
网易云音乐热门作品名字和链接抓取(bs4篇)
共 1080字,需浏览 3分钟
· 2022-05-25
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python白银交流群有个叫【O|】的粉丝问了一道关于网易云音乐热门作品名字和链接抓取的问题,获取源码之后,发现使用xpath匹配拿不到东西,从响应来看,确实是可以看得到源码的。
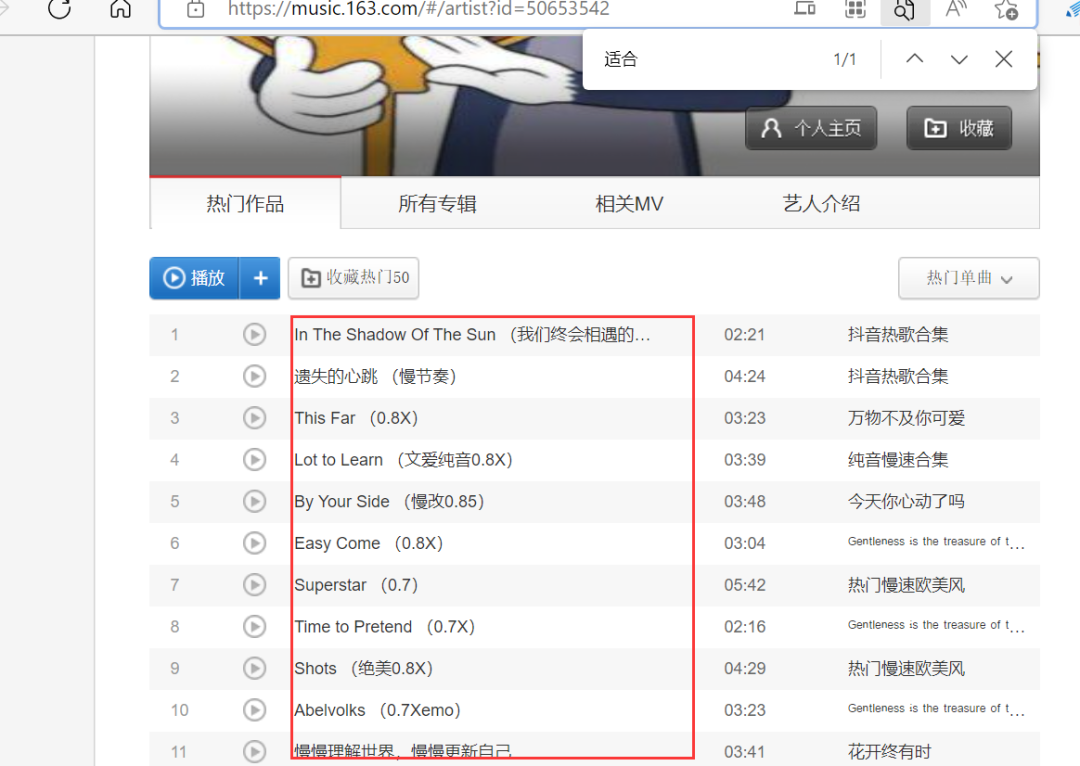 之前的文章,已经使用了正则表达式和
之前的文章,已经使用了正则表达式和xpath进行了相关实现,网易云音乐热门作品名字和链接抓取(正则表达式篇),网易云音乐热门作品名字和链接抓取(xpath篇),这篇文章我们使用bs4来实现。
二、实现过程
究其原因是返回的响应里边并不是规整的html格式,所以直接使用xpath是拿不到的。这里【Python进阶者】给了一个使用bs4的方法来实现的代码,代码如下。
# coding:utf-8
# @Time : 2022/5/11 11:46
# @Author: 皮皮
# @公众号: Python共享之家
# @website : http://pdcfighting.com/
# @File : 网易云音乐热门作品名字和链接(bs4).py
# @Software: PyCharm
#
# _ooOoo_
# o8888888o
# 88" . "88
# (| -_- |)
# O\ = /O
# ____/`---'\____
# .' \\| |// `.
# / \\||| : |||// \
# / _||||| -:- |||||- \
# | | \\\ - /// | |
# | \_| ''\---/'' | |
# \ .-\__ `-` ___/-. /
# ___`. .' /--.--\ `. . __
# ."" '< `.___\_<|>_/___.' >'"".
# | | : `- \`.;`\ _ /`;.`/ - ` : | |
# \ \ `-. \_ __\ /__ _/ .-` / /
# ======`-.____`-.___\_____/___.-`____.-'======
# `=---='
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# ☀佛祖保佑☀ 卍 ☀永无BUG☀
import requests, re
from lxml import etree
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
class Wangyiyun(object):
def __init__(self):
self.base_url = 'https://music.163.com/discover/artist'
self.headers = {
'user-agent': UserAgent().random,
'referer': 'https://music.163.com/',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}
def get_xpath(self, url):
res = requests.get(url, headers=self.headers)
# print(res.text)
html = res.text.replace('<适合才重要>', '适合才重要')
return BeautifulSoup(html, 'html.parser')
def singers_parse(self, url, items):
html = self.get_xpath(url)
song_dict = {}
# a_lis = html.xpath('//div[@id="song-list-pre-cache"]/ul/li/a') # "song-list-pre-cache"
a_lis = html.find('div', attrs={'id': 'song-list-pre-cache'}).find('ul').find_all('li')
for a in a_lis:
song_name = a.find('a').get_text()
print(song_name)
# print(a) # In The Shadow Of The Sun (我们终会相遇的,对吧)
song_url = 'https://music.163.com' + a.find('a').get('href')
print(song_url)
# song_dict[song_name] = song_url
items['所有歌曲:'] = song_dict
# print(items)
# name = items['歌手名:']
# print(f'歌手:{name} 的歌曲已经获取完毕!即将写入文件!')
# time.sleep(1)
# self.writer_data(items)
# print(f'歌手:{name} 的歌曲已经写入完毕!')
Wangyiyun().singers_parse(url='https://music.163.com/artist?id=50653542', items={})
这个代码亲测好使,运行之后结果如下。
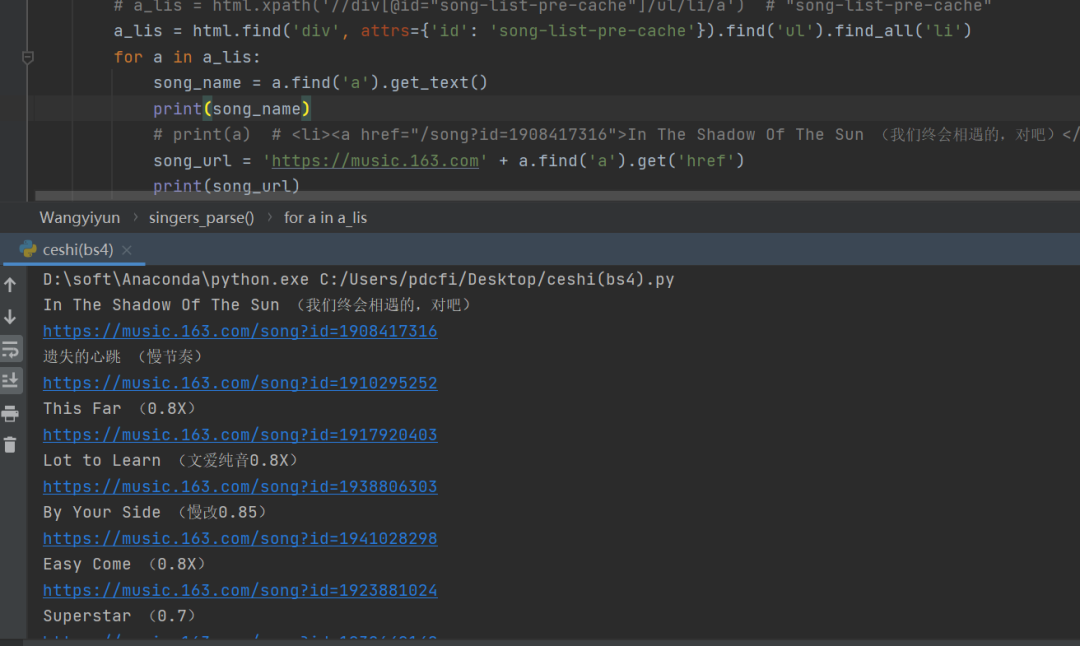
代码的关键点在于替换掉这个<>干扰,html误认为是标签了。这个问题和之前的百度贴吧网页类似,感兴趣的话,也可以看看这个文章,回味一下,两者有异曲同工之妙。
三、总结
大家好,我是皮皮。网易云音乐热门作品名字和链接抓取(bs4篇),行之有效,难点在于替换掉那个干扰标签。也欢迎大家积极尝试,一起学习。目前我们已经实现了使用正则表达式、xpath和bs4来进行操作,接下来的一篇文章,我们pyquery库来进行实现,帮助大家巩固下Python选择器基础。
最后感谢粉丝【O|】提问,感谢【dcpeng】、【月神】、【甯同学】、【凡人不烦人】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行