用enable_keyword_sniff: true会自动将k4 = "Doris On ES"转换成k4.keyword = "Doris On ES"来完全匹配SQL语义,转换后的ES query DSL为:
"term" : {
"k4.keyword": "Doris On ES"
}
k4.keyword 的类型是keyword,数据写入ES中是一个完整的term,所以可以匹配。
6.5.2.4 开启节点自动发现
"nodes_discovery" = "true"
参数说明:
是否开启es节点发现,默认为true。
当配置为true时,Doris将从ES找到所有可用的相关数据节点(在上面分配的分片)。如果ES数据节点的地址没有被Doris BE访问,则设置为false。ES集群部署在与公共Internet隔离的内网,用户通过代理访问。
6.5.2.5 配置https访问模式
"http_ssl_enabled" = "true"
参数说明:
ES集群是否开启https访问模式。
目前fe/be实现方式为信任所有,这是临时解决方案,后续会使用真实的用户配置证书。
6.5.2.6 查询用法
完成在Doris中建立ES外表后,除了无法使用Doris中的数据模型(rollup、预聚合、物化视图等)外并无区别。
基本查询
select * from es_table where k1 > 1000 and k3 ='term' or k4 like 'fu*z_'扩展的esquery(field, QueryDSL)
通过esquery(field, QueryDSL)函数将一些无法用sql表述的query如match_phrase、geoshape等下推给ES进行过滤处理,esquery的第一个列名参数用于关联index,第二个参数是ES的基本Query DSL的json表述,使用花括号{}包含,json的root key有且只能有一个,如match_phrase、geo_shape、bool等。
match_phrase查询:
select * from es_table where esquery(k4, '{
"match_phrase": {
"k4": "doris on es"
}
}');geo相关查询:
select * from es_table where esquery(k4, '{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
13,
53
],
[
14,
52
]
]
},
"relation": "within"
}
}
}');bool查询:
select * from es_table where esquery(k4, ' {
"bool": {
"must": [
{
"terms": {
"k1": [
11,
12
]
}
},
{
"terms": {
"k2": [
100
]
}
}
]
}
}');
6.5.3 最佳实践
6.5.3.1 时间类型字段使用建议
在ES中,时间类型的字段使用十分灵活,但是在Doris On ES中如果对时间类型字段的类型设置不当,则会造成过滤条件无法下推。
创建索引时对时间类型格式的设置做最大程度的格式兼容:
"dt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
在Doris中建立该字段时建议设置为date或datetime,也可以设置为varchar类型, 使用如下SQL语句都可以直接将过滤条件下推至ES:
select * from doe where k2 > '2020-06-21';
select * from doe where k2 < '2020-06-21 12:00:00';
select * from doe where k2 < 1593497011;
select * from doe where k2 < now();
select * from doe where k2 < date_format(now(), '%Y-%m-%d');
注意:
在ES中如果不对时间类型的字段设置format, 默认的时间类型字段格式为
strict_date_optional_time||epoch_millis导入到ES的日期字段如果是时间戳需要转换成ms, ES内部处理时间戳都是按照ms进行处理的, 否则Doris On ES会出现显示错误。
6.5.3.2 获取ES元数据字段_id
导入文档在不指定_id的情况下ES会给每个文档分配一个全局唯一的_id即主键, 用户也可以在导入时为文档指定一个含有特殊业务意义的_id; 如果需要在Doris On ES中获取该字段值,建表时可以增加类型为varchar的_id字段:
CREATE EXTERNAL TABLE `doe` (
`_id` varchar COMMENT "",
`city` varchar COMMENT ""
) ENGINE=ELASTICSEARCH
PROPERTIES (
"hosts" = "http://127.0.0.1:8200",
"user" = "root",
"password" = "root",
"index" = "doe",
"type" = "doc"
}
注意:
_id字段的过滤条件仅支持=和in两种_id字段只能是varchar类型
第7章 监控和报警
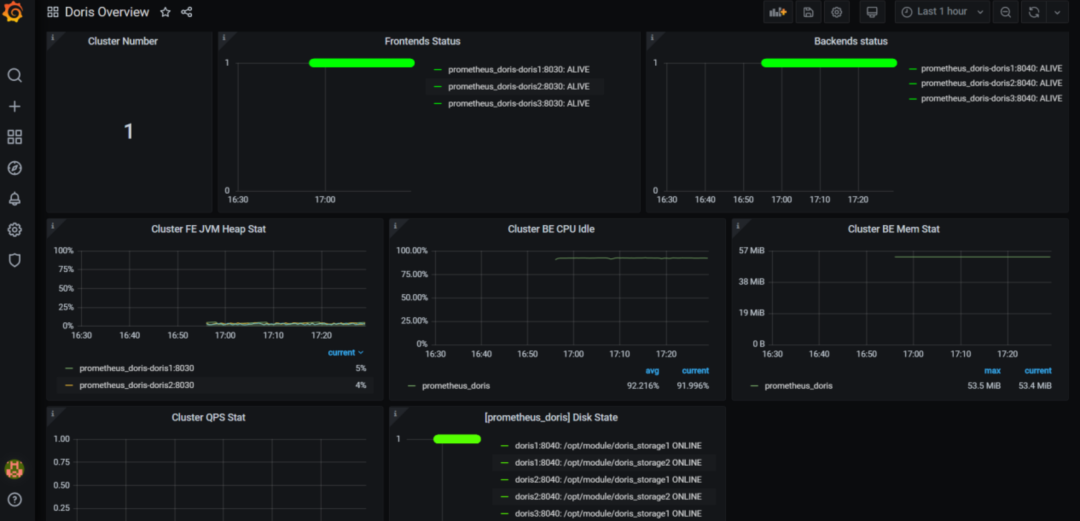
Doris可以使用Prometheus和Grafana进行监控和采集,官网下载最新版即可。
Prometheus官网下载:https://prometheus.io/download/
Grafana官网下载:https://grafana.com/grafana/download
Doris的监控数据通过FE和BE的http接口向外暴露。监控数据以key-value的文本形式对外展现。每个key还可能有不同的Label加以区分。当用户搭建好Doris后,可以在浏览器,通过以下接口访问监控数据.
Frontend: fe_host:fe_http_port/metrics,如 http://hadoop1:8030/metrics
Backend: be_host:be_web_server_port/metrics,如 http://hadoop1:8040/metrics
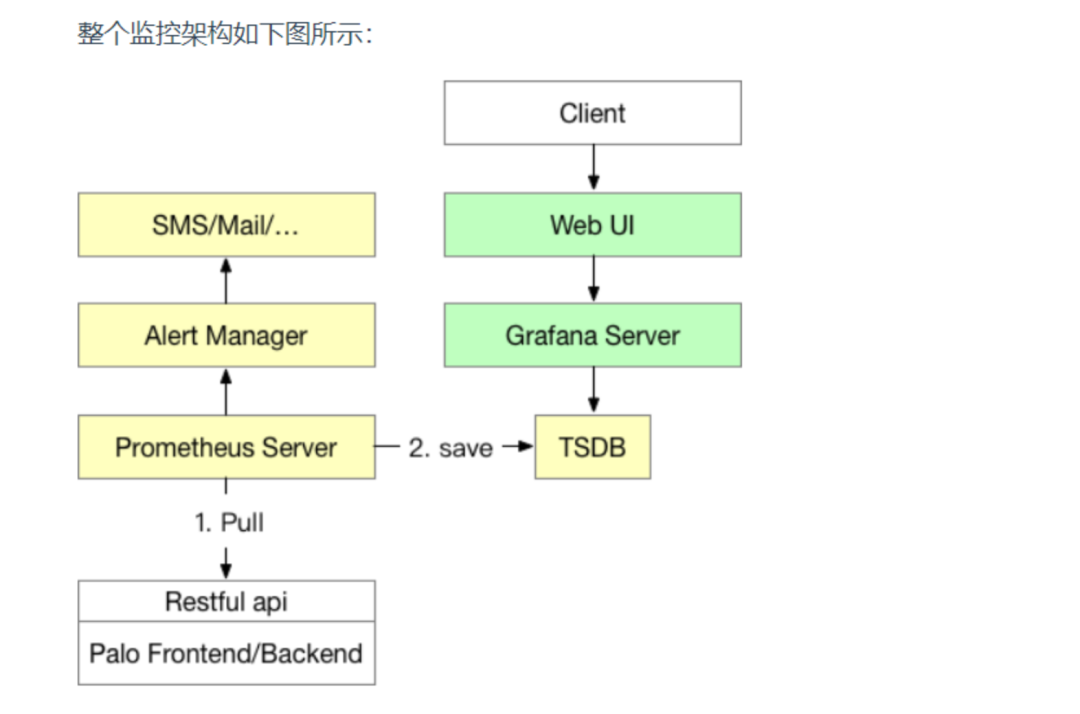
整个监控架构如下图
7.1 Prometheus
上传prometheus-2.26.0.linux-amd64.tar.gz,并进行解压
tar -zxvf prometheus-2.26.0.linux-amd64.tar.gz -C /opt/module
mv prometheus-2.26.0.linux-amd64 prometheus-2.26.0配置 promethues.yml
配置两个targets分别配置FE和BE,并且定义labels和groups指定组。如果有多个集群则再加 -job_name标签,进行相同配置
vim /opt/module/prometheus-2.26.0/prometheus.yml
scrape_configs:
- job_name: 'prometheus_doris'
static_configs:
- targets: ['hadoop1:8030','hadoop2:8030','hadoop3:8030']
labels:
group: fe
- targets: ['hadoop1:8040','hadoop2:8040','hadoop3:8040']
labels:
group: be启动prometheus
nohup ./prometheus --web.listen-address="0.0.0.0:8181" &该命令将后台运行 Prometheus,并指定其 web 端口为 8181。启动后,即开始采集数据,并将数据存放在 data 目录中。
通过浏览器访问prometheus
http://hadoop1:8181点击导航栏中,Status -> Targets,可以看到所有分组 Job 的监控主机节点。正常情况下,所有节点都应为 UP,表示数据采集正常。
点击某一个 Endpoint,即可看到当前的监控数值。
停止prometheus,直接kill -9即可
7.2 Grafana
上传grafana-7.5.2.linux-amd64.tar.gz,并进行解压
tar -zxvf grafana-7.5.2.linux-amd64.tar.gz -C /opt/module/
mv grafana-7.5.2.linux-amd64 grafana-7.5.2配置conf/defaults.ini
vim /opt/module/grafana-7.5.2/conf/defaults.ini
http_addr = hadoop1
http_port = 8182启动granafa
nohup /opt/module/grafana-7.5.2/bin/grafana-server &通过浏览器访问,配置数据源Prometheus
账号密码都是admin
添加dashboard
模板下载地址:https://grafana.com/grafana/dashboards/9734/revisions
上传准备好的doris-overview_rev4.json
第8章 优化
8.1 查看QueryProfile
利用查询执行的统计结果,可以更好的帮助我们了解Doris的执行情况,并有针对性的进行相应Debug与调优工作。
FE将查询计划拆分成为Fragment下发到BE进行任务执行。BE在执行Fragment时记录了运行状态时的统计值,并将Fragment执行的统计信息输出到日志之中。FE也可以通过开关将各个Fragment记录的这些统计值进行搜集,并在FE的Web页面上打印结果。
8.1.1 使用方式
开启profile:
set enable_profile=true;执行一个查询:
SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;通过FE的UI查看:
http://hadoop1:8030/ QueryProfile/
8.1.2 参数说明
Fragment
AverageThreadTokens 执行Fragment使用线程数目,不包含线程池的使用情况 Buffer Pool PeakReservation Buffer Pool使用的内存的峰值 MemoryLimit 查询时的内存限制 PeakMemoryUsage 整个Instance在查询时内存使用的峰值 RowsProduced 处理列的行数 BlockMgr
BlocksCreated BlockMgr创建的Blocks数目 BlocksRecycled 重用的Blocks数目 BytesWritten 总的落盘写数据量 MaxBlockSize 单个Block的大小 TotalReadBlockTime 读Block的总耗时 DataStreamSender
BytesSent 发送的总数据量 = 接受者 * 发送数据量 IgnoreRows 过滤的行数 LocalBytesSent 数据在Exchange过程中,记录本机节点的自发自收数据量 OverallThroughput 总的吞吐量 = BytesSent / 时间 SerializeBatchTime 发送数据序列化消耗的时间 UncompressedRowBatchSize 发送数据压缩前的RowBatch的大小 ODBC_TABLE_SINK
NumSentRows 写入外表的总行数 TupleConvertTime 发送数据序列化为Insert语句的耗时 ResultSendTime 通过ODBC Driver写入的耗时 EXCHANGE_NODE
BytesReceived 通过网络接收的数据量大小 MergeGetNext 当下层节点存在排序时,会在EXCHANGE NODE进行统一的归并排序,输出有序结果。该指标记录了Merge排序的总耗时,包含了MergeGetNextBatch耗时。 MergeGetNextBatch Merge节点取数据的耗时,如果为单层Merge排序,则取数据的对象为网络队列。若为多层Merge排序取数据对象为Child Merger。 ChildMergeGetNext 当下层的发送数据的Sender过多时,单线程的Merge会成为性能瓶颈,Doris会启动多个Child Merge线程并行归并排序。记录了Child Merge的排序耗时 该数值是多个线程的累加值。 ChildMergeGetNextBatch Child Merge节点从取数据的耗时,如果耗时过大,可能的瓶颈为下层的数据发送节点。 DataArrivalWaitTime 等待Sender发送数据的总时间 FirstBatchArrivalWaitTime 等待第一个batch从Sender获取的时间 DeserializeRowBatchTimer 反序列化网络数据的耗时 SendersBlockedTotalTimer(*) DataStreamRecv的队列的内存被打满,Sender端等待的耗时 ConvertRowBatchTime 接收数据转为RowBatch的耗时 RowsReturned 接收行的数目 RowsReturnedRate 接收行的速率 SORT_NODE
InMemorySortTime 内存之中的排序耗时 InitialRunsCreated 初始化排序的趟数(如果内存排序的话,该数为1) SortDataSize 总的排序数据量 MergeGetNext MergeSort从多个sort_run获取下一个batch的耗时 (仅在落盘时计时) MergeGetNextBatch MergeSort提取下一个sort_run的batch的耗时 (仅在落盘时计时) TotalMergesPerformed 进行外排merge的次数 AGGREGATION_NODE
PartitionsCreated 聚合查询拆分成Partition的个数 GetResultsTime 从各个partition之中获取聚合结果的时间 HTResizeTime HashTable进行resize消耗的时间 HTResize HashTable进行resize的次数 HashBuckets HashTable中Buckets的个数 HashBucketsWithDuplicate HashTable有DuplicateNode的Buckets的个数 HashCollisions HashTable产生哈希冲突的次数 HashDuplicateNodes HashTable出现Buckets相同DuplicateNode的个数 HashFailedProbe HashTable Probe操作失败的次数 HashFilledBuckets HashTable填入数据的Buckets数目 HashProbe HashTable查询的次数 HashTravelLength HashTable查询时移动的步数 HASH_JOIN_NODE
ExecOption 对右孩子构造HashTable的方式(同步or异步),Join中右孩子可能是表或子查询,左孩子同理 BuildBuckets HashTable中Buckets的个数 BuildRows HashTable的行数 BuildTime 构造HashTable的耗时 LoadFactor HashTable的负载因子(即非空Buckets的数量) ProbeRows 遍历左孩子进行Hash Probe的行数 ProbeTime 遍历左孩子进行Hash Probe的耗时,不包括对左孩子RowBatch调用GetNext的耗时 PushDownComputeTime 谓词下推条件计算耗时 PushDownTime 谓词下推的总耗时,Join时对满足要求的右孩子,转为左孩子的in查询 CROSS_JOIN_NODE
ExecOption 对右孩子构造RowBatchList的方式(同步or异步) BuildRows RowBatchList的行数(即右孩子的行数) BuildTime 构造RowBatchList的耗时 LeftChildRows 左孩子的行数 LeftChildTime 遍历左孩子,和右孩子求笛卡尔积的耗时,不包括对左孩子RowBatch调用GetNext的耗时 UNION_NODE
MaterializeExprsEvaluateTime Union两端字段类型不一致时,类型转换表达式计算及物化结果的耗时 ANALYTIC_EVAL_NODE
EvaluationTime 分析函数(窗口函数)计算总耗时 GetNewBlockTime 初始化时申请一个新的Block的耗时,Block用来缓存Rows窗口或整个分区,用于分析函数计算 PinTime 后续申请新的Block或将写入磁盘的Block重新读取回内存的耗时 UnpinTime 对暂不需要使用的Block或当前操作符内存压力大时,将Block的数据刷入磁盘的耗时 OLAP_SCAN_NODE
OLAP_SCAN_NODE 节点负责具体的数据扫描任务。一个 OLAP_SCAN_NODE 会生成一个或多个 OlapScanner 。每个 Scanner 线程负责扫描部分数据。查询中的部分或全部谓词条件会推送给 OLAP_SCAN_NODE。这些谓词条件中一部分会继续下推给存储引擎,以便利用存储引擎的索引进行数据过滤。另一部分会保留在 OLAP_SCAN_NODE 中,用于过滤从存储引擎中返回的数据。
OLAP_SCAN_NODE 节点的 Profile 通常用于分析数据扫描的效率,依据调用关系分为 OLAP_SCAN_NODE、OlapScanner、SegmentIterator 三层。
OLAP_SCAN_NODE (id=0):(Active: 1.2ms, % non-child: 0.00%)
- BytesRead: 265.00 B # 从数据文件中读取到的数据量。假设读取到了是10个32位整型,则数据量为 10 * 4B = 40 Bytes。这个数据仅表示数据在内存中全展开的大小,并不代表实际的 IO 大小。
- NumDiskAccess: 1 # 该 ScanNode 节点涉及到的磁盘数量。
- NumScanners: 20 # 该 ScanNode 生成的 Scanner 数量。
- PeakMemoryUsage: 0.00 # 查询时内存使用的峰值,暂未使用
- RowsRead: 7 # 从存储引擎返回到 Scanner 的行数,不包括经 Scanner 过滤的行数。
- RowsReturned: 7 # 从 ScanNode 返回给上层节点的行数。
- RowsReturnedRate: 6.979K /sec # RowsReturned/ActiveTime
- TabletCount : 20 # 该 ScanNode 涉及的 Tablet 数量。
- TotalReadThroughput: 74.70 KB/sec # BytesRead除以该节点运行的总时间(从Open到Close),对于IO受限的查询,接近磁盘的总吞吐量。
- ScannerBatchWaitTime: 426.886us # 用于统计transfer 线程等待scaner 线程返回rowbatch的时间。
- ScannerWorkerWaitTime: 17.745us # 用于统计scanner thread 等待线程池中可用工作线程的时间。
OlapScanner:
- BlockConvertTime: 8.941us # 将向量化Block转换为行结构的 RowBlock 的耗时。向量化 Block 在 V1 中为 VectorizedRowBatch,V2中为 RowBlockV2。
- BlockFetchTime: 468.974us # Rowset Reader 获取 Block 的时间。
- ReaderInitTime: 5.475ms # OlapScanner 初始化 Reader 的时间。V1 中包括组建 MergeHeap 的时间。V2 中包括生成各级 Iterator 并读取第一组Block的时间。
- RowsDelFiltered: 0 # 包括根据 Tablet 中存在的 Delete 信息过滤掉的行数,以及 unique key 模型下对被标记的删除行过滤的行数。
- RowsPushedCondFiltered: 0 # 根据传递下推的谓词过滤掉的条件,比如 Join 计算中从 BuildTable 传递给 ProbeTable 的条件。该数值不准确,因为如果过滤效果差,就不再过滤了。
- ScanTime: 39.24us # 从 ScanNode 返回给上层节点的时间。
- ShowHintsTime_V1: 0ns # V2 中无意义。V1 中读取部分数据来进行 ScanRange 的切分。
SegmentIterator:
- BitmapIndexFilterTimer: 779ns # 利用 bitmap 索引过滤数据的耗时。
- BlockLoadTime: 415.925us # SegmentReader(V1) 或 SegmentIterator(V2) 获取 block 的时间。
- BlockSeekCount: 12 # 读取 Segment 时进行 block seek 的次数。
- BlockSeekTime: 222.556us # 读取 Segment 时进行 block seek 的耗时。
- BlocksLoad: 6 # 读取 Block 的数量
- CachedPagesNum: 30 # 仅 V2 中,当开启 PageCache 后,命中 Cache 的 Page 数量。
- CompressedBytesRead: 0.00 # V1 中,从文件中读取的解压前的数据大小。V2 中,读取到的没有命中 PageCache 的 Page 的压缩前的大小。
- DecompressorTimer: 0ns # 数据解压耗时。
- IOTimer: 0ns # 实际从操作系统读取数据的 IO 时间。
- IndexLoadTime_V1: 0ns # 仅 V1 中,读取 Index Stream 的耗时。
- NumSegmentFiltered: 0 # 在生成 Segment Iterator 时,通过列统计信息和查询条件,完全过滤掉的 Segment 数量。
- NumSegmentTotal: 6 # 查询涉及的所有 Segment 数量。
- RawRowsRead: 7 # 存储引擎中读取的原始行数。详情见下文。
- RowsBitmapIndexFiltered: 0 # 仅 V2 中,通过 Bitmap 索引过滤掉的行数。
- RowsBloomFilterFiltered: 0 # 仅 V2 中,通过 BloomFilter 索引过滤掉的行数。
- RowsKeyRangeFiltered: 0 # 仅 V2 中,通过 SortkeyIndex 索引过滤掉的行数。
- RowsStatsFiltered: 0 # V2 中,通过 ZoneMap 索引过滤掉的行数,包含删除条件。V1 中还包含通过 BloomFilter 过滤掉的行数。
- RowsConditionsFiltered: 0 # 仅 V2 中,通过各种列索引过滤掉的行数。
- RowsVectorPredFiltered: 0 # 通过向量化条件过滤操作过滤掉的行数。
- TotalPagesNum: 30 # 仅 V2 中,读取的总 Page 数量。
- UncompressedBytesRead: 0.00 # V1 中为读取的数据文件解压后的大小(如果文件无需解压,则直接统计文件大小)。V2 中,仅统计未命中 PageCache 的 Page 解压后的大小(如果Page无需解压,直接统计Page大小)
- VectorPredEvalTime: 0ns # 向量化条件过滤操作的耗时。
- ShortPredEvalTime: 0ns # 短路谓词过滤操作的耗时。
- PredColumnReadTime: 0ns # 谓词列读取的耗时。
- LazyReadTime: 0ns # 非谓词列读取的耗时。
- OutputColumnTime: 0ns # 物化列的耗时。Buffer pool
AllocTime 内存分配耗时 CumulativeAllocationBytes 累计内存分配的量 CumulativeAllocations 累计的内存分配次数 PeakReservation Reservation的峰值 PeakUnpinnedBytes unpin的内存数据量 PeakUsedReservation Reservation的内存使用量 ReservationLimit BufferPool的Reservation的限制量
8.1.3 调试方式
https://doris.apache.org/zh-CN/developer-guide/debug-tool.html
8.2 Join Reorder
Join Reorder 功能可以通过代价模型自动帮助调整 SQL 中 Join 的顺序,以帮助获得最优的 Join 效率。可通过会话变量开启
set enable_cost_based_join_reorder=true
8.2.1 原理
数据库一旦涉及到多表 Join,Join 的顺序对整个 Join 查询的性能是影响很大的。假设有三张表 Join,参考下面这张图,左边是 a 表跟 b 张表先做 Join,中间结果的有 2000 行,然后与 c 表再进行 Join 计算。
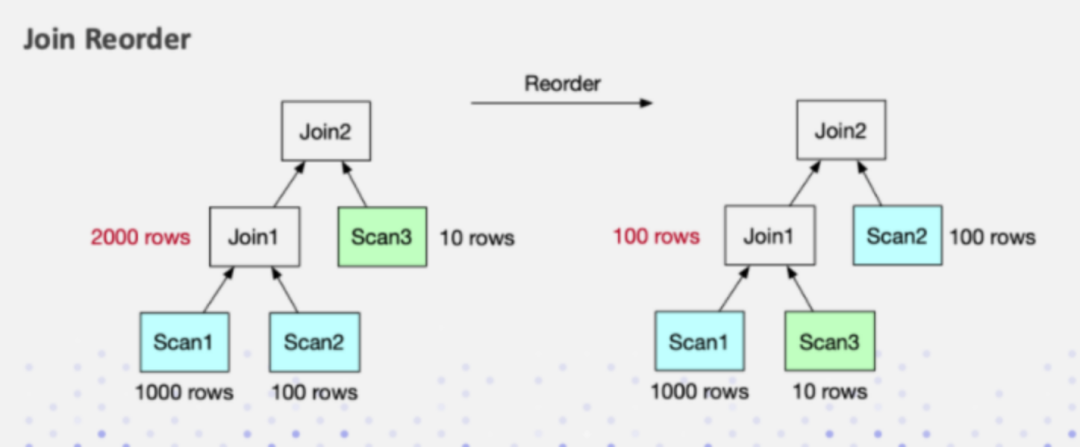
接下来看右图,把 Join 的顺序调整了一下。把 a 表先与 c 表 Join,生成的中间结果只有 100,然后最终再与 b 表 Join 计算。最终的 Join 结果是一样的,但是它生成的中间结果有 20 倍的差距,这就会产生一个很大的性能 Diff 了。
Doris 目前支持基于规则的 Join Reorder 算法。它的逻辑是:
让大表、跟小表尽量做 Join,它生成的中间结果是尽可能小的。
把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤
Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join 快很多的。
8.2.2 示例
查看未开启Join Reorder的执行计划
explain graph
select *
from example_site_visit
join example_site_visit2
on example_site_visit.user_id=example_site_visit2.user_id
join example_site_visit3
on example_site_visit.user_id=example_site_visit3.user_id;
开启Join Reorder
set enable_cost_based_join_reorder=true
查看开启Join Reorder后的执行计划
explain graph
select *
from example_site_visit
join example_site_visit2
on example_site_visit.user_id=example_site_visit2.user_id
join example_site_visit3
on example_site_visit.user_id=example_site_visit3.user_id;
8.3 Join的优化原则
在做 Join 的时候,要尽量选择同类型或者简单类型的列,同类型的话就减少它的数据 Cast,简单类型本身 Join 计算就很快。
尽量选择 Key 列进行 Join, 原因前面在 Runtime Filter 的时候也介绍了,Key 列在延迟物化上能起到一个比较好的效果。
大表之间的 Join ,尽量让它 Co-location ,因为大表之间的网络开销是很大的,如果需要去做 Shuffle 的话,代价是很高的。
合理的使用 Runtime Filter,它在 Join 过滤率高的场景下效果是非常显著的。但是它并不是万灵药,而是有一定副作用的,所以需要根据具体的 SQL 的粒度做开关。
涉及到多表 Join 的时候,需要去判断 Join 的合理性。尽量保证左表为大表,右表为小表,然后 Hash Join 会优于 Nest Loop Join。必要的时可以通过 SQL Rewrite,利用 Hint 去调整 Join 的顺序。

8.4 导入导出性能优化
在提交 LOAD 作业前,先执行 set enable_profile=true 打开会话变量。然后提交导入作业。待导入作业完成后,可以在 FE 的 web 页面的 Queris 标签中查看到导入作业的 Profile。这个 Profile 可以帮助分析导入作业的运行状态。当前只有作业成功执行后,才能查看 Profile。
8.4.1 FE 配置
以下配置属于 FE 的系统配置,可以通过修改 FE 的配置文件 fe.conf 来修改配置。
max_load_timeout_second min_load_timeout_second 最大、最小导入超时时间,单位秒,默认最大3天,最小1秒。用户自定义的导入超时时间不可超过这个范围。该参数通用于所有的导入方式。 desired_max_waiting_jobs 在等待队列中的导入任务最大个数,默认为100。当在 FE 中处于 PENDING 状态(也就是等待执行的)导入个数超过该值,新的导入请求则会被拒绝。仅对异步执行的导入有效,当异步执行的导入等待个数超过默认值,则后续的创建导入请求会被拒绝。 max_running_txn_num_per_db 每个 Database 中正在运行的导入最大个数(不区分导入类型,统一计数),默认100。如果是同步导入作业,则导入会被拒绝。如果是异步导入作业。则作业会在队列中等待。 Broker相关的FE配置:
min_bytes_per_broker_scanner 单个BE处理的数据量的最小值,默认 64MB,单位bytes max_bytes_per_broker_scanner 单个BE处理的数据量的最大值,默认 3G,单位bytes max_broker_concurrency 作业的最大的导入并发数,默认10 本次导入并发数 = Math.min(源文件大小/最小处理量,最大并发数,当前BE节点个数)
本次导入单个BE的处理量 = 源文件大小/本次导入的并发数
Stream Load相关的FE配置:
stream_load_default_timeout_second 导入任务的超时时间(以秒为单位),默认600 秒。也可以在 stream load 请求中设置单独的超时时间。 Export导出相关FE配置
export_checker_interval_second 调度间隔,默认5秒。设置该参数需重启FE。 export_running_job_num_limit 正在运行的Export作业数量限制。如果超过,则作业将等待并处于PENDING状态。默认为5,可以运行时调整。 export_task_default_timeout_second Export作业默认超时时间。默认为2小时。可以运行时调整。 export_tablet_num_per_task 一个查询计划负责的最大分片数。默认为5。
8.4.2 BE 配置
以下配置属于 BE 的系统配置,可以通过修改 BE 的配置文件 be.conf 来修改配置。
push_write_mbytes_per_sec BE 上单个 Tablet 的写入速度限制,默认 10,即 10MB/s。通常 BE 对单个 Tablet 的最大写入速度,根据 Schema 以及系统的不同,大约在 10-30MB/s 之间。可以适当调整这个参数来控制导入速度。 write_buffer_size 导入数据在 BE 上会先写入一个 memtable,memtable 达到阈值后才会写回磁盘。默认大小是 100MB。过小的阈值可能导致 BE 上存在大量的小文件。可以适当提高这个阈值减少文件数量。但过大的阈值可能导致 RPC 超时,见下面的配置说明。 tablet_writer_rpc_timeout_sec 导入过程中,发送一个 Batch(1024行)的 RPC 超时时间。默认 600 秒。因为该 RPC 可能涉及多个 memtable 的写盘操作,所以可能会因为写盘导致 RPC 超时,可以适当调整这个超时时间来减少超时错误(如 send batch fail 错误)。同时,如果调大 write_buffer_size 配置,也需要适当调大这个参数。 streaming_load_rpc_max_alive_time_sec 在导入过程中,Doris 会为每一个 Tablet 开启一个 Writer,用于接收数据并写入。这个参数指定了 Writer 的等待超时时间。如果在这个时间内,Writer 没有收到任何数据,则 Writer 会被自动销毁。当系统处理速度较慢时,Writer 可能长时间接收不到下一批数据,导致导入报错:TabletWriter add batch with unknown id。此时可适当增大这个配置。默认为 600 秒。 load_process_max_memory_limit_bytesload_process_max_memory_limit_percent 限制了单个 Backend 上,可用于导入任务的最大内存和最大内存百分比。load_process_max_memory_limit_percent 默认为 80,表示对 Backend 总内存限制的百分比(总内存限制 mem_limit 默认为 80%,表示对物理内存的百分比)。即假设物理内存为 M,则默认导入内存限制为 M * 80% * 80%。load_process_max_memory_limit_bytes 默认为 100GB。系统会在两个参数中取较小者,作为最终的 Backend 导入内存使用上限。 label_keep_max_second 设置导入任务记录保留时间。已经完成的( FINISHED or CANCELLED )导入任务记录会保留在 Doris 系统中一段时间,时间由此参数决定。参数默认值时间为3天。该参数通用与所有类型的导入任务。 Stream Load相关BE配置
streaming_load_max_mb Stream load的最大导入大小,默认为10G,单位MB。如果用户的原始文件超过这个值,则需要调大。
8.4.3 性能分析
导入过程中的查询超时,建议先看监控,grafana 上的数据。比如是否导入占用了过多的 IO或者 cpu 等,导致了相互影响,再逐步根据 pprof (8.1.3提到的调试工具)+ 代码分析。
8.4.4 Broker导入大文件
由于单个导入 BE 最大的处理量为 3G,超过 3G 的待导入文件就需要通过调整 Broker load 的导入参数来实现大文件的导入。
修改 fe.conf 中配置
根据当前 BE 的个数和原始文件的大小修改单个 BE 的最大扫描量和最大并发数。
max_broker_concurrency = BE 个数
当前导入任务单个 BE 处理的数据量 = 原始文件大小 / max_broker_concurrency
max_bytes_per_broker_scanner >= 当前导入任务单个 BE 处理的数据量比如一个 100G 的文件,集群的 BE 个数为 10 个。
max_broker_concurrency = 10
max_bytes_per_broker_scanner >= 10G = 100G / 10修改后,所有的 BE 会并发的处理导入任务,每个 BE 处理原始文件的一部分。
注意:上述两个 FE 中的配置均为系统配置,也就是说其修改是作用于所有的 Broker load的任务的。
合理设置timeout时间
在创建导入的时候自定义当前导入任务的 timeout 时间
单个BE处理数据量/最慢导入速度(MB/s)>=timeout时间>=单个BE处理数据量/10M/s比如一个 100G 的文件,集群的 BE 个数为 10个
timeout >= 1000s = 10G / 10M/s当计算出的 timeout 时间超过系统默认的导入最大超时时间 4小时,不推荐将导入最大超时时间直接改大来解决问题。最好是通过切分待导入文件并且分多次导入来解决问题。因为单次导入超过4小时的话,导入失败后重试的时间成本很高。
评估导入最大数据量
可以通过如下公式计算出 Doris 集群期望最大导入文件数据量:
期望最大导入文件数据量 = 14400s * 10M/s * BE 个数比如:集群的 BE 个数为 10个
期望最大导入文件数据量 = 14400s * 10M/s * 10 = 1440000M ≈ 1440G注意:一般环境可能达不到 10M/s 的速度,所以建议超过 500G 的文件都进行文件切分,再导入。
8.5 Bitmap 索引
用户可以通过创建bitmap index 加速查询
创建索引
语法:
CREATE INDEX [IF NOT EXISTS] index_name ON table_name (column [, ...],) [USING BITMAP] [COMMENT'balabala'];注意:BITMAP 索引仅在单列上创建
示例:在table1 上为siteid 创建bitmap 索引
CREATE INDEX table_bitmap ON table1 (siteid) USING BITMAP COMMENT 'table1_bitmap_index';查看索引
语法:
SHOW INDEX[ES] FROM [db_name.]table_name [FROM database];
或者
SHOW KEY[S] FROM [db_name.]table_name [FROM database];示例:展示table1索引
SHOW INDEX FROM test_db.table1;删除索引
语法:
DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name;示例:
DROP INDEX IF EXISTS table_bitmap ON test_db.table1;
8.6 BloomFilter索引
Doris的BloomFilter索引是从通过建表的时候指定,或者通过表的ALTER操作来完成。Bloom Filter本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回false,则一定不在这个集合内。而如果范围true,则有可能在这个集合内。
BloomFilter索引也是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BloomFilter索引条目,用于在查询是快速过滤不满足条件的数据。
建表时指定BloomFilter索引
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "销售时间",
customer_id int NOT NULL COMMENT "客户编号",
saler_id int NOT NULL COMMENT "销售员",
sku_id int NOT NULL COMMENT "商品编号",
category_id int NOT NULL COMMENT "商品分类",
sale_count int NOT NULL COMMENT "销售数量",
sale_price DECIMAL(12,2) NOT NULL COMMENT "单价",
sale_amt DECIMAL(20,2) COMMENT "销售总金额"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
PARTITION BY RANGE(sale_date)
(
PARTITION P_202111 VALUES [('2021-11-01'), ('2021-12-01'))
)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"bloom_filter_columns"="saler_id,category_id",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "P_",
"dynamic_partition.replication_num" = "3",
"dynamic_partition.buckets" = "3"
);查看BloomFilter索引
SHOW CREATE TABLE sale_detail_bloom修改BloomFilter索引
ALTER TABLE test_db.sale_detail_bloom SET ("bloom_filter_columns" = "customer_id,sku_id");删除BloomFilter索引
ALTER TABLE test_db.sale_detail_bloom SET ("bloom_filter_columns" = "");
8.7 合理设置分桶分区数
一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
举一些例子:假设在有10台BE,每台BE一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑4-8个分片。5GB:8-16个。50GB:32个。500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。
注:表的数据量可以通过 show data 命令查看,结果除以副本数,即表的数据量。
第9章 数据备份及恢复
Doris 支持将当前数据以文件的形式,通过 broker 备份到远端存储系统中。之后可以通过 恢复 命令,从远端存储系统中将数据恢复到任意 Doris 集群。通过这个功能,Doris 可以支持将数据定期的进行快照备份。也可以通过这个功能,在不同集群间进行数据迁移。
该功能需要 Doris 版本 0.8.2+
使用该功能,需要部署对应远端存储的 broker。如 BOS、HDFS 等。可以通过 SHOW BROKER; 查看当前部署的 broker。
9.1 简要原理说明
9.1.1 备份(Backup)
备份操作是将指定表或分区的数据,直接以 Doris 存储的文件的形式,上传到远端仓库中进行存储。当用户提交 Backup 请求后,系统内部会做如下操作:
快照及快照上传
快照阶段会对指定的表或分区数据文件进行快照。之后,备份都是对快照进行操作。在快照之后,对表进行的更改、导入等操作都不再影响备份的结果。快照只是对当前数据文件产生一个硬链,耗时很少。快照完成后,会开始对这些快照文件进行逐一上传。快照上传由各个 Backend 并发完成。
元数据准备及上传
数据文件快照上传完成后,Frontend 会首先将对应元数据写成本地文件,然后通过 broker 将本地元数据文件上传到远端仓库。完成最终备份作业。
9.1.2 恢复(Restore)
恢复操作需要指定一个远端仓库中已存在的备份,然后将这个备份的内容恢复到本地集群中。当用户提交 Restore 请求后,系统内部会做如下操作:
在本地创建对应的元数据
这一步首先会在本地集群中,创建恢复对应的表分区等结构。创建完成后,该表可见,但是不可访问。
本地snapshot
这一步是将上一步创建的表做一个快照。这其实是一个空快照(因为刚创建的表是没有数据的),其目的主要是在 Backend 上产生对应的快照目录,用于之后接收从远端仓库下载的快照文件。
下载快照
远端仓库中的快照文件,会被下载到对应的上一步生成的快照目录中。这一步由各个 Backend 并发完成。
生效快照
快照下载完成后,我们要将各个快照映射为当前本地表的元数据。然后重新加载这些快照,使之生效,完成最终的恢复作业。
9.1.3 最佳实践
备份
当前我们支持最小分区(Partition)粒度的全量备份(增量备份有可能在未来版本支持)。如果需要对数据进行定期备份,首先需要在建表时,合理的规划表的分区及分桶,比如按时间进行分区。然后在之后的运行过程中,按照分区粒度进行定期的数据备份。
数据迁移
用户可以先将数据备份到远端仓库,再通过远端仓库将数据恢复到另一个集群,完成数据迁移。因为数据备份是通过快照的形式完成的,所以,在备份作业的快照阶段之后的新的导入数据,是不会备份的。因此,在快照完成后,到恢复作业完成这期间,在原集群上导入的数据,都需要在新集群上同样导入一遍。
建议在迁移完成后,对新旧两个集群并行导入一段时间。完成数据和业务正确性校验后,再将业务迁移到新的集群。
重点说明
备份恢复相关的操作目前只允许拥有 ADMIN 权限的用户执行。
一个 Database 内,只允许有一个正在执行的备份或恢复作业。
备份和恢复都支持最小分区(Partition)级别的操作,当表的数据量很大时,建议按分区分别执行,以降低失败重试的代价。
因为备份恢复操作,操作的都是实际的数据文件。所以当一个表的分片过多,或者一个分片有过多的小版本时,可能即使总数据量很小,依然需要备份或恢复很长时间。用户可以通过
SHOW PARTITIONS FROM table_name;和SHOW TABLET FROM table_name;来查看各个分区的分片数量,以及各个分片的文件版本数量,来预估作业执行时间。文件数量对作业执行的时间影响非常大,所以建议在建表时,合理规划分区分桶,以避免过多的分片。当通过
SHOW BACKUP或者SHOW RESTORE命令查看作业状态时。有可能会在 TaskErrMsg 一列中看到错误信息。但只要 State 列不为 CANCELLED,则说明作业依然在继续。这些 Task 有可能会重试成功。当然,有些 Task 错误,也会直接导致作业失败。如果恢复作业是一次覆盖操作(指定恢复数据到已经存在的表或分区中),那么从恢复作业的 COMMIT 阶段开始,当前集群上被覆盖的数据有可能不能再被还原。此时如果恢复作业失败或被取消,有可能造成之前的数据已损坏且无法访问。这种情况下,只能通过再次执行恢复操作,并等待作业完成。因此,我们建议,如无必要,尽量不要使用覆盖的方式恢复数据,除非确认当前数据已不再使用。
9.2 备份
9.2.1 创建一个远端仓库路径
CREATE REPOSITORY `hdfs_ods_dw_backup`
WITH BROKER `broker_name`
ON LOCATION "hdfs://hadoop1:8020/tmp/doris_backup"
PROPERTIES (
"username" = "",
"password" = ""
)
9.2.2 执行备份
语法:
BACKUP SNAPSHOT [db_name].{snapshot_name}
TO `repository_name`
ON (
`table_name` [PARTITION (`p1`, ...)],
...
)
PROPERTIES ("key"="value", ...);
示例:
BACKUP SNAPSHOT test_db.backup1
TO hdfs_ods_dw_backup
ON
(
table1
);
9.2.3 查看备份任务
SHOW BACKUP [FROM db_name]
9.2.4 查看远端仓库镜像
语法:
SHOW SNAPSHOT ON `repo_name`
[WHERE SNAPSHOT = "snapshot" [AND TIMESTAMP = "backup_timestamp"]];
示例一:查看仓库 hdfs_ods_dw_backup 中已有的备份:
SHOW SNAPSHOT ON hdfs_ods_dw_backup;
示例二:仅查看仓库 hdfs_ods_dw_backup 中名称为 backup1 的备份:
SHOW SNAPSHOT ON hdfs_ods_dw_backup WHERE SNAPSHOT = "backup1";
示例三:查看仓库 hdfs_ods_dw_backup 中名称为 backup1 的备份,时间版本为 "2021-05-05-15-34-26" 的详细信息:
SHOW SNAPSHOT ON hdfs_ods_dw_backup
WHERE SNAPSHOT = "backup1" AND TIMESTAMP = "2021-05-05-15-34-26";
9.2.5 取消备份
取消一个正在执行的备份作业语法:
CANCEL BACKUP FROM db_name;
示例:取消 test_db 下的 BACKUP 任务
CANCEL BACKUP FROM test_db;
9.3 恢复
将之前通过 BACKUP 命令备份的数据,恢复到指定数据库下。该命令为异步操作。提交成功后,需通过 SHOW RESTORE 命令查看进度。
仅支持恢复 OLAP 类型的表
支持一次恢复多张表,这个需要和你对应的备份里的表一致
9.3.1 使用语法
RESTORE SNAPSHOT [db_name].{snapshot_name}
FROM `repository_name`
ON (
`table_name` [PARTITION (`p1`, ...)] [AS `tbl_alias`],
...
)
PROPERTIES ("key"="value", ...);
说明:
同一数据库下只能有一个正在执行的 BACKUP 或 RESTORE 任务。
ON 子句中标识需要恢复的表和分区。如果不指定分区,则默认恢复该表的所有分区。所指定的表和分区必须已存在于仓库备份中
可以通过 AS 语句将仓库中备份的表名恢复为新的表。但新表名不能已存在于数据库中。分区名称不能修改。
可以将仓库中备份的表恢复替换数据库中已有的同名表,但须保证两张表的表结构完全一致。表结构包括:表名、列、分区、Rollup等等。
可以指定恢复表的部分分区,系统会检查分区 Range 或者 List 是否能够匹配。
PROPERTIES 目前支持以下属性:
"backup_timestamp" = "2018-05-04-16-45-08":指定了恢复对应备份的哪个时间版本,必填。该信息可以通过 SHOW SNAPSHOT ON repo; 语句获得。"replication_num" = "3":指定恢复的表或分区的副本数。默认为3。若恢复已存在的表或分区,则副本数必须和已存在表或分区的副本数相同。同时,必须有足够的 host 容纳多个副本。"timeout" = "3600":任务超时时间,默认为一天。单位秒。"meta_version" = 40:使用指定的 meta_version 来读取之前备份的元数据。注意,该参数作为临时方案,仅用于恢复老版本 Doris 备份的数据。最新版本的备份数据中已经包含 meta version,无需再指定。
9.3.2 使用示例
示例一
从 example_repo 中恢复备份 snapshot_1 中的表 backup_tbl 到数据库 example_db1,时间版本为 "2021-05-04-16-45-08"。恢复为 1 个副本:
RESTORE SNAPSHOT example_db1.`snapshot_1`
FROM `example_repo`
ON ( `backup_tbl` )
PROPERTIES
(
"backup_timestamp"="2021-05-04-16-45-08",
"replication_num" = "1"
);示例二
从 example_repo 中恢复备份 snapshot_2 中的表 backup_tbl 的分区 p1,p2,以及表 backup_tbl2 到数据库 example_db1,并重命名为 new_tbl,时间版本为 "2021-05-04-17-11-01"。默认恢复为 3 个副本:
RESTORE SNAPSHOT example_db1.`snapshot_2`
FROM `example_repo`
ON
(
`backup_tbl` PARTITION (`p1`, `p2`),
`backup_tbl2` AS `new_tbl`
)
PROPERTIES
(
"backup_timestamp"="2021-05-04-17-11-01"
);演示
RESTORE SNAPSHOT test_db.backup1
FROM `hdfs_ods_dw_backup`
ON
(
table1 AS table_restore
)
PROPERTIES
(
"backup_timestamp"="2022-04-01-16-45-19"
);
9.3.3 查看恢复任务
可以通过下面的语句查看数据恢复的情况
SHOW RESTORE [FROM db_name]
9.3.4 取消恢复
下面的语句用于取消一个正在执行数据恢复的作业:
CANCEL RESTORE FROM db_name;
当取消处于 COMMIT 或之后阶段的恢复左右时,可能导致被恢复的表无法访问。此时只能通过再次执行恢复作业进行数据恢复
示例:取消 example_db 下的 RESTORE 任务。
CANCEL RESTORE FROM example_db;
9.4 删除远端仓库
该语句用于删除一个已创建的仓库。仅 root 或 superuser 用户可以删除仓库。这里的用户是指Doris的用户
语法:
DROP REPOSITORY `repo_name`;
说明:
删除仓库,仅仅是删除该仓库在 Doris 中的映射,不会删除实际的仓库数据。删除后,可以再次通过指定相同的 broker 和 LOCATION 映射到该仓库。
示例:删除名为 hdfs_ods_dw_backup 的仓库:
DROP REPOSITORY `hdfs_ods_dw_backup`;
第10章 1.0 新特性
Doris 1.0开始官网提供了编译好的二进制包,可以直接下载使用。如果老版本想滚动升级新版本,可以参照官方说明:https://doris.apache.org/zh-CN/installing/upgrade.html
版本通告:https://mp.weixin.qq.com/s/Ju3K67jOrBdJ8BX-V1IIgw
10.1 向量化执行引擎
过去 Apache Doris 的 SQL 执行引擎是基于行式内存格式以及基于传统的火山模型进行设计的,在进行 SQL 算子与函数运算时存在非必要的开销,导致 Apache Doris 执行引擎的效率受限,并不适应现代 CPU 的体系结构。向量化执行引擎的目标是替换 Apache Doris 当前的行式 SQL 执行引擎,充分释放现代 CPU 的计算能力,突破在 SQL 执行引擎上的性能限制,发挥出极致的性能表现。
基于现代 CPU 的特点与火山模型的执行特点,向量化执行引擎重新设计了在列式存储系统的 SQL 执行引擎:
重新组织内存的数据结构,用 Column替换 Tuple,提高了计算时 Cache 亲和度,分支预测与预取内存的友好度
分批进行类型判断,在本次批次中都使用类型判断时确定的类型,将每一行类型判断的虚函数开销分摊到批量级别。
通过批级别的类型判断,消除了虚函数的调用,让编译器有函数内联以及 SIMD 优化的机会
从而大大提高了 CPU 在 SQL 执行时的效率,提升了 SQL 查询的性能。
https://blog.csdn.net/qq_35423190/article/details/123129172
https://zhuanlan.zhihu.com/p/344706733
10.1.1 使用方式
set enable_vectorized_engine = true;
set batch_size = 4096;
batch_size代表了SQL算子每次进行批量计算的行数。Doris默认的配置为1024,这个配置的行数会影响向量化执行引擎的性能与CPU缓存预取的行为。官方推荐配置为4096。
10.1.2 准备测试表
CREATE TABLE IF NOT EXISTS test_db.user
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) NOT NULL COMMENT "用户所在城市",
`age` SMALLINT NOT NULL COMMENT "用户年龄",
`sex` TINYINT NOT NULL COMMENT "用户性别",
`phone` LARGEINT NOT NULL COMMENT "用户电话",
`address` VARCHAR(500) NOT NULL COMMENT "用户地址",
`register_time` DATETIME NOT NULL COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES("replication_num" = "1");
insert into test_db.user values\
(10000,'wuyanzu','北京',18,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),\
(20000,'wuyanzu','北京',19,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),\
(30000,'zhangsan','北京',20,0,12345678910,'北京海淀区','2017-11-15 06:10:20');
10.1.3 查看效果
explain select name from user where user_id > 20000
开启了向量化执行引擎之后,在SQL的执行计划之中会在SQL算子前添加一个V的标识。
10.1.4 注意事项
NULL值
由于NULL值在向量化执行引擎中会导致性能劣化。所以在建表时,将对应的列设置为NULL通常会影响向量化执行引擎的性能。这里推荐使用一些特殊的列值表示NULL值,并在建表时设置列为NOT NULL以充分发挥向量化执行引擎的性能。
与行存执行引擎的部分差异
在绝大多数场景之中,用户只需要默认打开session变量的开关,就可以透明地使用向量化执行引擎,并且使SQL执行的性能得到提升。但是,目前的向量化执行引擎在下面一些微小的细节上与原先的行存执行引擎存在不同,需要使用者知晓。这部分区别分为两类
不支持原有行存执行引擎的UDF与UDAF。
string/text类型最大长度支持为1MB,而不是默认的2GB。即当开启向量化引擎后,将无法查询或导入大于1MB的字符串。但如果关闭向量化引擎,则依然可以正常查询和导入。
不支持
select ... into outfile的导出方式。不支持external broker外表。
Float与Double类型计算可能产生精度误差,仅影响小数点后5位之后的数字。如果对计算精度有特殊要求,请使用Decimal类型。
DateTime类型不支持秒级别以下的计算或format等各种操作,向量化引擎会直接丢弃秒级别以下毫秒的计算结果。同时也不支持microseconds_add等,对毫秒计算的函数。
有符号类型进行编码时,0与-0在SQL执行中被认为是相等的。这可能会影响distinct,group by等计算的结果。
bitmap/hll 类型在向量化执行引擎中:输入均为NULL,则输出的结果为NULL而不是0。
a类 :行存执行引擎需要被废弃和不推荐使用或依赖的功能
b类:短期没有在向量化执行引擎上得到支持,但后续会得到开发支持的功能
10.2 Hive外表
Hive External Table of Doris 提供了 Doris 直接访问 Hive 外部表的能力,外部表省去了繁琐的数据导入工作,并借助 Doris 本身的 OLAP 的能力来解决 Hive 表的数据分析问题:
支持 Hive 数据源接入Doris
支持 Doris 与 Hive 数据源中的表联合查询,进行更加复杂的分析操作
10.2.1 基本语法
CREATE [EXTERNAL] TABLE table_name (
col_name col_type [NULL | NOT NULL] [COMMENT "comment"]
) ENGINE=HIVE
[COMMENT "comment"]
PROPERTIES (
'property_name'='property_value',
...
);
参数说明:
外表列
列名要与 Hive 表一一对应
列的顺序需要与 Hive 表一致
必须包含 Hive 表中的全部列
Hive 表分区列无需指定,与普通列一样定义即可。
ENGINE 需要指定为 HIVE
PROPERTIES 属性:
hive.metastore.uris:Hive Metastore 服务地址database:挂载 Hive 对应的数据库名table:挂载 Hive 对应的表名
10.2.2 类型匹配
支持的 Hive 列类型与 Doris 对应关系如下表:
| Hive | Doris | 描述 |
|---|---|---|
| BOOLEAN | BOOLEAN | |
| CHAR | CHAR | 当前仅支持UTF8编码 |
| VARCHAR | VARCHAR | 当前仅支持UTF8编码 |
| TINYINT | TINYINT | |
| SMALLINT | SMALLINT | |
| INT | INT | |
| BIGINT | BIGINT | |
| FLOAT | FLOAT | |
| DOUBLE | DOUBLE | |
| DECIMAL | DECIMAL | |
| DATE | DATE | |
| TIMESTAMP | DATETIME | Timestamp 转成 Datetime 会损失精度 |
注意:
Hive 表 Schema 变更不会自动同步,需要在 Doris 中重建 Hive 外表。
当前 Hive 的存储格式仅支持 Text,Parquet 和 ORC 类型
当前默认支持的 Hive 版本为 2.3.7、3.1.2,未在其他版本进行测试。后续后支持更多版本。
10.2.3 使用示例
完成在 Doris 中建立 Hive 外表后,除了无法使用 Doris 中的数据模型(rollup、预聚合、物化视图等)外,与普通的 Doris OLAP 表并无区别
Hive中创建测试表:
CREATE TABLE `test11` (
`k1` int NOT NULL COMMENT "",
`k2` char(10) NOT NULL COMMENT "",
`k3` timestamp NOT NULL COMMENT "",
`k5` varchar(20) NOT NULL COMMENT "",
`k6` double NOT NULL COMMENT ""
)
insert into test11 values (1,'a',unix_timestamp(),'haha',1.0);Doris中创建外表
CREATE TABLE `t_hive` (
`k1` int NOT NULL COMMENT "",
`k2` char(10) NOT NULL COMMENT "",
`k3` datetime NOT NULL COMMENT "",
`k5` varchar(20) NOT NULL COMMENT "",
`k6` double NOT NULL COMMENT ""
) ENGINE=HIVE
COMMENT "HIVE"
PROPERTIES (
'hive.metastore.uris' = 'thrift://hadoop1:9083',
'database' = 'test',
'table' = 'test11'
);查询外表
select * from t_hive;
10.3 Laterval view 语法
通过 Lateral View 语法,我们可以使用 explod_bitmap 、explode_split、explode_jaon_array 等 Table Function 表函数,将 bitmap、String 或 Json Array 由一列展开成多行,以便后续可以对展开的数据进行进一步处理(如 Filter、Join 等)。
创建测试表:
CREATE TABLE test3 (k1 INT,k2 varchar(30))
DISTRIBUTED BY HASH (k1) BUCKETS 2
PROPERTIES("replication_num" = "1");
INSERT INTO test3 VALUES (1,''), (2,null), (3,','), (4,'1'),(5,'1,2,3'),(6,'a,b,c');设置参数开启
set enable_lateral_view=true;explode_bitmap:展开一个bitmap类型
select k1, e1 from test3 lateral view explode_bitmap(bitmap_from_string("1")) tmp1 as e1 order by k1, e1;explode_split:将一个字符串按指定的分隔符分割成多个子串
select k1, e1 from test3 lateral view explode_split(k2, ',') tmp1 as e1 order by k1, e1;explode_json_array:展开一个 json 数组
select k1, e1 from test3 lateral view explode_json_array_int('[1,2,3]') tmp1 as e1 order by k1, e1;
select k1, e1 from test3 lateral view explode_json_array_double('[1.0,2.0,3.0]') tmp1 as e1 order by k1, e1;
select k1, e1 from test3 lateral view explode_json_array_string('[1,"b",3]') tmp1 as e1 order by k1, e1;
10.4 mysqldump导出
Doris 1.0支持通过mysqldump 工具导出数据或者表结构,下面几种操作:
导出 test 数据库中的 user 表:
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test_db --tables user > dump1.sql导出 test_db 数据库中的 user表结构:
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test_db --tables user --no-data > dump2.sql导出 test_db 数据库中所有表:
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test_db导出所有数据库和表
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --all-databases导出的结果可以重定向到文件中,之后可以通过 source 命令导入到Doris 中
source /opt/module/doris-1.0.0/dump1.sql

